Googleによるセマンティックイメージセグメンテーションの最新版(2018/07時点)である「DeepLab v3+」の論文「Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation」を、なるべくわかりやすく意訳してみます。
一応、Googleの説明記事も参考にします。
※Google翻訳をふんだんに使用しています
セマンティックイメージセグメンテーションのためのAtrous畳み込み分解を有するエンコーダ-デコーダ
Liang-Chieh Chen、Yukun Zhu、George Papandreou、Florian Schroff、Hartwig Adam
Google社
要旨
空間ピラミッドプーリングモジュールまたはエンコード-デコード構造は、セマンティックセグメンテーションタスクのためのDNNで使用されています。前者のネットワークは、入ってくる特徴をフィルタまたは複数の有効な視野でフィルタリングまたはプーリングすることによってマルチスケールのコンテキスト情報を符号化することができ、後者のネットワークは空間情報を徐々に回復することによってよりシャープなオブジェクト境界を取得できます。
この論文では、両方の方法の利点を組み合わせることを提案します。具体的には、提案されているDeepLab v3+モデルはDeepLab v3を拡張し、特にオブジェクト境界に沿ったセグメンテーション結果を洗練するためのシンプルで効果的なデコーダモジュールを追加しました。さらに、Xceptionモデルを調査し、深度方向畳み込み分解をAtrous分離可能ピラミッドプーリングとデコーダモジュールの両方に適用することで、より高速で強力なエンコーダ-デコーダネットワークを実現しました。
我々は、PASCAL VOC 2012セマンティックイメージセグメンテーションデータセットに提案されたモデルの有効性を実証し、後処理なしでテストセットにおいて89%の性能を達成しました。
私たちの論文には、Tensorflowの提案されたモデルの公開された参照実装がhttps://github.com/tensorflow/models/tree/master/research/deeplabにあります。
1.はじめに
画像内のすべてのピクセルにセマンティックラベルを割り当てるという目的のセマンティックセグメンテーションは、コンピュータビジョンにおける基本的なトピックの1つです。Fully畳み込みニューラルネットワークに基づくDeep畳み込みニューラルネットワークは、ベンチマークタスクで手作業に頼っている仕組みを大幅に改善します。
本研究では、空間ピラミッドプーリングモジュールやエンコーダ-デコーダ構造を用いてセマンティックセグメンテーションを行う2種類のニューラルネットワークを考えます。前者は異なる解像度の特徴をプーリングして豊かな文脈情報を獲得し、後者は鮮明なオブジェクト境界を得ることができます。
DeepLab v3では、複数のスケールでコンテキスト情報をキャプチャするために、異なるレートのいくつかの並列Atrous畳み込みを適用します(Atrous空間ピラミッドプーリングまたはASPPと呼ばれます)。PSPNetでは異なるグリッドスケールでプーリングを実行します。
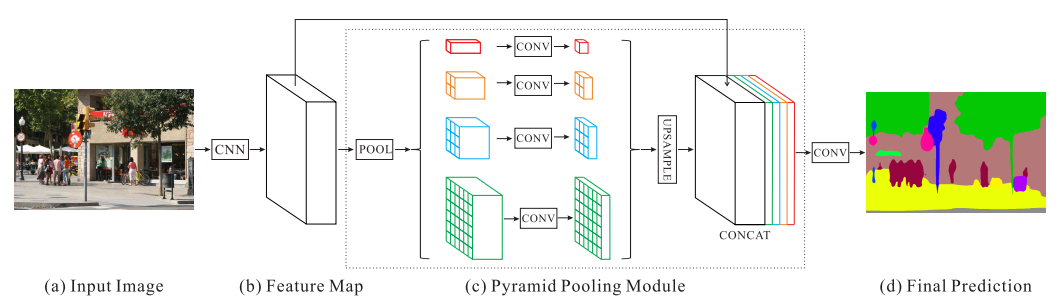
[参考]https://arxiv.org/abs/1612.01105
豊富なセマンティック情報が最後の特徴マップでエンコードされていても、ネットワークのバックボーン内でストライドを伴うプーリングまたは畳み込みのために、オブジェクト境界に関連する詳細情報が欠落しています。これは、より緻密な特徴マップを抽出するためにatrous畳み込みを適用することによって軽減することができます。
しかしながら、最先端のニューラルネットワークと限られたGPUメモリの設計を考えると、入力解像度より8倍、または4倍小さい出力特徴マップを抽出することは計算上禁止されています。たとえば、ResNet-101を使用して、入力分解能より16倍小さい出力特徴を抽出するためにatrous畳み込みを適用する場合、最後の3つの残差ブロック(9つのレイヤ)内の特徴を拡張する必要があります。さらに悪いことに、入力より8倍小さい出力特徴が望まれる場合、26個の残差ブロック(78個のレイヤ!)が影響を受けます。したがって、このタイプのモデルに対してより高密度の出力特徴が抽出されると、計算集約的になります。
