先日、おはなしを自動で生成して読み上げるアプリ「ずんだテラー」を作ってみたので、その開発ポイントについて解説します。主にOpenAI APIとVOICEVOXの機能を利用しています。
ずんだテラー(ずんテラ)
ずんだテラーは、東北応援キャラクター東北ずん子の関連キャラクターであるずんだもんが、その場で生成された様々な「おはなし」を読み上げてくれるアプリケーションです。
以下のリポジトリでソースコードとビルド済みPC/Androidアプリを公開しています。Unityプロジェクトです。
以下のような「おはなし」を作れます。
なぜ作った?
大きなモチベーションとしては以下でした。
- OpenAI APIを使って何か作りたかった
- 荒唐無稽なストーリーをAIに考えてもらうのが結構面白い
- ずんだもんがかわいい、しゃべらせたい
今回はGenerative AIを利用したシステムを作る際の勘所のようなものを、自分自身で掴みたいという意図が大きいです。プロンプト含めて内容自体は陳腐ですが、遊べる段階まで作ってみて何かしらの知見を得て、共有することに意義を置きました。
以下解説を続けます。
ストーリー生成プロンプト
ずんテラの中核ロジックである「おはなし」生成部はStoryTitleGeneratorとStoryContentsGeneratorの2つで構成されています。
双方とも以下のsystemプロンプトを冒頭に指定しています。
あなたは子供向けの物語のプロ作家です。楽しく教育的な物語を作る作業をアシストしてください。
おはなしタイトル候補リストの生成
おはなしタイトル候補リストの生成は以下のStoryTitleGeneratorが担っています。
プロンプトは以下で、非常にシンプルです。出力は直接json形式を指定しているので、そのままパースするだけです。(stringのリストを指定してもよかったですが一応構造化しています。)
子供向けのオリジナル物語のタイトルを{NUMBER}個考えてください。
## 制約事項
- タイトルは15文字以内にすること
- 日本語のタイトルにすること
- タイトルには改行を含めないこと
- 以下のjson形式のリストで返答し、json以外の会話文、コメント、補足などの情報は一切返答しないこと
## 出力フォーマット
[
{"title": "Title 1"},
{"title": "Title 2"},
{"title": "Title 3"},
]
temperatureはデフォルトの1ですが、これだけで、毎回異なるリストを返してきます。
プロンプトではjsonの出力例をなんとなく提示しているだけですが、個数も踏まえてかなり安定してレスポンスされます。いいですね。
おはなしコンテンツの生成(v1)
おはなしの文章自体の生成は以下のStoryContentsGeneratorが担当しています。v1とあるとおり現状は、少し改良したものを使っています。これは後述します。
プロンプトは以下のようになっています。
「{TITLE}」という子供向けの物語の内容を考えてください。
## 出力フォーマット
{emotion}: {content}
{emotion}: {content}
{emotion}: {content}
## 出力フォーマットの詳細
- {content}は物語の文章です
- {emotion}は{content}の感情を表す数字で、以下のEmotion Numberから選択します
### Emotion Number
0 -> 普通
1 -> 喜び
2 -> 驚き
3 -> 悲しみ
4 -> 怒り
## 制約事項
- {PREFERRED_LENGTH}行以上の物語にすること
- 1行は50文字以内にすること
- 文章の語尾は「です、ます」口調にすること
- フォーマット以外の会話文、コメント、補足などの情報は一切返答しないこと
## 物語の構成について
- 抽象的な表現は避け、具体的な物語の内容にすること
- 物語に起承転結の起伏をつけること
## 出力の例
0: 昔々あるところにおじいさんとお婆さんがいました。
0: おじいさんは芝刈りに、お婆さんは川に洗濯に行きました。
2: お婆さんが洗濯をしていると、川上から大きな桃が流れてきました。
1: お婆さんはその桃を家に持ち帰りました。
こちらはタイトルの時と違って、少し複雑です。
「出力フォーマット」がjson形式で指定しないのは逐次処理をするためです。こちらも後述します。
