きっかけ
転職後、徐々に生活が落ち着いてきたので、ここらでエンジニア的なところもペースを戻したいなと。
で、やりたいこと
例えば企業情報があって、会社名や郵便番号、電話番号などは一致しているんだけど、住所だけ一致しないとき、これは同じ会社の情報なのか判断できないだろうか?
前提条件
- あくまでも「表記ゆれ」を対象とします
(ここでの)表記ゆれの定義
- 半角-全角の違い
- 漢数字-アラビア数字の違い
- 丁目、番地、号の省略(「-」で記述)
とりあえず保留
- 建物名の省略
- 階数の省略
今回のデータ
デジタル庁のアドレス・ベース・レジストリを参考に正解を決め、それをベースに確認するデータを作成します。
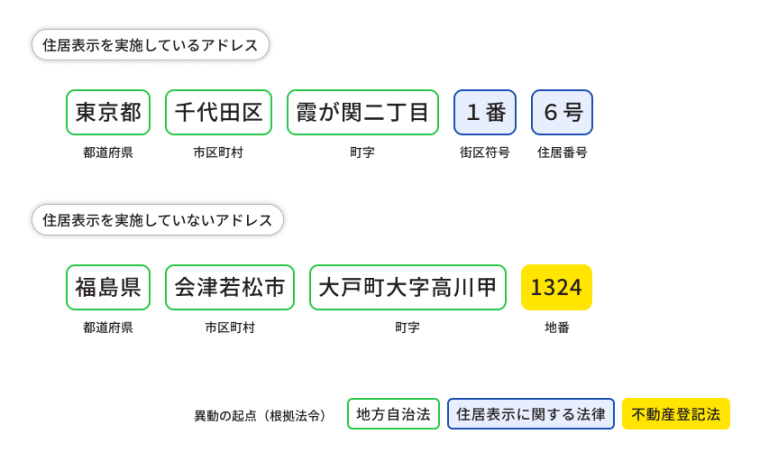
※今回は、上の「住居表示を実施しているアドレス」を対象にして、下の「住居表示を実施していないアドレス」は見送ります
- 正解
- 「東京都港区海岸一丁目2番3号」
- 表記ゆれ
- 半角「東京都港区海岸一丁目2番3号」
- 全角「東京都港区海岸一丁目2番3号」
- アラビア数字「東京都港区海岸1丁目2番3号」「東京都港区海岸1丁目2番3号」
- 丁目、番地、号の省略「東京都港区海岸1-2-3」「東京都港区海岸1-2-3」
- 不正解
- 正解「東京都港区海岸一丁目1番1号」
- 半角「東京都港区海岸一丁目1番1号」
- 漢数字「東京都港区海岸一丁目一番一号」
- アラビア数字「東京都港区海岸1丁目1番1号」「東京都港区海岸1丁目1番1号」
- 丁目、番地、号の省略「東京都港区海岸1-1-1」「東京都港区海岸1-1-1」
一応、不正解との比較もします。
なお、町名までは合っているもの(郵便番号があっている前提なので)としました。
環境構築
まずはベースモデルとして、日本語用Sentence-BERTモデル(バージョン2)を使用します。
ライセンスは「cc-by-sa-4.0」とのことですので、利用を明記しておけば商用利用も可能です。
インストール
以下をインストールします。(詳細は省略)
- CUDA 11.8、cuDNN v8.9.4
- PyTorch 2.0.1(とりあえずGPU版)
- transformers 4.7.0
- fugashi、ipadic
また、ローカル環境でJupyterNotebookを使いました。
(matplotlibも使用しました)
ソース
公式ページに従い、以下のコードを作成します。(途中まで)
from transformers import BertJapaneseTokenizer, BertModel
import torch
class SentenceBertJapanese:
def __init__(self, model_name_or_path, device=None):
self.tokenizer = BertJapaneseTokenizer.from_pretrained(model_name_or_path)
self.model = BertModel.from_pretrained(model_name_or_path)
self.model.eval()
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(device)
def _mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def encode(self, sentences, batch_size=8):
all_embeddings = []
iterator = range(0, len(sentences), batch_size)
for batch_idx in iterator:
batch = sentences[batch_idx:batch_idx + batch_size]
encoded_input = self.tokenizer.batch_encode_plus(batch, padding="longest",
