はじめに
「GraphQL」という技術を今から把握したいという方向けに、IBMが提供するAPI Connect for GraphQLというサービスを使ったデータアクセス体験を解説します。
記事は次の3つに分かれます。当記事では、GraphQLの簡単な説明と、実際に触れる環境づくりまでを対象とします。
- GraphQLの解説と準備(当記事)
- オーバーフェッチ対応
- アンダーフェッチ対応
GraphQLが解決する課題
GraphQLはAPIを使うクライアント側が、柔軟に必要なデータにアクセスするための技術というイメージを持っていただくとよいかと思います。
課題になりうるシーンは大きくは次の2つです。
オーバーフェッチ
各種サービスで提供されるAPIの情報量は、クライアントの要求する内容と合致しない場合があります。
または当初は合致していたが、運用中にずれてくることも考えられます。
クライアントのニーズにあわせてAPI提供者が仕様を変更、または新ニーズ用に追加してくれるのであれば問題ありませんが、対応のための調整期間や開発・保守コストなどを考えると期待どおりにいかないこともあります。
API提供者がサービス事業者だと、個別クライアントニーズに対応する可能性は低いです。代わりに想定ニーズの最小公倍数的な「全部入り」のAPIを提供することで、幅広いニーズに対応するというアプローチをよく見かけます。この場合、1APIで取得できる項目数が数百だったりすることもあり、使わないデータがほとんどというレスポンスを受信するのはクライアント側にとってあまり望ましい状況ではありません。
アンダーフェッチ
1回のサーバーアクセスで必要なデータが全て取れるのであれば効率的ですが、データがスクラッチアプリとSaaSに分かれて配置されていたり、マイクロサービスの潮流から必要なデータが複数のドメインに分散しているようなケースもあります。
クライアントが分散したサービスに1つずつリクエストを行ない、データを整理して利用するという方式も取れますが、クライアント側で行なう処理が煩雑になります。
クライアント側機能の位置づけにもよりますが、ロジックよりビュー機能としての比重が高いフロントエンドプログラムであれば、なるべくシンプルなロジックで必要なデータを取得したいところです。
両者に共通しているのは、不必要なトラフィックが目立つということで、これらは処理速度がユーザー体験に結びつきの深いモバイルアプリでは解決すべき課題といえます。
GraphQLとは
GraphQLの「QL」は、SQLのQLと同じ「クエリーランゲージ」です。
「Graph」は折れ線グラフなどExcelが出力するグラフのことではなく、ノードとエッジという概念で事象を表現するグラフ理論のことを指しています。グラフ理論の詳細はネット検索またはAIに問合せしてみてください。
graphql.orgの解説では
With GraphQL, you model your business domain as a graph by defining a schema; within your schema, you define different types of nodes and how they connect/relate to one another.
とあるので、複数データソース・ドメインの繋がりをグラフと捉えているようです。
構成要素として、サーバー側の機能としてスキーマとリゾルバ、クライアント側の機能としてクエリーがあります。
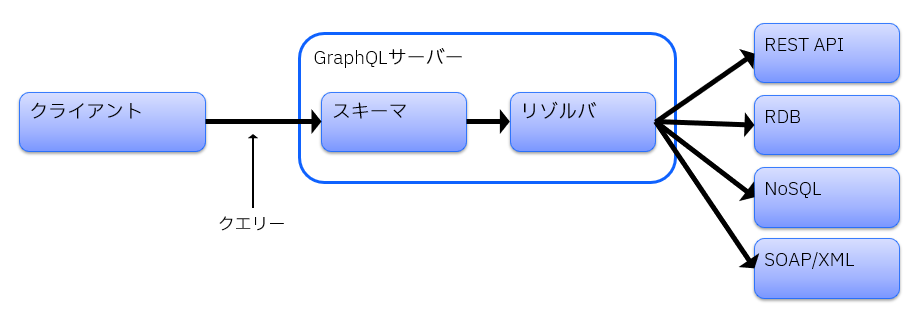
スキーマ
サーバー側が公開するデータ項目の定義になります。スキーマ定義言語(SDL)という構文を使って準備します。
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
}
type Query {
user(id: ID!): User
}
Javaの開発に例えると、バリューオブジェクトの定義をする感覚に似ています。
リゾルバ
スキーマで定義したデータを収集して提供するロジック部分になります。
GraphQLサーバーの実装によって、さまざまな実現方法があります。
クエリー
クライアントからリクエストする、欲しいデータのフォーマットです。
スキーマのなかから必要なデータ項目だけを取捨選択することができます。
query {
user(id: "123") {
id
name
}
}
この例では、上で定義したスキーマの特定userでposts部分以外のデータだけを戻すように指定しています。
参照のための「Query」と、更新のための「Mutation」の2つの機能がありますが、一連の記事ではQueryにフォーカスします。
IBM API Connect for GraphQL について
ここまで記載したのはGraphQLの仕様であり、これを実際に動かすためには、
- スキーマ仕様の値のやりとりを保証する
- クエリーを理解する
- リゾルバを動かしてデータ操作を行なう
というGraphQLの処理を担う実装が必要になります。
「IBM API Connect for GraphQL」はGraphQLサーバの実装の1つになります。
名称については、
- 以前から同分野で好評の「StepZen」という製品をリブランドして23年に「IBM API Connect Essentials」という名称でリリース
- 24年10月に「IBM API Connect for GraphQL」という名称に変更
という経過を辿っています。
現在の名前のほうが分かりやすくていいですね。
記事投稿時点では、まだまだ「StepZen」で検索したほうが多くの情報がヒットしますので、ご興味ある方はこちらの名前でも検索してみてください。
この製品の特徴としては、
- スキーマ作成やリゾルバ実装のアシスト
- クエリー検証用のサンドボックス環境
- アクセス分析の諸機能
があり、GraphQLの開発・運用をクイックに実現できます。
SaaSとオンプレミスの2形態で提供されていますので、ビジネス環境に合わせた配置が可能です。
IBM API Connect for GraphQL の利用を開始する
SaaS環境で無償版が提供されていますので、この記事ではこちらを利用します。
ここでは、StepZenのサイトからIBMアカウントを使用してSaaSを利用します。
右上の「Start for Free」のボタンからIBMアカウントを利用してログインします。アカウントは無料で作成できます。
IBM SaaSの利用状況を示す、次のような画面が表示されます。

「API Connect Essentials」のタイトルがリンクになっており、ここをクリックします。
Essentialsのインスタンスリストが表示されます。今回の手順では1件表示されます。

ここから「起動」を選択すると管理画面に到達します。
管理画面では、左側に各機能のメニューアイコンが配置されています。行ないたいタスク別のボックスが画面下側に配置されているため、ここから必要な作業を開始することもできます。

明日以降再接続する手順
ブラウザを終了して再度接続する場合には、こちらのリンクからIBM提供のSaaS一覧を表示します。
ここから「API Connect Essentials」をクリックすることで復帰できます。
この記事のまとめ
GraphQLがもたらすメリットと、実際に利用するためのスタート地点までを記載しました。
次の記事では、データソースへの接続手順と、製品の「Explorer」と呼ばれる機能で情報を絞り込むオーバーフェッチ対応を確認していきます。