HADR とは
HADR(High availability disaster recovery)とは、Db2において提供される、データベース単位の高可用性を実現する機能です。
データベースが2つ稼働した状態で、プライマリの役割を担うデータベース上の更新情報(ログ情報)をスタンバイ・データベースに転送&再生することで本番データベースのコピーを作成し、有事の際にはスタンバイ・データベースに切り替えてサービスが継続することができます。
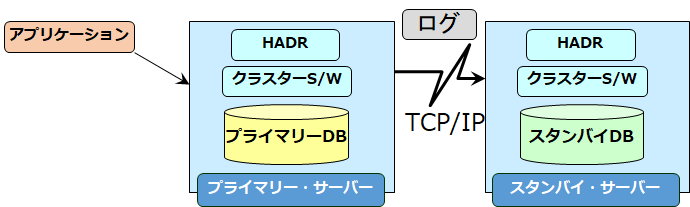
データベース・サーバの高可用性構成として従来から使われているのはアクティブ・スタンバイ方式(主DBサーバがダウンしたら、共有ディスクを引き継いで副DBサーバが起動する)で、Db2でも多く採用されます。
HADRを利用する高可用性構成では、ディスク引継ぎおよび破損回復が不要となることと、またスタンバイDBが既に活動化されている状態であるため、高速な引継ぎが可能となるメリットがあります。
参考:Db2製品マニュアル [高可用性災害時リカバリー (HADR)]
Db2 on OpenShift における HADR
Db2 on OpenShift 環境でも、HADRによる高可用性構成を利用することができます。
Db2 11.5.5 on OpenShift からの新機能として、Db2 Operatorの登場により、HADR構成も簡単に組むことができるようになりました(※同一ネームスペース内のHADR)。
-
HADR構成前に、以下のセットアップが済んでいることを前提とします
- Db2 Operatorが導入済みであること (補足:Db2 Operatorとは)
- Db2u Cluster(Db2本体) のインスタンスを2セット導入済みであること
(HADRのプライマリとスタンバイ)- プライマリ、スタンバイは同一のリリース・レベルである必要があります
-
Db2u Cluster導入手順はこちらに書いていますので、ここでは割愛します
-
Db2 on OpenShift でHADR構成を組むには下記3つの構成パターンがあり、今回は①の構成です
- ① 同一ネームスペース(プロジェクト)内
- ② 同一クラスター内 / 異なるネームスペース間
- ③ 異なるクラスター間
-
Db2 HADRには複数の同期モードが提供されますが、下記手順で構成したHADRの同期モードは、
デフォルトの「NEARSYNC」となります -
Db2 11.5.6 では、HADR マルチスタンバイ構成がサポートされるようになりました
- 複製するスタンバイを3つまで構成することが可能です
- ただし、自動引き継ぎは1次スタンバイのみがサポートされます(この制約はオンプレ版と同じ)
参考:
導入環境
以下の環境に Db2 11.5.5 on OpenShift をデプロイし、HADR構成としました。
| 項目 | バージョン |
|---|---|
| OS(bastion) | RHEL 7.7 |
