はじめに
「GraphQL」という技術を今から把握したいという方向けに、IBMが提供するAPI Connect for GraphQLというサービスを使ったデータアクセス体験を解説します。
記事は次の3つに分かれます。当記事では、複数のデータソースからの値取得をまとめて実行するアンダーフェッチを試します。
- GraphQLの解説と準備
- オーバーフェッチ対応
- アンダーフェッチ対応(当記事)
製品名が長いため、以下「4GraphQL」と記載します。この記事では、前の記事で構築した環境を使用することを前提にして、ここにRDBのデータソースを追加します。
実現すること
サーバーから「観光に行きたい上位10国とその都市のリスト」を取得します。
観光に行きたい上位10国はAPIで提供され、国の都市リストはDBに格納されています。これをクライアントから個別に呼び出す場合、単純に考えると
- APIから国リストを取得(1アクセス)
- RDBから各国の都市リスト取得(10アクセス)
の計11アクセスが必要です。これを1アクセスで完了させるようにします。
準備
RDBの構築
インターネットからアクセスできるRDBが必要になります。実現の手段は色々考えられますが、なるべく手数が少なく準備できることを意識して、クラウドのVM上でMariaDBコンテナを使用します。
sudo dnf -y install podman
podman run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=XXXXXX --name mariapod mariadb:latest
podman exec -it mariapod bash
ポッド内の操作は次のようになります。
mariadb -u root -p
MariaDB [(none)]> create database graphtest;
RDBへのデータ登録
今回はRELATIONAL DATASET REPOSITORYで公開されているWorldデータセットのCityテーブルを使用します。
次のテーブル項目を持っています。
| 列名 | データ型 |
|---|---|
| ID | int |
| Name | char |
| CountryCode | char |
| District | char |
| Population | int |
データ元はパブリックアクセス可能となっています。DBeaverなどのDBアクセスツールでローカルMariaDBとこのリポジトリに接続し、テーブル定義とデータをエクスポート/インポートで移送します(記事の本題ではないため詳細手順は省略します)。
4GraphQLの設定
RDBに接続する手順は、前記事でREST APIに接続した流れと同じです。異なる点に絞って記載します。
バックエンドの指定
バックエンドの選択では「MySQL」を選択します。

接続に必要な情報を指定します。
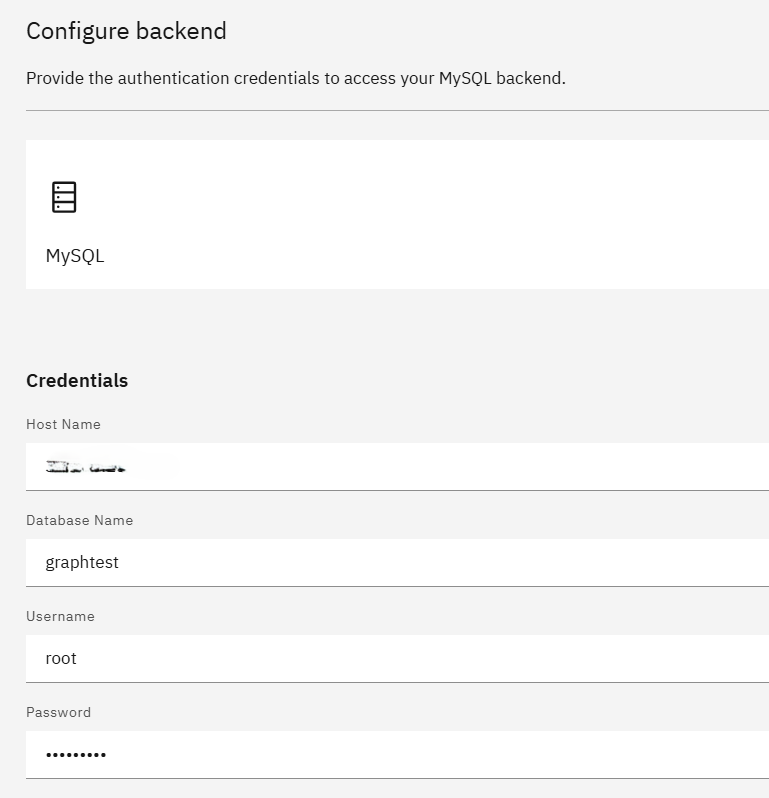
この入力に合わせたimport文が生成されるため、これをCLIで実行します。
定義ファイルの確認
import文の実行後に、各定義ファイルは次のように更新されています。
schema @sdl(files: ["rootQuery/index.graphql", "mysql/index.graphql"]) {
query: Query
}
追加したデータソース向けの定義ファイル(index.graphql)が追加されています。
type City {
CountryCode: String!
District: String!
ID: Int!
Name: String!
Population: Int!
}
type Country {
Capital: Int
Code: String!
Code2: String!
Continent: String!
:
:
Region: String!
SurfaceArea: Float!
}
"""
The following queries are just a set of examples of how to access your schema.
Feel free to modify them or aggregate more.
"""
type Query {
" Queries for type 'City' "
cityById(ID: Int!): [City]
@dbquery(type: "mysql", table: "City", configuration: "mysql_config")
cityByIdAndName(ID: Int!, Name: String!): [City]
@dbquery(type: "mysql", table: "City", configuration: "mysql_config")
cityList: [City]
@dbquery(type: "mysql", table: "City", configuration: "mysql_config")
cityPaginatedList(first: Int!, after: Int!): [City]
@dbquery(
type: "mysql"
query: """
SELECT `CountryCode`, `District`, `ID`, `Name`, `Population` FROM `City` LIMIT ? OFFSET ?
"""
configuration: "mysql_config"
)
import文には接続情報しか指定していませんが、4graphQLが自動で対象ユーザーの扱えるテーブル定義を収集し、データ型とクエリーを自動生成しています。RDBをデータソースにする場合も、各種定義は自動的に生成されるため、開発者は実現したいクエリー作成に集中することができます。
クエリーはデータ型をもとに基本形として出力されており、このままでも機能しますが修正して使うことが前提になります。
最初の記事でリゾルバについて触れていますが、4GraphQLでは宣言的にリゾルバを構成します。手続き型のコードを書かずに済みますが、細かいアクセスが必要な場合は、cityPaginatedListの例にあるようにSELECT文を記載する必要があります。
DB接続用の情報は、別の定義ファイルに記録されています。
configurationset:
- configuration:
name: mysql_config
dsn: root:<PASSWORD>@tcp(IPAddress)/graphtest
Explorerの状態
次のように今回追加されたクエリーが反映されます。

