📚 関連書籍
「ゼロから触ってわかった!Databricks × Airbyte」
クラウド時代のデータ基盤を“なぜ難しいのか”から丁寧にほどくガイドが完成しました。
Ingestion / LakeFlow / DLT / CDC をやさしく体系化し、
Airbyte × Databricks の真価を引き出す設計思想まで詰め込んだ一冊です。
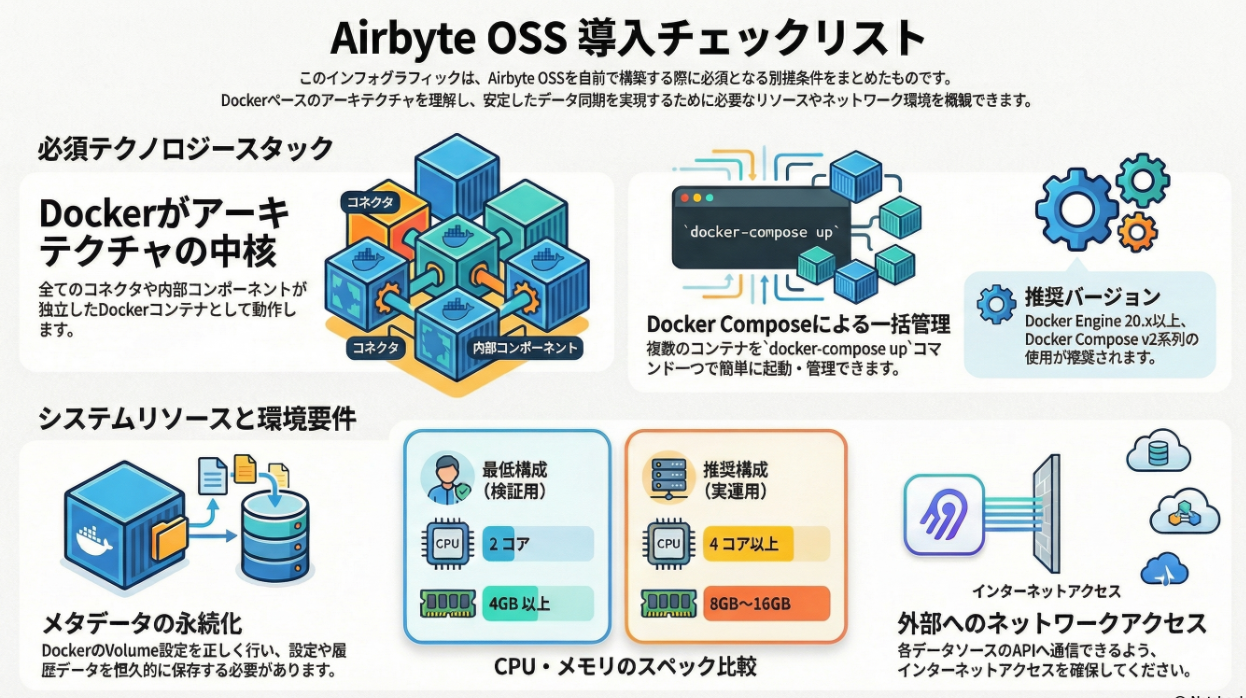
Airbyteアーキテクチャ基礎
必要環境(Docker / Compose / CPU / メモリ)
Airbyte OSS を本格的に使い始める前に、
多くの人が最初につまずくのが 「結局どれくらいの環境が必要なのか?」 という点です。
GitHub を見ると Docker / Docker Compose が前提になっており、
なんとなく「重そう」「ローカルでは厳しいのでは?」という印象を持たれがちです。
しかし実際には、
Airbyteは“最初は軽く、スケール時に重くなる”設計 になっています。
本記事では、Airbyte OSS を前提に、
最低限必要な環境から、実運用を見据えたリソース設計まで を
アーキテクチャ視点で整理します。
なぜDocker / Docker Composeが必須なのか 🐳
Airbyte OSS は、
マイクロサービス前提のアーキテクチャ で設計されています。
内部には、
- Server
- Worker
- Scheduler
- Temporal
- Web UI
- データベース
といった複数のコンポーネントが存在し、
それぞれが独立したプロセスとして動作します。
これを素直にローカル環境で管理しようとすると、
- プロセス管理が煩雑
- バージョン差異が出やすい
- 再現性が低い
という問題が発生します。
そこで Airbyte は、
Docker を唯一の公式実行環境 として採用しています。
Docker Compose を使うことで、
- 複数サービスを一括起動
- 依存関係を明示的に管理
- 環境差異を極小化
できるため、
OSSとして非常に現実的な選択です。
「Dockerが必須」というより、
Dockerでしかこの複雑さを扱えない
と理解した方が正確でしょう。
最低限必要なCPU / メモリの目安 💻
Airbyte公式ドキュメントでは、
最低限の推奨環境 が示されています。
目安としては以下です。
- CPU:2 core
- メモリ:4〜8 GB
- ストレージ:数十GB以上
これは、
- UI操作
- 少量データの同期
- PoC / 検証用途
を想定した構成です。
実際には、
- コンテナが常時複数起動している
- Temporal や DB もメモリを消費する
ため、
メモリ4GBは「動くが余裕はない」 レベルです。
ローカル検証でも、
- CPU:4 core
- メモリ:8 GB
程度あると、
体感的にかなり安定します。
ここで重要なのは、
Airbyte自体が重いのではなく、並列性を前提にしている
という点です。
Workerがリソースを食う理由 🔥
Airbyteにおいて、
最もリソースを消費するのは Worker です。
なぜなら Worker は、
- コネクタ実行
- API通信
- データ変換
- 書き込み処理
といった「実データ処理」を一手に担うからです。
さらに重要なのが、
- 同期ジョブごとに Worker が起動する
- 同時実行数が増えると線形に負荷が増える
という特性です。
つまり、
- 接続数が増える
- 同期頻度が上がる
- フルロードが走る
と、
CPU・メモリ消費は一気に跳ね上がります。
そのため、
- 少量データ → 軽い
- 本番運用 → 一気に重くなる
という“ギャップ”が生まれやすいのです。
これは欠点ではなく、
スケール可能な設計の裏返し だと捉えるべきポイントです。
Docker Compose構成で意識すべきポイント ⚙️
Docker Compose で Airbyte を動かす際、
次の点を意識するとトラブルを避けやすくなります。
- 同時Sync数を抑える
- フルリフレッシュは時間帯を分ける
- メモリ不足時はWorkerが落ちやすい
- ログと一時ファイルのディスク使用量
特にローカル環境では、
- Docker Desktop のメモリ上限
- CPU割り当て
がボトルネックになりがちです。
「Airbyteが不安定」というより、
Dockerに十分なリソースを渡せていない
ケースがほとんどです。
これは実運用でも同様で、
- Airbyteの問題