| OS(worker) | RHEL 7.7 |
| OCP(Client) ※ | 4.5.0-202007240519.p0-b66f2d3 |
| OCP(Server) ※ | 4.5.7 |
| Kubernetes | v1.18.3+2cf11e2 |
| NFS | 4.2 |
| Db2 OLTP | 11.5.5 |
検証環境の構成
下記構成のOCP環境にDb2をデプロイします。
- Bastion Node x1
- Master Node x3
- Worker Node x3
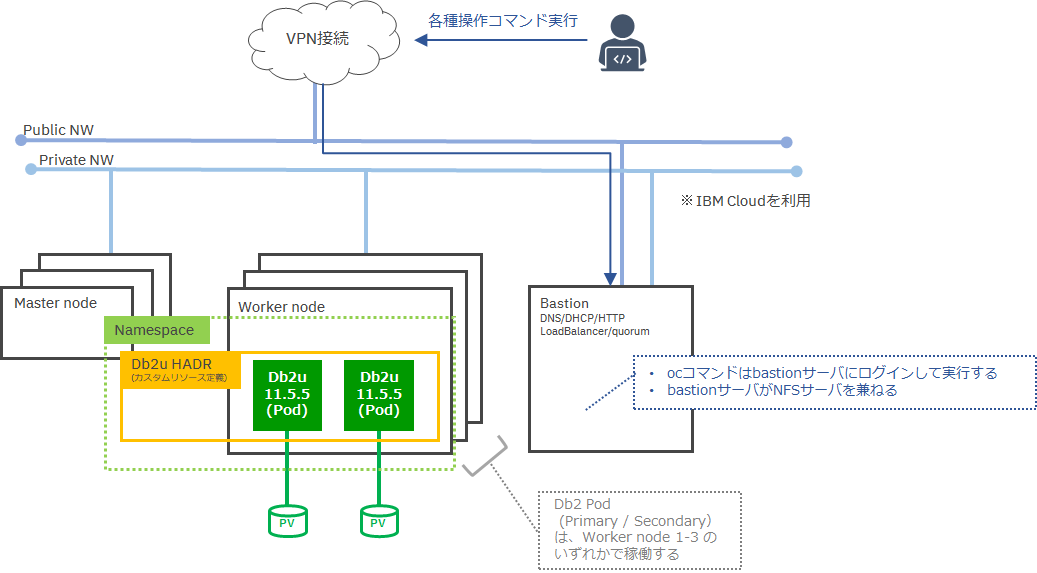
作業を行うノード / ユーザ
コマンドはすべてBastionノードから実行しています。
また、ユーザは以下の用途で使い分けています。
| ユーザ | 用途/補足 |
|---|---|
| rootユーザ | NFSサーバのセットアップ用 |
| OCPユーザ | ocコマンド実行 (cluster-admin権限付与) |
コマンド実行ノード、ユーザについてはご使用の環境に応じて決めてください。
また、ocコマンド実行前には、oc login が必要となります。
導入の流れ
同一ネームスペース(プロジェクト)内にプライマリ/セカンダリのPodを両方稼働させるシンプルな構成であれば、以下のようなごく少ない手順でHADR構成を組むことができます。
- Db2uHADRカスタムリソース作成
- プライマリPod -> セカンダリPod へのバックアップイメージ/キーストア転送
- Db2uHADRカスタムリソースのステータス確認
- HADRの状態確認
< 補足 >
Db2は、製品提供のDb2uClusterカスタムリソースのインスタンスを新規作成することで、StatefulSetとしてデプロイされます。
その後、作成済のDb2uClusterインスタンス2つと紐づける形でDb2uHADRカスタムリソースのインスタンスを新規作成します。
HADRの初期構成においては、プライマリDBのバックアップをスタンバイにリストアすることでスタンバイDBの初期セットアップを行います。OpenShift環境でもこの点は共通で、PVCを共有するか、oc rsync コマンドを利用して、プライマリのPodからセカンダリのPodへとデータベースのバックアップ・イメージを共有する必要があります。
ここでは、後者の方法(oc rsyncコマンドにより、プライマリDBのバックアップ・イメージをセカンダリにコピー)を選択しています。
同一ネームスペース(プロジェクト)内に定義されるDB間のHADR 構成は、こちらのマニュアルに従ってセットアップします。
→ Db2 11.5 KnowledgeCenter[Setting up HADR in a single OpenShift project]
[](1. は OCP Webコンソールから GUIでポチリで完了できそうでしたが、時間切れで環境が無くなってしまったので、残念ながら試すことはできず..)