一方、エンコーダ-デコーダモデルは、エンコーダ経路内で(特徴が拡張されないので)より高速な計算に役立ち、デコーダ経路内の鋭いオブジェクト境界を徐々に回復します。
両方の方法の利点を組み合わせようとすると、我々は、マルチスケールコンテキスト情報を組み込むことによって、エンコーダ-デコーダネットワーク内のエンコーダモジュールを豊かにすることを提案します。
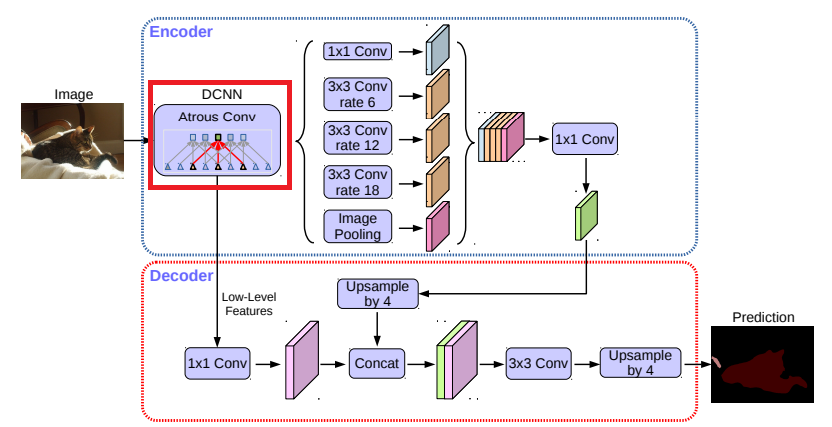
特に、DeepLab v3+と呼ばれる我々の提案するモデルは、【図1】に示すように、オブジェクト境界を復元するための単純で効果的なデコーダモジュールを追加することによりDeepLab v3を拡張しています。
豊富なセマンティック情報はDeepLab v3の出力でエンコードされており、計算資源の予算に応じてエンコーダの特徴の密度を制御することができます。 さらに、デコーダモジュールは、詳細なオブジェクト境界回復を可能にします。
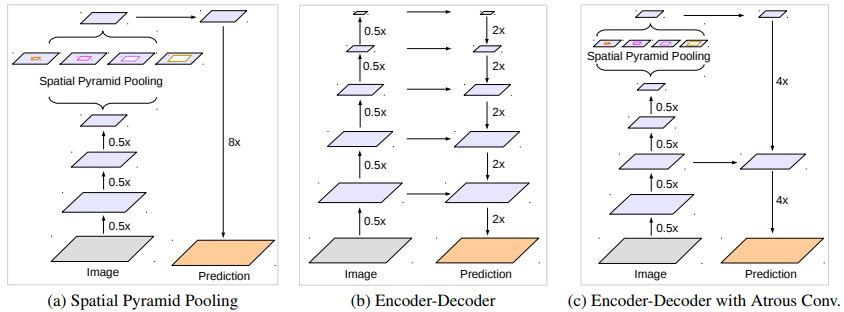
【図1】我々は、空間ピラミッドプーリングモジュール(a)を使用し、エンコーダ-デコーダ構造(b)を用いたDeepLab v3を改良することを提案します。
提案されたモデルDeepLab v3+は、エンコーダモジュールからの豊富なセマンティック情報を含み、詳細なオブジェクト境界は、シンプルで効果的なデコーダモジュールによって回復されます。
エンコーダモジュールを使用することで、atrous畳み込みを適用して任意の解像度で特徴を抽出することができます。
最近の深度方向畳み込み分解の成功によって動機づけられ、「Deformable Convolutional Networks」と同様に、Xceptionモデルを適用させることによって、この操作を探索し、速度と精度の両方の点で改善を示します。
最後に、PASCAL VOC 2012セマンティックセグメンテーションベンチマークで提案モデルの有効性を実証し、後処理なしでテストセットで89.0%のパフォーマンスを達成し、新しい最先端技術を確立します。
要約すると、我々の貢献は以下の通りです。
- DeepLab v3を強力なエンコーダモジュールとシンプルで効果的なデコーダモジュールとして採用した新しいエンコーダ-デコーダ構造を提案します
- 本発明者らの提案するエンコーダ-デコーダ構造では、従来のエンコーダ-デコーダモデルでは不可能であったトレードオフ精度及びランタイムに対するatrous畳み込みによって、抽出された符号器特徴の解像度を任意に制御することができます
- セグメンテーションタスクのXceptionモデルを適用し、ASPPモジュールとデコーダモジュールの両方に深度方向畳み込み分解を適用することで、より高速で強力なエンコーダ/デコーダネットワークが実現します
- 提案されたモデルは、PASCAL VOC 2012データセットで新しい最先端のパフォーマンスを達成します。 また、デザインの選択肢やモデルのバリエーションについても詳細に分析します
- 提案モデルのTensorflowベースの実装は、https://github.com/tensorflow/models/tree/master/research/deeplabで公開されています
2.関連研究
すでに完全畳み込みネットワーク(FCN)はいくつかのセグメンテーションベンチマークで大幅な改善を示しています。
マルチスケール入力(すなわち、画像ピラミッド)を用いるものや、確率的なグラフィカルモデル(効率的な推論アルゴリズムを有するDenseCRFなど)を採用するものを含む、セグメント化のコンテキスト情報を利用するために提案されるいくつかのモデル変形があります。
本研究では、主に、空間ピラミッドプーリングとエンコーダ-デコーダ構造を使用するモデルについて議論します。
空間ピラミッドプーリング
PSPNetやDeepLabなどのモデルは、いくつかのグリッドスケール(画像レベルのプーリングを含む)で空間ピラミッドプーリングを実行したり、異なるレートで複数の並列atrous畳み込みを適用します(Atrous空間ピラミッドプーリング、またはASPP)。 これらのモデルは、マルチスケール情報を活用することによって、いくつかのセグメンテーションベンチマークで有望な結果を示しています。

[参考]http://www.iandprogram.net/entry/2016/02/15/200242
エンコーダ-デコーダ
