前回、Amazon Kendraの勉強をしたので、早速改造してみます。
今回は、電子帳簿保存法の「一問一答」のPDFを検索したいと思います。
電子帳簿保存法 一問一答
URLはこちらになります。
電子帳簿保存法の法律や施行令などはやたらと難しいのですが、一問一答は具体的で、普通の人が読んでも非常にわかりやすいドキュメントとなっています。そのため、これならAmazon Kendraでの検索に使えるのではないかと思いました。
なお今回はお試しで上記ファイルを検索に使いますが、おそらく実際のシステムに組み込んだりしたらダメです。
(Amazon Kendraの注意事項として「Remember that you must only use Amazon Kendra Web Crawler to index your own web pages, or web pages that you have authorization to index. 」となってます)
法令は著作権の対象外ですが、法令の解説やコメントなどの二次的な著作物は著作権の対象になる可能性があるそうです。
この辺りは国税庁の見解待ちですね。
データソースをWebにして試してみる
前回は、データソースとしてS3にあるPDFとWeb Crawlerの両方を試しましたが、今回はWeb Crawlerだけで試してみます。
参照するファイルが違うだけで、ほかの設定は同じです。
「Default language」は「Japanese (ja)」にしておきます。
「Source URLs」に上記3つのURLを設定し、「Sync domain range」は「Sync domains only」、「Crawl depth」は「1」、「Sync run schedule」は「Run on demand」にしておきます。
(「Crawl depth」は「0」でも良さそうな気がします)
相変わらず、Syncが終わるのに、結構な時間がかかります。
ところが...
syncが正常に終了し、さて試しに検索してみようかなと思ったら...
