📚 関連書籍
※この記事は書籍の一部をベースに再構成しています。もう少し踏み込んだ内容(設計や具体例)は
書籍の中でまとめているので、気になる方はそちらもどうぞ。
データメッシュ
『ゼロから触ってわかった データメッシュ入門 ― 思想・型・組織構造から考えるデータメッシュ』
「Data Mesh を導入すべきかどうか」を断言する本ではありません。
また、「この形が正解だ」と教える本でもありません。
自分たちにとって、どこまで分散し、何を共有し、どこに責任を置くのか。
その判断をするための思考の土台を整理する一冊です。
第5章 Databricks で Hub & Spoke をどう実装するか
Data Mesh を“動かす”具体論
5-1 Databricks を Data Mesh 視点で捉え直す
プラットフォームと思想の関係を整理する
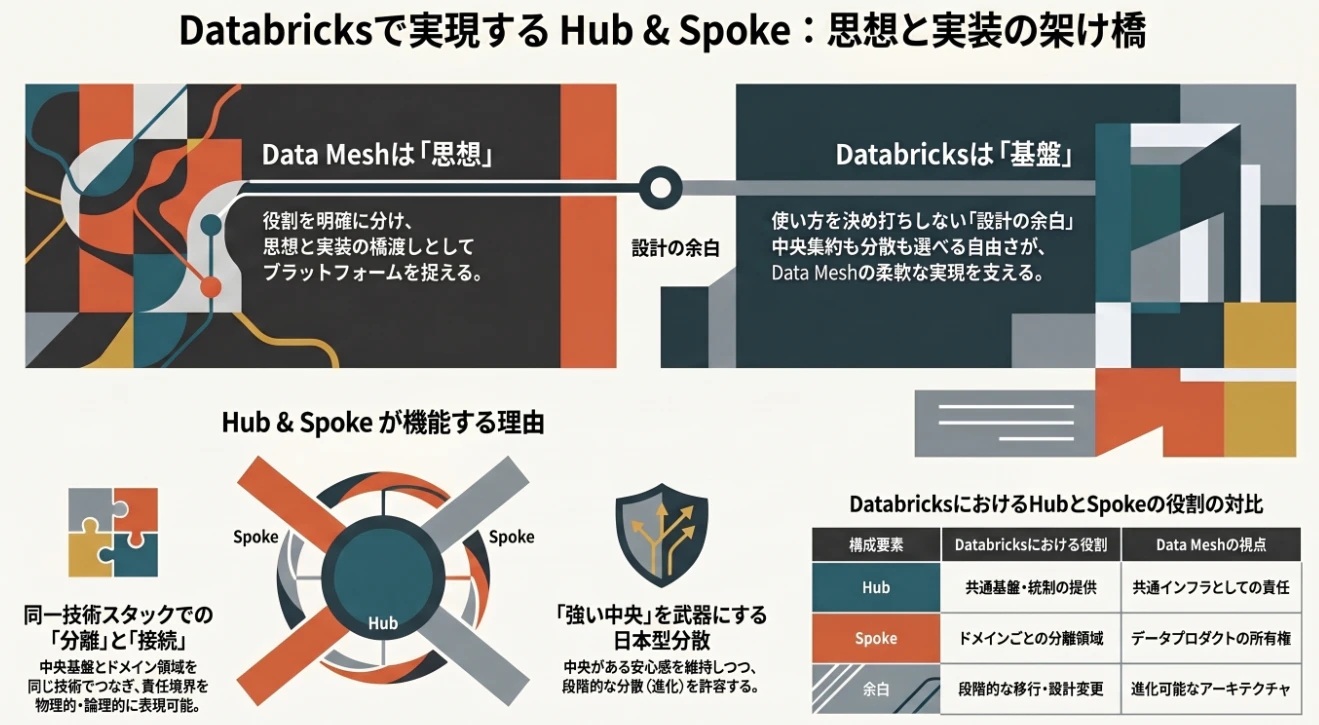
Data Mesh と Databricks は同じものではない 🤔
-
ここまでの章では、Data Mesh を思想として整理してきました。
-
なぜ中央集権に限界があるのか
-
Hub & Spoke が現実解になりやすい理由
-
ガバナンスと分散の関係
そして、ここからはいよいよ実装の話です。
ただし、その前に一つ大切な前提があります。
Databricks は Data Mesh そのものではありません。
Databricks は、特定の思想を押し付けるツールではなく、
データ活用を支えるためのプラットフォームです。
一方、Data Mesh は
- 誰が責任を持つのか
- 誰が意思決定するのか
- 組織をどう分散させるのか
を考える「思想」です。
つまり、両者は同じレイヤーではありません。
- Data Mesh:組織と責任の設計思想
- Databricks:その思想を支える実装基盤
第5章では、この「思想」と「実装」の橋渡しをしていきます。
Databricks は「こう使え」と決めつけない 🧭
- Databricks を触っていると、ある特徴に気づきます。
それは
「正解の使い方が決め打ちされていない」
という点です。
Databricks は
- 巨大な中央DWHのようにも使える
- チーム単位で分離して使うこともできる
- 中央集約にも分散にも対応できる
一見すると、自由すぎて分かりにくい。
しかし Data Mesh の視点で見ると、
この“余白”こそが価値になります。
なぜなら、Data Mesh には唯一の正解構造が存在しないからです。
組織や文化に合わせて、
少しずつ責任の境界を変えながら進化できる。
Databricks は、その柔軟性を壊しません。
Hub & Spoke を自然に表現しやすい ⚙️
- Databricks が Data Mesh 文脈で語られる最大の理由は、Hub & Spoke を自然に表現できることです。
例えば Hub 側では、
- 共通ガバナンス
- セキュリティルール
- 共通データ基盤
- 共通モニタリング
を提供できます。
一方 Spoke 側では、
- ドメイン単位のデータ管理
- 業務ロジック実装
- ドメイン固有分析
を自律的に進められます。
しかも、これらを同じ技術スタック上で実現できます。
無理やり組織を分散させなくてもよい。
中央と現場の役割を保ちながら、段階的に責任移譲できる。
これが現実的な強みです。
「中央集権っぽさ」が逆に武器になる 🏗️
- Databricks は外から見ると、強い中央基盤にも見えます。
そのため、
- 「中央集権なのでは?」
- 「Data Mesh と相性が悪いのでは?」
と感じる人もいます。
しかし、日本企業ではこの“中央感”がむしろ武器になります。
- 安心感がある
- 説明しやすい
- 既存の職能組織と接続しやすい
第4章で整理した通り、
中央があるからこそ分散が機能するケースは多い。
Databricks は、その前提を壊さずに Hub & Spoke を実装できます。
「責任を持たせる」設計がしやすい 🔍
