RAGに興味が出てきたので、その実現の第一歩として「Amazon Kendra」の勉強をしてみることにしました。
大規模言語モデル (LLM) と組み合わせて使用することで、ユーザー向けに安全な生成系AIを活用した会話体験を迅速に作成できるらしいです。
参考とするのは、AWSのハンズオン「Amazon Kendra で簡単に検索システムを作ろう!」になります。
Amazon Kendraとは
Amazon Kendraは、機械学習を活用したエンタープライズ向けのマネージド検索サービスです。
Amazon Kendraを利用することで、Amazon S3やGoogleドライブなどインターネット上のデータや自社内のデータなど、様々な場所に散らばっているデータやドキュメントから、自然言語を使って必要な情報を効率的に検索することが可能になります。
また、AWS CLIやAPIからAmazon Kendraを利用することで、アプリケーションやWebサイトに簡単に検索システムを組み込むことも可能です。
構成
こんな感じのものを作るようです。

インデックスの作成
まずはAmazon Kendraでインデックスを作成します。
ここからはマネージメントコンソールから作業を行います。
今回、リージョンは「バージニア北部」で行います。(応用編で利用するファイルの都合)
リージョンを確認したら、Amazon Kendraサービスに入ります。

初めに、右上の「Create an Index」を選択します。
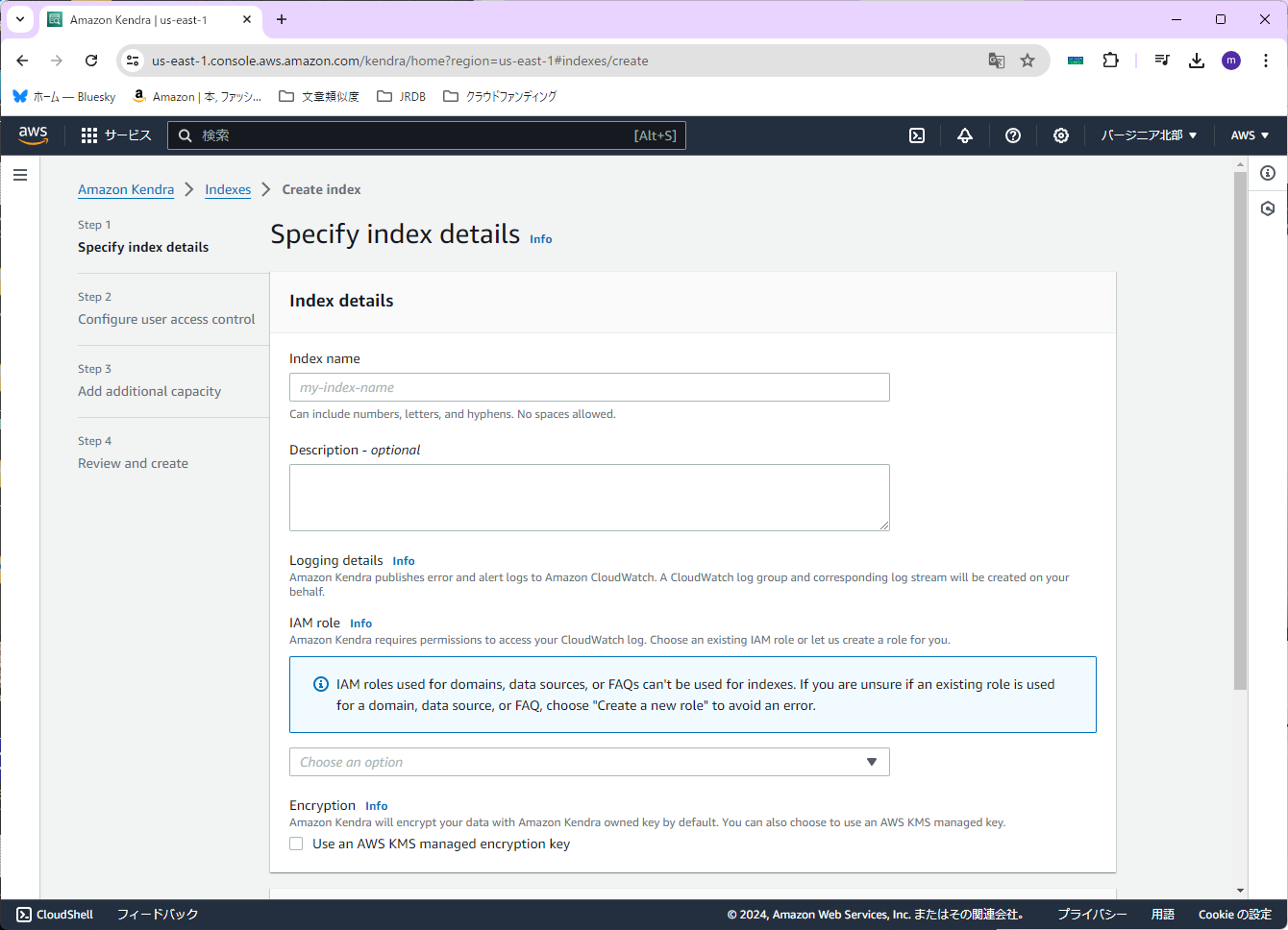
まず、「Index name」を設定します。今回は「Handson-index」とします。
次に「IAM role」を設定します。今回は「Create a new role (Recommended)」を選択します。さらに「Role name」を設定します。今回は「Handson-index-Role」(実際には「AmazonKendra-us-east-1-Handson-index-Role」となる)と入力します。
なお今回は「Encryption」(暗号化キーの設定)は行いません。(Amazon Kendraのデフォルトの暗号化キーを使用するため)
ここまで設定したら、右下の「Next」を押します。

Access Controlの設定は、デフォルトのままとします。
なにも変更せずに、右下の「Next」を押します。

Editionの設定は、今回は本番用ではなく検証目的なので、「Developer edition」のままにします。
なにも変更せずに、右下の「Next」を押します。
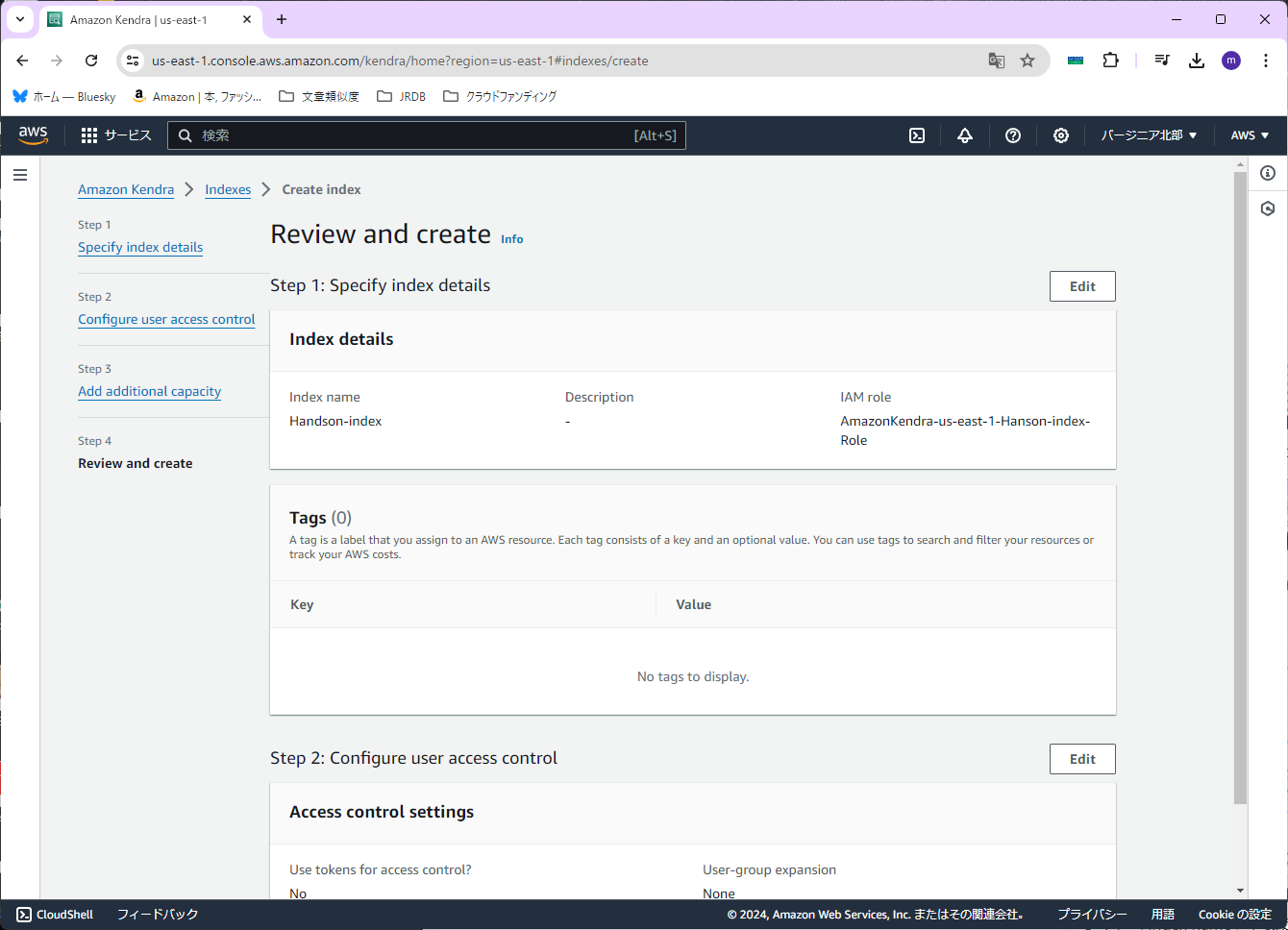
確認画面が出ますので、特に問題が無ければ、右下の「Create」を押します。
※画面が切り替わるのに、30秒ほどがかかります。