Step1. Db2uHADRカスタムリソース作成
1-1. Yaml作成
Db2uHADRカスタム・リソースを新規作成するためのYamlファイルを作成します。
HADRのプライマリ、スタンバイとなるシングル構成Db2(Db2uCluster) の名前は、以下のとおりです。
- プライマリ ---> db2ucluster-1
- スタンバイ ---> db2ucluster-2
導入済みのDb2uClusterの名前を指定し、yamlファイルを保存します。
apiVersion: db2u.databases.ibm.com/v1alpha1
kind: Db2uHadr
metadata:
name: example-hadr
spec:
primary:
db2uCluster: "db2ucluster-1"
standby:
db2uCluster: "db2ucluster-2"
1-2. Db2uHADRカスタム・リソース作成
oc create コマンドでカスタム・リソースを作成します。(即時に応答が戻ります)
$ oc create -f /work/db2-11.5.5/db2u-hadr-test.yaml
db2uhadr.db2u.databases.ibm.com/example-hadr created
1-3. ステータス確認
Db2uHadrカスタム・リソースのステータスを確認します。
example-hadrという名前でDeployされていることがわかります。
(この時点では STATE: NotReadyとなっていて、まだHADRセットアップは完了していません。)
$ oc get Db2uHadr
NAME HADRPRIMARY HADRSTANDBY STATE AGE
example-hadr db2ucluster-1 db2ucluster-2 NotReady 9s
HADRのセットアップ状況は、以下のコマンドで確認することができます。
$ oc get db2uhadr <Db2uHadr-Name> -o yaml | awk '/^status:/,/hadrSettings:/'
実行例:
$ oc get db2uhadr example-hadr -o yaml | awk '/^status:/,/hadrSettings:/'
status:
conditions:
- lastTransitionTime: "2020-12-25T10:47:30Z"
message: Done
status: "True"
type: Creating Db2u HADR configuration files
- lastTransitionTime: "2020-12-25T10:47:28Z"
message: Done
status: "True"
type: Creating Service endpoints for HADR Primary and Standby
- lastTransitionTime: "2020-12-25T10:50:38Z"
message: Done
status: "True"
type: Setting up Primary database copy for HADR
- lastTransitionTime: "2020-12-25T10:47:25Z"
message: Setting up Standby database copy for HADR
status: "False" <--- 「True」に変わったら次のステップへ進む
type: latestPhase
hadrSettings:
上記ステータス・メッセージの「type: Setting up Primary database copy for HADR」が「True」の状態になったら次の手順に進みます。
Step2. バックアップイメージ/キーストア転送
プライマリPod -> セカンダリPod へ、バックアップイメージとキーストアを転送します。
この2つは、現時点ではプライマリPodの「/mnt/blumeta0/db2/backup」ディレクトリに配置されています。
(※)スタンバイPodの同ディレクトリは、この時点では空です
プライマリDBからスタンバイDBにバックアップ・イメージを転送するには、Persistent Volumeの共有もしくは rsync を利用することができます。
① プライマリの /mnt/blumeta0/db2/backup ディレクトリの確認
転送をはじめる前に、プライマリのPodにログインし、転送すべきファイルが作成されていることを確認します。
$ oc rsh c-db2ucluster-1-db2u-0 /bin/bash
$ su - db2inst1
$ date ; pwd ; ls -la /mnt/blumeta0/db2/backup
Fri Dec 25 10:58:29 UTC 2020
/mnt/blumeta0/home/db2inst1
total 540844
drwxrwxrwx. 2 db2inst1 db2iadm1 79 Dec 25 10:50 .
drwxr-xr-x. 10 700 wheel 135 Dec 24 07:31 ..
