「ミライアカリ」-「電脳少女シロ」=「万楽えね」?
概要
現在5000人を超えるバーチャルYouTuber。一番大きいブームが来てた時期は過ぎたと思われますが、バーチャルYouTuberそれぞれの個性が確立されてきて、なんとなくベクトル化したくなってきます。
ということで、有名なバーチャルYouTuberの動画のタイトルを形態素解析して、Doc2Vecに突っ込んでベクトル化してみます。
ベクトル化することで、似ている、似てないの判定や、足し算引き算などが出来たりします。
今回データとして集めたVTuberは、UserLocalさんのバーチャルYouTuberランキングから上位200人のバーチャルYouTuberを拾得しました。(2018/10/30)
環境
- MacOS X 10.14
- Python3.6
外部ライブラリ
- google-api-python-client == 1.7.4
- gensim == 3.6.0
- tqdm == 4.19.5
- requests == 2.20.0
- beautifulsoup4 == 4.6.0
- pandas == 0.22.0
- mecab-python3 == 0.7
ただし、tqdmはあってもなくても大丈夫です。
構成
環境が整ったら、以下のやり方で完成します。
- バーチャルYouTuberランキングからスクレイピング
- YouTube APIで各VTuberのタイトルを拾得
- バーチャルYouTuber用の辞書を作成
- 形態素解析と前処理
- GenSimでDoc2Vecを使ってベクトル化する
そして出来たモデルを使って、遊んでいきます。
スクレイピング
バーチャルYouTuberランキングから各VTuberの名前, チャンネルID, チャンネルのURL, ランキングをCSVファイルにまとめます。
まず、requestsでGETして、beautifulsoup4でhtmlをパースします。
def get_ranking_page(page: int = 1):
html = requests.get(RANKING_URL+"?page={}".format(page)).text # リクエスト
return BeautifulSoup(html, 'html.parser') # パース
本当ならここで終わらせたいのですが、バーチャルYouTuberランキングから各VTuberのチャンネルIDを拾得できません。
なので、各VTuberの詳細ページに飛んで、動画をYouTube APIから検索し、チャンネルIDを特定します。
def get_channel_id(url: str):
for url in get_videos_url(url): # 詳細ページにある、そのVTuberのおすすめ動画
try:
mid = url.split("?v=")[-1] # 動画のid
return video_id_to_channel_id(YouTube, mid) # 動画のidからチャンネルidを拾得
except IndexError:
pass
raise IndexError
チャンネルID習得後はhttps://www.youtube.com/channel/{channel_id}がそのチャンネルのURLになります。
最後に、データをCSVで書き出します。
,channel_id,name,ranking,userlocal-url,youtube-url
0,UC4YaOt1yT-ZeyB0OmxHgolA,キズナアイ,1,https://virtual-youtuber.userlocal.jp/user/D780B63C2DEBA9A2_fa95ae,https://www.youtube.com/channel/UC4YaOt1yT-ZeyB0OmxHgolA
1,UCbFwe3COkDrbNsbMyGNCsDg,キズナアイ(ゲーム),2,https://virtual-youtuber.userlocal.jp/user/538612673177E888_594fe8,https://www.youtube.com/channel/UCbFwe3COkDrbNsbMyGNCsDg
2,UCQYADFw7xEJ9oZSM5ZbqyBw,輝夜月(かぐやるな),3,https://virtual-youtuber.userlocal.jp/user/3636EECB49E075A1_941766,https://www.youtube.com/channel/UCQYADFw7xEJ9oZSM5ZbqyBw
3,UCMYtONm441rBogWK_xPH9HA,ミライアカリ,4,https://virtual-youtuber.userlocal.jp/user/bittranslate_295a57,https://www.youtube.com/channel/UCMYtONm441rBogWK_xPH9HA
4,UCLhUvJ_wO9hOvv_yYENu4fQ,電脳少女YouTuberシロ,5,https://virtual-youtuber.userlocal.jp/user/5C9973C694A2C341_632bad,https://www.youtube.com/channel/UCLhUvJ_wO9hOvv_yYENu4fQ
参考
YouTube APIを叩く
先程も少し触りましたが、YouTube APIを叩いて、動画のタイトルを拾得していきます。
まず、先程保存したCSVファイルを読み込みます。
列でのアクセスを楽にするためにpandasを使います。
vtuber = pd.read_csv("VTuber_list.csv", index_col=0).dropna().reset_index(drop=True)
この.dropna().reset_index(drop=True)は動画の無いチャンネル(どっとライブとか)やチャンネルIDの拾得失敗したものを取り除く作業です。
このデータフレームをループに回し、動画のタイトルを拾得し、csvとして保存します。
for i, channel_id in zip(tqdm(vtuber.ranking), vtuber.channel_id):
df = create_df(channel_id=channel_id)
df.to_csv("rank_{}.csv".format(i))
create_dfではYouTube APIを叩いて、各VTuberの動画からpublished_at,title,video_id,urlの情報を拾得し、データフレームを作ります。
具体的には、チャンネルIDで動画検索し、動画情報をリストに追加して、次のページの検索結果を見ます。そして、100件を超えたら打ち切りという形です。
検索のAPIでは1ページに50件までしか拾得出来ないので、pageTokenを指定することで51件以上の結果が得られます。
VTuber_list.csvとrank_{ランキング}.csvが用意できたらデータ集めは終了です。
参考
- Search | YouTube Data API (v3) | Google Developers
- youtubeAPIを使って特定のチャンネルの動画タイトルを取得
- YouTube Data API (v3)のサンプルコードを解釈する。
形態素解析
さっそく形態素解析をやりたいのですが、VTuber界隈で独自に発展した言葉などがあります。(いい例が"VTuber"という単語ですが)
なので、VTuber専用の辞書を作っていきます。
形態素解析はMeCabを使うので、MeCabのユーザー辞書を作ります。
ユーザー辞書のコンパイルが出来たら、タイトルを形態素解析して、動詞、名詞、感動詞などを取り出して行きます。
辞書の登録
活用しない語を追加する場合、csvファイルに
ユーザ設定,,,10,名詞,一般,*,*,*,*,ユーザ設定,ユーザセッテイ,ユーザセッテイ,追加エントリ
って感じで単語追加します。
具体的に何の単語を追加するかと言うと、上で作成したrank_{ランキング}.csvから実際に動画のタイトルを見て、機械で理解するのは難しそうだな、と思ったものを登録していきます。
大変ですが、人力です。
csvファイルに書き出したら、コンパイルを行います。
import subprocess
subprocess.call([
"/usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index",
"-d", "/usr/local/lib/mecab/dic/ipadic",
"-u", "vtuber.dic",
"-f", "utf-8",
"-t", "utf-8", "vtuber_user_dic.csv"
])
こうしてvtuber.dicという辞書が完成しました。
辞書の比較
素のMeCabと、NEologd、NEologd+VTuber辞書を比較します。
実際の動画タイトル「みとぽん生放送 月ノ美兎 × ウェザーロイドAiri コラボ生放送 2018.09.20」を形態素解析してみます。
素のMeCab