エンコーダ-デコーダネットワークは、人間の姿勢推定、物体検出、およびセマンティックセグメンテーションを含む多くのコンピュータビジョンタスクにうまく適用されています。 典型的には、エンコーダ-デコーダネットワークは、(1)特徴マップを徐々に減少させ、より高い意味情報を捕捉するエンコーダモジュールと、(2)空間情報を徐々に回復するデコーダモジュールとを含みます。このアイデアを基にして、我々は、DeepLab v3をエンコーダモジュールとして使用し、よりシャープなセグメンテーションを得るためのシンプルで効果的なデコーダモジュールを追加することを提案します。
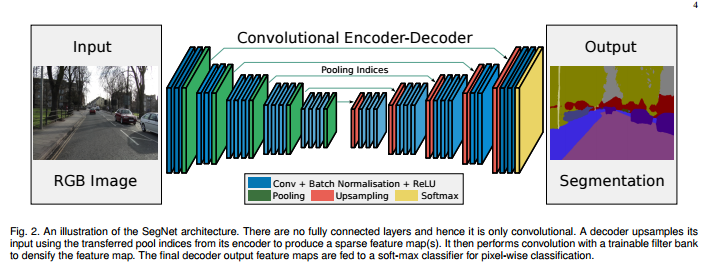
[参考]http://mabonki0725.hatenablog.com/entry/2017/04/19/113424
深度方向畳み込み分解
深度方向畳み込み分解またはグループ畳み込みは、同様の(またはわずかに優れた)パフォーマンスを維持しながら、計算コストおよびパラメータの数を削減する強力な操作です。この操作は、多くの最近のニューラルネットワーク設計で採用されています。特に、我々はCOCO2017検出チャレンジ提出の「Deformable Convolutional Networks」と同様のXceptionモデルを調査し、セマンティックセグメンテーションのタスクの精度と速度の両方の改善を示します。
[参考]http://machinethink.net/blog/googles-mobile-net-architecture-on-iphone/
3.方式
このセクションでは、Atrous畳み込みと深度方向畳み込み分解を簡単に紹介します。
次に、エンコーダ出力に付加された提案されたデコーダモジュールについて議論する前に、エンコーダモジュールとして使用されるDeepLab v3を検討します。
また、より高速な計算でパフォーマンスを向上させる変更されたXceptionモデルも提示します。
3.1. Atrous畳み込みを使用したエンコーダ-デコーダ
Atrous畳み込み
深い畳み込みニューラルネットワークによって計算された特徴の解像度を明示的に制御し、マルチスケール情報をキャプチャするためにフィルタの視野を調整することを可能にする強力なツールであるAtrous畳み込みは、標準畳み込み演算を一般化します。
特に、2次元信号の場合、出力特徴マップyおよび畳み込みフィルタw上の各位置iに対して、以下のように、入力特徴マップx上にatrous畳み込みが適用されます。
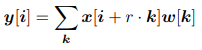
入力信号をサンプリングするストライドが決定されます。 私たちは興味のある読者に「DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs」を紹介します。
標準畳み込みはレートr = 1の特殊なケースであることに注意してください。フィルタの視野は、レート値を変更することによって適応的に変更されます。
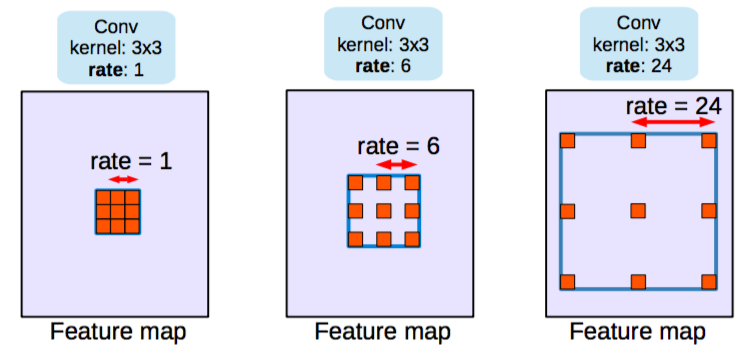
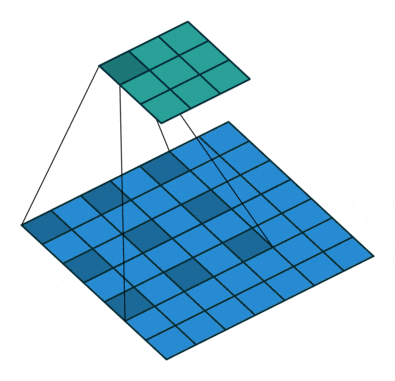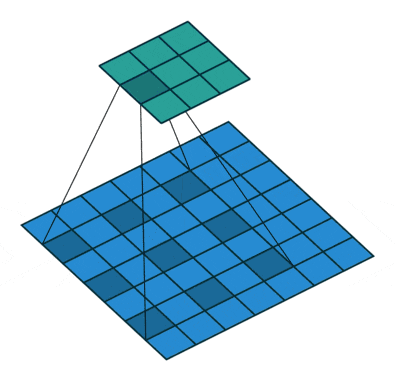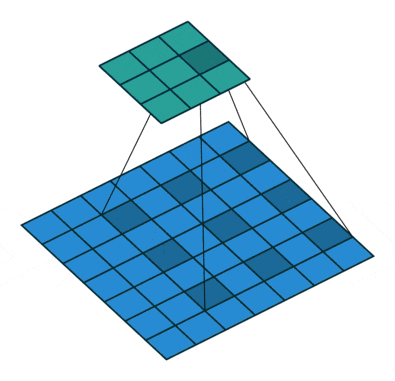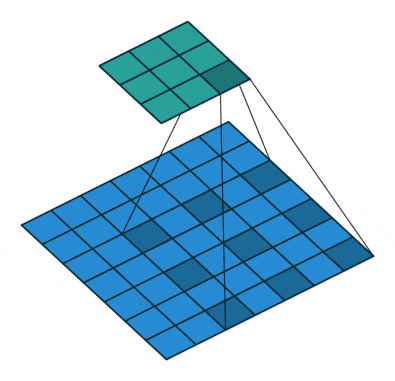
[参考]https://postd.cc/semantic-segmentation-deep-learning-review/
深度方向畳み込み分解
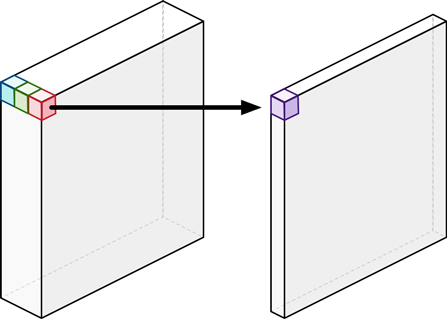
深度方向畳み込み分解、標準的な畳み込みを深さ方向の畳み込みに因数分解した後に点単位の畳み込み(すなわち、1×1畳み込み)が行われ、計算の複雑さが大幅に低減されます。具体的には、奥行き方向の畳み込みは、入力チャネルごとに独立して空間畳み込みを行い、点方向の畳み込みは、奥行き方向の畳み込みからの出力を結合するために使用されます。
深度方向畳み込み分解のTensorFlow実装では、奥行き方向の畳み込み(すなわち、空間畳み込み)においてatrous畳み込みがサポートされています。
本研究では、得られた畳み込みをAtrous畳み込み分解と呼んでおり、Atrous畳み込み分解が、類似した(またはより良い)性能を維持しながら、提案されたモデルの計算の複雑さを大幅に減少させることを見出しました。
