はじめに
IBM App Connect Enterprise(以下 ACEと略します)は、IBMが提供するシステム間連携のソフトウェアで、システム間のさまざまなギャップを整理して連携を実現します。
ACEでは入力メッセージを相手先システムのニーズにあわせて加工・編集します。そのため、元になるメッセージがACEのなかでどのように扱われるかを把握しておく必要があります。
当記事では、
- メッセージモデルの考え方
- 入力ノードでのメッセージの変換
- Computeノードのメッセージ入出力
について解説していきます。この記事では入出力にMQを使うメッセージを想定しています。
メッセージモデル
ACE内で扱うメッセージのフォーマット定義として「メッセージモデル」があります。
メッセージモデルでは、メッセージの論理的な構造(メッセージがどのような項目を保持するか)、および管理するフォーマット(スキーマ)を定義します。
これをメッセージフローとは別に定義します。
メッセージモデルの作成
ここではメッセージモデルの作成手順をご紹介します。こちらをモデルの概念を理解する材料のひとつにしていただきたいです。

アプリケーションの右クリックメニューで New > Message Model を選択します。

取り扱うデータフォーマットにあわせた手段が複数用意されていますが、ここではCSV textを選択します。

モデルをDFDLというスキーマで作成するようリードされました。次の工程へ進むためにいくつかの選択肢があります。ここではウィザード利用を選択します。

CSVデータの構造について確認が入ります。
改行コード、レコード内の項目数などを指定します。
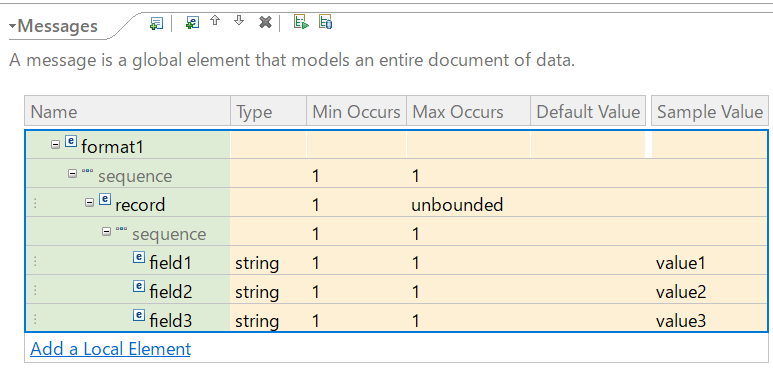
メッセージモデルの詳細編集を行ないます。手前までの入力で自動生成されたデータ構造をもとに、フィールド名やデータ型などを実際のデータにあわせて修正します。
メッセージモデルはアプリケーションプロジェクトのなかの「XML and DFDL Schemas」というフォルダに、xsdファイルとして作成されます。
入力ノードでのメッセージモデル変換
MQInputノードのプロパティで、Input Message Parsingにて使用するメッセージモデルを選択します。この設定で、メッセージモデルに定義したレイアウトでACE内にメッセージが作成されます。
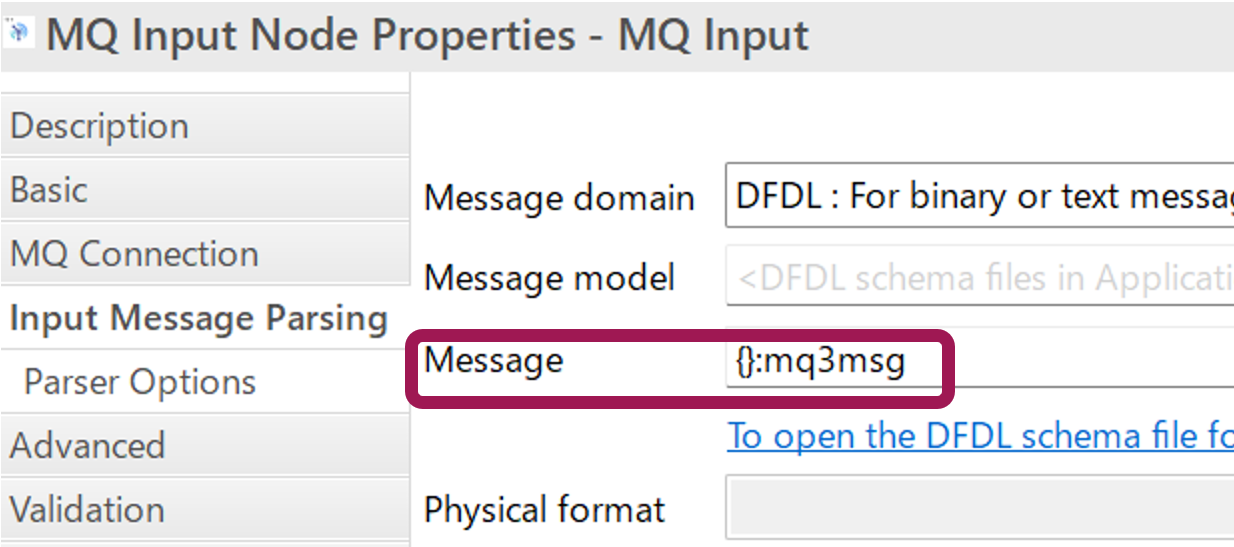
ここではmq3msgというメッセージモデルが指定されています。
Computeノードでのメッセージ参照
DFDLであれば、
Set var1 = xxxxRoot.DFDL.メッセージモデル名.record.フィールド名;
の書式で、メッセージ内の項目を参照できます。
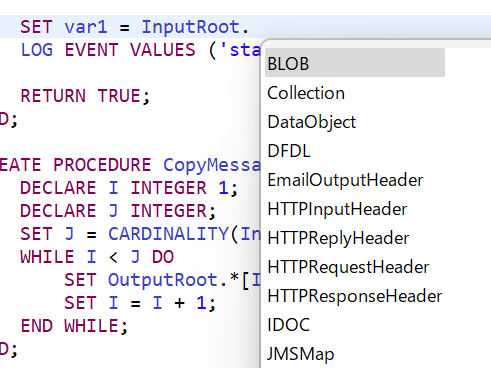
ESQLのエディタ上では、項目を接続するピリオドを入力した後にCtrl+Spaceを押すと次に指定可能な要素がリスト表示されます。文法に慣れない間は勿論、不具合のないコードを作成するうえでもこの補完機能は積極的に利用してください。
Computeノードでのメッセージ入出力
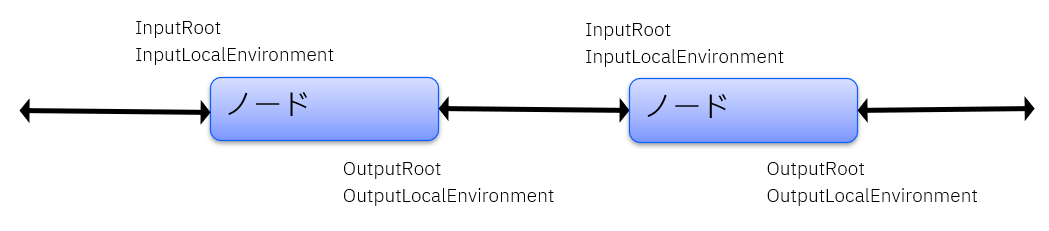
Computeノード前後のデータの受け渡しは、上のようになっています。
Rootはメッセージデータ、LocalEnvironmentはメッセージ外のフロー制御用パラメータです。
(もう1つInputExceptionListという要素がありますが、当記事では省略します)
前ノードから、InputRoot、InputLocalEnvironmentという名前でデータが引き継がれます。
次ノードにデータを渡す際には、
- データを編集せずInputXXをそのまま次ノードに渡す