-rw-r--r--. 1 db2inst1 db2iadm1 553816064 Dec 25 10:49 BLUDB.0.db2inst1.DBPART000.20201225104803.001
-rw-r--r--. 1 db2inst1 db2iadm1 4328 Dec 25 10:50 keystore.tar
スタンバイにコピーする必要のあるアセットである、
- DBバックアップファイル(BLUDB.0.db2inst1.DBPART000.20201225104803.001)
- キーストアファイル(keystore.tar)
が存在することが確認できました。
② rsyncコマンドによる転送
スタンバイ側の /mnt/blumeta0/db2 ディレクトリー直下に、プライマリ側の /mnt/blumeta0/db2/backup ディレクトリーをコピーします。
- rsyncコマンドは、ノード <-> Pod 間で、ディレクトリの転送を行うことのできるツールです
- Pod <-> Pod 間のコピーは出来ない
- ファイル単位の転送は出来ず、ディレクトリを指定してコピーする
- 今回は以下のようにファイル転送を行っています
- 転送元:BastionノードのNFSディレクトリパス (プライマリの/mnt/blumeta0/db2/backupに相当)
- 転送先:スタンバイPodの/mnt/blumeta0/db2ディレクトリ
$ oc rsync /work/nfsdir/Db2NFS_Meta1/db2/backup c-db2ucluster-2-db2u-0:/mnt/blumeta0/db2
sending incremental file list
backup/BLUDB.0.db2inst1.DBPART000.20201225104803.001
backup/keystore.tar
sent 553,955,829 bytes received 55 bytes 7,970,588.26 bytes/sec
total size is 553,820,392 speedup is 1.00
スタンバイPodにログインし、バックアップ・イメージとkeystore tarファイルが転送されていることを確認します。
$ ls -la /mnt/blumeta0/db2/backup
total 540844
drwxrwxrwx. 2 db2inst1 db2iadm1 79 Dec 25 11:08 .
drwxr-xr-x. 10 700 wheel 135 Dec 24 08:51 ..
-rw-r--r--. 1 db2uadm wheel 553816064 Dec 25 10:49 BLUDB.0.db2inst1.DBPART000.20201225104803.001
-rw-r--r--. 1 db2uadm wheel 4328 Dec 25 10:50 keystore.tar
補足:
スタンバイ側に手動コピーしたバックアップ・ファイルとkeystore.tarファイルは、HADRセットアップ完了後は自動削除されるようです。
Step3. Db2uHADRカスタムリソースのステータス確認
ファイルコピー後、しばらく待機すると、HADR構成は自動的に完了します。
HADRセットアップの進捗は、下記コマンドにて確認することができます。
oc get db2uhadrコマンド出力のSTATEが”Complete"となっていたら、HADR構成が完了しています。
$ oc get db2uhadr
NAME HADRPRIMARY HADRSTANDBY STATE AGE
example-hadr db2ucluster-1 db2ucluster-2 Complete 2d14h
補足:
HADR構成完了時点の詳細ステータスメッセージは下記のようになります。
$ oc get db2uhadr example-hadr -o yaml | awk '/^status:/,/hadrSettings:/'
status:
conditions:
- lastTransitionTime: "2020-12-25T10:47:30Z"
message: Done
status: "True"
type: Creating Db2u HADR configuration files
- lastTransitionTime: "2020-12-25T10:47:28Z"
message: Done
status: "True"
type: Creating Service endpoints for HADR Primary and Standby
- lastTransitionTime: "2020-12-25T11:17:00Z"
message: Done
status: "True"
type: Enabling ACR feature for HADR
- lastTransitionTime: "2020-12-25T10:50:38Z"
message: Done
status: "True"
type: Setting up Primary database copy for HADR
- lastTransitionTime: "2020-12-25T11:16:50Z"
message: Done
status: "True"
type: Starting HADR on the Primary database copy
- lastTransitionTime: "2020-12-25T10:47:25Z"
message: Setting up Db2u HADR completed
status: "False"
type: latestPhase
hadrSettings:
Step4. HADRの状態確認
HADRの状態確認は、manage-hadr ツールで行うことができます。
コマンド構文:
$ oc exec -it <Db2uCluster-Pod-Name> -- manage_hadr -status
① スタンバイの状態確認
$ oc exec -it c-db2ucluster-2-db2u-0 -- manage_hadr -status
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -status on the database BLUDB ...