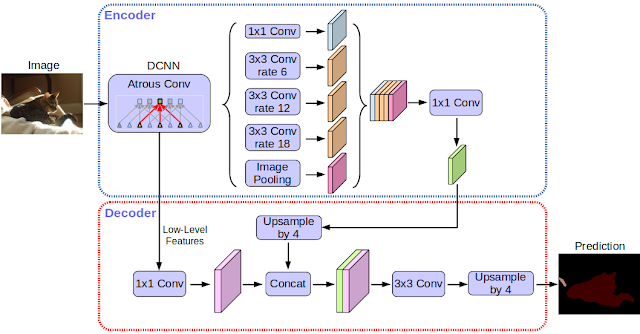
【図2】私たちの提案するDeepLab v3+は、DeepLab v3をエンコーダ/デコーダ構造を採用して拡張しています。エンコーダモジュールは、多スケールのatrous畳み込みを複数のスケールで適用することによってマルチスケールのコンテキスト情報をエンコードしますが、シンプルで効果的なデコーダモジュールはオブジェクト境界に沿ってセグメンテーション結果を緻密化します。
DeepLab v3のエンコーダ
DeepLab v3は、atrous畳み込みを用いて、深い畳み込みニューラルネットワークによって計算された特徴を任意の分解能で抽出します。ここでは、最終的な出力解像度(グローバルプーリングまたは完全接続レイヤより前)に対する入力イメージの空間解像度の比としての出力ストライドを示します。
画像分類のタスクでは、最終的な特徴マップの空間解像度は、通常、入力画像解像度よりも32倍小さいので、ストライド= 32を出力します。
セマンティックセグメンテーションのタスクでは、ストライドを除去することにより、より高密度の特徴抽出のために出力ストライド= 16(または8)を採用することができます。最後の1つ(または2つ)のブロックに対応して対応する畳み込みを適用します(例えば、出力ストライド= 8の場合、それぞれ最後の2つのブロックにレート= 2およびレート= 4を適用します)。
さらに、DeepLab v3は、Atrous空間ピラミッドプーリングモジュールを補強します。このモジュールは、画像レベルの特徴を用いて異なるレートのatrous畳み込みを適用することにより、複数のスケールで畳み込み特徴を調べます。
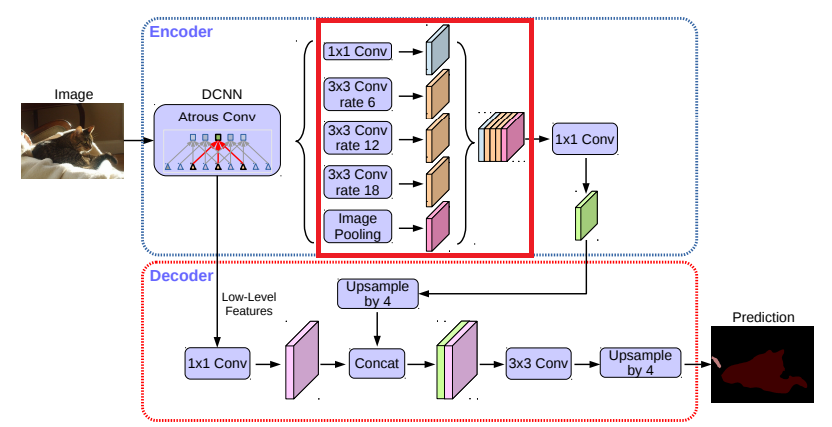
オリジナルのDeepLab v3のlogits前の最後の特徴マップを、提案するエンコーダ-デコーダ構造のエンコーダ出力とします。エンコーダが出力する特徴マップには、256チャネルと豊富な意味情報が含まれています。
また、計算予算に応じて、atrous畳み込みを適用することで、任意の解像度で特徴を抽出することができます。
提案するデコーダ
DeepLab v3のエンコーダ特徴は、通常、出力ストライド= 16で計算されます。
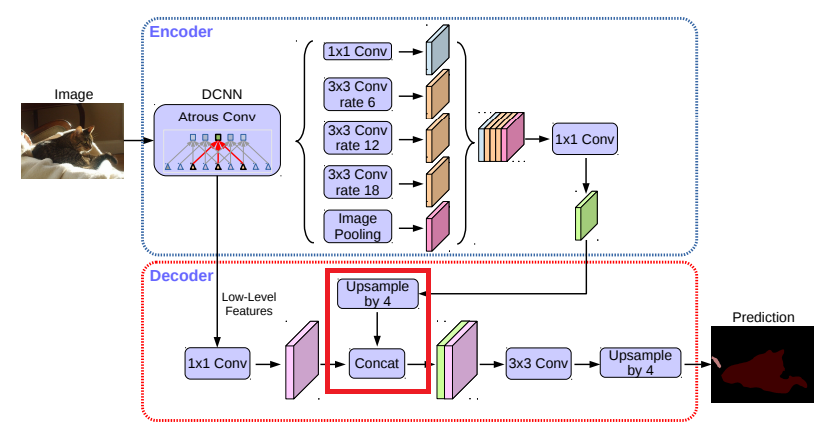
「Rethinking Atrous Convolution for Semantic Image Segmentation」の研究では、特徴は純粋なデコーダモジュールにより16の倍数でバイリニアアップサンプリングされます。しかし、この純粋なデコーダモジュールは、オブジェクトセグメンテーションの詳細なところを作成できないことがあります。そこで我々は、【図2】に示すように、シンプルで有効なデコーダモジュールを提案します。
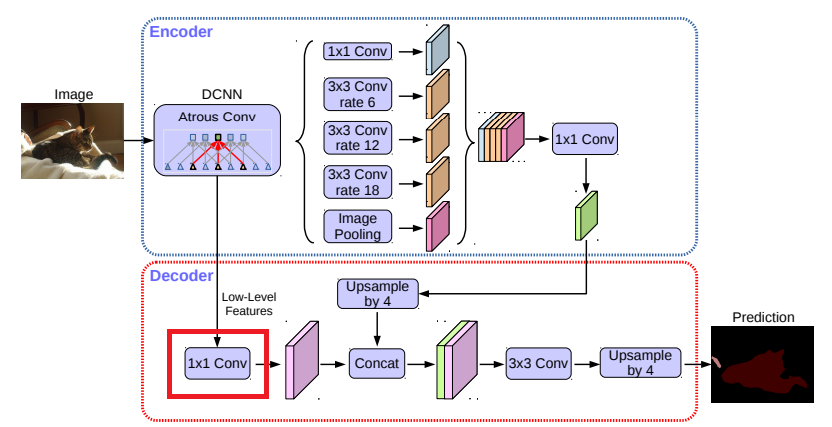
エンコーダ特徴は、最初に4倍にバイリニアアップサンプリングされ、同じ空間解像度を持つネットワークバックボーンから該当する低レベルの特徴(例えば、ResNet-101におけるストライドする前のConv2)と連結されます。
豊富なエンコーダ機能(我々のモデルでは256チャンネルのみ)の重要性を上回り、学習をより困難にする可能性がある多数のチャネル(例えば、256または512)を通常含むので、低レベルの特徴に1×1の畳み込みを適用してチャネル数を減らします。
連結後、少々3×3畳み込みを適用して特徴を改良し、その後に別の単純なバイリニアアップサンプリング4倍にします。
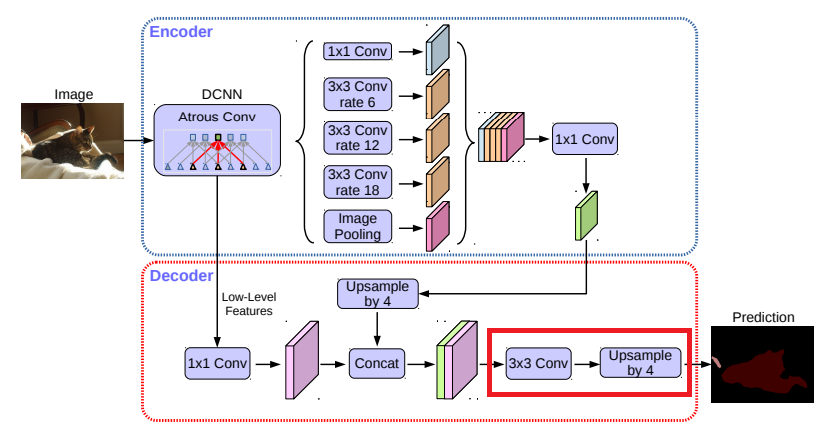
4章に示すように、エンコーダモジュールの出力ストライド= 16を使用すると、速度と精度の最適なトレードオフが得られます。エンコーダモジュールに出力ストライド= 8を使用すると、余計な計算量を犠牲にしてパフォーマンスはわずかに改善されます。
3.2. Aligned Xceptionの変更
Xceptionモデルは、ImageNetにおいて、高速に計算にして画像分類結果を出すのに有効です。最近では、MSRAチームがXceptionモデル(Aligned Xceptionと呼ばれます)を改修し、オブジェクト検出のタスクでパフォーマンスをさらに向上させました。これらの発見に動機づけられて、同じ方向性でXceptionモデルをセマンティックイメージセグメンテーションのタスクのために使います。