※インデックスの作成には数分かかります。

これでインデックスの作成は完了です。
ドキュメント(PDF)を取り込む
PDFファイルの準備
まずAmazon S3サービスに入ります。
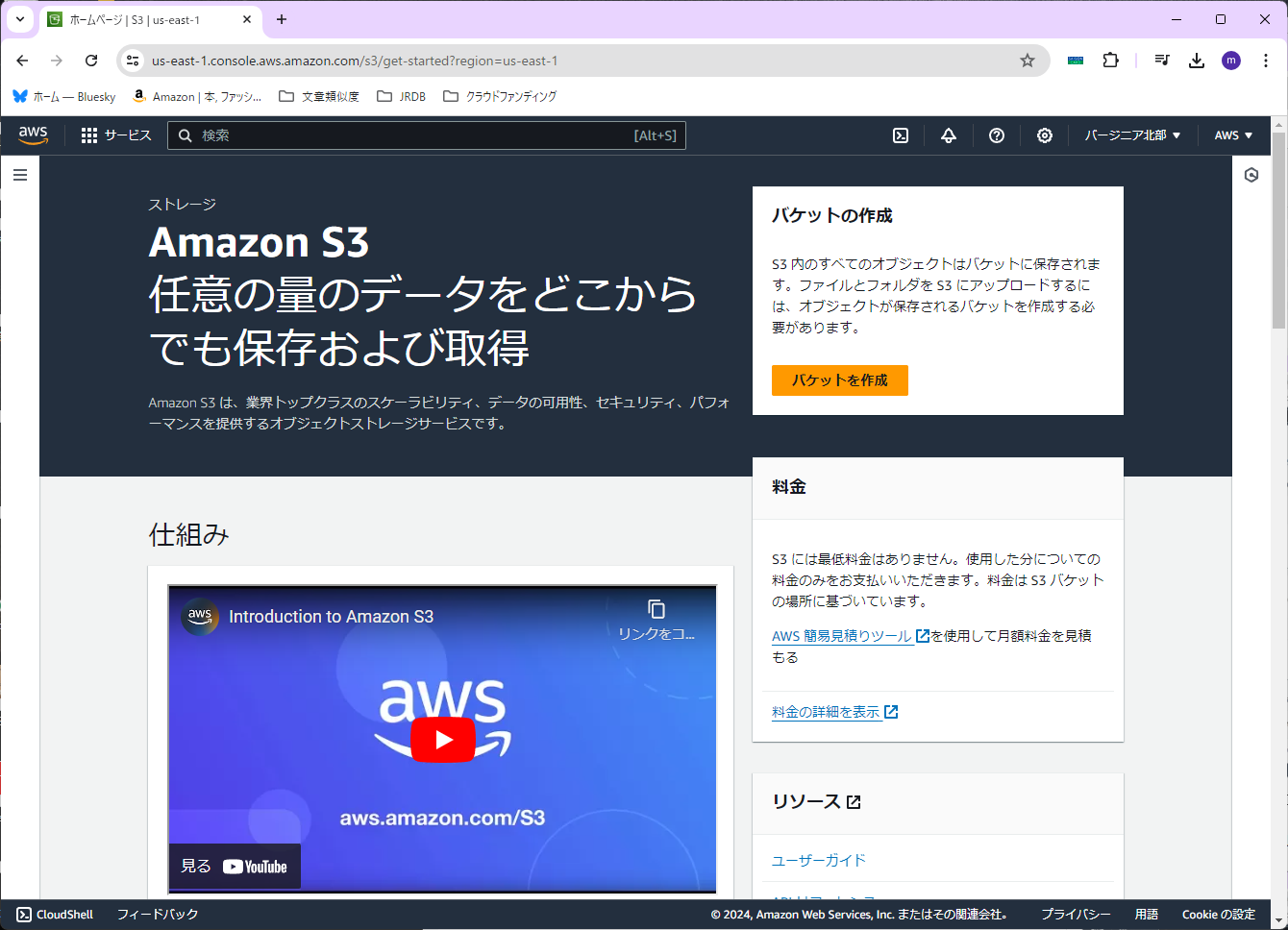
初めに、「バケットの作成」を押し、バケットを作成します。

念のため、「AWSリージョン」が「バージニア北部」になっていることを確認します。
次に、「バケット名」を入力します。今回は「kendra-handson-20240720-mine」とします。
他の設定はデフォルトのまま、右下の「バケットを作成」を押します。

次に、PDFファイルをアップロードします。右上のベルのマークの左にあるCloud Shellのマークを押します。
すると、Cloud Sellの画面が下に表示されます。

そこに、以下の内容をコピペします。
なお「BACKET_NAME」の値は、先ほど作成したバケット名を設定します。
# S3 バケット名を設定
BUCKET_NAME=kendra-handson-20240720-mine
# S3 バケットを作成
aws s3 mb s3://${BUCKET_NAME}
# AWS の公式ドキュメントの PDF ファイルをダウンロード
mkdir awsdoc
pushd awsdoc
wget https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-dg.pdf -O Lambda.pdf
wget https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-ug.pdf -O VPC.pdf
wget https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/kendra-dg.pdf -O Kendra.pdf
wget https://docs.aws.amazon.com/ja_jp/Route53/latest/DeveloperGuide/route53-dg.pdf -O Route53.pdf
popd
# S3 バケットに PDF ファイルをアップロード
aws s3 cp awsdoc s3://${BUCKET_NAME}/awsdoc/ --recursive
【注意】AWSのハンズオンの内容から1ファイル削除しています
複数行コピペすると確認ダイアログが出るので、「貼り付け」を押します。

