はじめに
某ドラマで亀梨和也が演じていると思って見ていた人物が実は佐藤健だと第8話後に知り、我ながら愕然としました...
まさか区別がついていなかったとは _| ̄|○
Google先生に聞いてみたところ、結構「似ている」とか「間違えた」とかいう人がいるようなので、そこのところはAIにおまかせしてみようと思い立ちました。
準備
単純にGoogle先生にお願いして、佐藤健と亀梨和也の画像を集めました。(手動で)
顔のアップやら全身画像やら、いろいろ集めました。
その後変な画像は除外して、最終的にそれぞれ100枚としました。
これを学習用90枚とテスト用10枚に分け、さらに学習用は81枚をトレーニング用、9枚を評価用としました。
フォルダ構成はこんな感じです。
# data/train/TakeruSato/
# /KazuyaKamenashi/
# /test/TakeruSato/
# /KazuyaKamenashi/
○佐藤健フォルダ
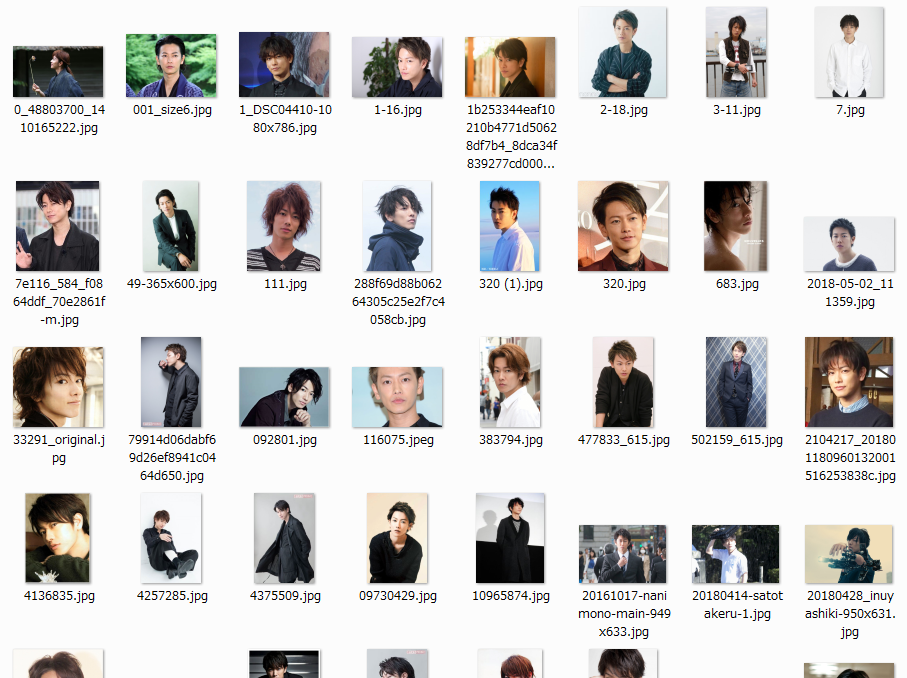
○亀梨和也フォルダ

