本記事は Timee Product Advent Calendar 2025 シリーズ3 25日目の記事です。
はじめに

僕の名前はメトリっち!
タイミーの指標をなんでも正しく出せるように日々成長してるんだ!
よろしくね!
何を作ったか
Slackから呼び出せて、弊社のLooker上に整えられているセマンティックレイヤー群を参照して、正しいデータをテキスト形式でレスポンスしてくれるエージェントを作りました。
 |
ユーザーの要求したデータをLookerURLと一緒に回答してくれて、
 |
フィードバックボタンを押すと展開されるこちらのモーダルに改善要望を入力することで、その改善要望に応じた改善PullRequestが生成されるようなものです。
なぜ作ったか・課題感
データモデリングの開発が進まない
弊社はLookerセマンティックレイヤーを月に850人が使っており、国内有数のLooker活用事例だと思われますが、データモデリング&セマンティックレイヤーの整備がビジネスの拡大スピードに追随しきれていませんでした。
⇒ よりスケーラブルかつアジリティの高いモデリング開発体制を実現したい
データを取得するまでのリードタイムの短縮・取得体験の平滑化
Lookerをベースにしたセマンティックレイヤーを活用する社内文化は醸成されているものの、現状、データを取得するまでに以下のような課題があります。
- Lookerセマンティックレイヤー上で目的の用語を探すのが大変
- どのLookerセマンティックレイヤーにどのMeasure,Dimensionが格納されているかわからない
- そもそもLookerを開くこと自体がめんどうくさい
⇒ 誰もが迷うことなく、すぐに正しい指標を取得できる体験を作りたい。
あらゆる社内エージェントが正しい指標を取得できる体験の創出
A2Aで各エージェントが繋がることを見越して、社内のあらゆる自動化やエージェント連携において、常に正しいデータ定義に基づいた指標が活用される基盤を作りたいと考えています。
⇒ どのAIも社内の正しい指標を取得できるようにしたい。
セマンティックレイヤーをビジネスに追随させ続けることが難しい
社内でユビキタス言語はある程度定義されているものの、ビジネスの拡大スピードや組織再編スピードが凄まじく、「アクティブ率」のように、定義が複数存在する用語が社内にいくつもあったり、部署によって定義が変化している用語があったりします。
⇒ 同義語登録やデータモデリング開発の工数を最小化したい。