最後まで実行されるのを待ちます。
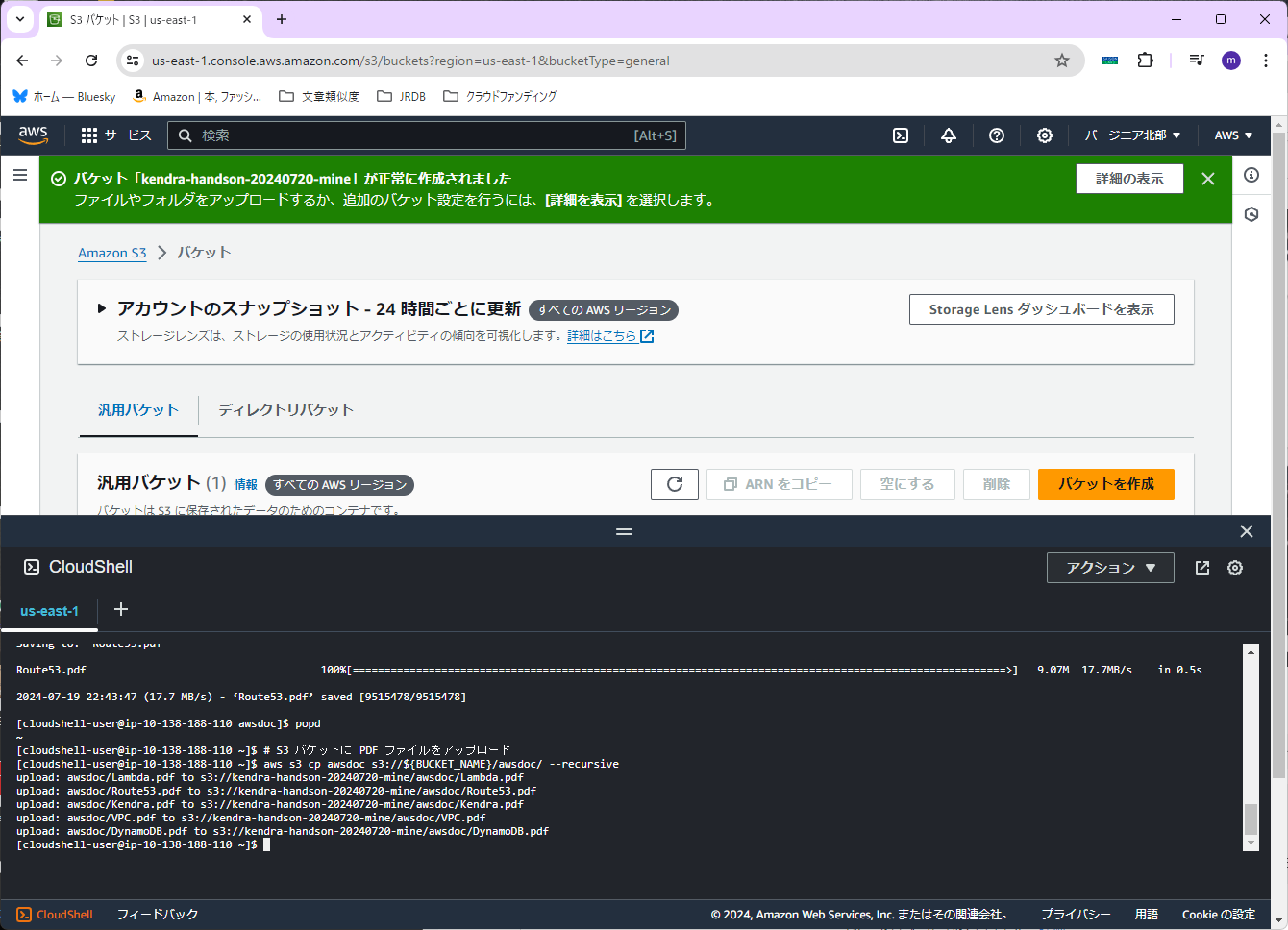
終わったら、「awsdoc」というフォルダがちゃんとできているか、その中にPDFファイルがあるかを確認します。


これでPDFファイルの準備ができました。
インデックスにPDFファイルの内容を取りこむ
Amazon Kendraサービスに戻ります。

左のメニューから「Data sources」を選びます。

利用できるコネクタから、Amazon S3を選びます。Amazon S3 connectorの「Add connector」を押します。

次に、「Data source name」を設定します。今回は、「Handson-S3-Connector」と入力します。
次に、「Default language」を設定します。今回のPDFファイルは日本語なので、「Japanese (ja)」を選択します。
右下の「Next」を押します。
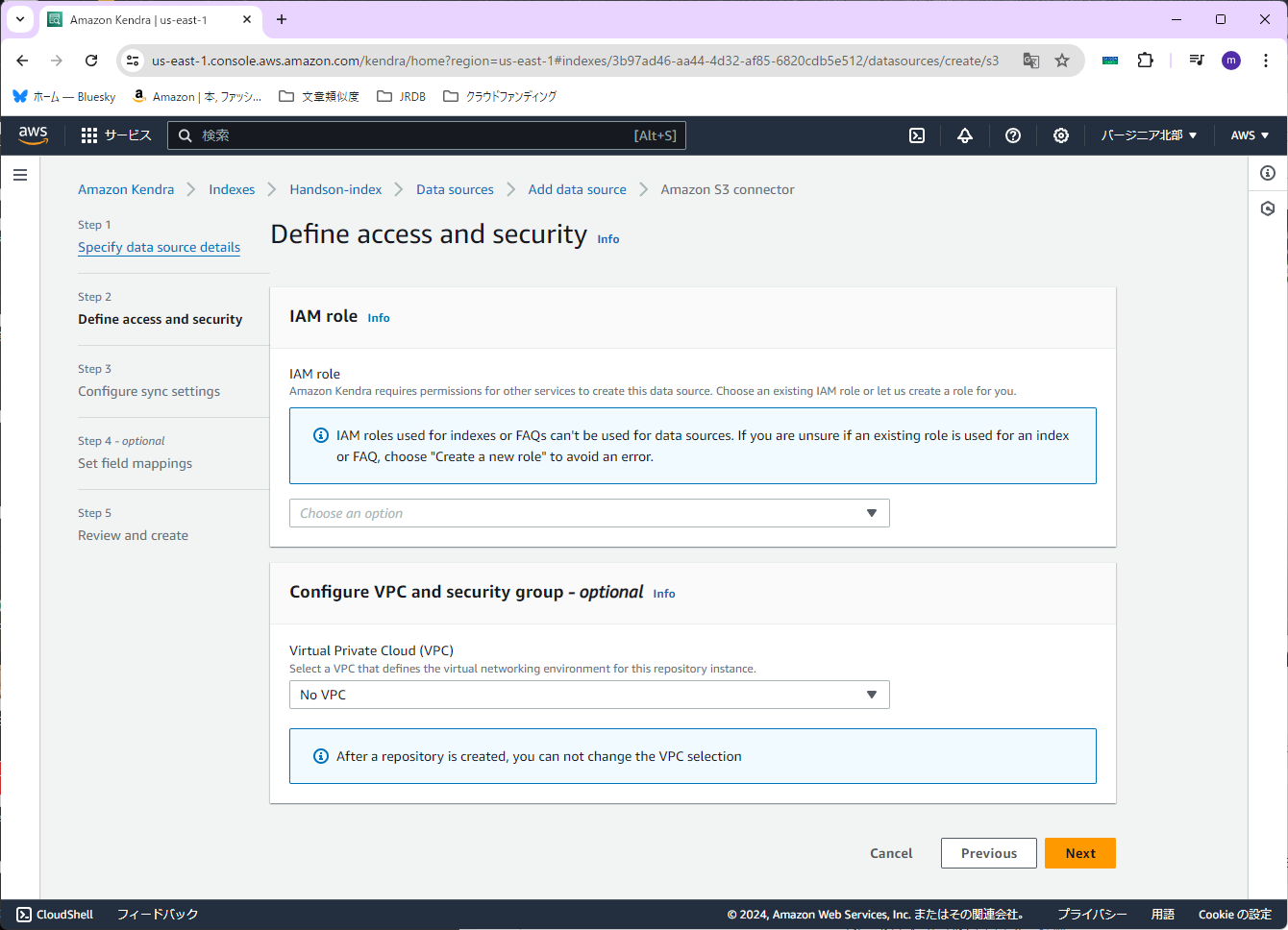
次に、「IAM role」を設定します。今回は「Create a new role (Recommended)」を選択します。「Role name」は「Handson-S3-Connector」(実際には「AmazonKendra-Handson-S3-Connector」となる)と入力します。
右下の「Next」を押します。

次に「Enter the data source location」を設定します。「Browse S3」を押し、先ほど作成したS3バケットを選択します。

次に「Sync run schedule」を設定します。今回は取り込むPDFファイルの変化が無いので「Run on demand」を選択します。
他の項目はデフォルトのままで、右下の「Next」を押します。

