はじめに
青空文庫から引っ張ってきた作品を使って、作者を推定するというタスクをやったので記事にしました。コードはここで公開してます。
今回やった流れは以下です。
-
wgetを使って青空文庫から本文をダウンロード - MeCabを使って、本文を整形
- Doc2Vecを使って、本文をベクトル化(本文から作られたベクトルをx、作者IDをyとしたデータの作成)
- kerasを使ってニューラルネットを構成し、分類問題として教師あり学習
環境
- MacOS Catalina
- python3.7
ライブラリは主にBeautifulSoup, keras, Mecab, gensimを使っています。主旨からずれるので、これらのインストール方法は割愛します。基本的にpipでなんとかなりました。
下準備
まずは、作品をダウンロードする作者を決めます。今回はとりあえず「あ行の作者」かつ「公開作品数が20以上」を満たす人を対象としました。
青空文庫の作家リストから作品をダウンロードするために必要な作者IDを取得します。例えば芥川龍之介なら879です。

これらをまとめたauthors.txtを作成します。これも自動で作成するようにしてもよかったのですが、人数が少なかったので手作業で作っています。
芥川龍之介 879
有島武郎 25
アンデルセンハンス・クリスチャン 19
石川啄木 153
石原純 1429
泉鏡花 50
伊丹万作 231
伊藤左千夫 58
伊藤野枝 416
上田敏 235
上村松園 355
内田魯庵 165
海野十三 160
江戸川乱歩 1779
大久保ゆう 10
大隈重信 1879
大町桂月 237
丘浅次郎 1474
岡本かの子 76
岡本綺堂 82
小川未明 1475
小熊秀雄 124
小栗虫太郎 125
織田作之助 40
折口信夫 933
全部で25人。名前と作者IDの間は半角スペースです。また、後述する問題の関係でこのリストから省いた人(大倉燁子)もいます。
あとは必要なライブラリのインポートです。これ以降のpythonスクリプトはauthor_prediction.ipynbで公開しているものと同じです。
from bs4 import BeautifulSoup
import re
import MeCab
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
import numpy as np
import matplotlib.pyplot as plt
from keras import layers
from keras import models
from keras import optimizers
from keras.utils import np_utils
これで下準備は終わり。
1.wgetを使って青空文庫から本文をダウンロード
1.1 作品IDの取得
まずはauthors.txtを使って作者ごとの作品IDを取得する。これはpersonID??.txtという名前で保存する(??は作者ID)。
# authors.txtをもとに、wgetして作品IDが入ったpersonID??.txtを生成(??にはpersonIDが入る)
# personID_listにはpersonIDを入れる
personID_list = []
memo = open('./authors.txt')
for line in memo:
line = line.rstrip()
line = line.split( )
#print(line)
author = line[0]
personID = line[1]
personID_list.append(personID)
# authors.txtのpersonIDをもとに、indexをwgetする(すでに作成済なのでやる必要なし)
#!wget https://www.aozora.gr.jp/index_pages/person{personID}.html -O ./data/index{personID}.html
#!sleep 1
# 保存したindex??.htmlを開く
with open("./data/index{}.html".format(personID), encoding="utf-8") as f:
soup = BeautifulSoup(f)
ol = soup.find("ol").text
bookID = re.findall('ID:[0-9]*', ol) # index??.htmlの中から、作品IDが書いてある部分を取得
#print(bookID)
bookID_list = []
for b in bookID:
b = b[3:] # 'ID:'の削除
bookID_list.append(b) # 作品IDの追加
#print(bookID_list)
print('author {}\tpersonID {}\tnumber of cards {}'.format(author, personID, len(bookID_list)))
# bookID_listをもとに、ある作者の作品IDが記述されているテキストファイルを作成(すでに作成済なのでやる必要なし)
#with open('./data/personID{}.txt'.format(personID), mode='w') as f:
# for b in bookID_list:
# f.write(b + ' ')
実行するとこんな感じの出力が得られます。これでpersonID??.txtというファイルが25人分できます(??は作者ID)。
author 芥川龍之介 personID 879 number of cards 376
author 有島武郎 personID 25 number of cards 44
author アンデルセンハンス・クリスチャン personID 19 number of cards 23
author 石川啄木 personID 153 number of cards 78
author 石原純 personID 1429 number of cards 24
author 泉鏡花 personID 50 number of cards 208
author 伊丹万作 personID 231 number of cards 23