- 次ノードへ渡すOutputXXという変数を別に作成し、ここにデータを作成する
の2パターンの渡し方が存在します。
Computeモード
どの情報を出力するかの指定は、ComputeノードのプロパティにあるComputeモード(韻を踏みたいわけではありません![]() )で行ないます。
)で行ないます。
デフォルトではMessageが選択されます。
| モード | ノードからの出力 | 利用する状況 |
|---|---|---|
| Message | OutputRoot InputLocalEnvironment |
メッセージの内容を変更したい |
| LocalEnvironment | InputRoot OutputLocalEnvironment |
メッセージの内容はそのままに、制御用のパラメータだけ変更したい |
| LocalEnvironment and Message | OutputRoot OutputLocalEnvironment |
色々変更したい |
Computeモードを適切に設定することで、コード量が減り品質面にプラスとなる他、メッセージフロー定義から「このノードで実現したいこと」がある程度把握できるようになり保守性にも寄与します。
OutputRootの編集
OutputRootの内容はゼロからつくることもできますが、前ノードから受け取ったメッセージを継承して必要な編集を行なう流れが基本です。
Computeノードを作成するとESQLのひな形コードが自動的に作成されますが、このなかにOutputRootを作成する関数が2つ準備されています。
CREATE PROCEDURE CopyMessageHeaders() BEGIN
DECLARE I INTEGER 1;
DECLARE J INTEGER;
SET J = CARDINALITY(InputRoot.*[]);
WHILE I < J DO
SET OutputRoot.*[I] = InputRoot.*[I];
SET I = I + 1;
END WHILE;
END;
CREATE PROCEDURE CopyEntireMessage() BEGIN
SET OutputRoot = InputRoot;
END;
| 関数名 | 機能 |
|---|---|
| CopyEntireMessage | メッセージ全体をまるごとコピーする処理 |
| CopyMessageHeaders | メッセージのヘッダ部分のみをコピーする処理 |
ノードで必要な処理にあわせて、いずれかをMainから呼び出すという使い方になります。
メッセージのうち一部だけを修正して次ノードに送るような場合は、CopyEntireMessage を実行した後に必要な編集を追加する、という使い方にすると記載するコード量が少なく済みます。
おわりに
メッセージの構造を理解することが、メッセージフロー作成の第一歩になります。このポイントをおさえて、システム間連携の世界へスムーズに入っていただきたいです。
さらに詳しい情報をお探しの方へ
IBMの最新情報、イベント情報、さらに役立つ資料は、以下のIBM Communityでも発信・格納されています。
最新のトレンドや有益な情報をチェックするために、ぜひご覧ください!
-
WebSphere: IBM Community - WebSphere
WebSphere関連の最新情報やディスカッション、イベント情報、技術資料を公開中! -
ELM (Engineering Lifecycle Management): IBM Community - ELM
ELMに関する最新のイベント情報、ナレッジ共有、便利なドキュメントをチェック! -
Integration: IBM Community - Integration
Integrationに関する最新のイベント情報、ナレッジ共有、便利なドキュメントをチェック!