truncation=True, return_tensors="pt").to(self.device)
model_output = self.model(**encoded_input)
sentence_embeddings = self._mean_pooling(model_output, encoded_input["attention_mask"]).to('cpu')
all_embeddings.extend(sentence_embeddings)
# return torch.stack(all_embeddings).numpy()
return torch.stack(all_embeddings)
MODEL_NAME = "sonoisa/sentence-bert-base-ja-mean-tokens-v2" # <- v2です。
model = SentenceBertJapanese(MODEL_NAME)
そのあとに、今回のデータを用意して、ベクトルを求めます。
sentences = [
# 正解
"東京都港区海岸一丁目2番3号",
# 表記ゆれ
"東京都港区海岸一丁目2番3号",
"東京都港区海岸一丁目二番三号",
"東京都港区海岸1丁目2番3号",
"東京都港区海岸1丁目2番3号",
"東京都港区海岸1-2-3",
"東京都港区海岸1-2-3",
# 不正解
"東京都港区海岸一丁目1番1号",
"東京都港区海岸一丁目1番1号",
"東京都港区海岸一丁目一番一号",
"東京都港区海岸1丁目1番1号",
"東京都港区海岸1丁目1番1号",
"東京都港区海岸1-1-1",
"東京都港区海岸1-1-1"
]
sentence_vectors = model.encode(sentences)
ここでは768次元のベクトルが求まります。
最後に正解とのコサイン距離を求めます。
import scipy.spatial
distances = scipy.spatial.distance.cdist(sentence_vectors, sentence_vectors, metric="cosine")[0]
結果
何のチューニングもしない状態で、以下の結果になりました。
| 東京都港区海岸一丁目2番3号 | ||
|---|---|---|
| 1 | 東京都港区海岸一丁目2番3号 | 2.22044605e-16 |
| 2 | 東京都港区海岸一丁目二番三号 | 6.11741123e-02 |
| 3 | 東京都港区海岸1丁目2番3号 | 7.29590979e-03 |
| 4 | 東京都港区海岸1丁目2番3号 | 7.29590979e-03 |
| 5 | 東京都港区海岸1-2-3 | 5.00328437e-02 |
| 6 | 東京都港区海岸1-2-3 | 5.00328437e-02 |
| 7 | 東京都港区海岸一丁目1番1号 | 2.45641245e-01 |
| 8 | 東京都港区海岸一丁目1番1号 | 2.45641314e-01 |
| 9 | 東京都港区海岸一丁目一番一号 | 2.57492124e-01 |
| 10 | 東京都港区海岸1丁目1番1号 | 2.58257453e-01 |
| 11 | 東京都港区海岸1丁目1番1号 | 2.58257453e-01 |
| 12 | 東京都港区海岸1-1-1 | 2.06726289e-01 |
| 13 | 東京都港区海岸1-1-1 | 2.06726289e-01 |
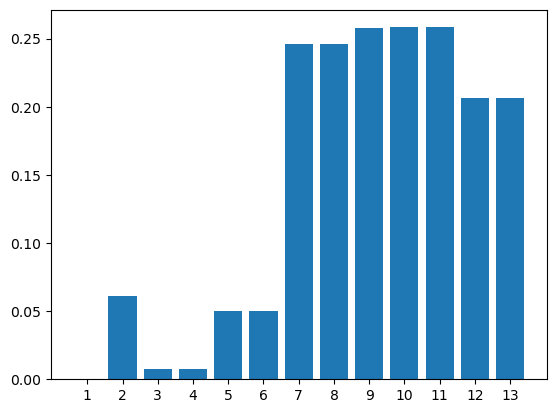
一応、正解(表記ゆれ)/不正解はわかりそう。
なおアラビア数字・ハイフンの半角・全角は、どっちかにそろえてから処理していそうですね。
今後の予定
- 今のモデルを住所の表記ゆれ用にチューニングしたいと思います
- モデル自体をもっと性能の良いものに見直したいです
参考資料
こちらを参考にさせていただいております。