author 伊藤左千夫 personID 58 number of cards 39
author 伊藤野枝 personID 416 number of cards 80
author 上田敏 personID 235 number of cards 53
author 上村松園 personID 355 number of cards 83
author 内田魯庵 personID 165 number of cards 26
author 海野十三 personID 160 number of cards 177
author 江戸川乱歩 personID 1779 number of cards 91
author 大久保ゆう personID 10 number of cards 68
author 大隈重信 personID 1879 number of cards 31
author 大町桂月 personID 237 number of cards 60
author 丘浅次郎 personID 1474 number of cards 25
author 岡本かの子 personID 76 number of cards 119
author 岡本綺堂 personID 82 number of cards 247
author 小川未明 personID 1475 number of cards 521
author 小熊秀雄 personID 124 number of cards 33
author 小栗虫太郎 personID 125 number of cards 22
author 織田作之助 personID 40 number of cards 70
author 折口信夫 personID 933 number of cards 197
注意
上記のスクリプトにおいて、#を外して自分でwgetしてpersonID??.txtを作ると、アップロードしてあるpersonID??.txtよりも作品IDが多いものが得られます。これは、次のスクリプトで本文を取り出す時にエラーが出る作品IDを手動で消してるからです。
例えば、大久保ゆうさんの「あップルパイを」という作品では、通常の青空文庫のサイトの他に外部リンクが貼ってあって、そっちを取得してしまいます。この青空文庫のサイトが取れれば良いのに、外部サイトが取れてしまうということです。
また、小熊秀雄さんの短歌集のように、本文が存在しない(<div class="main_text">タグが存在しない)ものもあり、これもエラーの原因となります。
このような例外的な作品IDは消したpersonID??.txtをアップロードしているので、とりあえず動かしたい人はコメントを外すことは避けた方が無難です。動作を確認したい人だけコメントを外して保存先のディレクトリを変更する、といったことをすると良いと思います。
1.2 作品をwgetで保存
次に、personID??.txtに書かれている作品IDを用いて、作品をダウンロードする。作品ダウンロードにはpubserver2を使用させてもらっていますが、今考えるとpubserver2を経由しないで普通にwgetしてもよかったかも?
# personID??.txtから作品IDを取得して、その作品をwgetで持ってくる(作者1人あたり50作品まで)
# 作品が書かれているhtmlの名前はtext_x_y.html(xがpersonID、yがbookID)
for personID in personID_list:
print('personID', personID)
with open("./data/personID{}.txt".format(personID), encoding="utf-8") as f:
for bookID_str in f:
bookID_list = bookID_str.split( )
print('number of cards', len(bookID_list))
# 作品数が多すぎると時間かかるので50作品までに限定
if len(bookID_list) >= 50:
bookID_list = bookID_list[:50]
for bookID in bookID_list:
print('ID', bookID)
# bookIDをもとにwgetして本文が記述されているhtmlを作成(すでに作成済なのでやる必要なし)
#!wget http://pubserver2.herokuapp.com/api/v0.1/books/{bookID}/content?format=html -O ./data/text{personID}_{bookID}.html
#!sleep 1
2. MeCabを使って、本文を整形
本文を整形して、タグづけする関数を作成。これはここを参考にしました。
タグは0から24の数字をauthors.txtの順に割り振っています(芥川龍之介が0、有島武郎が1、...、折口信夫が24)。タグの数字に作者IDをそのまま利用するとデータ生成の時に面倒なので、ここで新たに番号を振り直してます。
# doc(作品の本文)を動詞・形容詞・名詞のみのwordsというリストにする
# wordsとtagからなるTaggedDocumentを生成
def split_into_words(doc, name=''):
mecab = MeCab.Tagger("-Ochasen")
lines = mecab.parse(doc).splitlines() # 形態素解析
words = []
for line in lines:
chunks = line.split('\t')
# 名詞(数詞は除く)、動詞、形容詞のみ加える
if len(chunks) > 3 and (chunks[3].startswith('動詞') or chunks[3].startswith('形容詞') or (chunks[3].startswith('名詞') and not chunks[3].startswith('名詞-数'))):
words.append(chunks[0])
#print(words)
return TaggedDocument(words=words, tags=[name])
学習用データとのtrain_textと、評価用データのtest_textを生成する。