具体的には、MSRAの変更に対してさらにいくつかの変更を行います。
(1)高速計算とメモリ効率を得るために入力フローのネットワーク構造の変更だけ行い、「Deformable convolutional networks」と同じより深いXceptionにします
(2)全てのMax Poolingを、任意の解像度で特徴マップを抽出するためのatrous分離可能な畳み込みを行えるストライドする深度方向畳み込み分解に置き換えます。(別の選択肢は、atrousアルゴリズムをMax Poolingに拡張)
(3)バッチノーマライゼーションとReLU活性化を、MobileNetと同様に、3×3深度畳み込みの後に追加します。
修正されたXception構造を【図3】に示します。
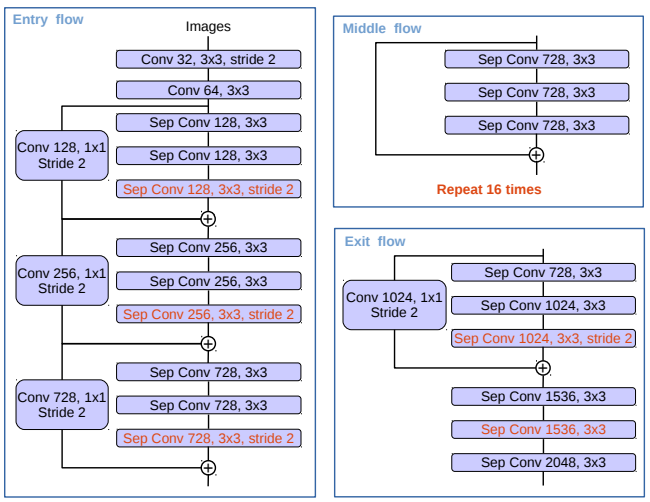
【図3】Xceptionモデルは次のように変更されています。
(1)より多くのレイヤー(エントリーフローの変更を除くMSRAの変更と同じ)(2)すべての最大プーリングが、ストライドを伴う深度方向畳み込み分解に置き換え(3)MobileNetと同様に、3×3の深度畳み込みのたびにバッチ正規化とReLUが追加
4.実験的評価
atrous畳み込みで高密度の特徴マップを抽出するためにImageNet-1kデータセットで事前学習されている、ResNet-101または修正アライメント済みXceptionを使用します。
私たちの実装はTensorFlowで構築され、一般に公開されています。
提案モデルは、20個の前景オブジェクトクラスと1個の背景クラスを含むPASCAL VOC 2012セマンティックセグメンテーションベンチマークで評価します。

[参考]http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
元のデータセットには、1,464個(学習)、1,449個(検証)、1,456個(テスト)のピクセルレベルのアノテーション画像が含まれています。
我々は「Semantic contours from inverse detectors」によって提供される追加のアノテーションによってデータセットを補強し、その結果、10,582個(学習)の学習画像が得られます。
パフォーマンスは、21のクラスにわたって平均化されたピクセルのIoU(領域の一致具合の指標)から測定されます(mIOU)。
私たちは「Rethinking atrous convolution for semantic image segmentation」と同じ学習プロトコルに従ってますので、詳細は「Rethinking atrous convolution for semantic image segmentation」を参照してください。
要するに、同じ学習率スケジュール(「ポリ」ポリシーと同じ初期学習率0.007)で、クロップサイズ513×513、出力ストライド= 16の場合のファインチューニングバッチ正規化パラメータ、および学習中のランダムスケールデータ拡張を行います。提案されたデコーダモジュールにバッチ正規化パラメータも含めることに注意してください。
我々の提案したモデルは、各構成要素の区分的な事前学習なしに、エンドツーエンドで学習します。
4.1. デコーダ設計の選択肢
まず、DeepLab v3で計算された最後の特徴マップ(すなわち、ASPP特徴、画像レベル特徴などを含む特徴)として「DeepLab v3特徴マップ」を定義します。そして、[k×k、f]は、カーネルサイズk×kとf個のフィルタとの畳み込み演算とします。
出力ストライド= 16を使用する場合、ResNet-101ベースのDeepLab v3は、訓練と評価の両方とも16でlogitsをバイリニアアップサンプリングします。
この単純なバイリニアアップサンプリングは、純粋なデコーダ設計と見なすことができ、PASCAL VOC 2012検証セットで77.21%の性能を達成し、学習でこの純粋なデコーダを使用しない場合(すなわち、学習中の本当の正解であるダウンサンプリング)よりも1.2%優れています。
この純粋なベースラインを改善するために、我々の提案するモデル "DeepLab v3 +"は、【図2】に示すように、エンコーダ出力の上にデコーダモジュールを追加します。
デコーダモジュールでは、異なる設計選択のために以下の3つを検討します。
(1)低レベル特徴マップのチャネルをエンコーダモジュールから削減するために使用される1×1畳み込み