環境
個人PCは非常にプアな環境なので、コーディング&テストはCPUで行い、本格的な学習はGoogle Colaboratoryを使用しました。
ちなみにGoogle Colaboratoryの使い方ですが、詳しくは他の方の説明を見ていただくとして、ざっくりというと、
- Google Driveにコード等が書かれたJupyter Notebookファイルをアップロードする
- 同じくGoogle Driveに画像ファイルをアップロードする
- Jupyter NotebookをGoogle Colaboratoryで起動する
- Google ColaboratoryからGoogle Driveが見えるようにする(ディレクトリのマウントもする)
- Jupyter Notebookを実行する
といった感じになります。
以降は、Google Colaboratory上で実行したコードになります。
学習
これは特に説明はいらないほど単純です。
Inception-v3を使用して、佐藤健と亀梨和也を0 or 1で分類しています。
なお、ハイパーパラメータの調整等はしていないので、頑張ればもっと精度は上がるかもしれません。
import tensorflow as tf
from keras.applications.inception_v3 import InceptionV3
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras.optimizers import SGD
from keras.regularizers import l2
import numpy as np
from PIL import Image
import os
# 学習用のデータを作る
image_list = []
label_list = []
# drive/keras/data/train 以下のTakeruSato、KazuyaKamenashiディレクトリ以下の画像を読み込む
for dir in os.listdir("drive/keras/data/train"):
dir1 = "drive/keras/data/train/" + dir
label = 0
if dir == "TakeruSato": # 佐藤健はラベル0
label = 0
elif dir == "KazuyaKamenashi": # 亀梨和也はラベル1
label = 1
for file in os.listdir(dir1):
# label_listに正解ラベルを追加(佐藤健:0 亀梨和也:1)
label_list.append(label)
filepath = dir1 + "/" + file
# 画像を299x299pixelに変換し、2次元配列として読み込む
image = np.array(Image.open(filepath).resize((299, 299)))
print(filepath)
# 画像をimage_listに追加(値を-1~1に変換)
image_list.append((image/127.5)-1.0)
# kerasに渡すためにnumpy配列に変換
image_list = np.array(image_list)
label_list = np.array(label_list)
# 順番をシャッフル
p = np.random.permutation(len(image_list))
image_list = image_list[p]
label_list = label_list[p]
# Inception v3モデルの読み込み ※最終層は読み込まない
base_model = InceptionV3(weights='imagenet', include_top=False)
# 最終層の設定
x = base_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(1, kernel_initializer="glorot_uniform", activation="sigmoid", kernel_regularizer=l2(.0005))(x)
model = Model(inputs=base_model.input, outputs=predictions)
# base_modelはweightsを更新しない
for layer in base_model.layers:
layer.trainable = False
# オプティマイザにSDGを使用
opt = SGD(lr=.01, momentum=.9)
# モデルをコンパイル
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# 学習を実行(10%はテストに使用)
model.fit(image_list, label_list, epochs=1000, batch_size=64, verbose=1, validation_split=0.1)
Inception-v3の重みは変えていないので、GAPのあとに全結合層+Dropoutを入れても良いかもしれません。
GPUを使用すると、1epochを2秒ぐらいで学習できています。

validationのaccuracyが0.7~0.8ぐらいなので、ちょっとイマイチな感じです。(しかも変動しないし...)
trainのaccuracyが1.0になっちゃっているのも問題かと。
また、lossもtrain側は徐々に下がっているのですが、validation側は一進一退状態なので、よろしくないですね。
識別
学習結果がよろしくないのであまりやる意味はありませんが、識別もやってみます。
テストデータでの識別のコードはこんな感じにしています。
# テスト用ディレクトリ(drive/keras/data/test/)の画像でチェック
total = 0.
ok_count = 0.
for dir in os.listdir("drive/keras/data/test"):
dir1 = "drive/keras/data/test/" + dir
label = 0
if dir == "TakeruSato":
label = 0
elif dir == "KazuyaKamenashi":
label = 1
for file in os.listdir(dir1):
filepath = dir1 + "/" + file
image = np.array(Image.open(filepath).resize((299, 299)))
print(filepath)
result = model.predict(np.array([(image/127.5)-1.0]))
print("label:", label, "result:", result[0,0])
total += 1.
if label == round(result[0,0]):
ok_count += 1.
print("seikai: ", ok_count / total * 100, "%")
実行すると、正解率55%ととっても微妙な結果に。
(佐藤健:2/10枚ハズレ、亀梨和也:7/10枚ハズレ)

学習データが悪いのか、数が少ないのか...
そもそもそっくりさんだと証明されたのか?!(苦笑)
参考URL
https://qiita.com/hiroeorz@github/items/ecb39ed4042ebdc0a957
https://employment.en-japan.com/engineerhub/entry/2017/04/28/110000