################################################################################
### The HADR status summary ###
################################################################################
Database Member 0 -- Database BLUDB -- Standby -- Up 1 days 02:05:33 -- Date 2020-12-28-02.05.47.857426
HADR_ROLE = STANDBY
HADR_STATE = PEER
PRIMARY_MEMBER_HOST = c-db2ucluster-1-db2u-0
STANDBY_MEMBER_HOST = c-db2ucluster-2-db2u-0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/27/2020 00:00:17.102237 (1609027217)
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
PEER_WINDOW_END = 12/28/2020 02:07:46.000000 (1609121266)
GOVERNOR: RUNNING
The HADR action -status was successful
② プライマリの状態確認
$ oc exec -it c-db2ucluster-1-db2u-0 -- manage_hadr -status
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -status on the database BLUDB ...
################################################################################
### The HADR status summary ###
################################################################################
Database Member 0 -- Database BLUDB -- Active -- Up 1 days 02:08:40 -- Date 2020-12-28-02.07.21.217258
HADR_ROLE = PRIMARY
HADR_STATE = PEER
PRIMARY_MEMBER_HOST = c-db2ucluster-1-db2u-0
STANDBY_MEMBER_HOST = c-db2ucluster-2-db2u-0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/27/2020 00:00:17.092367 (1609027217)
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
PEER_WINDOW_END = 12/28/2020 02:09:21.000000 (1609121361)
GOVERNOR: RUNNING
The HADR action -status was successful
動作確認1: 切り替え(failover)
現スタンバイPodからtakeoverコマンドを実行し、プライマリ -> スタンバイへの切替を行います。

① フェイルオーバー実行
takeoverコマンドは即時に戻ります。切替自体も数分程度で完了します。
(トランザクションが無い状態)
$ oc exec -it c-db2ucluster-2-db2u-0 -- manage_hadr -takeover
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -takeover on the database BLUDB ...
################################################################################
### Running takeover HADR on bludb ###
################################################################################
Executing HADR role-switch via Db2 Governor ...
current leader is c-db2ucluster-1-db2u-0
new leader is c-db2ucluster-2-db2u-0
################################################################################
### The manage_hadr command completed an HADR takeover. ###
################################################################################
The HADR action -takeover was successful
② フェイルオーバー後の新Primaryデータベースの状態確認
新プライマリ(旧スタンバイ) の「HADR_ROLE」が「PRIMARY」に変わっていることが確認できます。
$ oc exec -it c-db2ucluster-2-db2u-0 -- manage_hadr -status
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -status on the database BLUDB ...
################################################################################
### The HADR status summary ###
################################################################################
Database Member 0 -- Database BLUDB -- Active -- Up 1 days 03:11:08 -- Date 2020-12-28-03.11.22.516943
HADR_ROLE = PRIMARY
HADR_STATE = PEER
PRIMARY_MEMBER_HOST = c-db2ucluster-2-db2u-0
STANDBY_MEMBER_HOST = c-db2ucluster-1-db2u-0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/28/2020 03:11:07.878952 (1609125067)
PRIMARY_LOG_FILE,PAGE,POS = S0000013.LOG, 4, 346478652
STANDBY_LOG_FILE,PAGE,POS = S0000013.LOG, 4, 346478652
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000013.LOG, 4, 346478652
PEER_WINDOW_END = 12/28/2020 03:13:18.000000 (1609125198)
GOVERNOR: RUNNING
The HADR action -status was successful
新プライマリのPodにログインし、データの参照ができることも確認します。
$ oc exec -it c-db2ucluster-2-db2u-0 -- /bin/bash
[db2uadm@c-db2ucluster-2-db2u-0 /]$ su - db2inst1
Last login: Mon Dec 28 03:13:10 UTC 2020 on pts/3
[db2inst1@c-db2ucluster-2-db2u-0 - Db2U db2inst1]$ db2 connect to bludb
Database Connection Information
Database server = DB2/LINUXX8664 11.5.5.0
SQL authorization ID = DB2INST1
Local database alias = BLUDB
[db2inst1@c-db2ucluster-2-db2u-0 - Db2U db2inst1]$ db2 "insert into t1 values (11,'aa')"
DB20000I The SQL command completed successfully.