また、文章に応じて「感情」に対応する数字も指定してもらっています。この数字をEmotionというenumにマッピングし、ずんだもんの表情を変化させています。とりあえず、簡単に5個の感情を用意しましたが、精度はまぁまぁという感じですす。
最後に出力の例を提示しています。このセクションがないと出力が安定しない場合がありました。
総じてですが、gpt-3.5-turboモデルでは、物語の長さの安定感含めて少し出力がキツそうでした。なお、ブラウザでGPT-4で同様のプロンプトを試したところ、物語の長さや安定感踏まえてかなり精度は上がっているようには感じました。
おはなしコンテンツの生成(v2)
上記のv1でもそれなりに出力ができていたのですが、v0.1.0では以下のStepByStepContentsGeneratorを使っています。
プロンプトは以下で、多少変更点があります。
「{TITLE}」という子供向けの物語の内容を考えてください。
## 出力フォーマット
{"content": <content>, "emotion": <emotion>}
{"content": <content>, "emotion": <emotion>}
{"content": <content>, "emotion": <emotion>}
## 出力フォーマットの詳細
- <content>は物語の文章です
- <emotion>は<content>の感情を表す数字で、以下のEmotion Numberから選択します
### Emotion Number
0 -> 普通
1 -> 喜び
2 -> 驚き
3 -> 悲しみ
4 -> 怒り
## 制約事項
- <content>に改行を含めないこと
- <content>は50文字以内にすること
- 文章の語尾は「です・ます」口調にすること
- 1行ずつjson形式で出力し、それ以外の会話文、コメント、補足などの情報は一切返答しないこと
## 物語の構成について
- 抽象的な表現は避け、具体的な内容にすること
- 物語に起承転結の起伏をつけること
## 出力の例
{"content": "昔々あるところにおじいさんとお婆さんがいました。", "emotion": 0}
{"content": "おじいさんは芝刈りに、お婆さんは川に洗濯に行きました。" , "emotion": 0}
{"content": "お婆さんが洗濯をしていると、川上から大きな桃が流れてきました。" , "emotion": 2}
{"content": "お婆さんはその桃を家に持ち帰りました。", "emotion": 1}
v1からの変更点としては、1行づつのjson出力に変えた点です。そもそもv1では速度を稼ぐ意図で、余計な文字列出さないようなフォーマットにしていましたが、開発中に十分な速度を出せそうなことがわかったので、「行ごと」のjsonに変更しました。
また、これは完全にヒューリスティックで性能の評価もしてないですが、emotion=>contentの並びから、content=>emotionの順に変更しました。LLMで逐次、次の文字列を推論をしているとなると、このような順の方が自然になりやすいのでは?と考えたためです。
さらに、大きい点として、起承転結のパートごとに、順次出力してもらうようにしました。これにより物語の長さや構成のコントロールがしやすくなったように思います(こちらも評価は特にしていません)。以下のようなフローのイメージです。
user:
上記のルールに従って、まずは起承転結の「起」の部分を2行で返答してください
assistant:
{"conent": "ある日森の中、男の子はアライグマさんに出会いました。", "emotion": 0}
{"conent": "アライグマさんは川で魚を捕っていました", "emotion": 0}
user:
次に、起承転結の「承」の部分を3行で返答してください
assistant:
{"conent": "男の子はアライグマさんに話しかけ、彼が魚を捕っているのを手伝いました", "emotion": 1}
{"conent": "魚を捕るための川縁の道具や技術について、アライグマさんは男の子に教えてくれました。", "emotion": 0}
{"conent": "男の子はアライグマさんと魚を捕って、楽しい時間を過ごしました。", "emotion": 1}
...
*今思うと、v2のjsonの構造化によりemotionを数字にマッピングしてもらう必要は無くなった気がします。ここのタスク負荷を減らすとまた変化があるかも?