なんで「メトリっち」って命名なの?
メトリクスを出力してくれる & みんなに育てていって欲しいという思いから、
たまごっちをリスペクトして「メトリっち」です。
構成紹介
全体構成
| 全体の概念図 |
|---|
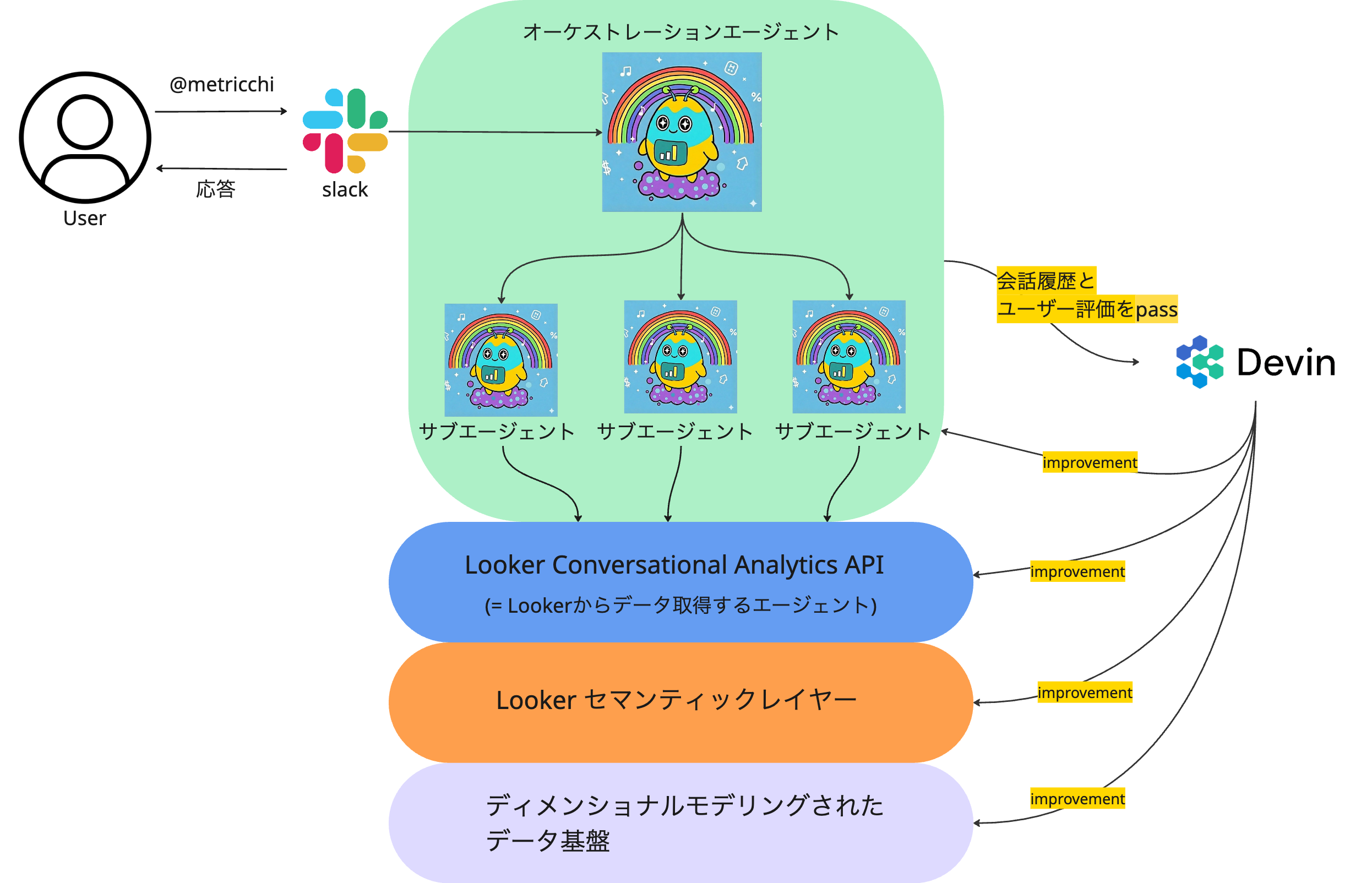 |
| インフラ周りざっくり図 |
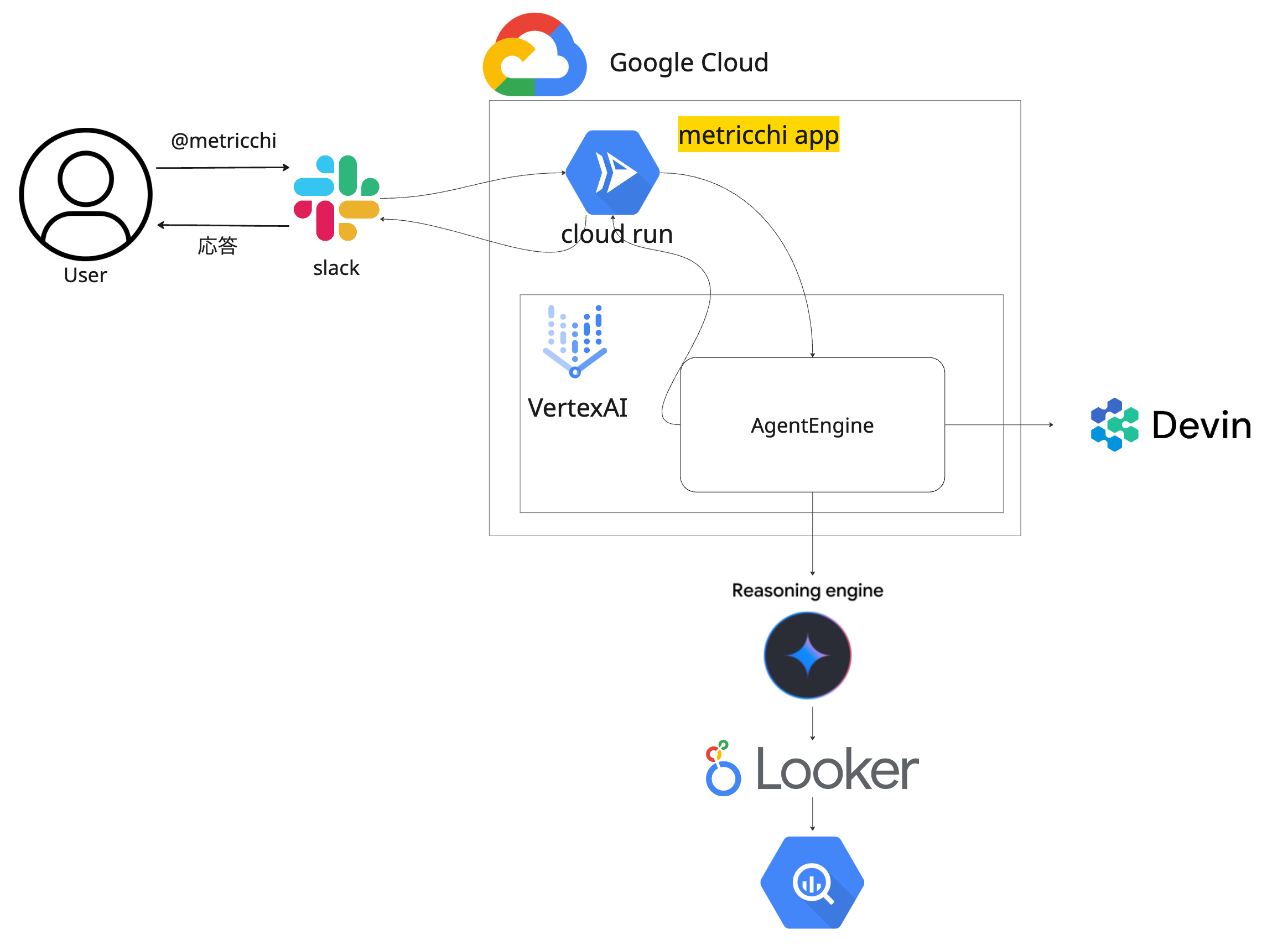 |
- Slackからユーザーがメトリっちをメンションして問い合わせると、Lookerセマンティックレイヤー経由で正しいデータ定義の指標をレスポンスしてくれます。
- 各種データ出力要件に特化したサブエージェントに適切に依頼を出し分けてデータ出力を実施するような構成にしています。
- Devinに会話履歴とフィードバック内容を渡すことで
メトリっち自身,LookerConversationalAnalyticsAPIのDataAgent,Looker製セマンティックレイヤー,dbtで管理されたディメンショナルモデリング層のうち、必要な箇所を改善するPRを作成します。 - エージェントが構成されているSlackApp+CloudRun+AgentEngineの構成は弊社のこちらのブログにて紹介されています。 https://tech.timee.co.jp/entry/ai-agent-platform
エージェント周りの構成
エージェント周りの概念図がこんな感じです。
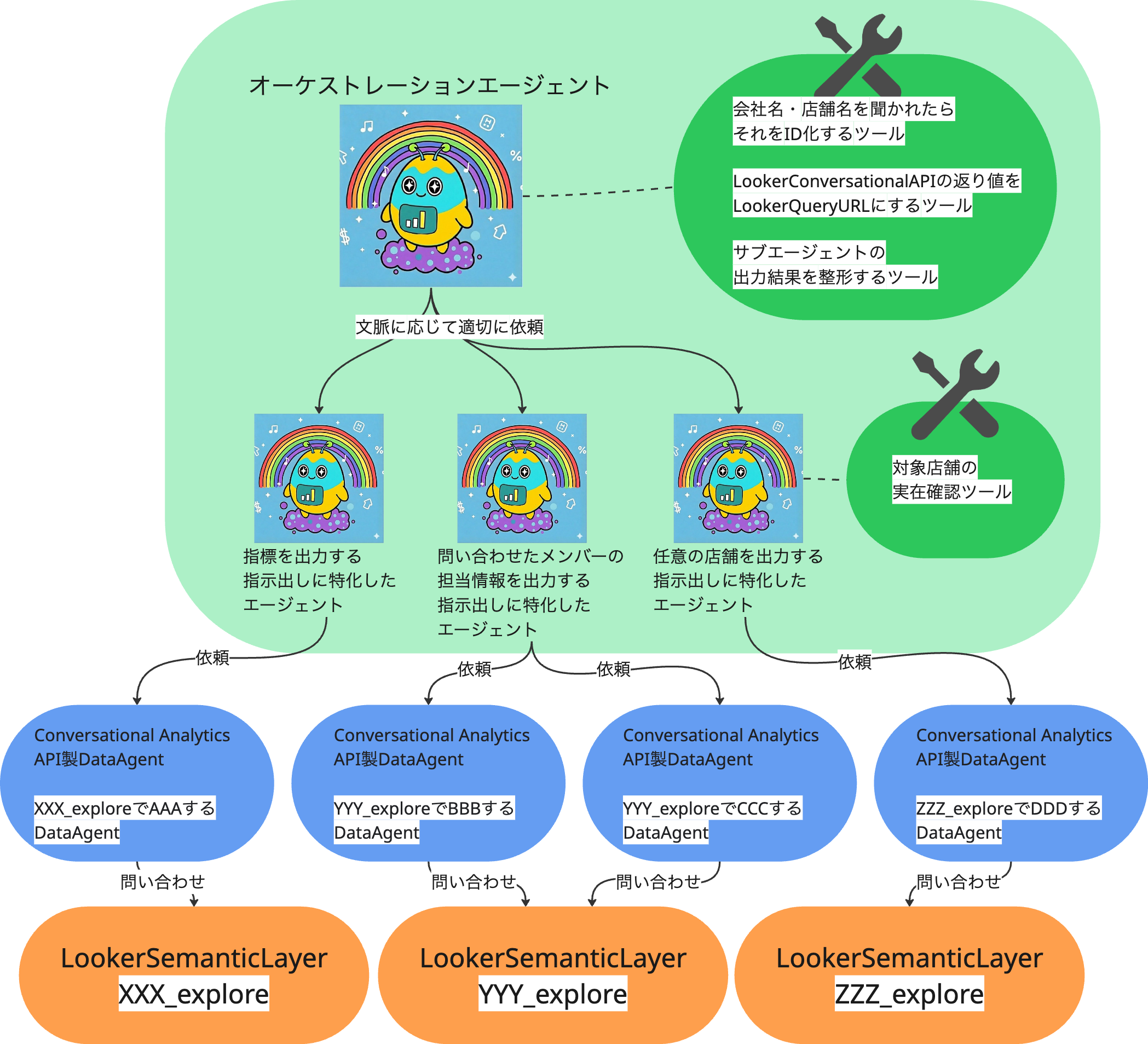
メトリっちのエージェント構成
メトリっちは
- データ出力要件ごとに特化した
サブエージェント - ユーザーからの応答をサブエージェントに渡したり、サブエージェントの出力結果をユーザー向けに整形したりする
オーケストレーションエージェント
で構成されており、それぞれのエージェントが必要なToolを持っています。
出力したい要件単位でエージェントを分離することで、単一のエージェントにあらゆる責務を持たせるOneBigPromptな構成を避け、開発とフィードバックがしやすい構成としています。
LookerConversationalAnalyticsAPIのDataAgent構成
-
メトリっちオーケストレーションエージェントhas manyメトリっちサブエージェント -
メトリっちサブエージェントhas manyDataAgent -
