完全パングラム
ヒシメク本ノ森ヲ 積ム港
揺レル船ハ 沖ヘ抜ケ
縦ヤ横二 ソロウ街
世界サエ 表ス
これは2011年に小林賢太郎テレビ3というNHKの番組で紹介された, 日本語のひらがな46音すべてを一回だけ使って生成された詩です. このような文章は正式には完全パングラムと呼ばれています. 自分は小学生のときにこの詩を見てすごく感動して, ひらがなカードを作ってカードを並び替えて遊んでました. しかし, 当時, 時間をかけて試行錯誤したにもかかわらず余計な文字が余ったりしてしまって満足いく文章を一度も作ることができませんでした.
現在, 自分は情報系の大学生でヒューリスティクスやアルゴリズムの技法を学んでいます. そこで, 学んだ技術を使って, 小学校の時に挫折した完全パングラムに再挑戦することにしました.
githubのレポジトリはこちらです.
またこれから紹介するプログラムは現在進行形なもので引き続き改善を行う予定です.
プログラムの概要
作業内容としては大きく2つに分かれました.
- 日本語の文章の"自然さ"を定量化する言語モデルの作成
- ヒューリスティクスによってより"自然"になるような文章の生成
言語モデルの作成
まずひらがなのみのデータセットを作り, それを用いてKenLMの学習を行いました.
ひらがなデータセットの生成
ひらがなデータセットの生成には前処理が十分にされている青空文庫のデータセットの文章をすべてひらがな化する形で行いました. 漢字はkakasiを用いてひらがなにしました. またパングラムはひらがなのみで行う予定なのでひらがな以外の記号(。や、や数字)はすべて削除しました. またfugashiを用いて文章を形態素単位で分解しました.
KenLMの学習
今回はn-gramベースの言語モデルであるKenLMを用いることにしました. LLMのような言語モデルよりも軽量なのが特徴です. 特にヒューリスティクスと組み合わせる今回のタスクでは言語モデルの推論時間の短さは重要になってきます. もちろん後述するように欠点もあります. ちなみにKenLMはLLMの学習の前処理で低品質文の除外の用途で使われることがあります.
ひらがな化したデータセットを用いてKenLMによる5-gram言語モデルを学習させました. 15分くらいで学習は終わりました. モデルは, 文章を順方向から予測するモデルと逆方向から予測するモデルの2種類を作成しました.
学習したモデルはここにあります.
他に試したこと(Bertの学習)
KenLMは5形態素前までしか考慮しないので, 文章全体の文脈を扱うことはできません. そのため, Bertを用いて学習もやってみました. 具体的には, すでに日本語でpretrainingされているBertをひらがなデータセットでcontinual pretrainingをしました.
ひらがなデータセットを使うと1エポック分の学習はA100で1時間弱かかります. ただ量子化など高速化のテクニックを使っても推論速度でKenLMより数十倍遅いので, Bertを使う方針は一旦棚上げになっています. (あと自腹でレンタルGPUを使ってるので少し学習がやりづらいです)
ヒューリスティクス
KenLMによる対数確率を指標として日本語文の“自然さ”を定量化し, そのスコアを最適化するために焼きなまし法と4-opt mutationを組み合わせて探索を行いました.
スコア関数
文章をまず形態素単位に分解し, 順方向と逆方向それぞれのKenLMのモデルで文章のスコアを出し, 足し合わせます. 日本語が"自然"だとスコアは低くなります.
実装は以下のようになっています.
def calculate_score(sentence):
"""
KenLM を使って
与えられた文の score(自然さ)を算出する.
"""
sentence = ''.join(sentence)
processed_sentence_list = [word.surface for word in tagger(sentence)]
reversed_processed_sentence_list = processed_sentence_list[::-1]
processed_sentence = ' '.join(processed_sentence_list)
reversed_processed_sentence = ' '.join(reversed_processed_sentence_list)
score = -model.score(processed_sentence) -model.score(reversed_processed_sentence)
return score
探索アルゴリズム
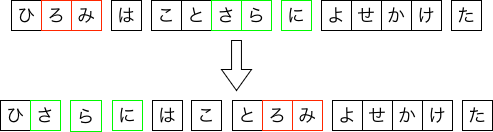
巡回セールスマン問題の代表的なアルゴリズムとして焼きなまし法と近傍法(n-opt法)があります. 焼きなまし法と近傍法はこの記事が参考になるかもしれません. 今回はその解法をそのまま適用して探索アルゴリズムを作りました. 近傍法は2つの部分文字列を交換する4-opt法を用いました. 下図がその例です.
実装は以下のようになっています. 3分くらいで実行が終わります.
def improve_by_4_opt_sa(sentence, step=2_000_000, T0=2.0, Tmin=0.1, alpha=0.9999999):
v = calculate_score(sentence)
best_sentence, best_v = sentence, v
T = T0
for step_num in range(step):
# ランダムに4点選択
indices = sorted(random.sample(range(len(sentence)+1), 4))
a, b, c, d = indices
new_sentence = sentence[:a] + sentence[c:d] + sentence[b:c] + sentence[a:b] + sentence[d:]
new_v = calculate_score(new_sentence)
delta = new_v - v
# 改善 or 確率的悪化許容
if delta < 0 or random.random() < math.exp(-delta / T):
sentence, v = new_sentence, new_v
if v < best_v:
best_sentence, best_v = sentence, v
print(f"Step {step_num}: Improved! new_score={v:.3f}, best sentence = {''.join(best_sentence)}")
# 温度を減衰
T = max(T * alpha, Tmin)
# ログ出力(確認用)
if step_num % 1000 == 0:
print(f"Step {step_num}: T={T:.3f}, score={v:.3f}, sentence = {''.join(sentence)}")
print(f"Finished all {step} steps.")
print(f"Best score: {best_v:.3f}")
return best_sentence
生成例
チェリーピックせずに生成された例をいくつか紹介します.
へん しろ と むらさき や ひめい の ほそおもて くみつこう まちあわせる より ふね は かれ を たすけ ぬ なにゆえ
ほえる なんて ぬきあわせよう ふみしめ さむらい や かねもち の ひろま へ そこ は おれ を たすけ に ゆつくり と
ねえ さま おやこ かたつむり は それ に あしもと を すくわ ひきぬけろ ふみならせよう ほてる いち へん の ゆめ
しち に あたま を はね ぬけ やりなおせよう くさむら へ えんかい のみほす ひそめ て われ ふところ ゆき つもる
おまえ は もちぬし の そうさく てき かんせい に ほらあな を むね へ ふところ よ ひける ゆすりみつれ たわやめ
アニメーション
探索過程で, 1000ステップごとに記録した最良の文字列を抽出し, それらを連結してGIFとして可視化しました. (1周3分くらい) もし動かなければ画像をクリックしてみてください.

考察
なんとなく意味が伝わるような文章はできてはいるのですが, やっぱりKenLMが5形態素前までしか記憶していないこともあって結局なんなのという文章もできてしまっています. (詩としては完成ということでもいいのでしょうか?) 全体の文脈も考慮したパングラムの文章ができるようにKenLM以外の言語モデルを使うこともこれから考えたいです.
最後に
最後まで読んでくださりありがとうございます. 完全パングラム生成のNLP的アプローチに興味を持ってくださる方が増えることを願っています. 日本語の奥の深さを感じることができて楽しいです. 考察でも述べたように生成された文章にはまだ問題があるため, 引き続き改善を行っていく予定です. もし, 提案などがありましたらgithubでissueなどを立ててくださるととてもうれしいです.