プロンプトインジェクション対応について
ユーザーの自由入力があるので少し考えましたが、文字数の制限があるかつ、以下のように「」で括るだけでも、それなりに防げそうだったので、特に対応はしていません。
「{TITLE}」
また、出力結果はこちらが指定した構造に一度パースするので、変なレスポンスはエラーになる率は高そうでもありました。
このような自由入力があるところは、ランダムなハッシュ値などで括るなどすると、簡単かつよりセキュアになりそうではあります。
VOICEVOXでのボイス生成
音声の生成にはVOICEVOXを利用しています。
こちらの採用理由はずんだもんのボイスが利用できるという点が主です。あとはHTTP通信経由で簡単にエンジンと連携できる点も良かったです。他のボイス生成系のシステムは今回は調査・比較はしていません。
こちらは、都合や紆余曲折があって、2つの連携方法を用意しました。
ローカルのVOICEVOXエンジンとの連携
PCローカルのVOICEVOXとの連携には、以下のUnityからVOICEVOX Engineと連携できる自作ライブラリを使っています。
また、自宅では以下の記事のようにVOICEVOX Engineサーバーを別PCに立てて利用しています。
ただし、上記ライブラリは現時点で音声の生成と再生のコンポーネントが密になっているため、部分的に使うざるを得なくなりました(ライブラリ設計時から責務定義がNGだと思っていたが、やはり「簡単」を優先したせいで実際イケてなかった)。
WEB版VOICEVOX APIの利用
