Python 3.8 に導入1した LOAD_GLOBAL 命令用の per-opcode cache について紹介します。
LOAD_GLOBAL 命令
Python のグローバル変数のロードはローカル変数のロードに比べて遅いです。そのためにグローバル変数に繰り返しアクセスする場合は一旦ローカル変数に格納するというテクニックがあったりします。
$ python3 -m timeit -s '
> def foo():
> for _ in range(1000):
> sum
> ' -- 'foo()'
10000 loops, best of 5: 29.9 usec per loop
$ python3 -m timeit -s '
def foo():
_sum = sum
for i in range(1000):
_sum
' -- 'foo()'
20000 loops, best of 5: 16.7 usec per loop
この例では速度比は2倍弱ですが、これはループのオーバーヘッドを含んでいるので、ロード命令単体での速度比は3倍くらいはあります。
ローカル変数は関数をコンパイルする時に整数のインデックスがつけられ、ローカル変数用の配列からそのインデックスでアクセスしているので高速です。
>>> def foo():
... s = 1
... s
...
>>> import dis
>>> dis.dis(foo)
2 0 LOAD_CONST 1 (1)
2 STORE_FAST 0 (s)
3 4 LOAD_FAST 0 (s) # 0 番目のローカル変数をロードする命令
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
一方、グローバル変数をロードは次のように実現されています。
- コンパイル時に名前一覧の配列が作られる
- LOAD_GLOBAL 命令の引数に名前のインデックスが渡される
- 名前一覧配列からインデックスアクセスで名前を取り出す
- その名前をモジュールのグローバル変数 dict から探索する
- (存在しなかった場合)ビルトイン変数 dict から探索する
>>> def foo():
... sum
...
>>> dis.dis(foo)
2 0 LOAD_GLOBAL 0 (sum) # 0番目の名前 (="sum") でグローバル変数をロードする
2 POP_TOP
4 LOAD_CONST 0 (None)
6 RETURN_VALUE
>>> foo.__code__.co_names # 名前一覧配列
('sum',)
配列アクセスよりも遅いdict の探索を多ければ2回実行するのでグローバル変数アクセスには時間がかかってしまいます。
dict のバージョン
Python 3.6 で dict の実装を変更したタイミングで、 ma_version という変数が dict に追加されました。
グローバルなカウンタを dict を変更するたびにインクリメントし、それを ma_version にセットするという実装になっています。そのため、別の dict や、同じ dict でも何かが変更されていると ma_version は異なります。これを使ってグローバル変数dictとビルトイン変数dictのバージョンを覚えておけば、2回目以降は前回の探索結果を再利用できます。
per opcode cache
LOAD_GLOBAL 命令だけを高速化したい場合は LOAD_GLOBAL 命令の引数でアクセスされる名前一覧配列のインデックスをキーにキャッシュを実装することもできます。しかし今後他の命令にもキャッシュを実装することを考えて、 per opcode cache (opcache) を実装しました。
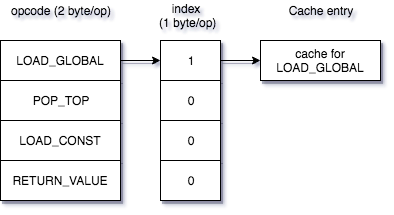
Python の opcode は一命令あたり2バイト (word code とも呼ばれます) になっています。関数が1000回実行された時にキャッシュ用の領域を確保します。キャッシュは比較的大きいデータが必要になる2ので、1命令あたり1バイトのインデックステーブルをこのときに作成します。最終的に 命令数1 + LOAD_GLOBAL命令数(キャッシュエントリサイズ) バイトの領域を利用します。
効果
$ local/py38/bin/python3 -m timeit -s '
> def foo():
> for _ in range(1000):
> sum
> ' -- 'foo()'
10000 loops, best of 5: 20.4 usec per loop
$ local/py38/bin/python3 -m timeit -s '
> def foo():
> _sum = sum
> for _ in range(1000):
> _sum
> ' -- 'foo()'
20000 loops, best of 5: 18.1 usec per loop
違う条件でコンパイルしたバイナリなので最初の Python 3.7 の結果と直接は比較できませんが、ローカル変数アクセスとの違いがかなり小さくなっているのが分かります。高速化のために一旦ローカル変数に置いておくというテクニックはあまり推奨されなくなっていくでしょう。