- インフラ設計の問題
を切り分けて考えることが重要です。
本番を見据えた環境設計の考え方 🏗️
Airbyte OSS を本番で使う場合、
ローカル検証と同じ感覚では成立しません。
重要なのは、
- 同期数
- 同時実行数
- データ量
- 同期頻度
を明確にしたうえで、
- CPUコア数
- メモリ容量
- スケール方式
を決めることです。
Airbyteは、
- 最初はDocker Compose
- 成長したらKubernetes
という段階的移行を前提にしています。
Docker Compose は
あくまで“入口” であり、
重たい処理をすべて賄う前提ではありません。
この割り切りを理解していないと、
「思ったより重い」という誤解につながります。
まとめると
Airbyte OSS の必要環境は、次のように整理できます。
- Docker / Docker Compose は必須
- 最低限 CPU 2core / メモリ 4GB
- 快適に使うなら 4core / 8GB 以上
- 実運用では Worker が支配的にリソースを消費
Airbyteは、
軽量ツールではなく、スケール前提の基盤 です。
その分、
- 小さく始められる
- 成長に合わせて伸ばせる
というモダンデータスタックらしい特性を持っています。
必要環境を正しく理解することは、
Airbyteを「試す」段階から
「設計して使う」段階へ進むための重要な一歩 です。
📚 関連書籍
Databricks/n8n/Salesforce/AI基盤 を体系的に学べる「ゼロから触ってわかった!」シリーズをまとめました。
MCP
『ゼロから触ってわかった!MCPビギナーズガイド』 ― AIエージェント時代の次世代プロトコル入門 アーキテクチャ・ガバナンス・実装―
MCPというプロトコルは、単なる技術トレンドではなく
「AIとシステムの関係性」そのものを変える可能性を秘めています。
SaaS、AIエージェント、ガバナンス、アーキテクチャ。
その交差点を一度、立ち止まって整理した一冊です。
👉 https://amzn.to/3LcAjgg
Snowflake
ゼロから触ってわかった!Snowflake非公式ガイド ― 基礎から理解するアーキテクチャとCortexによる次世代AI基盤
「結局、DatabricksとSnowflakeは何が違うの?」
一見シンプルですが、機能表を比べるだけでは見えてこない深い問いです。 本書ではこの疑問を軸に、Snowflakeの思想・アーキテクチャ・設計思想を紐解いていきます。「違い」を知ることは、すなわち「現代のデータ基盤の本質」を知ることだからです。
初めてSnowflakeに触れる方には「最初の一冊」として。 なんとなく使っているけれどモヤモヤしている方には「頭の中を整理する一冊」として。 AI時代のエンジニアを目指すための、確かな燃料となる一冊です。
『ゼロから触ってわかった! Snowflake × Databricksでつくる次世代データ基盤 - 比較・共存・連携 非公式ガイド』
SnowflakeとDatabricks――二つのクラウドデータ基盤は、これまで「どちらを選ぶか」で語られることが多くありました。
しかし、実際の現場では「どう共存させるか」「どう連携させるか」が、より重要なテーマになりつつあります。
本書は、両プラットフォームをゼロから触り、構築・運用してきた実体験をもとに、比較・共存・連携のリアルを丁寧に解説する“非公式ガイド”です。
『ゼロから触ってわかった!スペック駆動開発入門 ― SaaS is dead?AI時代のソフトウェア設計論』
本書は、近年現場や技術コミュニティで注目を集め始めた**スペック駆動開発(Spec Driven Development:SDD)**を軸に、
AI時代のソフトウェア設計がどこへ向かおうとしているのかを解き明かします。
なぜ今「コード」でも「GUI設定」でも足りなくなってきたのか。
なぜ業務の意図や判断を、実装の外に出す必要があるのか。
前半では思想や背景を丁寧に整理し、後半ではスペック・実装・実行の三層モデルをサンプルコードとともに具体化します。
Databricks
『Databricks──ゼロから触ってわかった!Databricks非公式ガイド』
クラウド時代の分析基盤を “体験的” に学べるベストセラー入門書。
Databricksの操作、SQL/DataFrame、Delta Lakeの基本、ノートブック操作などを
初心者でも迷わず進められる構成で解説しています。
https://amzn.to/4pzlCCT