この画面はデフォルトのまま、右下の「Next」を押します。
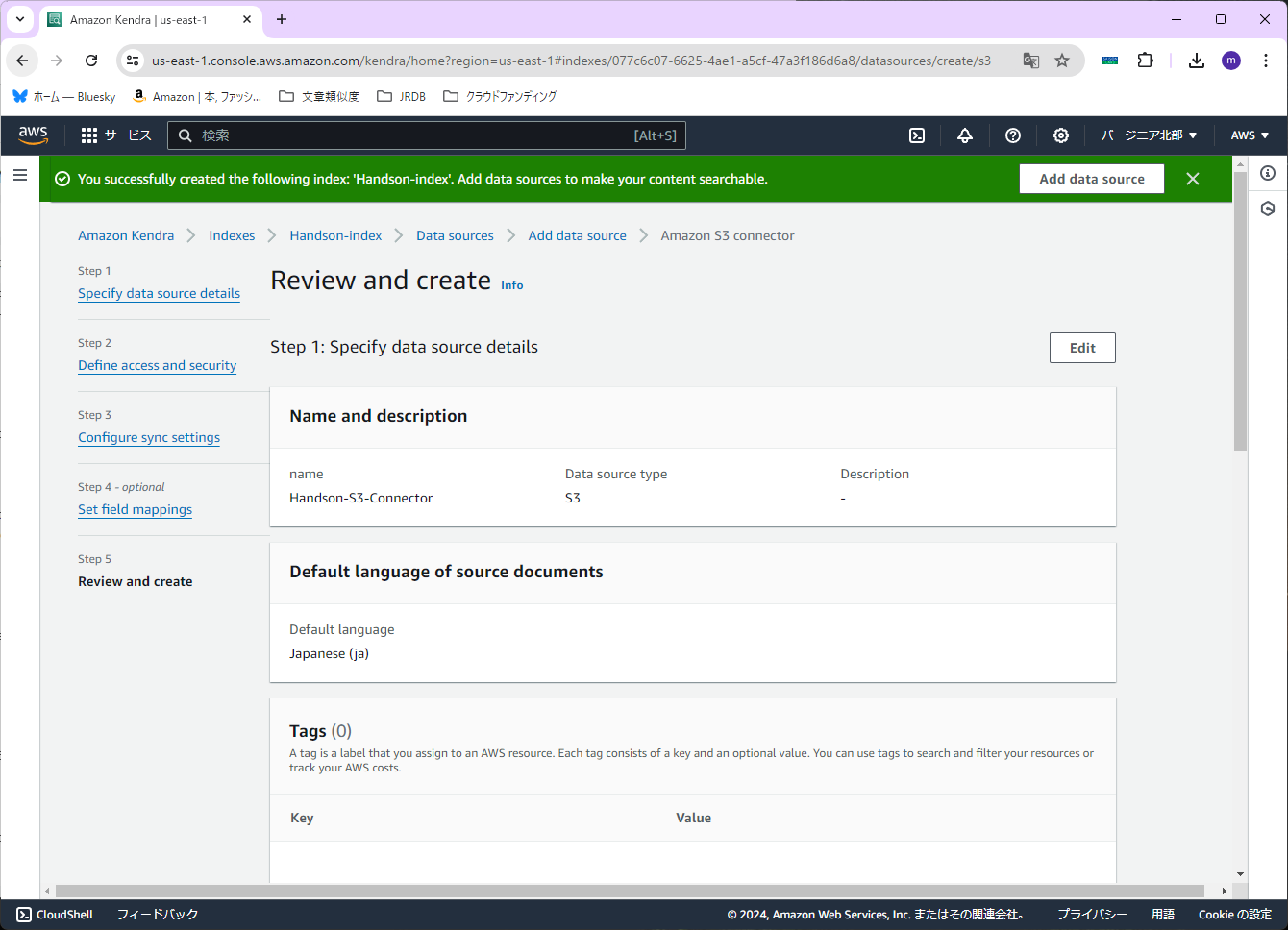
確認画面が出ますので、特に問題が無ければ、右下の「Add data source」を押します。
※画面が切り替わるまで、30秒ほどかかります

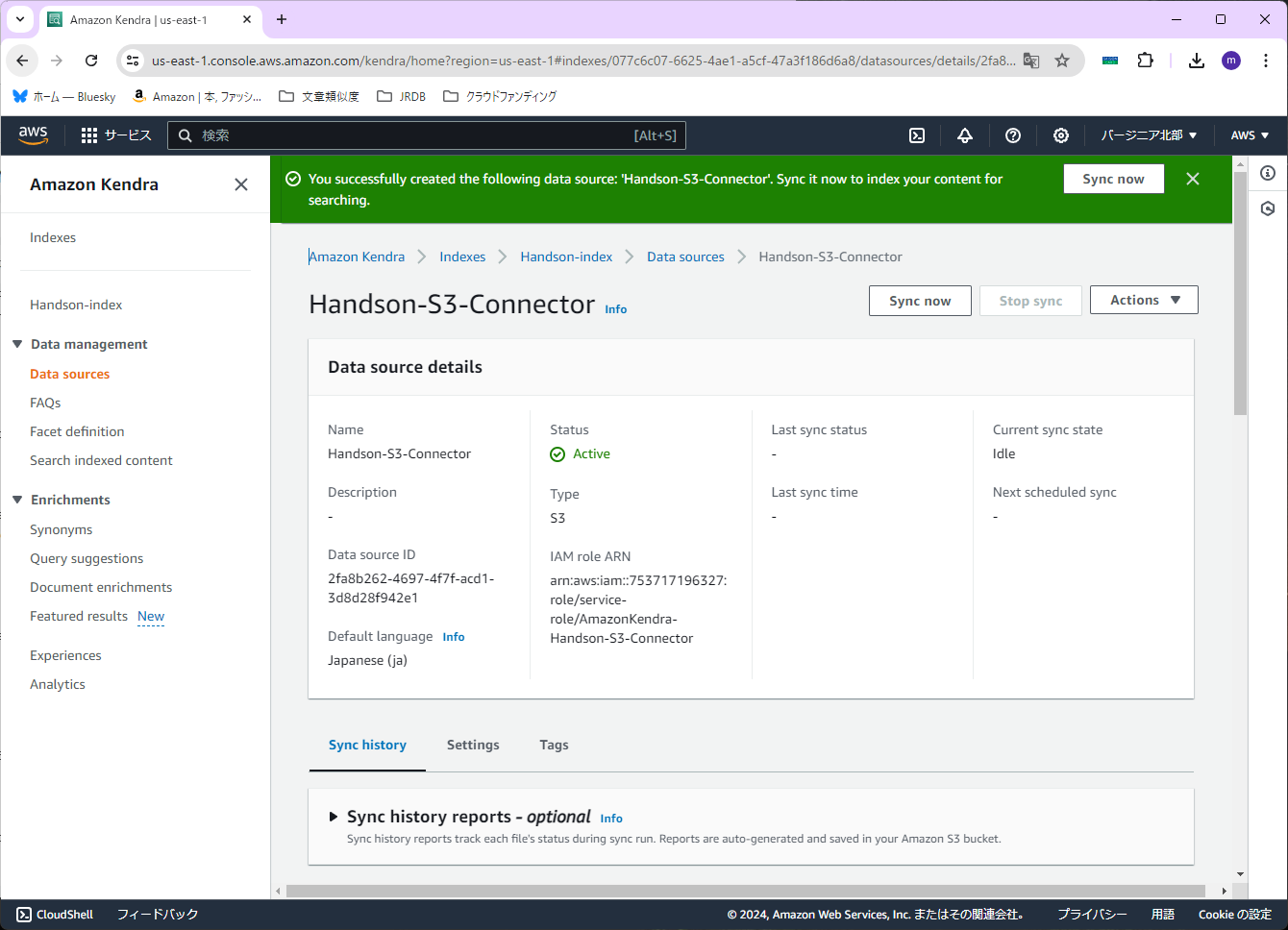
コネクタが作成できたら、右上の「Sync now」を押します。
※データの取り込みが終わるまで、結構時間がかかります
※取り込めるドキュメントのサイズに制限があるので気を付けてください(ハンズオンの通りにやったらエラーになった)
{
"DocumentId": "s3://kendra-handson-20240720-mine/awsdoc/DynamoDB.pdf",
"IndexName": "Handson-index",
"IndexID": "077c6c07-6625-4ae1-a5cf-47a3f186d6a8",
"SourceURI": "https://kendra-handson-20240720-mine.s3.amazonaws.com/awsdoc/DynamoDB.pdf",
"IndexingStatus": "DocumentFailedToIndex",
"ErrorMessage": "Extracted document content size 5.914343 MB is larger than Kendra supported size 5.000000 MB",
"ErrorCode": "400"
}
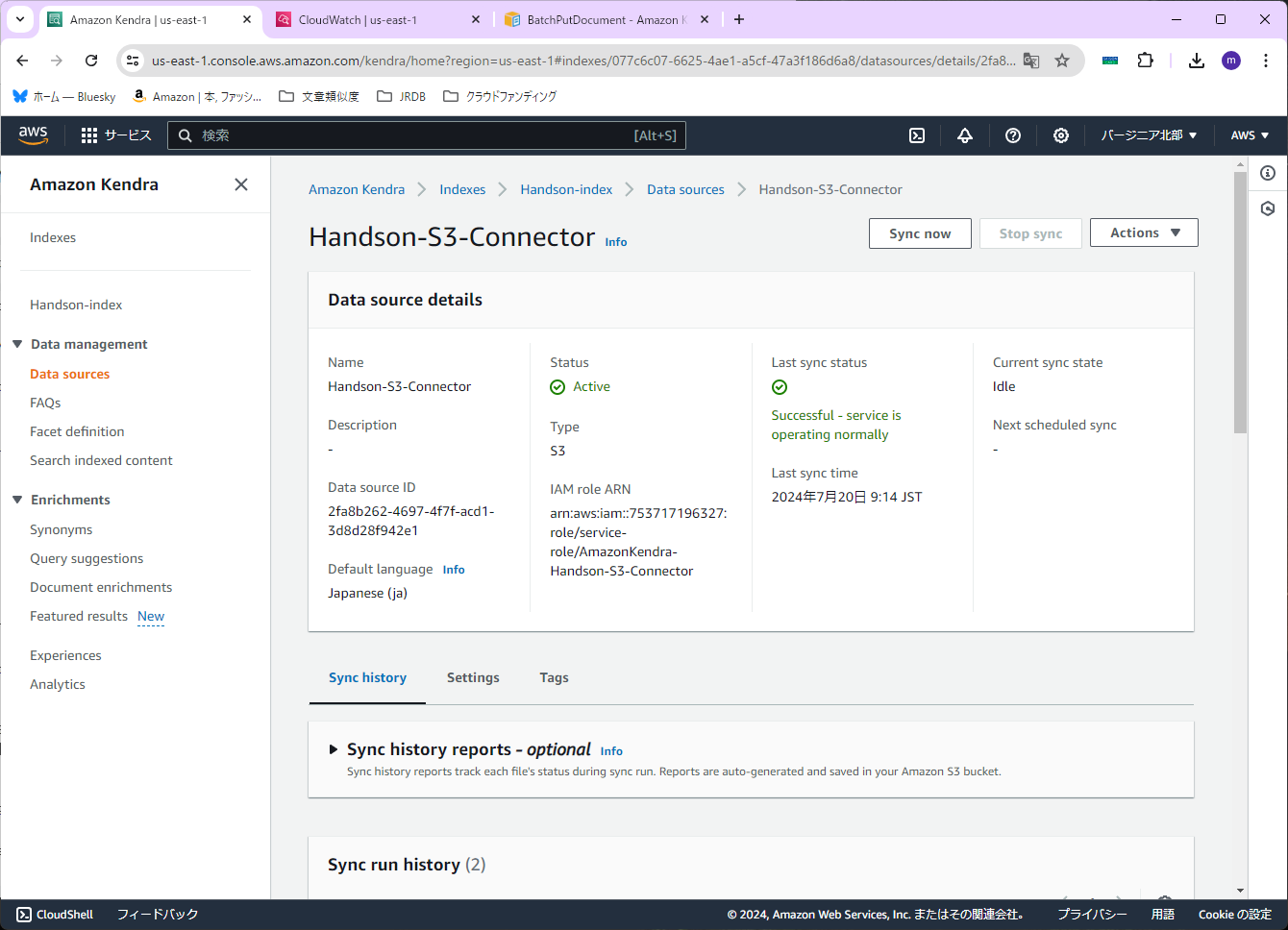
データの取り込みが終わったら、念のため、検索ができるか確認してみます。
左のメニューから「Search indexed content」を選びます。
検索する前に、右の上から3つ目のマーク(設定のマーク)を押します。
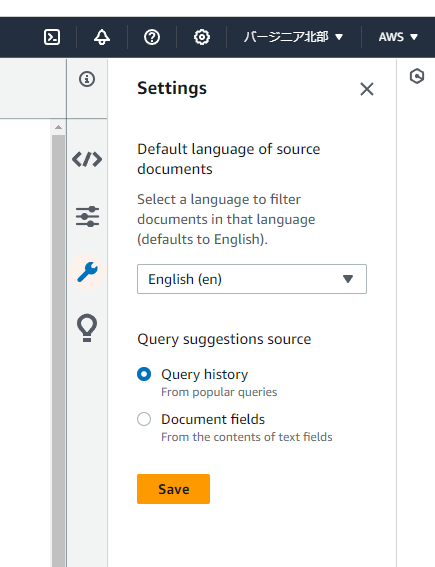
そこで「Default language of source documents」に「Japanese (ja)」を選択します。
(「Save」を押すことを忘れないように)
設定したら、早速検索してみます。今回は「Lambda関数で使用できるメモリの最大値は?」と聞いてみます。