最終的にアプリを配布し、モバイルでも遊んでもらうことを考えると、VOICEVOX Engineのサーバーを独自に立ててもらうのはハードルが高いきがしました(VOICEVOXアプリをPCで単に起動しておくだけでは別ホストからのアクセスはできなそう)。
その対応として、WEB版のVOICEVOX APIを利用させてもらうことにしました。こちらは、かなりシンプルに利用ができ、非常に助かりました。
簡単ですが連携コードは以下になります。
現状はOpenAIのAPI Keyと同様に、アプリ利用者のユーザーの方にAPI Keyの取得をお願いしています。
ストーリー生成と再生開始待ち時間への対応
ChatGPT APIとVOICEVOXでのコンテンツ生成処理には時間がかかります。一番最初に試した時は、おはなしの生成をChatGPT APIにリクエストしてから、データを受信して再生を開始するまでに30秒ほどかかりました。この時間はあきらかにユーザーは待てないです。
とはいえ、おはなしは大体1分30秒ほどを目安にしているため、全部を一気に出力してから再生を開始するのではなく、逐次生成しながら再生すればよいという話です。
これを実現するために、Chat Completion APIのstream(Server-Sent Events)オプションを利用することにしました。こちらは以下の記事で解説してます。
この機能を利用して、タイトルコール表示で冒頭コンテンツ生成の待ち時間を誤魔化しつつ、以下のコードのようにおはなしの生成を再生と並行して行います。
ずんだもん立ち絵
立ち絵素材は坂本アヒルさんの以下の素材を利用させてもらっています。かわいい!
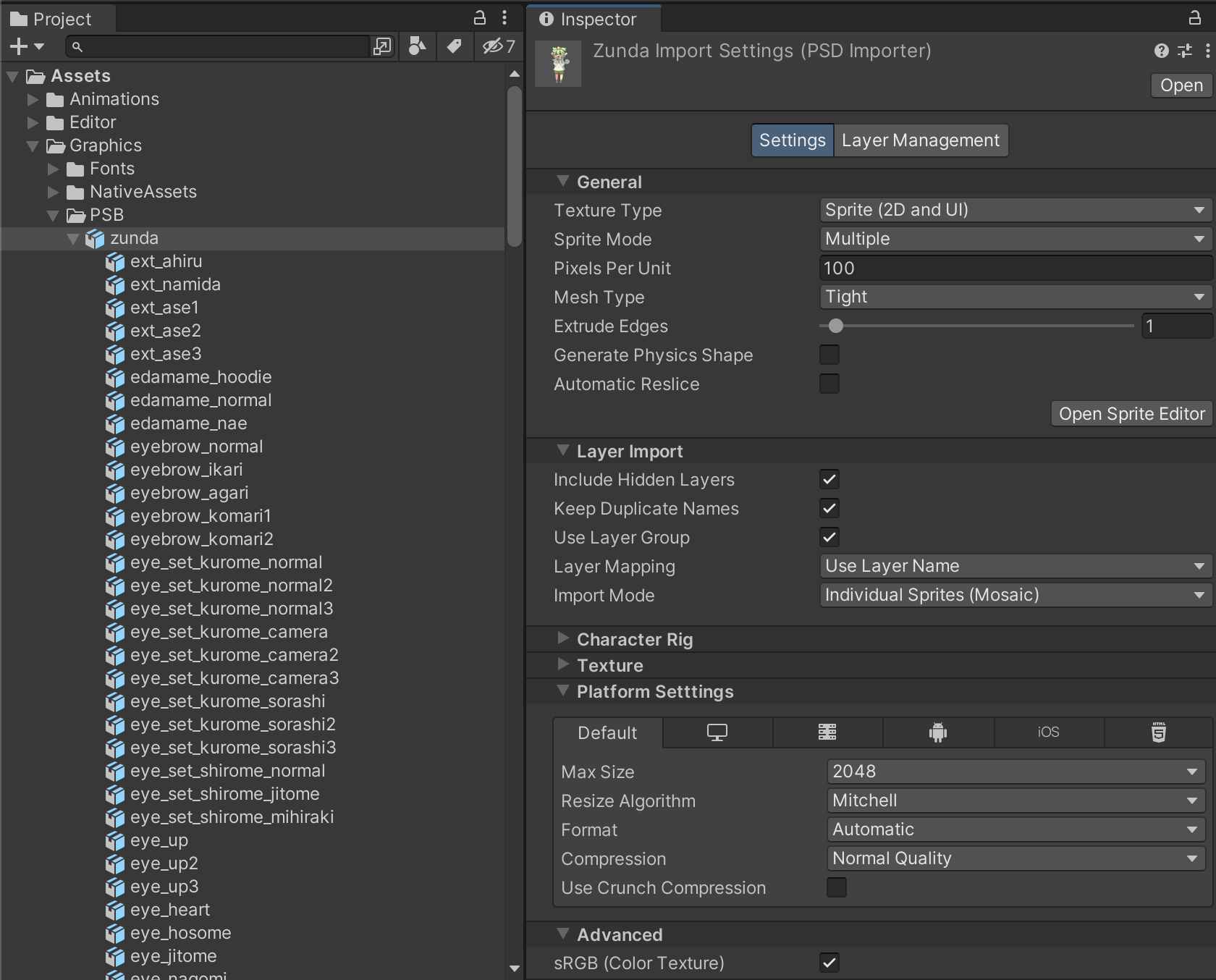