月ノ美兎が1単語として読み込まれていないので使い物になりません。
NEologd

かなりいい感じになっています。十分使えると思われます。
NEologd+VTuber辞書

月ノ美兎、ウェザーロイドなどを一般の固有名詞から、人物名と認識してくれる様になりました。
この比較ではユーザー辞書がなくとも、NEologdが十分優秀なので欲している結果が得られましたが、名取さながファンを呼ぶ時の「せんせえ」などは認識してくれなかったので、ユーザー辞書を登録することに意味はあると思います。
形態素解析の実用部分
MeCabでNEologd+VTuber辞書をセットします。
import MeCab
mecab = MeCab.Tagger("-d %s -u %s" % (MECAB_IPADIC_NEOLOGD_PATH, VTUBER_DIC_PATH))
mecab.parseToNode("")
mecab.parseToNode("")は魔法の言葉です。
そして、引数から、動詞、数以外の名詞、'!'とかの一般記号、感動詞、だけを取り出す関数を書いていきます。
def parser(text):
node = mecab.parseToNode(text)
ret = []
while node:
feature = node.feature.split(',')
if feature[0] == "BOS/EOS":
pass
elif feature[0] == "動詞":
ret.append(node.surface)
elif feature[0] == "名詞" and feature[1] != "数":
ret.append(node.surface)
elif feature[0] == "記号" and feature[1] == "一般":
ret.append(node.surface)
elif feature[0] == "感動詞":
ret.append(node.surface)
node = node.next
return ret
また、一般記号は、意味のあるものと無いものがあるので、意味がなさそうなものはリストから取り除きます。
def remove_word(word_list):
return [w for w in word_list if w not in REMOVE_WORD_LIST]
これでDoc2Vecに食べさせる語の前処理は終了です。
参考
- 単語の追加方法
- Mecabのシステム辞書・ユーザ辞書の利用方法について
-
「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
- この記事はVTuber2Vecを作る上でものすごく参考にさせていただきました。
GenSimでDoc2Vecを使う
自分は機械学習さっぱりわからないのですが、なんとなくそれっぽい物ができて動くGenSimは素晴らしいです。
プログラムはGenSimからDoc2Vecをインポートして、形態素解析した動画のタイトルをトレーニングデータとして入れ、パラメーターを少し弄って、モデルを作ります。
def main():
vtuber = pd.read_csv("VTuberData/VTuber_list.csv", index_col=0).dropna().reset_index(drop=True)