???
答えがないですね...
本当はこんな感じの表示になるようです。

とりあえず気にしないでおきます。(いいのか?)
Webページから情報を取り込む
PDFと同様に、Amazon Kendraサービスの左のメニューから「Data sources」を選びます。

右上の「Add data source」を押します。
今度はAmazon S3ではなく、「Web Crawler(V2.0)」の「Add connector」を押します。
(ハンズオンではV1.0を使っているようです)

まず「Data source name」を設定します。今回は「web-crawler-ds」とします。
「Default language」もとりあえず「Japanese (ja)」の選んでおきます。
右下の「Next」を押します。

「Source URLs」を設定します。今回はS3とSagemakerのユーザーガイドを指定します。
URLはこちらです。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/Welcome.html
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html
入力欄は「Add Source URLs」を押すと追加できます。
次に「IAM role」を設定します。今回は「Create a new role (Recommended)」を選択します。「Role name」には「WebCrawler」(実際には「AmazonKendra-WebCrawler」になります)を設定します。
右下の「Next」を押します。

「Sync domain range」は「Sync domains only」を選んでおきます。
「Crawl depth」は「1」にしておきます。
「Sync run schedule」は、今回は1回だけ読み込めばいいので「Run on demand」にしておきます。
右下の「Next」を押します。