PSBのインポート
ずんだもん立ち絵はpsdで配布されいますが、こちらはUnityのPSD Importerを利用してUnityに取り込んでいます。ただ、レイヤー名が日本語で文字化けしてしまったので、手作業で英数字表記にしてpsb形式に変換しました。
インポート後はこのようにレイヤーの情報やパーツの位置関係など踏まえて、アトラス化やアセット化がされるのでUnityで割と扱いやすかったです。
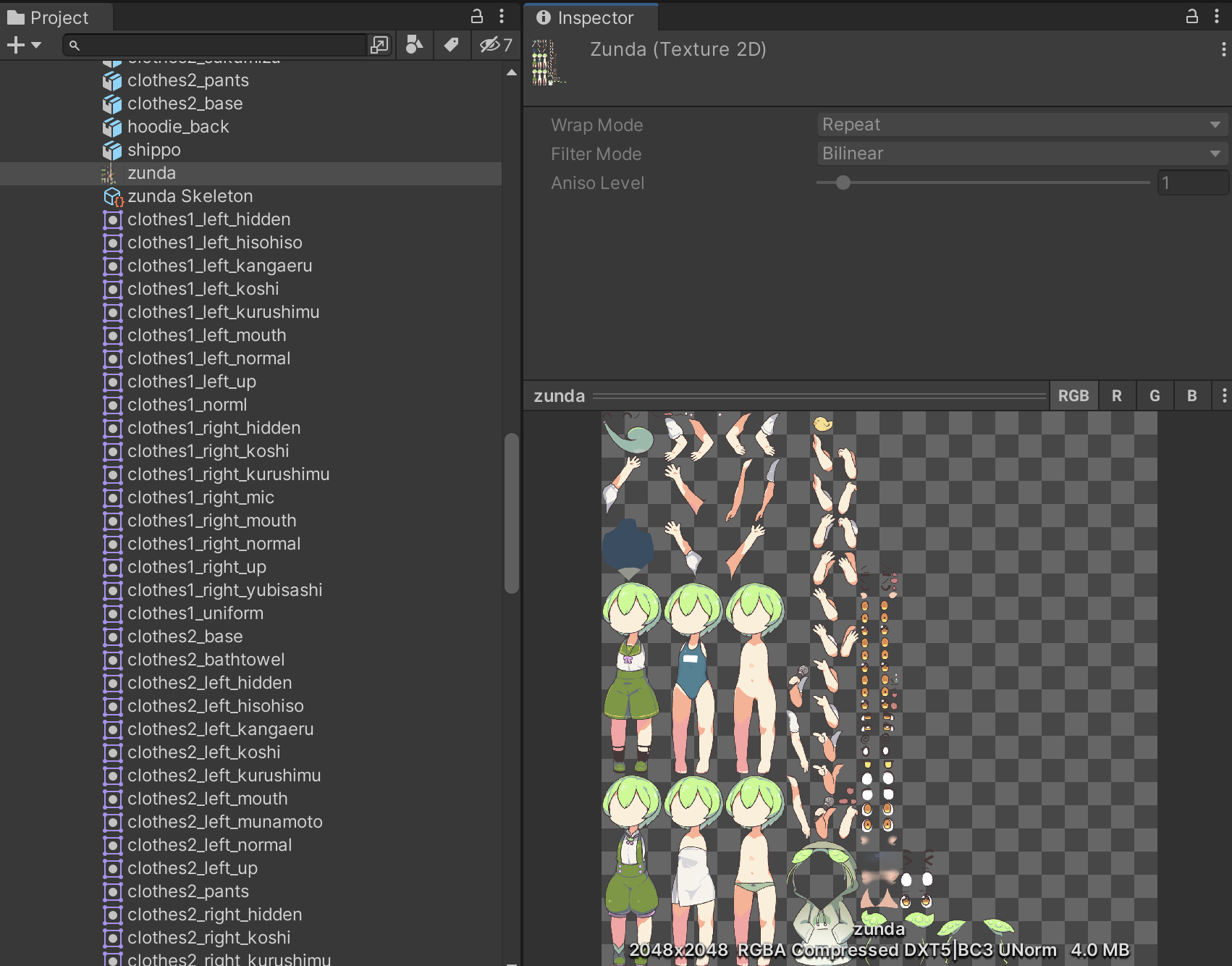
表情と口パク
表情はアニメーションクリップで各パーツをオンオフしています。口パクはリップシンクとか考えず適当に複数のスプライトを切り替えているだけです。

口パクアニメは表情に関連せず1クリップだけ作り、Animatorで別レイヤーとして設定しています。これで、表情を簡単に増やせます。
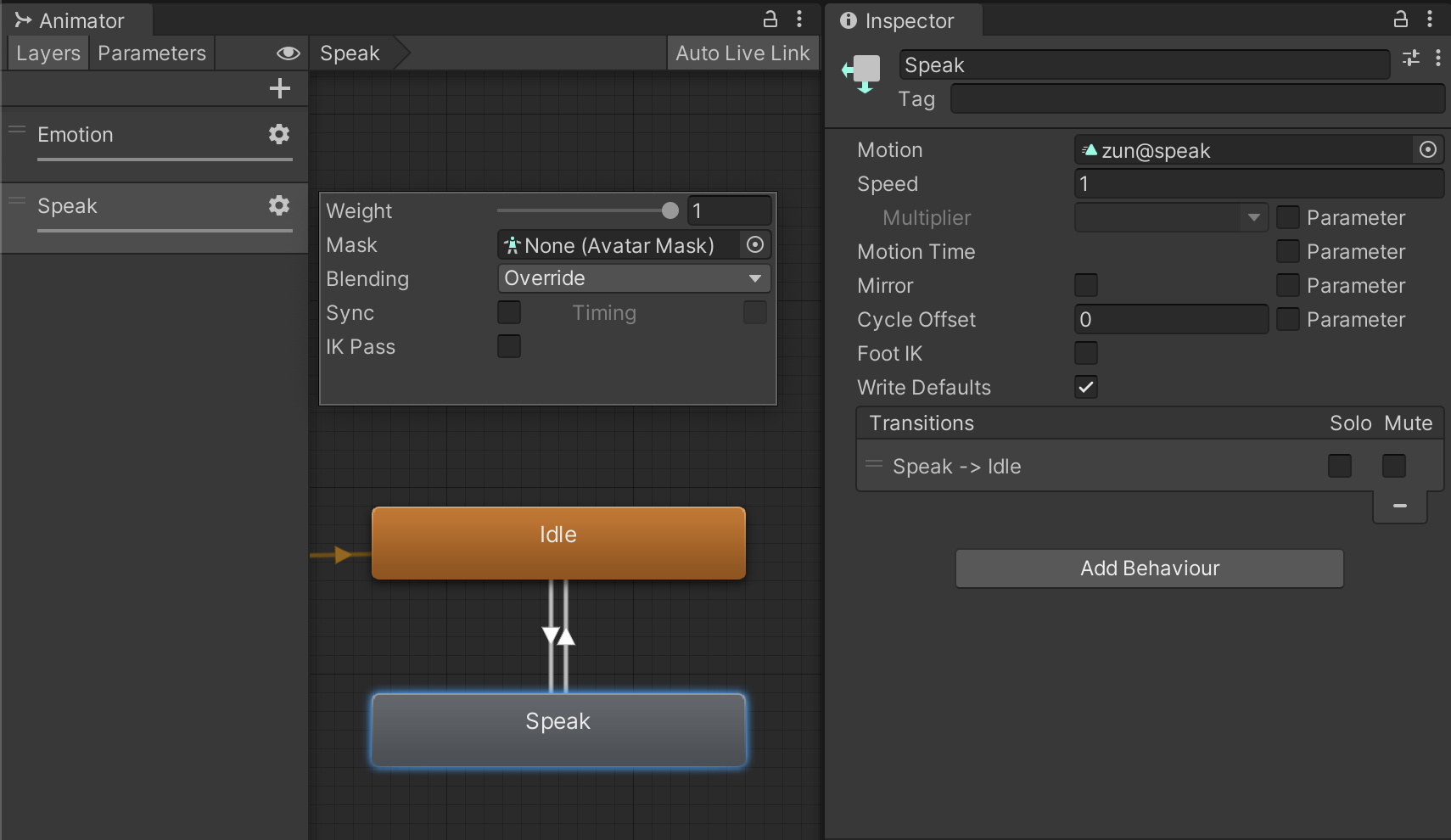
正直このpsbアセットの取り回しや口パク周りはあまり詳しくなく、もっと良い方法があるかもしれません。
アプリのアーキテクチャの話
公開にあたりコードと依存をそれなりに整理しました。アプリとしてエラーハンドリングやバックキー対応、ボタン音など機能が足りないところも多々ありますが、現時点の最低限の構造になっているとは思います。小さめのゲームやアプリを作る際は参考になるかもしれません。
正直、簡易的ではありますがフルスクラッチでViewや画面遷移の仕組みなどを作るのが一番手間でした。
その先のアプリとしての技術的雑感
冒頭に述べたとおり、今回は開発の所感を得てソースコードの公開&解説で目的達成です。