# 学習させるtrain_textを生成(著者1人あたり20作品で固定)
# テスト用のtest_textも作る(学習で使わないデータの残り全てを使用)
# 人によって作品数が違うので、test_textに含まれる作品数も人によって異なる
train_text = []
test_text = []
for i, personID in enumerate(personID_list):
print('personID', personID)
with open("./data/personID{}.txt".format(personID), encoding="utf-8") as f:
for bookID_str in f:
#print(bookID)
bookID_list = bookID_str.split( )
# 50作品以上はダウンロードしてないのでカット
if len(bookID_list) >= 50:
bookID_list = bookID_list[:50]
print('number of cards', len(bookID_list))
for j, bookID in enumerate(bookID_list):
# 先ほど保存した本文が含まれるhtmlを開く
soup = BeautifulSoup(open("./data/text{}_{}.html".format(personID, bookID), encoding="shift_jis"))
# 本文が書かれている<div>を取り出す
main_text = soup.find("div", "main_text").text
#print(main_text)
# 最初の20作品はtrain_textに入れ、残りはtest_textに入れる
if j < 20:
train_text.append(split_into_words(main_text, str(i)))
print('bookID\t{}\ttrain'.format(bookID))
else:
test_text.append(split_into_words(main_text, str(i)))
print('bookID\t{}\ttest'.format(bookID))
3. Doc2Vecを使って、本文をベクトル化
Doc2Vecのモデルを作成する。alphaとかepochsとかのハイパーパラメータはかなり適当に決めています。
# Doc2Vecのモデルを作成し、学習させる
model = Doc2Vec(vector_size=len(train_text), dm=0, alpha=0.05, min_count=5)
model.build_vocab(train_text)
model.train(train_text, total_examples=len(train_text), epochs=5)
# 学習結果を保存
#model.save('./data/doc2vec.model')
ニューラルネットで学習させるために、本文を数値ベクトルに変換させたデータを作成。
# 作成したmodelとTaggedDocumentのリストであるtextから、ニューラルネット用のデータを作る
def text2xy(model, text):
x = []
y = []
for i in range(len(text)):
#print(i)
vec = model.infer_vector(text[i].words) # 数値からなるベクトルに変換
x.append(vec.tolist())
y.append(int(text[i].tags[0]))
x = np.array(x)
y = np_utils.to_categorical(y) # tagの数字はonehotに変換
return x, y
# 学習用データと評価用データの作成
x_train, y_train = text2xy(model, train_text)
x_test, y_test = text2xy(model, test_text)
4. kerasを使ってニューラルネットを構成し、分類問題として教師あり学習
モデルの作成から学習まで行う関数(dense_train)と、描画のための関数(draw_accとdraw_loss)を用意する。
作ったニューラルネットのモデルはかなり単純な全結合層3層からなるモデル。
損失関数には分類問題でよく使われるcategorical crossentropyを使用した。ユニットの数やlearning rateなどは適当です。
def dense_train(epochs):
# モデルの定義
kmodel = models.Sequential()
kmodel.add(layers.Dense(512, activation='relu', input_shape=(500,)))
kmodel.add(layers.Dense(256, activation='relu'))
kmodel.add(layers.Dense(25, activation='softmax'))
kmodel.summary()
# モデルのコンパイル
kmodel.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
# モデルの学習
history = kmodel.fit(x=x_train, y=y_train, epochs=epochs, validation_data=(x_test, y_test))
# モデルの保存
#model.save('./data/dense.h5')
return history, kmodel
# 正解率のプロット
def draw_acc(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1, len(acc) + 1)
fig = plt.figure()
fig1 = fig.add_subplot(111)
fig1.plot(epochs, acc, 'bo', label='Training acc')
fig1.plot(epochs, val_acc, 'b', label='Validation acc')
fig1.set_xlabel('epochs')
