経緯など
Pentaho Data Integartion(PDI)上で形態素解析する必要があったので調査とメモ。
PDIがJavaで実装されているため呼び出しやすいようにJavaの形態素解析器を調べたところ、Kuromojiがあったので、そちらを利用させていただくことにしました。
ただ、Javaで書いてPDIで呼ぶのも面倒だったので、結局Jython経由で利用しています。
使用環境
PDI 7.1
Java Version 8 Update 131
Kuromoji 0.7.7
Jython 2.7.0
設定手順
PDIはこちらからダウンロードしてきたZIPファイルを適当な場所に解凍しておくだけでよい
※解凍すると"data-integration"というディレクトリができるがこの辺りは割愛
※あとJavaが必要なので事前にインストールしておく
KuromojiをGitHubからZIPファイルをダウンロードして解凍し、以下に置く。
$ pwd
~/data-integration/lib
$ ls kuromoji-0.7.7.jar
kuromoji-0.7.7.jar
$
JythonをこちらからStandaloneJarをダウンロードして、以下に置く。
$ pwd
~/data-integration/lib
$ ls jython-standalone-2.7.0.jar
jython-standalone-2.7.0.jar
$
実行
PDIを起動。
$ pwd
~/data-integration
$ ./spoon.sh
起動したら、以下のように設定する。詳細はイメージの下に記載。
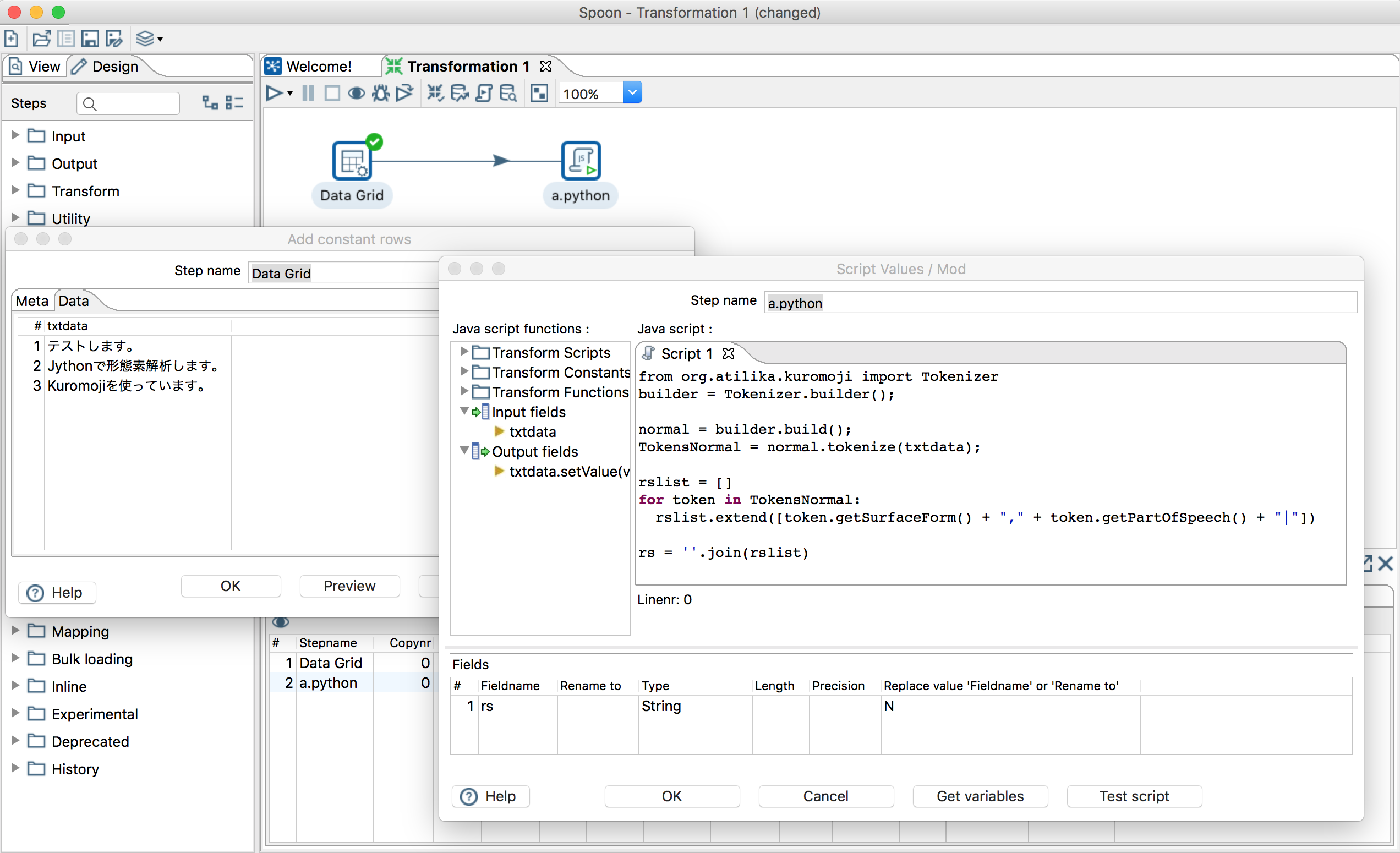