ただし、このようなアプリをサービスとして提供する場合は、技術的には以下の課題があるように感じました(権利と収益関係除く)。
1つ目は、OpenAIのAPI Keyをクライアントに埋め込むわけにはいかないので、アプリから直接APIと通信していたところを、自前のサーバー経由で行う必要があるところです。さらに今回のように順次処理を行う場合はサーバーからPushできるような構成にしないといけなそうな気がします。
2つ目は、音声合成処理サーバーの用意です。複数リクエストを捌くとしたらGPUインスタンスを用意しつつ、冗長化含めて考えておく必要があります。通信量の削減のために圧縮したフォーマットでのやりとりや転送負荷、コネクション時間などの考慮も必要です。(モバイル向けにはvoicevox_coreのビルトインはキツそうな所感)
1も2もガッツリ取り組めばクリアできそうですが、時間と運用コストはかかりそうですね。
まとめ
今回はOpenAI APIとVOICEVOX、そしてfeaturing.ずんだもんな、 おはなし無限読み上げアプリ「ずんだテラー」の開発ポイントについて解説しました。
LLMは実用的システムへの適用は多々考えられると思いますが、このようなエンタメへの適用も面白いですね。今回はいろいろ勉強になりました。
ただし、「よいおはなし」とは何かのようなものは、とても主観的であり評価は難しく、プロンプトの定義・改良などにも多くのヒューリスティックが必要そうな印象を持ちました(今回は検証&ジョーク半分なので深くは検討してません)。
以上、アプリ開発やプロンプトの参考にしていただければ幸いです。