ここは変更なしで、右下の「Next」を押します。

確認画面が出ますので、特に問題が無ければ、右下の「Add data source」を押します。
※画面が切り替わるまで、30秒ほどかかります


コネクタが作成できたら、右上の「Sync now」を押します。
※データの取り込みが終わるまで、結構時間がかかります
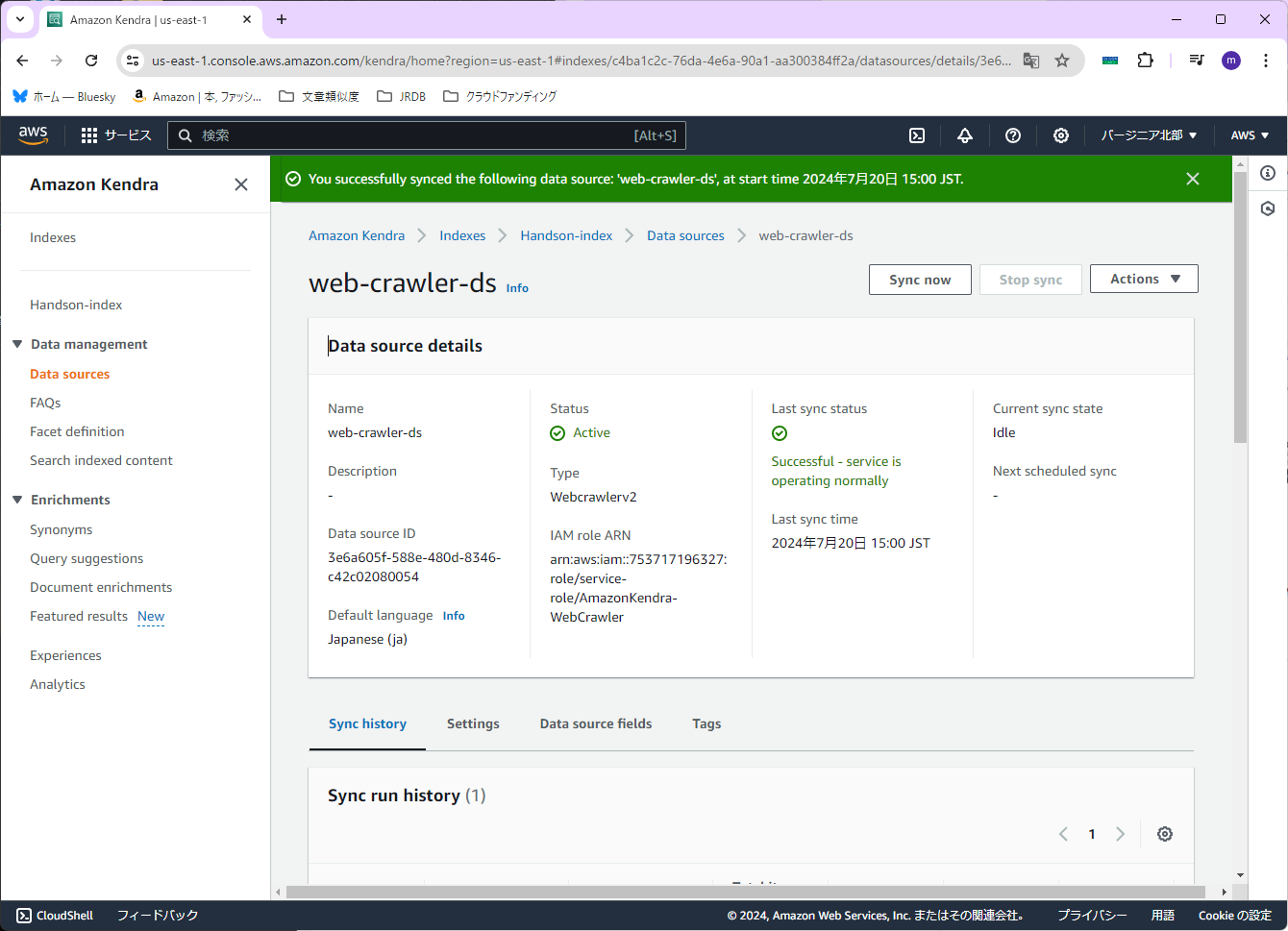
データの取り込みが終わったら、今回も検索ができるか確認してみます。
左のメニューから「Search indexed content」を選びます。
やはり今回も言語設定を日本語にします。右の上から3つ目のマーク(設定のマーク)を押します。
そこで「Default language of source documents」に「Japanese (ja)」を選択します。
(「Save」を押すことを忘れないように)
設定したら、検索してみます。今回は「S3 ストレージクラス」と聞いてみます。

今回はこれでよいみたいです。
Kendraを利用したWebアプリケーションを作ってみる
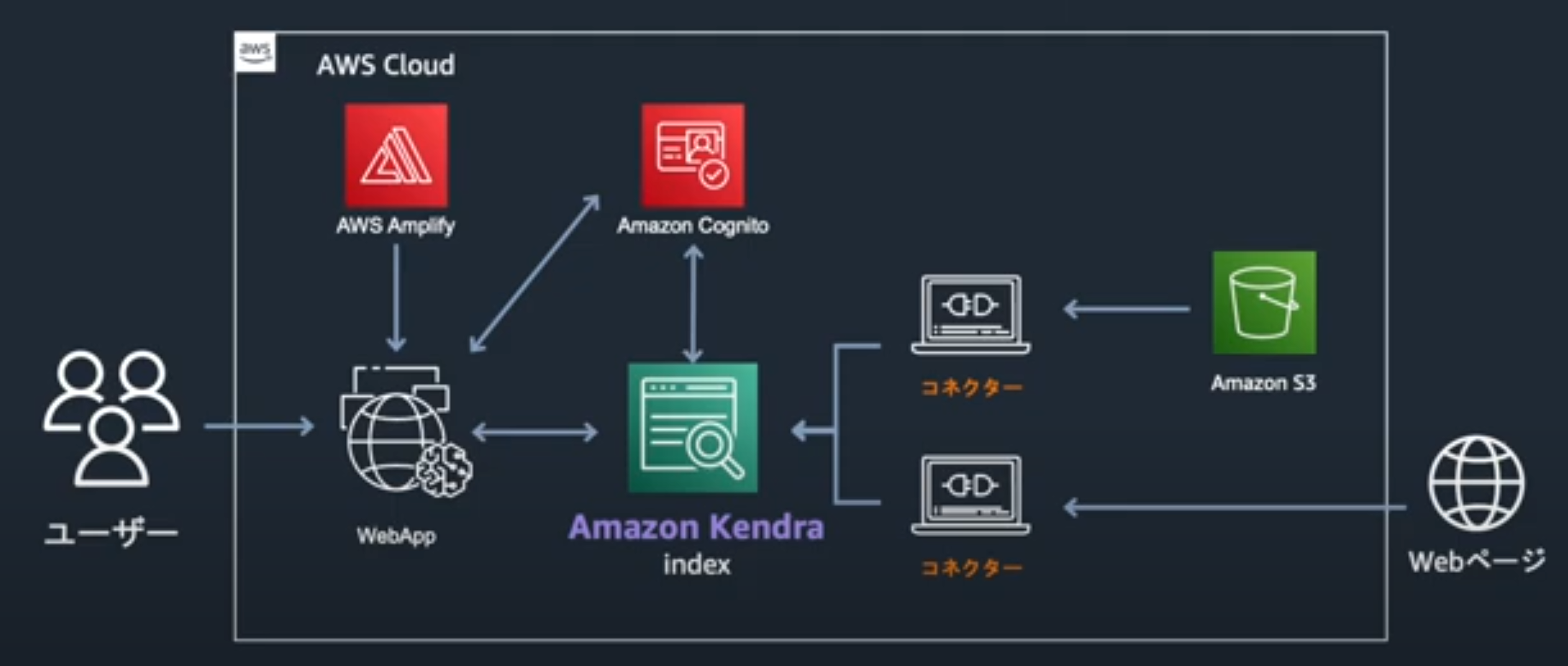
構成はこんな感じになるそうです。
CloudFormationで作成する
まずこちらのURLにアクセスします。するとCloudFormationの画面が表示されます。
既に設定されている「スタック名」の後ろに、日付を入力します。「MediaSearch-Finder-20240720」といった感じになります。
次に「KendraIndexId」を設定します。Kendraで作成したインデックス(今回は「Handson-index」)を開き、「Index settings」の「Index ID」の値を入力します。
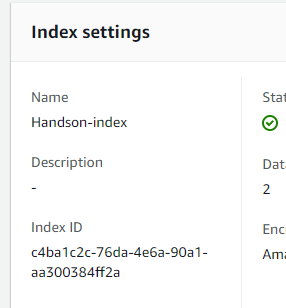
「MediaBucketNames」には、S3で作成したバケット名を入力します。

「AdminEmail」も設定します。パスワードが届きますので、ちゃんと受け取れるメールアドレスを設定します。
「EnableAccessTokens」は「true」に変更します。
最後に「AWS CloudFormation によって IAM リソースが作成される場合があることを承認します。」のチェックを入れます。
右下の「スタックの作成」を押します。
※完了するまでしばらく時間がかかります