[db2inst1@c-db2ucluster-2-db2u-0 - Db2U db2inst1]$ db2 "select * from t1"
C1 C2
----------- --------
1 a
2 b
11 aa
3 record(s) selected.
[db2inst1@c-db2ucluster-2-db2u-0 - Db2U db2inst1]$ db2 terminate
DB20000I The TERMINATE command completed successfully.
[db2inst1@c-db2ucluster-2-db2u-0 - Db2U db2inst1]$ exit
[db2uadm@c-db2ucluster-2-db2u-0 /]$ exit
takeoverが成功し、新プライマリ上のDBに接続しデータアクセス(参照・更新)できるようになっていることが確認できました。
動作確認2: 切り戻し(failback)
テイクオーバー後(=元々のスタンバイPodが新プライマリとしてサービスを提供している状態)、
再度takeoverを行うと、旧プライマリPod のロールがプライマリに戻ります。

① フェイルバック実行
takeoverコマンドは即時に戻ります。切替自体も数分程度で完了します。
(トランザクションが無い状態)
$ oc exec -it c-db2ucluster-1-db2u-0 -- manage_hadr -takeover
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -takeover on the database BLUDB ...
################################################################################
### Running takeover HADR on bludb ###
################################################################################
Executing HADR role-switch via Db2 Governor ...
current leader is c-db2ucluster-2-db2u-0
new leader is c-db2ucluster-1-db2u-0
################################################################################
### The manage_hadr command completed an HADR takeover. ###
################################################################################
The HADR action -takeover was successful
② フェイルバック後の新Primaryデータベースの状態確認
Primary の「HADR_ROLE」が「PRIMARY」に戻っていることが確認できます。
$ oc exec -it c-db2ucluster-1-db2u-0 -- manage_hadr -status
#######################################################################
### Db2 Advanced Edition high availability and ###
### disaster recovery (HADR) management ###
#######################################################################
Running HADR action -status on the database BLUDB ...
################################################################################
### The HADR status summary ###
################################################################################
Database Member 0 -- Database BLUDB -- Active -- Up 0 days 00:17:18 -- Date 2020-12-28-03.28.17.033400
HADR_ROLE = PRIMARY
HADR_STATE = PEER
PRIMARY_MEMBER_HOST = c-db2ucluster-1-db2u-0
STANDBY_MEMBER_HOST = c-db2ucluster-2-db2u-0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/28/2020 03:26:23.011800 (1609125983)
PRIMARY_LOG_FILE,PAGE,POS = S0000014.LOG, 4, 366858652
STANDBY_LOG_FILE,PAGE,POS = S0000014.LOG, 4, 366858652
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000014.LOG, 4, 366858652
PEER_WINDOW_END = 12/28/2020 03:30:14.000000 (1609126214)
GOVERNOR: RUNNING
The HADR action -status was successful
『動作確認1: 切り替え(failover)』でINSERTしたレコードが存在することを、切り戻し後のプライマリPodで確認します。
◇切替後に追加したレコード:
$ db2 "insert into t1 values (11,'aa')"
$ oc exec -it c-db2ucluster-1-db2u-0 -- /bin/bash
[db2uadm@c-db2ucluster-1-db2u-0 /]$ su - db2inst1
Last login: Mon Dec 28 03:34:30 UTC 2020 on pts/3
[db2inst1@c-db2ucluster-1-db2u-0 - Db2U db2inst1]$ db2 connect to bludb
Database Connection Information
Database server = DB2/LINUXX8664 11.5.5.0
SQL authorization ID = DB2INST1
Local database alias = BLUDB
[db2inst1@c-db2ucluster-1-db2u-0 - Db2U db2inst1]$ db2 "select * from t1"
C1 C2
----------- --------
1 a
2 b
11 aa
3 record(s) selected.