(2)よりシャープなセグメンテーション結果を得るために使用された3×3畳み込み
(3)どのエンコーダの低レベル特徴を使用すべきか
デコーダモジュールにおける1×1畳み込みの影響を評価するために、すなわち、res2x残差ブロック内の最後の特徴マップ(具体的には、ストライドする前に特徴マップを使用)になる、ResNet-101ネットワークバックボーンの[3×3、256]およびConv2特徴を使います。【表1】に示すように、低レベルの特徴マップのチャネルをエンコーダモジュールから48または32のいずれかに縮小すると、より良い性能につながります。したがって、チャネル削減に[1×1,48]を使用します。

【表1】エンコーダモジュールからの低レベルの特徴マップのチャネルを低減するために使用されるデコーダ1×1畳み込みの効果。我々は[3×3、256]およびConv2(ストライド前)を使用して、デコーダ構造内の他のコンポーネントを固定します。VOC 2012の実績。
次に、デコーダモジュールの3×3畳み込み構造を設計し、その結果を【表2】に報告します。Conv2特徴マップ(ストライド前)をDeepLab v3特徴マップと連結した後、1回または3回の畳み込みを行うよりも、256個のフィルタで2回3×3畳み込みを行う方が効果的です。フィルタの数を256から128に変更するか、カーネルサイズを3x3から1x1に変更すると、パフォーマンスが低下します。
我々はまた、Conv2とConv3の両方の特徴マップがデコーダモジュールで利用される場合を実験しました。この場合、デコーダの特徴マップは、2倍づつ徐々にアップサンプリングされ、最初にConv3と連結され、次にConv2と連結され、その後それぞれが[3×3、256]演算により改良されます。
デコード手順全体は、UNet / SegNetと同様です。しかしながら、重要な改善が含まれていません。したがって、最終的に、非常にシンプルで効果的なデコーダモジュールである、2つの[3×3、256]操作によって改良されるDeepLab v3特徴マップとチャネル縮小Conv2特徴マップとの連結を取り入れます。
提案したDeepLab v3+モデルは出力ストライド= 4となっていることに注意してください。GPUリソースが限られているのであれば、より高密度(すなわち、出力ストライド<4)の出力特徴マップは求めません。
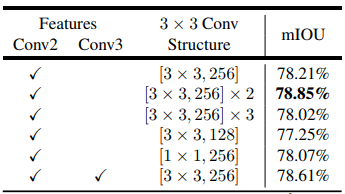
【表2】エンコーダの特徴チャネルを縮小するために[1×1,48]を固定するときのデコーダ構造の影響。Conv2(ストライド前)の特徴マップと2つの追加の[3×3、256]操作を使用することが最も効果的であることがわかりました。VOC 2012の実績。
4.2. ネットワークバックボーンとしてのResNet-101
精度と速度の両面で異なるモデルを比較するために、提案するDeepLab v3+モデルでネットワークバックボーンとしてResNet-101を使用して、表3にmIOUとMultiply-Addsを報告します。
Atrous畳み込みのおかげで、単一のモデルを使用した学習と評価の間で解像度が異なっても特徴を得ることができます。
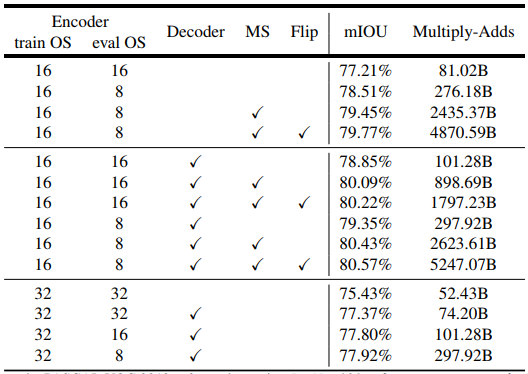
【表3】特徴抽出器としてResNet-101を使用した場合のPASCAL VOC 2012検証セットの推論戦略。train OS:学習中に使用される出力ストライド。eval OS:評価中に使用される出力ストライド。Decoder:提案されたデコーダ構造を採用。MS:評価中のマルチスケール入力。Flip:左右反転入力を追加。
ベースライン
【表3】の最初の行ブロックには、「Rethinking atrous convolution for semantic image segmentation」に対して、評価中の密度の高い特徴マップ(すなわち、評価出力ストライド= 8)を抽出し、マルチスケール入力を採用するとパフォーマンスが向上することを示すの結果が含まれています。さらに、左右反転された入力を追加することで、わずかなパフォーマンスの向上だけで計算の複雑さが倍増します。
デコーダの追加
【表3】の第2の行ブロックは、提案するデコーダ構造を使用したときの結果を含んでいます。
評価出力ストライド= 16または8を使用すると、それぞれ約20Bの余分な計算オーバーヘッドがかかりますが、パフォーマンスが77.21%から78.85%または78.51%から79.35%に改善されました。マルチスケール入力と左右反転入力を使用すると、パフォーマンスがさらに向上しました。