完了(スタックに「CREATE_COMPLETE」と表示)したら、「出力」タブを押します。

「MediaSearchFinderURL」のURLを、新しいタブで開きます。

先ほど設定したメールアドレスにパスワードが届いているので、「Username」は「admin」と設定し、「SIGN IN」を押します。
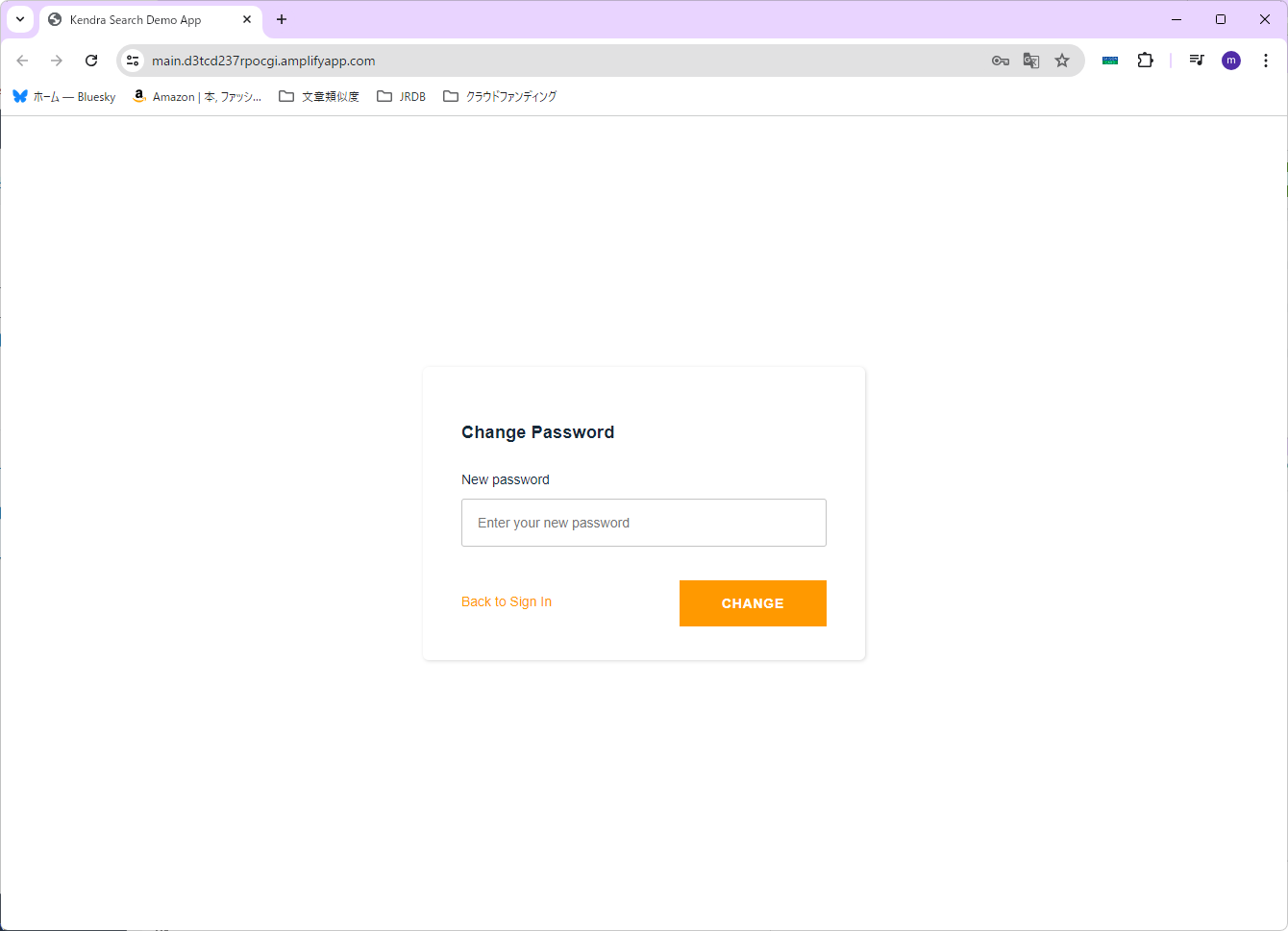
新しいパスワードを聞かれますので、設定して「CHANGE」を押します。
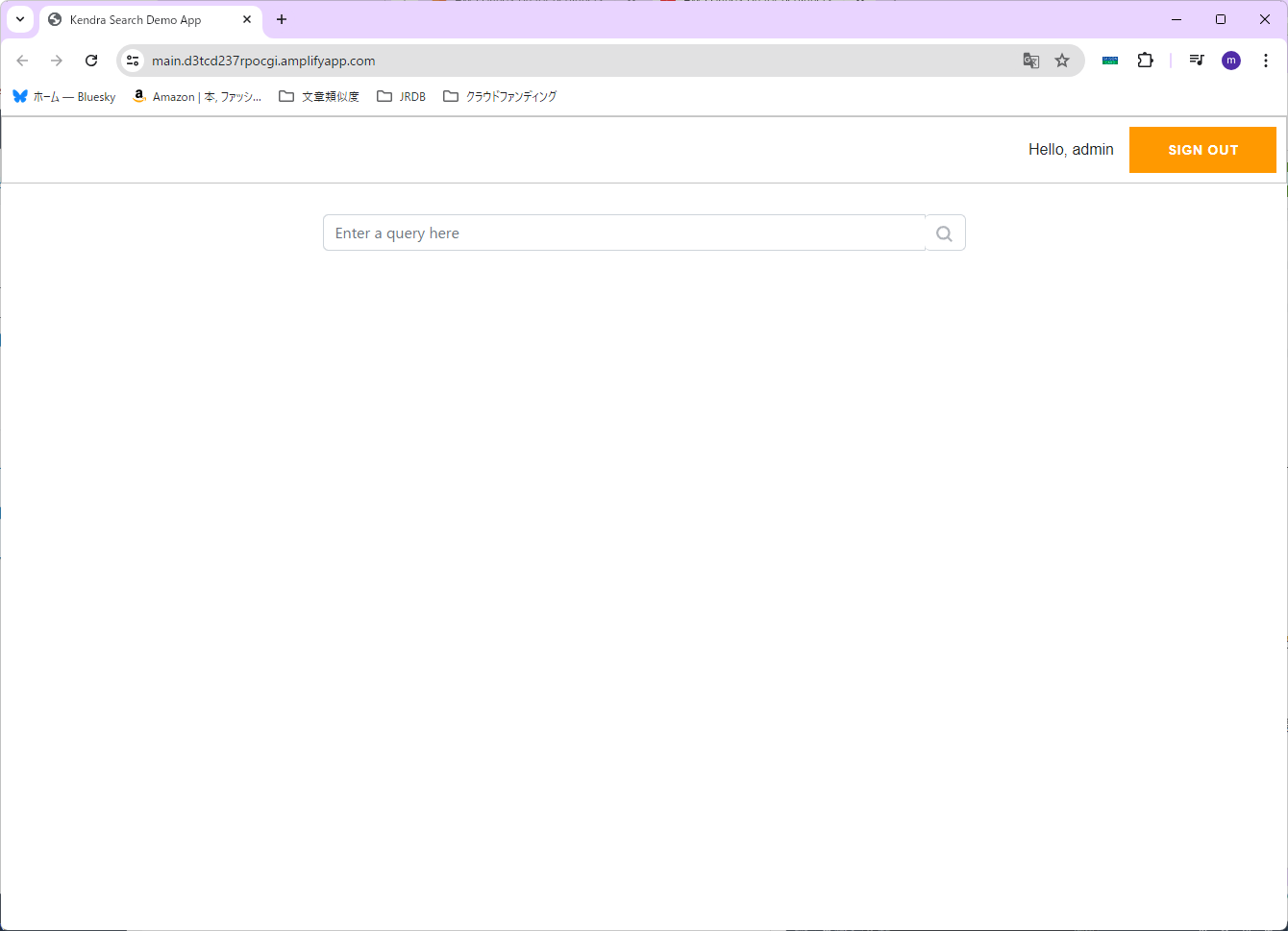
日本語対応する
用意されているCoudFormationの設定ままだと日本語で検索できないので、修正していきます。
CodeCommitサービスを開きます。

作成されているリポジトリをクリックし、その後「src」→「search」をクリックします。
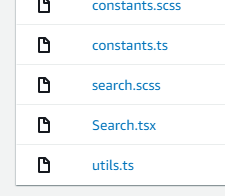
「Search.tsx」を開きます。