- Data Mesh の本質は、データを管理することではありません。
責任を持たせること
にあります。
Databricks では、
- 誰が作ったか
- 誰が管理するか
- どこまでが責任範囲か
を物理的・論理的に整理しやすい。
例えば、
- カタログ単位
- スキーマ単位
- ワークスペース単位
など、責任境界を明示しやすい構造が取れます。
これは後から責任を説明するのではなく、
最初から責任が見える状態で設計できるという意味です。
Big Bang を強制しない「余白」がある 🌱
-
Databricks が Data Mesh と相性が良い最大の理由は、“途中で変えられる”ことです。
-
最初は中央寄り
-
徐々にドメイン分散
-
成熟度に応じて責任移譲
この段階的な進め方ができます。
Big Bang を強制されない。
これは実務では非常に重要です。
Data Mesh は一度で完成するものではありません。
学習しながら進化する取り組みです。
Databricks は、その前提と相性が良いのです。
ツール選定の話に矮小化しない ⚠️
- ここで注意したいのは、
「だから Databricks を使えば解決する」
という話にしないことです。
大事なのは、
- なぜその構造を選ぶのか
- 誰が責任を持つのか
- どう進化させるのか
を先に決めること。
Databricks は、それを実装しやすい選択肢の一つにすぎません。
まとめると ✍️
- Data Mesh は思想、Databricks は実装基盤
- Databricks は「こう使え」を決めつけない余白がある
- Hub & Spoke を自然に表現しやすい
- 中央を残しながら段階的に分散できる
- 重要なのはツールではなく責任設計
第5章では、ここからさらに具体化します。
- Hub は何を提供するべきか
- Spoke に何を委ねるべきか
- 境界をどう切るべきか
Databricks を「全部入りの基盤」としてではなく、
分散を支える装置としてどう使うかを整理していきます。
📚 関連書籍
※この記事は書籍の一部をベースに再構成しています。もう少し踏み込んだ内容(設計や具体例)は
書籍の中でまとめているので、気になる方はそちらもどうぞ。
Databricks/n8n/Salesforce/AI基盤 を体系的に学べる「ゼロから触ってわかった!」シリーズをまとめました。
『Databricks──ゼロから触ってわかった!Databricks非公式ガイド(2026年更新版)』
クラウド時代の分析基盤を “体験的” に学べるベストセラー入門書。
Databricksの操作、SQL/DataFrame、Delta Lakeの基本、ノートブック操作、SDP(宣言型パイプライン)
Serverless、Genieなどを初心者でも迷わず進められる構成で解説しています。
https://amzn.to/3Ob4eqD
『ゼロから触ってわかった! Snowflake × Databricks次世代データ基盤PoC実践 非公式ガイド』
『ゼロから触ってわかった! Snowflake × Databricksでつくる次世代データ基盤 - 比較・共存・連携 非公式ガイド』
SnowflakeとDatabricks――二つのクラウドデータ基盤は、これまで「どちらを選ぶか」で語られることが多くありました。本書は、両プラットフォームをゼロから触り、構築・運用してきた実体験をもとに、比較・共存・連携のリアルを丁寧に解説する“非公式ガイド”です。
👉 https://amzn.to/4bZeCvo
Snowflake
ゼロから触ってわかった!Snowflake非公式ガイド ― 基礎から理解するアーキテクチャとCortexによる次世代AI基盤
「結局、DatabricksとSnowflakeは何が違うの?」
初めてSnowflakeに触れる方には「最初の一冊」として。
なんとなく使っているけれどモヤモヤしている方には「頭の中を整理する一冊」として。
AI時代のエンジニアを目指すための、確かな燃料となる一冊です。