DataAgenthas oneexplore(=セマンティックレイヤー)
な構成にしており、
出力要件ごとに責務を切り分けたサブエージェントが、その出力要件を満たすために、複数のDataAgentから適切なものを選択してデータ出力を依頼する、という流れになっています。
LookerConversationalAnalyticsAPIのDataAgentもセマンティックレイヤーの出力要件ごとに作るようなデザインにしています。
(aaa_exploreでAの出力要件に最適化されたDataAgentと、aaa_exploreでBの出力要件に最適化されたDataAgentの二つができることを許容するイメージ)
DataAgentが複数のexploreを参照できるようになるリリースも出ていましたが、現時点ではその構成を採用はしていません。
どうやって作ったか
SlackApp + AgentEngine + CloudRunの基盤部分
先ほども紹介した通り基盤部分の詳細はこちらの記事で紹介されています。
検証環境, Staging環境, 本番環境で切られていて、非常に開発体験の良い基盤が整っている状態です。
セマンティックレイヤーとデータモデリング
弊社では、Lookerセマンティックレイヤーに接続されるテーブルについて、dbtを活用してディメンショナルモデリングを徹底しています。
ConversationalAnalyticsAPIのLookerDataAgent
LookerDataAgentのプロンプトは
-
system_instruction: エージェントの役割とペルソナを定義 -
golden_queries: 定義可能な一般的な質問や重要な質問に対する正解例 -
glossaries: データ内にまだ含まれていないビジネス用語、専門用語、略語の定義 -
additional_descriptions: システムの説明で他に説明されていない一般的な追加指示やコンテキスト
を渡してあげることで性能を向上させられます。
ざっくりしたプロンプト例はこちらです。
- system_instruction: "主な役割は、「売上」Exploreにクエリを実行して担当者ごとの実績を出力することです。担当者はメールアドレスもしくは人名で渡される場合があります。メールアドレスの場合はxxx_explore.tanto_member_email, 人名の場合はxxx_explore.tanto_member_nameで担当者を絞り込んでください。また、出力されたデータが要求された粒度になっているか確認してください。"