アンダーフェッチ対応
フェデレーション
ここまで作成したリゾルバ定義は、単一データソースへのアクセスでした。ここでは、複数の結果を組み合わせるために「フェデレーション」という対応を行ないます。これは複数のクエリーを一括して実施するという機能です。
今回は「観光に行きたい上位10国の都市リスト」を取得するという仕様のため、上位10国のクエリー結果に「各国の都市リスト」を要素として追加します。
materializer ディレクティブ
結果を結合するためにmaterializerという機能を使います。英単語としては「実現する」のような意味ですが、4GraphQLでは複数クエリーを結合する機能を持ちます。RDBでのサブクエリーと近いかもしれません。
ここまで作成された定義ファイルに次の修正を行ないます。
RDB用のスキーマ定義追加
type Query {
cityByCountryCode(CountryCode: String!): [City]
@dbquery(type: "mysql", table: "City", configuration: "mysql_config")
こちらは、国コードを検索条件として都市リストを取得するためのスキーマ定義です。
(CountryCode: String!)の部分は、クエリーのパラメータを示しており、[City]はCity型のリストを示しており、これが戻り値になります。
フェデレーションのスキーマ定義追加
type TopCountriesAndCities {
id: String
Code: String
Cities: [City]
@materializer (query: "cityByCountryCode", arguments: {name: "CountryCode", field: "Code"})
}
type Query {
topCountriesAndCities: [TopCountriesAndCities]
@rest(endpoint: "http://(IPAddress):3000/countryname")
}
アンダーフェッチのスキーマを定義します。topCountriesAndCities は、国取得のAPIを呼び出して結果を返却しますが、データ型(TopCountriesAndCities)には、APIが提供する項目のほかに、Citiesが追加されています。
ここでmaterializerを使用し、Citiesを埋めるために上で追加定義したcityByCountryCodeクエリーを呼出しています。その際、抽出条件(CountryCode)に渡す値は、APIから取得したCodeを当てはめるという指定です。
適用結果

Explorerにはこのように表示されます。
子階層となるCitiesにも、どの項目を抽出するかを指定することができます。

上記設定をクエリーに変換するとこのような形になります。

実行した結果がこちらになります。
国名の1件目に日本、Citiesには日本のなかの代表的な都市がリスト表示されています。JokohamaやKiotoという発音ベースの表記があることはこの記事を作成してるうえで一番の発見かも...
このように、必要なデータを1リクエストで取得することが可能です。
N+1問題
クライアントの視点では、1リクエストで結合した結果を取得できることが確認できました。
ただ、GraphQLサーバーからバックエンドに対しては複数回のリクエストは必要です。
4GraphQLでは「同一リクエストを複数回発行しない」「結果をキャッシュする」といった最適化処理を内部で実行しています。これにより、サーバーサイドの負荷軽減にも寄与するところはあるでしょう。
この記事のまとめ
3記事を通して、GraphQLを使うことでクライアントからのリクエストに柔軟性を持たせる、また簡潔に記載ができることを確認してきました。
4GraphQLによる実装の例から、
- ツール側の支援が手厚いこと
- 各種定義は宣言的であること
から実現したいことに注力することができるというツールの特徴も確認することができました。
Mutationや4GraphQLの分析機能など、まだ紹介できていない要素も多いですが、ここからGraphQLの可能性を感じていただけると幸いです。
参考
StepZen解説:宣言的な GraphQL Federation
StepZenブログ:GraphQL Optimization: It’s More Than N+1