より粗い特徴マップ
我々はまた、高速計算のために、学習出力ストライド = 32(すなわち、訓練中にatural畳み込みを全く使用しない)を使用する場合を実験しました。
【表3】の第3行のブロックに示すように、Multiply-Addsに74.20Bだけ必要になりますが、デコーダを追加すると約2%改善します。ただし、学習出力ストライド= 16とし、異なる評価出力ストライド値を使用した場合、性能は常に約1%〜1.5%下回ります。
したがって、複雑さの状況に応じて、学習や評価の際に出力ストライド= 16または8を使用することをお勧めします。
4.3. ネットワークバックボーンとしてのXception
さらに、ネットワークバックボーンとして、より強力なXceptionを使用します。
「Deformable convolutional networks」を参考に、3.2節で説明するように、いくつか変更を加えます。
ImageNet事前学習
提案するXceptionネットワークは「Xception: Deep Learning with Depthwise Separable Convolutions」と同様の学習プロトコルを用いてImageNet-1kデータセットを事前学習しています。具体的には、運動量 = 0.9のNesterovモーメンタムオプティマイザを採用し、初期学習率 = 0.05、レート減衰 = 2エポックごとに0.94、重み減衰 = 4e - 5としています。
私たちは50個のGPUで非同期に学習を行いました。各GPUはバッチサイズ32で、イメージサイズは299×299です。
セマンティックセグメンテーションのためにImageNetのモデルを事前学習するのに、そんなに厳しくはハイパーパラメータを調整しませんでした。
同じ学習プロトコルの下でResNet-101を再現したベースラインとともに【表4】の検証セットの単一モデルエラー率を報告します。
変更したXceptionにおいて、各3×3の深さ方向畳み込み後にバッチ正規化とReLUを追加しないと、Top1とTop5の精度で0.75%と0.29%の性能低下が見られました。
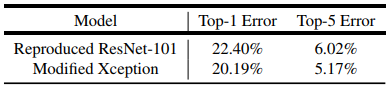
【表4】ImageNet-1K検証セットでの単一モデルのエラー率。
セマンティックセグメンテーションのためのネットワークバックボーンとして提案するXceptionを使用した結果を【表5】に報告します。
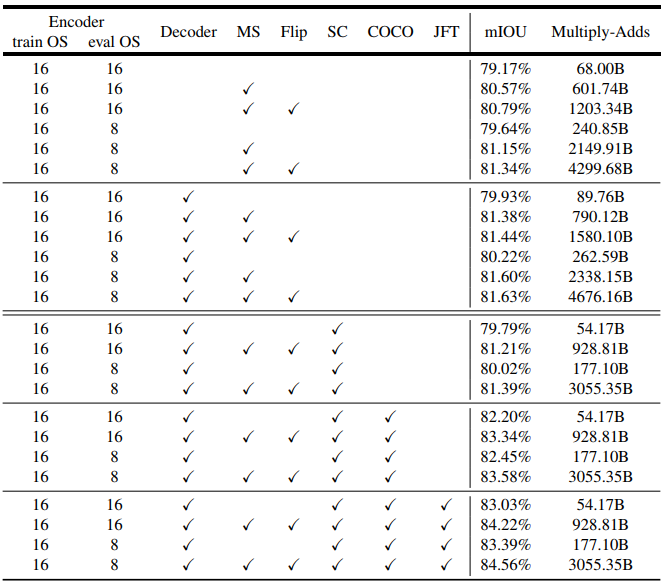
【表5】特徴抽出器として修正したXceptionを使用した場合のPASCAL VOC 2012検証セットの推論戦略。train OS:学習中に使用される出力ストライド。eval OS:評価中に使用される出力ストライド。Decoder:提案されたデコーダ構造を採用。MS:評価中のマルチスケール入力。Flip:左右反転入力を追加。SC:ASPPモジュールとデコーダモジュールの両方に深度方向畳み込み分解を採用。COCO:MS-COCOデータセットで事前学習されたモデル。JFT:JFTデータセットで事前学習されたモデル。
ベースライン
【表5】の最初の行ブロックでは、提案するデコーダを使用しなかった結果を報告します。これは、ネットワークバックボーンとしてXceptionを採用することにより、学習出力ストライド= 評価出力ストライド= 16としたResNet-101を使用する場合よりも約2%の性能向上を示しています。
評価出力のストライド= 8、推論中のマルチスケール入力、左右反転された入力を追加することにより、さらに改善されます。
パフォーマンスは向上しなかったので、マルチグリッド方式は使用していません。
デコーダの追加
【表5】の2行目のブロックに示すように、デコーダを追加すると、すべての異なる推論戦略に対して評価出力ストライド= 16を使用すると約0.8%の改善がもたらされます。評価出力ストライド = 8を使用すると、改善は少なくなります。
深度方向畳み込み分解の使用
深度方向畳み込み分解が効率的に計算することを期待し、ASPPおよびデコーダモジュールに対してさらに使用しています。
【表5】の3行目のブロックに示すように、Multiply-Addsによる計算の複雑さは33%から41%まで大幅に削減され、同様にmIOUパフォーマンスも得られます。
COCOでの事前学習