fig1.set_ylabel('accuracy')
fig.legend(bbox_to_anchor=(0., 0.19, 0.86, 0.102), loc=5) # anchor(凡例)の第2引数がy、第3引数がx
# 画像の保存
fig.savefig('./acc.pdf')
plt.show()
# lossのプロット
def draw_loss(history):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure()
fig1 = fig.add_subplot(111)
fig1.plot(epochs, loss, 'bo', label='Training loss')
fig1.plot(epochs, val_loss, 'b', label='Validation loss')
fig1.set_xlabel('epochs')
fig1.set_ylabel('loss')
fig.legend(bbox_to_anchor=(0., 0.73, 0.86, 0.102), loc=5) # anchor(凡例)の第2引数がy、第3引数がx
# 画像の保存
#fig.savefig('./loss.pdf')
plt.show()
訓練させ、正解率のグラフを描画する。今回、エポック数は10とした。
history, kmodel = dense_train(10)
draw_acc(history)
得られた出力は以下。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 256512
_________________________________________________________________
dense_2 (Dense) (None, 256) 131328
_________________________________________________________________
dense_3 (Dense) (None, 25) 6425
=================================================================
Total params: 394,265
Trainable params: 394,265
Non-trainable params: 0
_________________________________________________________________
Train on 500 samples, validate on 523 samples
Epoch 1/10
500/500 [==============================] - 0s 454us/step - loss: 3.0687 - acc: 0.1340 - val_loss: 2.9984 - val_acc: 0.3308
Epoch 2/10
500/500 [==============================] - 0s 318us/step - loss: 2.6924 - acc: 0.6300 - val_loss: 2.8255 - val_acc: 0.5698
Epoch 3/10
500/500 [==============================] - 0s 315us/step - loss: 2.3527 - acc: 0.8400 - val_loss: 2.6230 - val_acc: 0.6864
Epoch 4/10
500/500 [==============================] - 0s 283us/step - loss: 1.9961 - acc: 0.9320 - val_loss: 2.4101 - val_acc: 0.7610
Epoch 5/10
500/500 [==============================] - 0s 403us/step - loss: 1.6352 - acc: 0.9640 - val_loss: 2.1824 - val_acc: 0.8088
Epoch 6/10
500/500 [==============================] - 0s 237us/step - loss: 1.2921 - acc: 0.9780 - val_loss: 1.9504 - val_acc: 0.8337
Epoch 7/10
500/500 [==============================] - 0s 227us/step - loss: 0.9903 - acc: 0.9820 - val_loss: 1.7273 - val_acc: 0.8432
Epoch 8/10
500/500 [==============================] - 0s 220us/step - loss: 0.7424 - acc: 0.9840 - val_loss: 1.5105 - val_acc: 0.8642
Epoch 9/10
500/500 [==============================] - 0s 225us/step - loss: 0.5504 - acc: 0.9840 - val_loss: 1.3299 - val_acc: 0.8623
Epoch 10/10
500/500 [==============================] - 0s 217us/step - loss: 0.4104 - acc: 0.9840 - val_loss: 1.1754 - val_acc: 0.8719
学習結果の図はこちら。
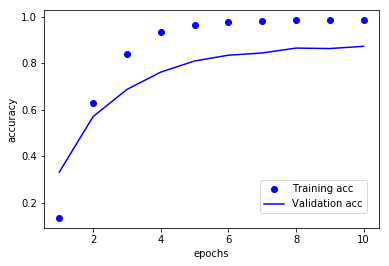
6エポック以降はサチっている気がするが、最終的に**87.16%**の正解率が得られた。ハイパーパラメータチューニングをほとんどやっていないのに、そこそこの正解率が得られたような気がする。
終わりに
ハイパーパラメータチューニングやモデルの選定(LSTMとか使う?)はもっとやっても良いかも。何かご指摘があればコメントください。ご覧いただきありがとうございました。