「Data Grid」ステップは、適当な文章をいくつか設定しておく。今回は以下のようにした。
・テストします。
・Jythonで形態素解析します。
・Kuromojiを使っています。
「Script」ステップは、以下のように設定。また、ステップ名を「〜.python」としておく必要があるので注意する。
from org.atilika.kuromoji import Tokenizer
builder = Tokenizer.builder();
normal = builder.build();
TokensNormal = normal.tokenize(txtdata);
rslist = []
for token in TokensNormal:
rslist.extend([token.getSurfaceForm() + "," + token.getPartOfSpeech() + "|"])
rs = ''.join(rslist)
「Script」ステップの下部の"Fields"には、最終的に返却したいフィールドを設定する。ここでは、"rs"。
ここまで設定したら、「Script」ステップ上でプレビュー実行を行うと、以下のようになります。
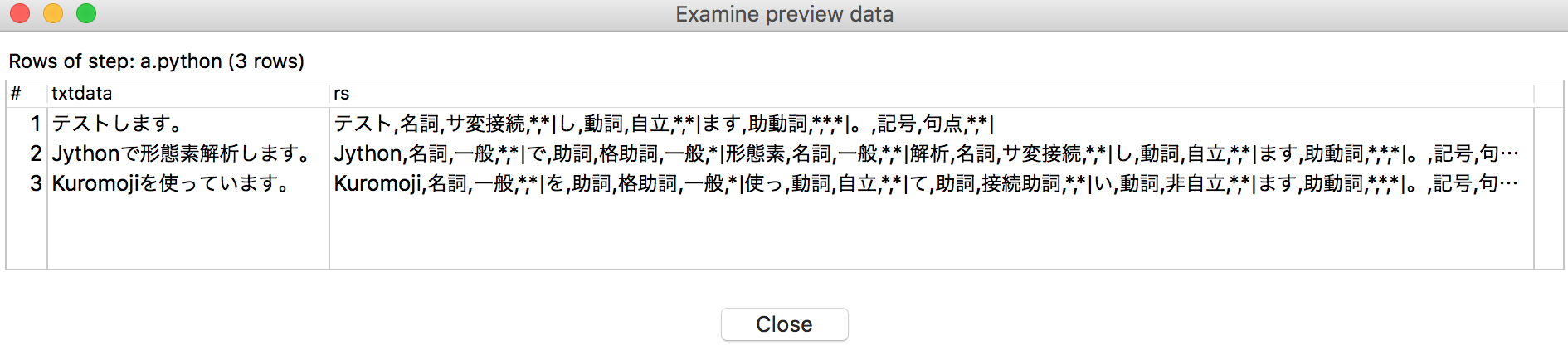
複数の文字列を連続して処理しているので、1つの文字列を形態素解析した結果は、"|"でつないでます。
形態素解析とPDIでの処理を別々でやっていて、煩わしさを感じている場合などに使えるのではないかと思います。
参考
http://d.hatena.ne.jp/knaka20blue/20151224/1450943656
https://www.atilika.com/ja/products/kuromoji.html