- golden_queries:
- golden_query:
- question: xxx@timee.co.jpの担当企業の売り上げを月毎に出力して
- looker_query:
- model: xxx_model
- view: xxx_explore
- fields:
- xxx_explore.sales
- xxx_explore.month
- filters: xxx_explore.tanto_member_email=xxx@timee.co.jp
- additional_descriptions:
- text: yyyという文言が指示に含まれている場合、売上の定義はyyy_uriageを使用してください
- text: zzzという文言が指示に含まれている場合、売上の定義はzzz_uriageを使用してください
LookML側のsynonymsパラメータを育てていきたいので、glossariesは使いません。
DataAgentに対する定義反映
ConversationalAnalyticsAPIのDataAgentはTerraformなどで現状コード管理ができないので
DataAgentの作成と定義変更をYAMLベースで実施できるようにGithubActionsを作成しました。
DataAgentへの定義反映のコード管理化はこちらのレポジトリを参考にしました。
https://github.com/looker-open-source/ca-api-quickstarts
サブエージェントとメインエージェントの構成
各エージェントの責務を分離することで
- 他ユースケースのコンテキストを汚染することなく、出力ユースケースごとの専門性を作り込める
- ユースケースごとにエージェントが分離しているので、役割ごとのプロンプトを修正することができ、修正範囲が明確になる
ことを狙っています。
「サブエージェント」を採用するか「ツールとしてのエージェント」を採用するかで悩みましたが、疎結合にすることで相互の影響を最小化しつつ、ガシガシ改善を回していける「ツールとしてのエージェント」方針を現時点では採用しています。
コードはこんな感じです。
metricchi_coordinator = LlmAgent(
name="metricchi_coordinator",
model=MODEL,
description=(