「ゼロから触ってわかった!Codex - AIエージェント時代のソフトウェア設計」
本書は、AIエージェントと共に開発する時代において、
エンジニアが思考停止せず、主体的に価値を発揮し続けるための指針を提示します。ツールの使い方ではなく、
これからの開発の本質を理解したいすべてのエンジニアへ。
「ゼロから触ってわかった! Claude Code × ChatGPT × Gemini AI共生戦略 -“対立”ではなく“共生”する時代へ」
Claude Code × ChatGPT × Geminiという共生モデルを解説します。
👉 https://amzn.to/4diheF9
『ゼロから触ってわかった!スペック駆動開発入門 ― SaaS is dead?AI時代のソフトウェア設計論』
前半では思想や背景を丁寧に整理し、後半ではスペック・実装・実行の三層モデルをサンプルコードとともに具体化します。
👉 https://amzn.to/4slxDxv
データメッシュ
『ゼロから触ってわかった データメッシュ入門 ― 思想・型・組織構造から考えるデータメッシュ』
「Data Mesh を導入すべきかどうか」を断言する本ではありません。
また、「この形が正解だ」と教える本でもありません。
自分たちにとって、どこまで分散し、何を共有し、どこに責任を置くのか。
その判断をするための思考の土台を整理する一冊です。
データクリーンルーム
ゼロから触ってわかった データクリーンルーム実践入門 ~ Lakehouse時代のクリーンルームを、思想・設計・マネタイズで読み解く ~
データはあるのに、渡せない。
それでも一緒に分析したい——そんな現場の悩みから、本書は始まります。
データクリーンルームを「難しい技術」ではなく、現実の業務でどう使い、どう続けるかという視点で整理しました。
非ITのビジネスパーソンにも読める、実践的な一冊です。
Databricks
『ゼロから触ってわかった!Azure × Databricksでつくる次世代データ基盤 非公式ガイド ―』
クラウドでデータ基盤を作ろうとすると、Azure・Storage・ネットワーク・権限・セキュリティ…そこに Databricks が加わった瞬間、一気に難易度が跳ね上がります。
「結局どこから理解すればいいの?」
「Private Link むずかしすぎない?」
「Unity Catalog って実務ではどう扱うの?」
——そんな “最初のつまづき” を丁寧にほどいていくのが本書です。
👉 https://amzn.to/4tAOVHP
「ゼロから触ってわかった!Databricks × Airbyte」
クラウド時代のデータ基盤を“なぜ難しいのか”から丁寧にほどくガイドが完成しました。
Ingestion / LakeFlow / DLT / CDC をやさしく体系化し、
Airbyte × Databricks の真価を引き出す設計思想まで詰め込んだ一冊です。
『Databricks──ゼロから触ってわかった!DatabricksとConfluent(Kafka)連携!非公式ガイド』
Kafkaによるストリーム処理とDatabricksを統合し、リアルタイム分析基盤を構築するハンズオン形式の一冊。
イベント駆動アーキテクチャ、リアルタイムETL、Delta Live Tables連携など、
モダンなデータ基盤の必須スキルがまとめられています。
『Databricks──ゼロから触ってわかった!AI・機械学習エンジニア基礎 非公式ガイド』
Databricksでの プロンプト設計・RAG構築・モデル管理・ガバナンス を扱うAIエンジニアの入門決定版。
生成AIとデータエンジニアリングの橋渡しに必要な“実務の型”を体系化しています。
資格本ではなく、実務基盤としてAIを運用する力 を育てる内容です。
『Databricks認定データエンジニアプロフェッショナル 試験レベル ― 1日3分!気になったところから読めるデータブリックス!魂の100本ノック!』
Databricksを業務で触っている。なのに——サンプル問題を解いた瞬間、手が止まる。