他の最先端のモデルとの比較のために、私たちはさらに、提案されたDeepLab v3+モデルにMS-COCOデータセットを事前学習しました。これは、すべての異なる推論戦略に対して約2%の改善をもたらします。
JFTでの事前学習
「Rethinking atrous convolution for semantic image segmentation」と同様に、我々は事前学習されたImageNet-1kとJFT-300Mの両方のデータセットを提案するXceptionモデルに使用しており、これにより0.8%〜1%改善されます。
テストセットの結果
計算の複雑さはベンチマーク評価では考慮されていないため、最高のパフォーマンスモデルを選択し、出力ストライド= 8とバッチ正規化パラメータを凍結させて学習します。
最終的には、私たちの「DeepLab v3+」は、JFTデータセットの事前習得なしで、87.8%と89.0%のパフォーマンスを達成します。
定性的結果
【図5】に我々の最良のモデルの視覚的結果を提供します。図に示すように、我々のモデルは後処理を行わなくてもオブジェクトを非常によく分割することができます。

【図5】最良のモデルを使用した場合のPASCAL VOC 2012検証セットを視覚化した結果。 最後の行は障害モード。
障害モード
【図5】の最後の行に示されているように、我々のモデルは、(a)ソファ対椅子、(b)重度に遮られた物体、および(c)まれな視界の物体をセグメント化することが困難です。
4.4. オブジェクト境界に沿った改善
ここではオブジェクト境界付近における提案されたデコーダモジュールの精度を定量化するために、trimap実験によるセグメンテーション精度を評価します。

[参考]http://disp.ee.ntu.edu.tw/~phoenix104104/vfx/FinalProject/vfx_final_result.html
一般に、オブジェクト境界の周りで発生する、検証セットの 'void'ラベルアノテーションに形態素的膨張を適用します。
次に、膨張された'void'ラベルの帯域(trimapと呼ばれる)の中にあるピクセルの平均IOUを計算します。
【図4】に示すように、提案されたデコーダをResNet-101とXceptionネットワークバックボーンの両方に採用することで、ナイーブバイリニアアップサンプリングに比べてパフォーマンスが向上します。拡張された帯域が狭い場合、改善はより重要になります。図に示すように、ResNet-101とXceptionの最小trimap幅でそれぞれ4.8%と5.4%のmIOU向上が見られました。また、【図6】に提案するデコーダの効果を視覚化します。
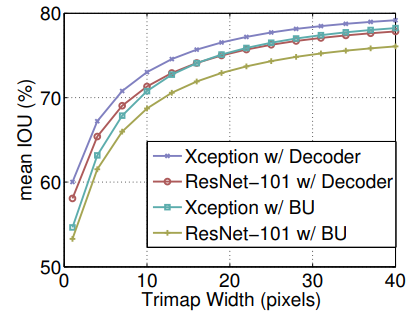
【図4】学習出力ストライド = 評価出力ストライド = 16を使用した場合の、オブジェクト境界の周りのtrimap帯域幅の関数としてのmIOU。BU:バイリニアアップサンプリング。

【図6】提案したデコーダモジュールを使用した定性的効果は、ナイーブバイリニアアップサンプリング(BUと表示される)と比較しました。これらの例では、Xceptionを特徴抽出器として使用し、学習出力ストライド = 評価出力ストライド = 16としています。

【表6】高いパフォーマンスのモデルで評価したPASCAL VOC 2012テストセットの結果。 詳細に興味のある読者はリーダーボードを参照してください。
5.結論
我々の提案するモデル "DeepLab v3+"は、豊富な文脈情報を符号化するためにDeepLab v3が使用しているエンコーダと、オブジェクト境界を回復するために採用された単純ではあるが有効なデコーダモジュールの、エンコーダ-デコーダ構造を使っています。またそれは、利用可能な計算資源に応じて、任意の解像度でエンコーダ特徴を抽出するためのatrous畳み込みに使えます。
我々はまた、提案されたモデルをより速くより強くするために、Xceptionモデルとatrous畳み込み分解を使用ました。
最後に、提案モデルセットがPASCAL VOC 2012セマンティックイメージセグメンテーションベンチマークにおいて最先端のパフォーマンスであることを実験結果は示しています。
謝辞
Haozhi QiとJifeng DaiとAligned Xception、Chen Sunからのフィードバック、Google Mobile Visionチームのサポートについての貴重な議論を感謝します。
おまけ
ひどい翻訳でゴメンナサイ...