"Lookerのデータ出力をサポートするコーディネーターエージェント。"
"Lookerに問い合わせる各種データ出力エージェントをコントロールします。"
),
instruction=prompt.METRICCHI_COORDINATOR_PROMPT,
tools=[
FunctionTool(xxxx),
FunctionTool(yyyy),
# Sub-agents as AgentTools (coordinator has no direct tools)
AgentTool(agent=xxx_agent),
AgentTool(agent=yyy_agent),
AgentTool(agent=zzz_agent),
],
)
Devinを活用した自律改善フロー
フィードバックボタンがsubmitされた場合、メトリっちが動作するAgentEngineからAPI経由でDevinのセッションを作成することで開発を依頼します。
- メトリっち自身
- ConversationalAnalyticsAPIのLookerのDataAgent
- セマンティックレイヤー
- ディメンショナルモデリング
のいずれかに対してフィードバックをもとに改善PRを作成します。
Devinへの開発依頼時に渡す情報
フィードバックボタンを押された場合に以下の情報をDevinに渡します。
- ユーザーとメトリっちの
セッションの会話履歴全体を取得して整形したもの-
idとsession_idを使ってAgentEngineのAPIから取得します。
-
- Slackのフィードバックモーダルに入力された
目的が達成できたかどうかの評価と自由記入のフィードバック内容
DevinのPlaybookについて
Devinにメトリっち改善用の/metricchi_improve という命名のplaybookを作成しました。
playbookの中身をざっくり簡略化したものがこんな感じです。
## Overview
自然言語で社内指標出力を可能にするデータエージェント:メトリっちの改善フィードバックに対応します。 改善要望ごとに改修するべき対象が異なります。
## What's Needed From User
ユーザーがメトリっちと交わしたAgentEngine上の会話履歴
メトリっちを利用した結果のユーザー評価(目的のデータを出せた, 目的のデータを出せなかった, 目的のデータを出せたかわからない)
## Procedure
会話履歴を確認して問題の部分を特定する