「使ってはいるけど、設計の“理由”までは腹落ちしていない」…その違和感から、この本は生まれました。
本書は、Databricks認定データエンジニア・プロフェッショナル相当の論点を、100個のユースケースに分解し、**“2択の検討”→“解説コラム”→“結論”**でテンポよく叩き込む「魂の100本ノック」です。
暗記ではなく、現場で遭遇する判断ポイント(取り込み・変換・品質・共有・監視・性能/コスト・セキュリティ・ガバナンス・デプロイ・モデリング)を、短い読書時間で反復できるように整えました。
👉 https://amzn.to/4aTP9lR
👉 https://amzn.to/4qEzVWq
🧠 Advancedシリーズ(上/中/下)
Databricksを “設計・運用する” ための完全版実践書
「ゼロから触ってわかった!Databricks非公式ガイド」の続編として誕生した Advancedシリーズ は、
Databricksを触って慣れた“その先”――本格運用・チーム開発・資格対策・再現性ある設計 に踏み込む構成です。
Databricks Certified Data Engineer Professional(2025年9月改訂版)のカリキュラムをベースに、
設計思考・ガバナンス・コスト最適化・トラブルシュートなど、実務で必須の力を養えます。
📘 [上]開発・デプロイ・品質保証編
📘 [中]取込・変換・監視・コスト最適化編
📘 [下]セキュリティ・ガバナンス・トラブルシュート・最適化戦略編
n8n
『n8n──ゼロから触ってわかった!AIワークフロー自動化!非公式ガイド』
オープンソースの自動化ツール n8n を “ゼロから手を動かして” 学べる実践ガイド。
プログラミングが苦手な方でも取り組めるよう、画面操作中心のステップ構成で、
業務自動化・AI連携・API統合の基礎がしっかり身につきます。
Salesforce
『ゼロから触ってわかった!Salesforce AgentForce + Data Cloud 非公式ガイド』
Salesforceの最新AI基盤 AgentForce と Data Cloud を、実際の操作を通じて理解できる解説書。
エージェント設計、トピック/アクション構築、プロンプトビルダー、RAG(検索拡張生成)など、
2025年以降のAI×CRMのハンズオン知識をまとめた一冊です。
👉 https://amzn.to/40fI7BK
👉 https://amzn.to/3OuN07o
要件定義(上流工程/モダンデータスタック)
『モダンデータスタック時代の シン・要件定義 クラウド構築大全 ― DWHからCDP、そしてMA / AI連携へ』
クラウド時代の「要件定義」って、どうやって考えればいい?
Databricks・Snowflake・Salesforce・n8nなど、主要サービスを横断しながら“構築の全体像”をやさしく解説!
DWHからCDP、そしてMA/AI連携まで──現場で使える知識をこの一冊で。
MCP
『ゼロから触ってわかった!MCPビギナーズガイド』 ― AIエージェント時代の次世代プロトコル入門 アーキテクチャ・ガバナンス・実装―
MCPというプロトコルは、単なる技術トレンドではなく
「AIとシステムの関係性」そのものを変える可能性を秘めています。
SaaS、AIエージェント、ガバナンス、アーキテクチャ。
その交差点を一度、立ち止まって整理した一冊です。
👉 https://amzn.to/3LcAjgg
💡 まとめ:このラインナップで“構築者の視点”が身につく
これらの書籍を通じて、
クラウド基盤の理解 → 要件定義 → 分析基盤構築 → 自動化 → AI統合 → 運用最適化
までのモダンデータスタック時代のソリューションアーキテクトとしての全体像を
「体系的」かつ「実践的」に身につけることができます。
- PoC要件整理
- データ基盤の要件定義
- チーム開発/ガバナンス
- AIワークフロー構築
- トラブルシュート
など、現場で直面しがちな課題を解決する知識としても活用できます。