右上の「編集」ボタンを押し、ファイルの中身をこちらのファイルと置き換えます。
置き換えたら、「作成者」に名前を入力し、「Eメールアドレス」にちゃんと受け取れるメールアドレスを入力します。
右下の「変更のコミット」を押します。
しばらくすると修正が反映されるので、先ほどのアプリケーションのURLを再度開きます。
試しに「Lambda関数で使用できるメモリの最大量は?」と検索してみます。
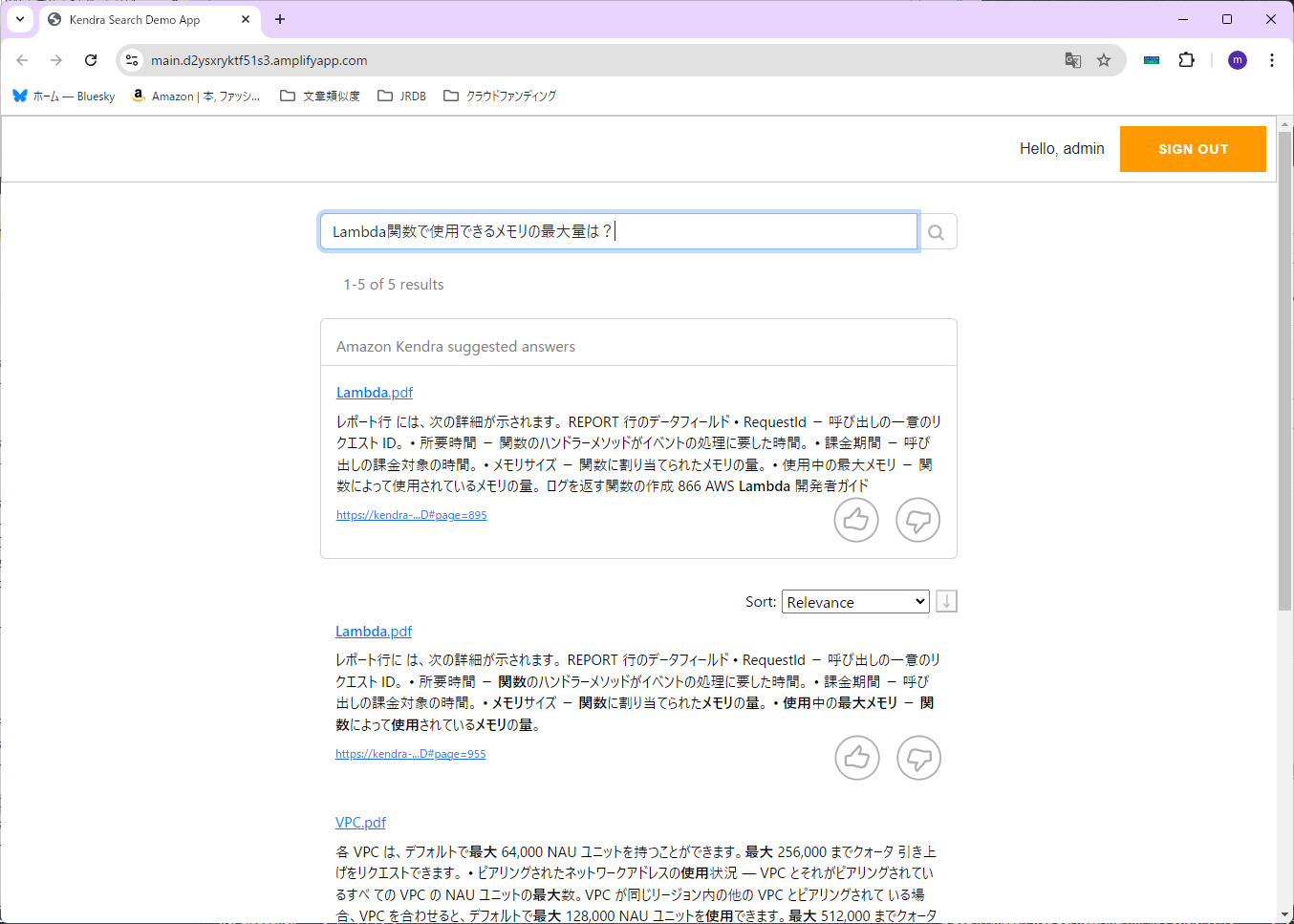
S3の時と同じ表示なので、良さそうな感じです。
お掃除
作成したリソースを削除していきます。
Amazon Kendra
まずAmazon Kendra Indexを削除します。
Amazon Kendraサービスを開き、作成したインデックスを選びます。

「Index settings」の「Delete」を押します。

削除する理由を選んで、「Delete」を押します。
Amazon S3
次にAmazon S3のバケットを削除します。
Amazon S3サービスを開き、作成したバケットをチェックします。
「空にする」を押して、まずバケットの中身を削除します。
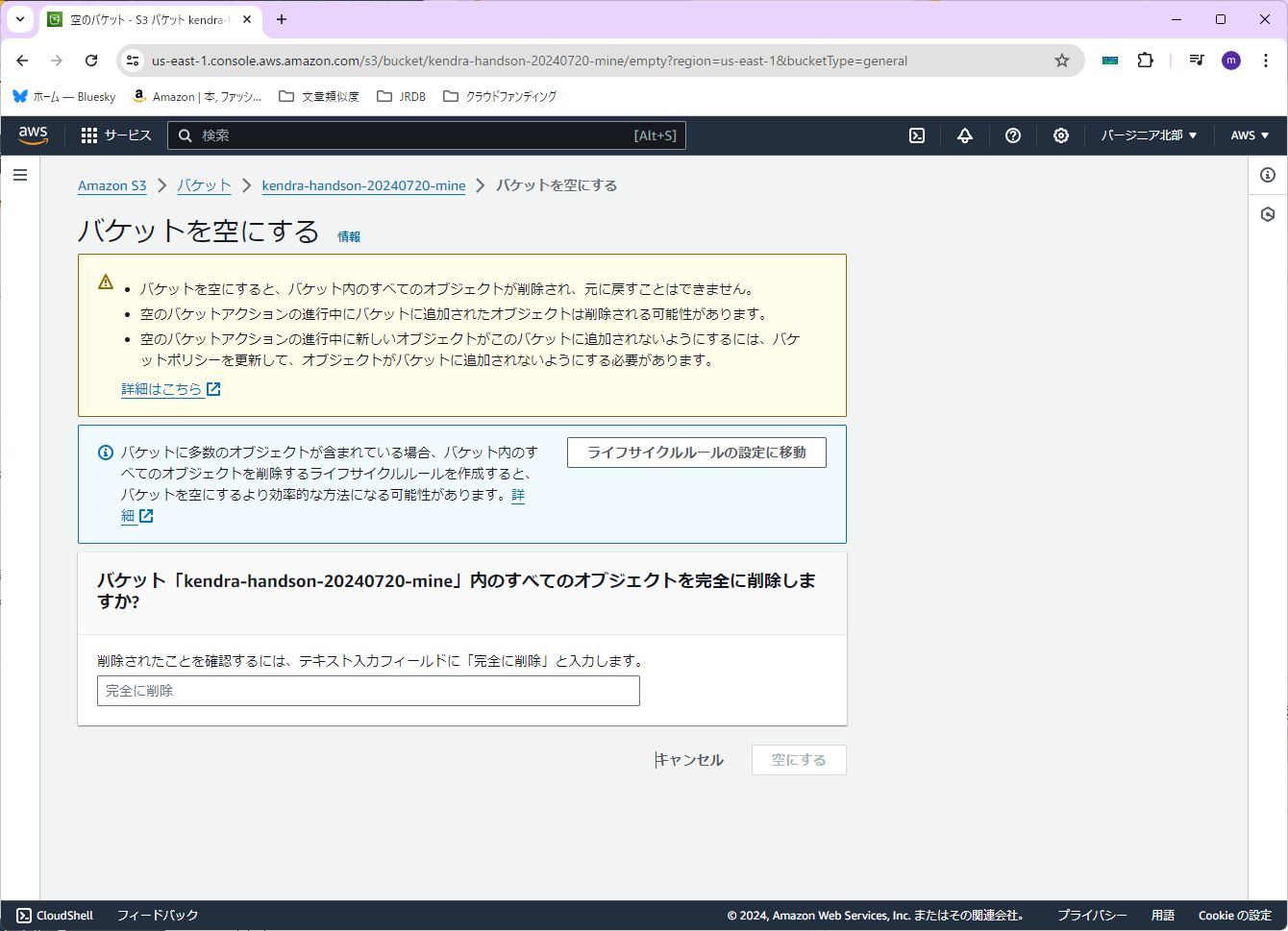
「完全に削除」と入力し、右下の「空にする」を押します。

右上の「終了」を押します。
再度バケットを選択し、今度は「削除」を押します。

バケット名を入力し、右下の「バケットを削除」を押します。
CloudFormation
次にCloudFormationのスタックを削除します。
CloudFormationサービスを開き、作成したスタックを選びます。
右上の「削除」を押します。

「削除」を押します。
CloudWatch
次にCloudWatchロググループのログを削除します。
CloudWatchサービスを開き、ロググループを表示します。

今回作成したロググループをすべて選択し、右上の「アクション」-「ロググループの削除」を選択します。

「削除」を押します。
IAM
最後にIAMロールの削除を行います。
IAMサービスを開き、ロールを表示します。

今回作成したロールを選択し、「削除」を押します。

「削除」と入力し、「削除」を押します。
まとめ
それなりにうまくいき、なんとなくイメージはつかめました。
これを踏まえて、最終的にはRAGの実装を目指したいと思います。