ユーザー評価と会話内容に応じて、以下のいずれかの修正対象を決定する:
- エラーで途中で処理が落ちている場合 => metricchi自身を修正する https://github.com/OurCompanyOrganization/hogehoge
- 「この言葉で伝えた時にこの指標が出力されて欲しい」 => lookerレポジトリでsynonymパラメータを定義してその言葉をカバー可能にします。 https://github.com/OurCompanyOrganization/fugafuga
- 「思ったのと違う指標が出力された」=> lookerレポジトリでConversationalAnalyticsAPIのDataAgentの指示を修正します https://github.com/OurCompanyOrganization/fugafuga
- 「ユーザーの要求している指標がそもそもLooker上に存在しない」=> dbtレポジトリで対象の指標が出力できるようなデータモデリングを実施します。 https://github.com/OurCompanyOrganization/blabla
- 「ユーザーの要求に対してエージェントが期待していない挙動をしている」 => metricchi自身を修正する https://github.com/OurCompanyOrganization/hogehoge
AgentEngineからDevinにリクエストを投げる時に、リクエストの先頭に
!metricchi_improve の文字列をくっつけて投げることでこのplaybookが起動します
作ってみてどうだったか
- Devinはやっぱりとてもとても賢い
-
会話履歴+ユーザー評価のフィードバック+playbookの指示でかなり確度の高い修正提案を作成してくれます。
-
- Slackでデータをサクッと知りたいケースって実はそんなにない?
- 元々は「Slackの会話中の気になった時に正しい指標がパッと出せる」って最高のデータ体験じゃないか?という仮説から作ってみたのですが、自分の手元にそれができるものが来てもあんまり使わないんだなあと思ってしまっているところがあります。
- 僕を含めデータの専門スキルを持つメンバーは、欲しいデータを自分でサクッと出力できます。他の専門スキルを持つメンバーは、このツールに求める体験が異なりそうであるため、特にビジネスサイドのメンバーにリリースして、反応を確かめてみたいです!