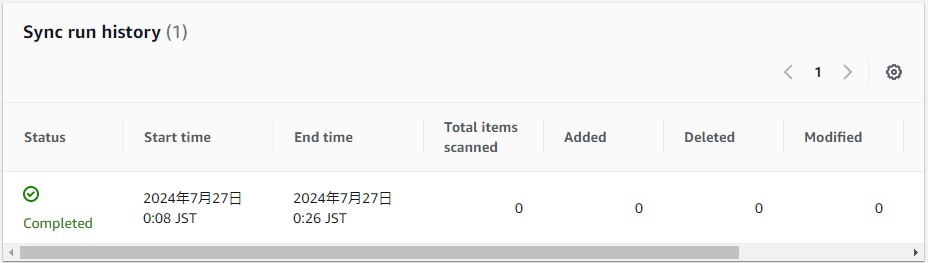
...スキャンしたファイルが0?
もしかしてWebだとPDFファイルは読み込めないのかな?
いろいろ設定を変更して試してみましたが、うまくいきませんでした。
ということで、とりあえずこちらの方法はあきらめることにします。
データソースをS3にしてみる
今度は、参照先のPDFファイルをダウンロードしてきて、S3に置いてみます。
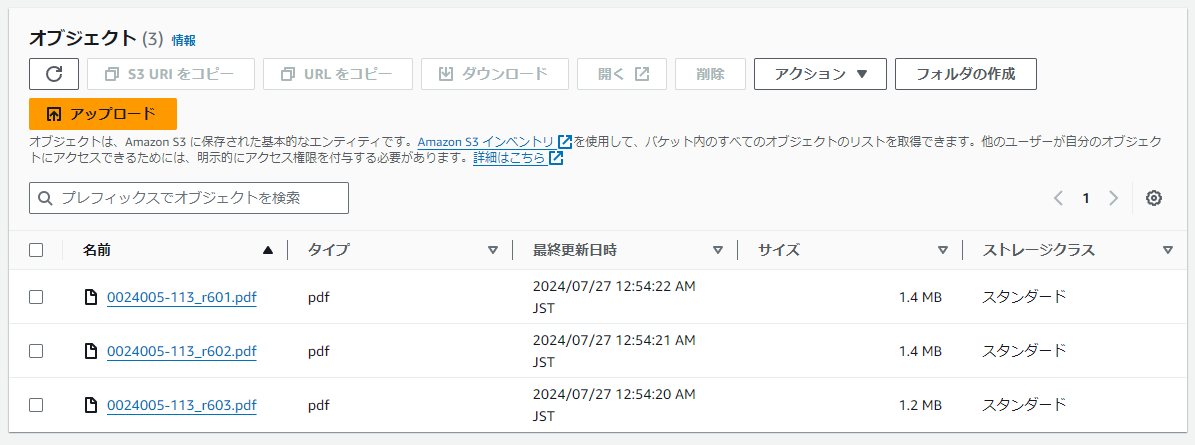
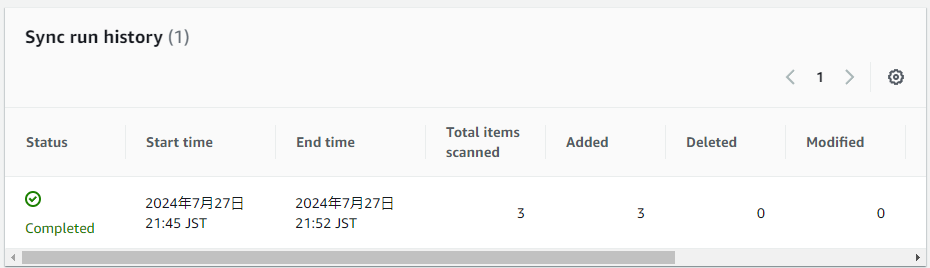
で、データソースをS3にして読み込んでみます。
質問してみる
早速試してみます。
(Webアプリからではなく、直接参照してみます)
-
「金額をマイナスで入力してもよいですか?」と聞いてみたら、こうなりました。
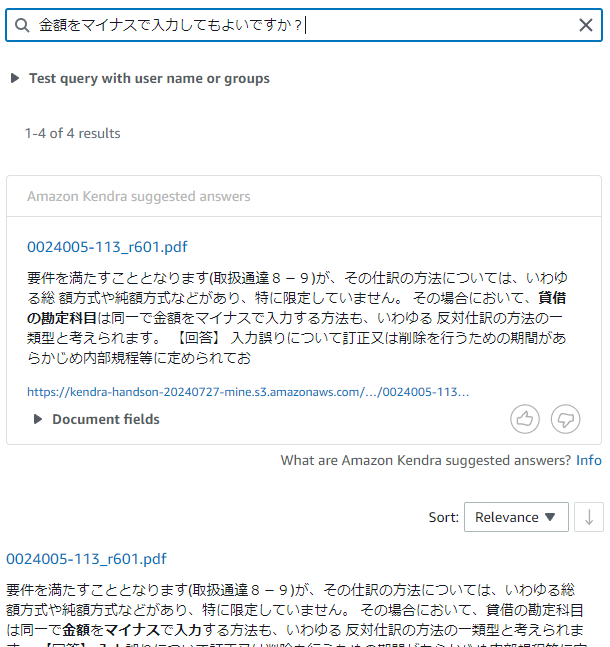
-
「スキャナ保存時の解像度は?」と聞いてみたら、こうなりました。
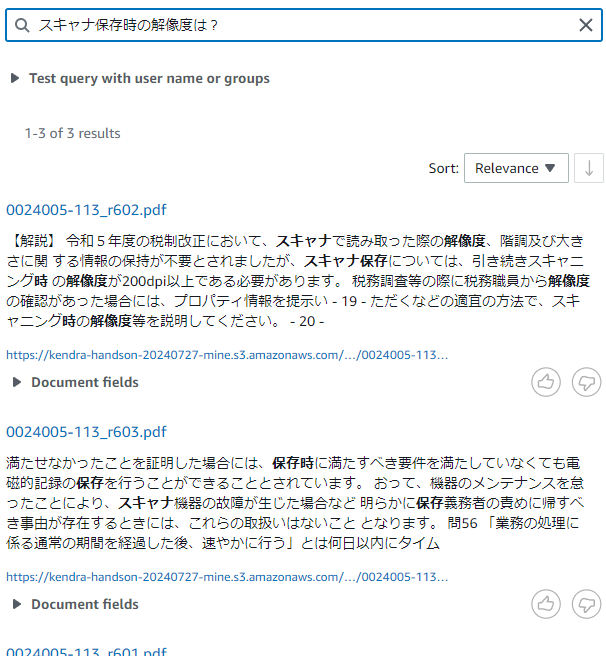
-
「請求書をデータベースに保存できますか?」と聞いてみたら、こうなりました。
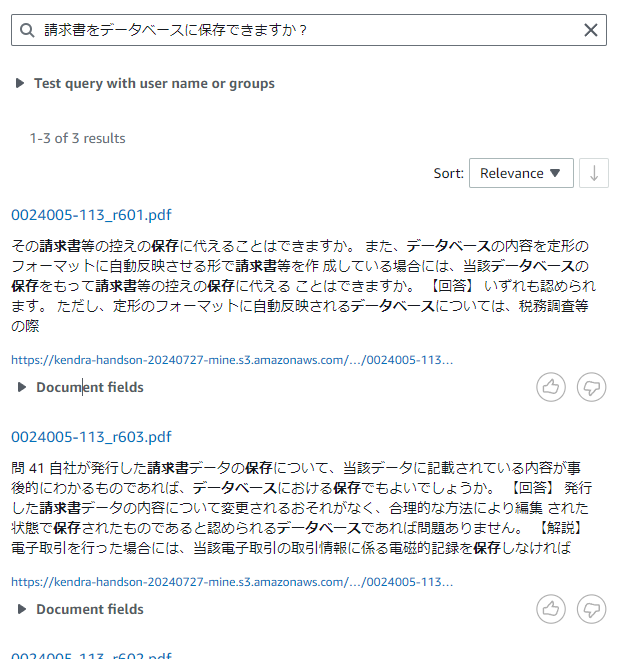
一応、期待するPDFファイルから期待する回答を選んできているから、合っているような気がします。
まとめ
調べるのにめんどくさい法律関連も、これで調べやすくなるような気がします。ただこれだけだとただの検索システムなので、もう一歩進めたいです。
(感覚的には、キーワード検索から自然言語検索になっただけ)
例えば、自社サービスの情報も突っ込み、LLMと組み合わせれば「自社サービスは電子帳簿保存法に適合してますか?」とか質問できるような気がします。そこまでいければ「使える」と言えるのではないかと思います。
(期待しすぎかな?)
よし、次はBedrockを勉強して、RAGを実現しよう!