print("pre processing vtuber titles")
training = [
TaggedDocument(words=get_title_usable(i), tags=[name]) for i, name in zip(tqdm(vtuber.ranking), vtuber.name)
]
print("\ntraining")
model = Doc2Vec(documents=training, dm=0, window=3, alpha=0.013, min_alpha=0.013, min_count=1)
for _ in tqdm(range(15)):
model.train(training, total_examples=model.corpus_count, epochs=model.iter)
model.alpha -= 0.0011
model.min_alpha = model.alpha
model.save('vtuber2vec.model')
そうしたらjupyterで完成したモデルを読み込み、動かしてみます。
model = Doc2Vec.load("vtuber2vec.model")
これで、model.docvecs.most_similar(["キズナアイ"])の用に書くとキズナアイにベクトルが似たVTuberが出てきます。
参考
実行結果
独断と偏見で1~10で精度を評価していきたいと思います。
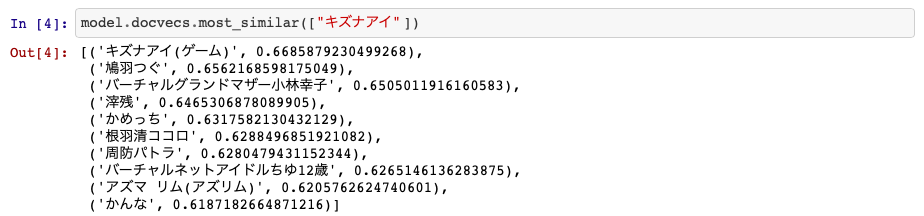
キズナアイ
精度:3
キズナアイ要素は強いですが、過学習なVTuberが入ってきている感じがします。
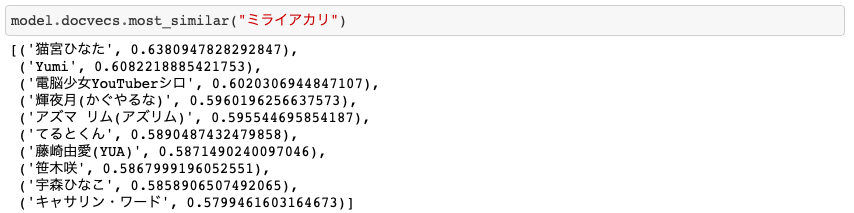
ミライアカリ
精度:7
同じ事務所の猫宮ひなたが1番で、輝夜月やシロちゃんが出てくるのはいい結果だと思います。YumiはVRChatをやってますが、そこまで似ている印象がなかったので、マイナス。
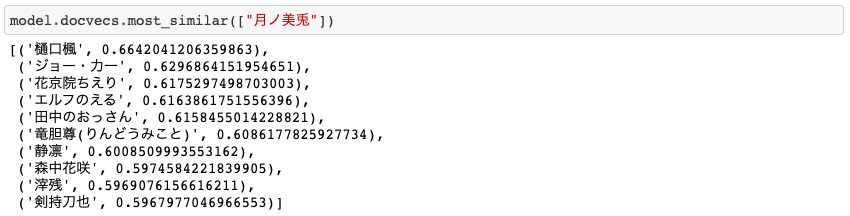
月ノ美兎
精度:6
にじさんじが出てきたのは嬉しいですが、もっと清楚(にじさんじ)な感じが欲しかったです
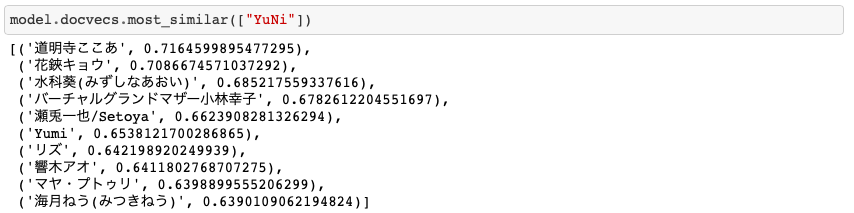
YuNi
精度:9
トップ数人はバーチャルシンガーで、とてもいい結果だと思います。過学習組を除けばもっと良い結果が出せそう。
ミライアカリ ー 電脳少女シロ
精度:6
問題のミライアカリからシロちゃんを引いたものです。変態ベクトルが残ると思っていましたが、歌要素が残りました。割とアズリムはそんな気がする…

ミライアカリ ー 万楽えね
精度:7
歌と清楚が残った感じです。期待していた結果に近いと思います。

考察
VTuberをベクトル化してみましたが体感では70%ぐらいの精度ぐらいと感じました。
この精度を上げるには
- 辞書をより充実させる
- パラメータの調整
- VTuber詳しい人に精度を評価してもらう
といった感じでしょうか。コメントやPRお待ちしています。
ソースコード
終わりに
途中でも言いましたが、自分は機械学習出来ません。GenSimの偉大さにあやかってるだけなので、もっと精度を上げる方法などあると思います。Twitter(@app1e_s)によくいるので、いろいろな意見をいただけるとありがたいです。