- 元々は「Slackの会話中の気になった時に正しい指標がパッと出せる」って最高のデータ体験じゃないか?という仮説から作ってみたのですが、自分の手元にそれができるものが来てもあんまり使わないんだなあと思ってしまっているところがあります。
- 本リリースまでもう少し磨き込みたい
- ⬆︎のような初期仮説との食い違いもあったりして、今はまだデータ部内に閉じたプレリリースのステータスです。
- 使い込んでもらってガンガン改善を回していきたいのですが、経験上こういったアプリはリリース直後に「これは使える!」とメンバーに第一印象を植え付ける必要があると思っているので、もう少し精度を高めてリッチな機能を付与してからリリースしようとしているところです!
- 会話履歴+フィードバック内容をDevinに渡す構成は弊社で開発している他のLLMエージェント全てで応用できるので、この機能をさまざまなLLMエージェントに搭載していこうと思っています。
気になりそうな部分への回答
メトリっちの精度はどうなの?
任意の指標をフィルター+group byして出力するような要件には対応できるようになってきていると思います。(例:昨日のXXX会社のYYYを見せて)
が、
- 同じ概念が別々のセマンティックレイヤーに乗っている場合の最適なものの選択
- ユビキタス言語から外れた指示(アクティブアカウント数をAA数と略した指示など)
あたりがまだ精度が低く、全社リリース前に最低限の改善をするべきだと感じています。
フィードバックをベースに自律改善するようにした理由
「エージェント経由でセマンティックレイヤーで定義されたデータを取得する体験」を改善しようと考えた時に、
- エージェント自身
- ConversationalAnalyticsAPIのDataAgentの定義
- Lookerセマンティックレイヤー
- ディメンショナルモデリング
と、動かせる変数がたくさんあり、自社に最適化された優れた体験を提供するには、どれも細かいドメインの反映とチューニングが必要となってきます。
この細かいチューニングを人間がし続けることは難しいので、フィードバックをベースに自律改善を繰り返せるようにすることで、まだ世の中にベストプラクティスが存在しない領域で、高速に試行錯誤を繰り返していきたいと考えています。
Devinの改善の精度はどうなの?
体感4割くらいがそのままマージできるなって印象です。playbookをもっと磨き込むのとDevinのWikiに適切な知識をフィードバックすることで、もっと精度は上がると思っています。
また、一発生成されたPullRequestが微妙であっても、PullRequestからDevinのセッション画面に遷移して細かい指示を出せば良いため、フィードバックに対する一次対応業務はほぼ問題なくできていると思っています。
- この名前ではこの指標が見たい
- こういうチャットが返ってきた方が見やすい
- プロンプトインジェクションできてしまう
などさまざまなフィードバックに対して、ほぼそのままマージできるPullRequestが作れていてとてもありがたいです。
まとめ
- セマンティックレイヤーやモデリングを改善するには、地道なドメイン回収と改善作業が必須! ⇒ でもめんどうくさいし工数も取れない
- そもそもLookerを見に行って検索して指標を探して出力するのがめんどうくさい
- 各種AIが正しい指標をベースに判断できるようにしたい
これら課題を解決するためにメトリっちというアプリケーションを作ってみました
現時点での実践を経た所感としては
- セマンティックレイヤーやモデリングを改善するための地道なドメイン回収と改善作業
- ⇒ かなり強力にカバーしてくれそう
- そもそもLookerを見に行って検索して指標を探して出力するのがめんどうくさい
- ⇒ 何を見るか考えて伝えるより既存のダッシュボードへの導線を整えた方が良さそう
- ⇒ ダッシュボード化されていない単一レコードをサクッと知る経験としては良さそう
- 各種AIが正しい指標をベースに判断できるようにしたい
- ⇒ メトリっちの精度さえ上がれば確度高く実現できそう
って感想です。
本リリースを経てこれら課題が解決できるものにできるか最後の調整をしていきたいと思います!
一緒にメトリっちを育てながらプロダクトに向き合いたい方、ご興味があればぜひ1度お話ししましょう!