『ゼロから触ってわかった!Azure × Databricksでつくる次世代データ基盤 非公式ガイド ―』
クラウドでデータ基盤を作ろうとすると、Azure・Storage・ネットワーク・権限・セキュリティ…そこに Databricks が加わった瞬間、一気に難易度が跳ね上がります。
「結局どこから理解すればいいの?」
「Private Link むずかしすぎない?」
「Unity Catalog って実務ではどう扱うの?」
——そんな “最初のつまづき” を丁寧にほどいていくのが本書です。
👉 https://amzn.to/4ocWcJI
「ゼロから触ってわかった!Databricks × Airbyte」
クラウド時代のデータ基盤を“なぜ難しいのか”から丁寧にほどくガイドが完成しました。
Ingestion / LakeFlow / DLT / CDC をやさしく体系化し、
Airbyte × Databricks の真価を引き出す設計思想まで詰め込んだ一冊です。
『Databricks──ゼロから触ってわかった!DatabricksとConfluent(Kafka)連携!非公式ガイド』
Kafkaによるストリーム処理とDatabricksを統合し、リアルタイム分析基盤を構築するハンズオン形式の一冊。
イベント駆動アーキテクチャ、リアルタイムETL、Delta Live Tables連携など、
モダンなデータ基盤の必須スキルがまとめられています。
『Databricks──ゼロから触ってわかった!AI・機械学習エンジニア基礎 非公式ガイド』
Databricksでの プロンプト設計・RAG構築・モデル管理・ガバナンス を扱うAIエンジニアの入門決定版。
生成AIとデータエンジニアリングの橋渡しに必要な“実務の型”を体系化しています。
資格本ではなく、実務基盤としてAIを運用する力 を育てる内容です。
🧠 Advancedシリーズ(上/中/下)
Databricksを “設計・運用する” ための完全版実践書
「ゼロから触ってわかった!Databricks非公式ガイド」の続編として誕生した Advancedシリーズ は、
Databricksを触って慣れた“その先”――本格運用・チーム開発・資格対策・再現性ある設計 に踏み込む構成です。
Databricks Certified Data Engineer Professional(2025年9月改訂版)のカリキュラムをベースに、
設計思考・ガバナンス・コスト最適化・トラブルシュートなど、実務で必須の力を養えます。
📘 [上]開発・デプロイ・品質保証編
📘 [中]取込・変換・監視・コスト最適化編
📘 [下]セキュリティ・ガバナンス・トラブルシュート・最適化戦略編
n8n
『n8n──ゼロから触ってわかった!AIワークフロー自動化!非公式ガイド』
オープンソースの自動化ツール n8n を “ゼロから手を動かして” 学べる実践ガイド。
プログラミングが苦手な方でも取り組めるよう、画面操作中心のステップ構成で、
業務自動化・AI連携・API統合の基礎がしっかり身につきます。
Salesforce
『ゼロから触ってわかった!Salesforce AgentForce + Data Cloud 非公式ガイド』
Salesforceの最新AI基盤 AgentForce と Data Cloud を、実際の操作を通じて理解できる解説書。
エージェント設計、トピック/アクション構築、プロンプトビルダー、RAG(検索拡張生成)など、
2025年以降のAI×CRMのハンズオン知識をまとめた一冊です。
要件定義(上流工程/モダンデータスタック)
『モダンデータスタック時代の シン・要件定義 クラウド構築大全 ― DWHからCDP、そしてMA / AI連携へ』
クラウド時代の「要件定義」って、どうやって考えればいい?
Databricks・Snowflake・Salesforce・n8nなど、主要サービスを横断しながら“構築の全体像”をやさしく解説!
DWHからCDP、そしてMA/AI連携まで──現場で使える知識をこの一冊で。
💡 まとめ:このラインナップで“構築者の視点”が身につく
これらの書籍を通じて、
クラウド基盤の理解 → 要件定義 → 分析基盤構築 → 自動化 → AI統合 → 運用最適化
までのモダンデータスタック時代のソリューションアーキテクトとしての全体像を
「体系的」かつ「実践的」に身につけることができます。
- PoC要件整理
- データ基盤の要件定義
- チーム開発/ガバナンス
- AIワークフロー構築
- トラブルシュート
など、現場で直面しがちな課題を解決する知識としても活用できます。