[db2inst1@c-db2ucluster-1-db2u-0 - Db2U db2inst1]$ db2 terminate
DB20000I The TERMINATE command completed successfully.
[db2inst1@c-db2ucluster-1-db2u-0 - Db2U db2inst1]$ exit
[db2uadm@c-db2ucluster-1-db2u-0 /]$ exit
exit
---> スタンバイDBへの切替後にレコード追加を行った処理についてHADRデータベース間で無事にログ転送が行われ、切り戻し後のプライマリDBでも該当の更新処理内容が反映されていることが確認できました。
付録 db2pd -hadr 出力
プライマリ、スタンバイそれぞれのPodにログインし、db2pdにてHADRステータス情報を確認した結果を添付しておきます。
① プライマリ
$ oc exec -it c-db2ucluster-1-db2u-0
$ su - db2inst1
$ db2pd -hadr -db bludb
Database Member 0 -- Database BLUDB -- Active -- Up 1 days 02:37:33 -- Date 2020-12-28-02.36.14.870306
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS = TCP_PROTOCOL
PRIMARY_MEMBER_HOST = c-db2ucluster-1-db2u-0
PRIMARY_INSTANCE = db2inst1
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = c-db2ucluster-2-db2u-0
STANDBY_INSTANCE = db2inst1
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/27/2020 00:00:17.092367 (1609027217)
HEARTBEAT_INTERVAL(seconds) = 5
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 19152
HADR_TIMEOUT(seconds) = 120
TIME_SINCE_LAST_RECV(seconds) = 2
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 0.000024
LOG_HADR_WAIT_ACCUMULATED(seconds) = 0.125
LOG_HADR_WAIT_COUNT = 3152
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 361280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_REPLAY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_RECV_BUF_SIZE(pages) = 4300
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 125000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 120
PEER_WINDOW_END = 12/28/2020 02:38:11.000000 (1609123091)
READS_ON_STANDBY_ENABLED = N
HADR_LAST_TAKEOVER_TIME = 12/26/2020 23:58:16.000000 (1609027096)
② スタンバイ
$ oc exec -it c-db2ucluster-2-db2u-0 -- /bin/bash
$ su - db2inst1
$ db2pd -hadr -db bludb
Database Member 0 -- Database BLUDB -- Standby -- Up 1 days 02:25:57 -- Date 2020-12-28-02.26.11.213499
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS = TCP_PROTOCOL
PRIMARY_MEMBER_HOST = c-db2ucluster-1-db2u-0
PRIMARY_INSTANCE = db2inst1
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = c-db2ucluster-2-db2u-0
STANDBY_INSTANCE = db2inst1
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 12/27/2020 00:00:17.102237 (1609027217)
HEARTBEAT_INTERVAL(seconds) = 5
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 19030
HADR_TIMEOUT(seconds) = 120
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 0.000024
LOG_HADR_WAIT_ACCUMULATED(seconds) = 0.125
LOG_HADR_WAIT_COUNT = 3152
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 359360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 629, 328647048
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_REPLAY_LOG_TIME = 12/28/2020 01:00:31.000000 (1609117231)
STANDBY_RECV_BUF_SIZE(pages) = 4300
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 125000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 120
PEER_WINDOW_END = 12/28/2020 02:28:11.000000 (1609122491)
READS_ON_STANDBY_ENABLED = N
HADR_LAST_TAKEOVER_TIME = NULL
関連記事
◆Db2 11.5.5 on OpenShift デプロイ手順
https://qiita.com/mi-kana/items/6266fcdcdc3b71d8a0fb
◆OpenShift環境へのDb2 Operator導入手順
https://qiita.com/mi-kana/items/c3fb640d671caf624eb8
◆Db2 11.5.5 on OpenShift:GUIベースのデプロイ手順
https://qiita.com/mi-kana/items/f429c7e4e86f6077df84
以上です。