実際のライブラリを利用したベンチマークスイート (pyperformance) の結果はこのキャッシュ導入前後でこうなっています。
$ ./cpython/python -m perf compare_to master.json opcache_load_global.json -G --min-speed=2
Slower (2):
- pickle: 19.1 us +- 0.2 us -> 19.7 us +- 0.8 us: 1.03x slower (+3%)
- unpickle_list: 8.66 us +- 0.04 us -> 8.85 us +- 0.06 us: 1.02x slower (+2%)
Faster (23):
- scimark_lu: 424 ms +- 22 ms -> 384 ms +- 4 ms: 1.10x faster (-9%)
- regex_compile: 359 ms +- 4 ms -> 330 ms +- 1 ms: 1.09x faster (-8%)
- django_template: 250 ms +- 3 ms -> 231 ms +- 2 ms: 1.08x faster (-8%)
- unpickle_pure_python: 802 us +- 12 us -> 754 us +- 9 us: 1.06x faster (-6%)
- pickle_pure_python: 1.04 ms +- 0.01 ms -> 991 us +- 15 us: 1.05x faster (-5%)
- hexiom: 20.8 ms +- 0.2 ms -> 19.8 ms +- 0.1 ms: 1.05x faster (-5%)
- logging_simple: 18.4 us +- 0.2 us -> 17.6 us +- 0.2 us: 1.05x faster (-4%)
- sympy_expand: 774 ms +- 5 ms -> 741 ms +- 3 ms: 1.04x faster (-4%)
- json_dumps: 28.1 ms +- 0.2 ms -> 27.0 ms +- 0.2 ms: 1.04x faster (-4%)
- logging_format: 20.4 us +- 0.2 us -> 19.6 us +- 0.3 us: 1.04x faster (-4%)
- richards: 147 ms +- 2 ms -> 141 ms +- 1 ms: 1.04x faster (-4%)
- meteor_contest: 189 ms +- 1 ms -> 182 ms +- 1 ms: 1.04x faster (-4%)
- xml_etree_iterparse: 226 ms +- 2 ms -> 217 ms +- 2 ms: 1.04x faster (-4%)
- sympy_str: 358 ms +- 3 ms -> 345 ms +- 4 ms: 1.04x faster (-4%)
- sqlalchemy_imperative: 44.0 ms +- 1.2 ms -> 42.4 ms +- 1.2 ms: 1.04x faster (-4%)
- sympy_sum: 167 ms +- 1 ms -> 161 ms +- 1 ms: 1.04x faster (-4%)
- nqueens: 217 ms +- 1 ms -> 211 ms +- 1 ms: 1.03x faster (-3%)
- fannkuch: 1.09 sec +- 0.01 sec -> 1.07 sec +- 0.00 sec: 1.03x faster (-3%)
- raytrace: 1.11 sec +- 0.02 sec -> 1.08 sec +- 0.01 sec: 1.03x faster (-3%)
- dulwich_log: 122 ms +- 1 ms -> 119 ms +- 1 ms: 1.03x faster (-3%)
- logging_silent: 419 ns +- 5 ns -> 410 ns +- 5 ns: 1.02x faster (-2%)
- sympy_integrate: 33.5 ms +- 0.1 ms -> 32.8 ms +- 0.2 ms: 1.02x faster (-2%)
- pathlib: 40.8 ms +- 0.4 ms -> 40.0 ms +- 0.5 ms: 1.02x faster (-2%)
今後について
LOAD_GLOBALよりも動作が複雑で難しいのですが、属性アクセスのLOAD_ATTR, LOAD_METHODに対するキャッシュは実現したいです。
他には {"a": foo(), "b": bar()} のようにキーが文字列だけで構成された dict display を構築する CONST_MAP_KEY という命令があるのですが、この命令を使う時にハッシュテーブルを毎回構築するのではなく構築済みのハッシュテーブルから dict を高速に作成するようにするアイデアもあります。
一方で、1000回実行したらキャッシュを構築するという今のやり方はシンプルすぎるのでその辺の改良は必要になってくるかもしれません。