概要
この記事ではAWS認定DASに出題されるリソースを使った構成をシリーズ化して紹介します。
前回までの内容は以下をご覧ください!
【AWS DAS】S3上のデータをQuicksightで可視化するまでやってみた Part1
【AWS DAS】S3上のデータをQuicksightで可視化するまでやってみた Part2
【AWS DAS】S3上のデータをQuicksightで可視化するまでやってみた Part3
今回の実施内容
前回Part3の内容を行いました。今回はAthenaの設定を行います。
- Part1
- JSONのダミーデータの作成
- S3バケットの作成
- Part2
- Lambda作成
- S3イベントとLambdaの連動
- Part3
- Glueの設定
- Part4
- Athenaの設定
- Part5
- Quicksightでの可視化
Amazon Athenaとは?
Amazon AthenaはS3やGlueのデータソースに対して標準SQLを実行し操作できるサービスです。
業務ではS3に保存されているVPCフローログを参照した外部テーブルを作成し、必要なデータを抽出するなどの使い方をしています。
今回はGlueのデータカタログに作成したデータベース上のテーブルをAthenaで確認し、
実際に操作を行います。
Athenaの設定
前回の手順で作成したテーブルをAthenaで確認、操作するまでを行っていきます。
- Athenaを実行する際のクエリ保存先S3を作成していきます。
名前は「athena-query-2024」としました。
以降の設定はデフォルト値にしています。

- クエリの保存先の設定を行います。
Athenaのコンソール画面で「クエリエディタ」を選択。
「設定」タブを選択し「管理」をクリックします。
遷移先画面にて先ほど作成したクエリ保存先S3を選択します。

- Glueのコンソール画面にて「Tables」を選択。前回の手順にて作成されたテーブルをクリックします。

- 右上の「Action」から「View data」をクリックします。

- 別タブでAthenaの画面が表示されます。
自動的にGlueで作成したテーブルのクエリが記載されているので「もう一度実行する」をクリックします。

- Glueで設定したテーブルのデータが表示されます。
Lambdaの動作確認時のデータしか入っていないので1行のみとなっています。。

Athenaでの操作
Part1で作成したダミーデータも追加で入れたので
Athenaを使用して実際にテーブルを操作してみました。
想定通りに操作できます!
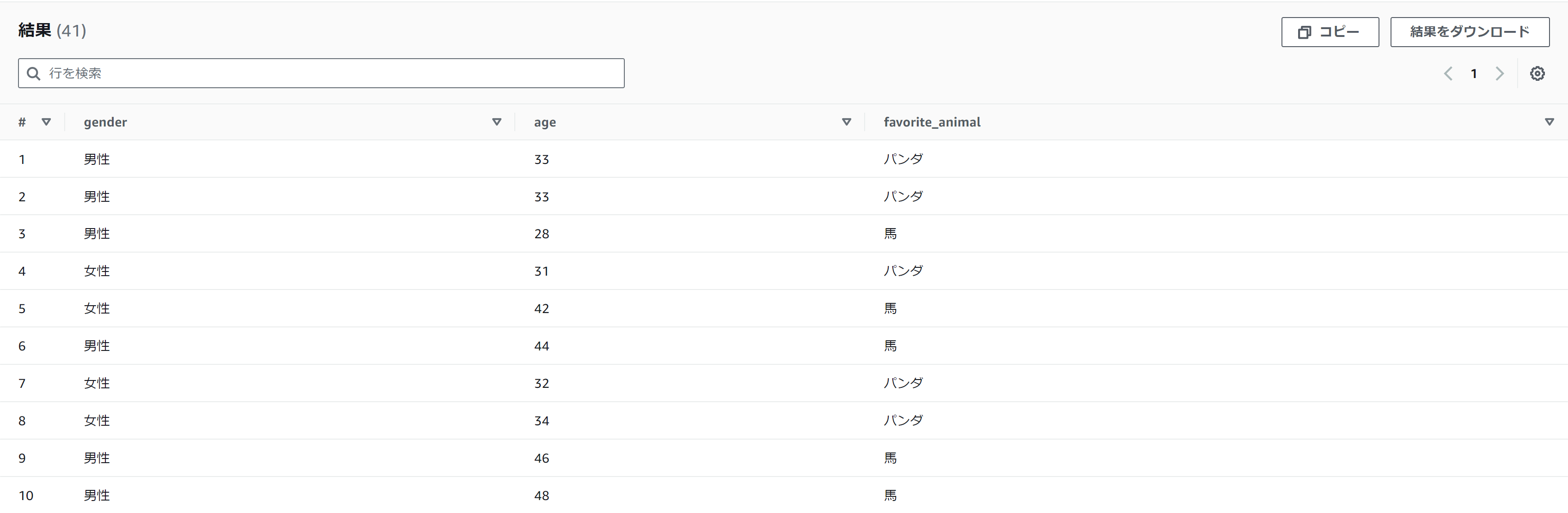
- favorite_animalが「パンダ」、「馬」のデータのみ抽出
SELECT
*
FROM
output
WHERE
favorite_animal IN ('パンダ', '馬')
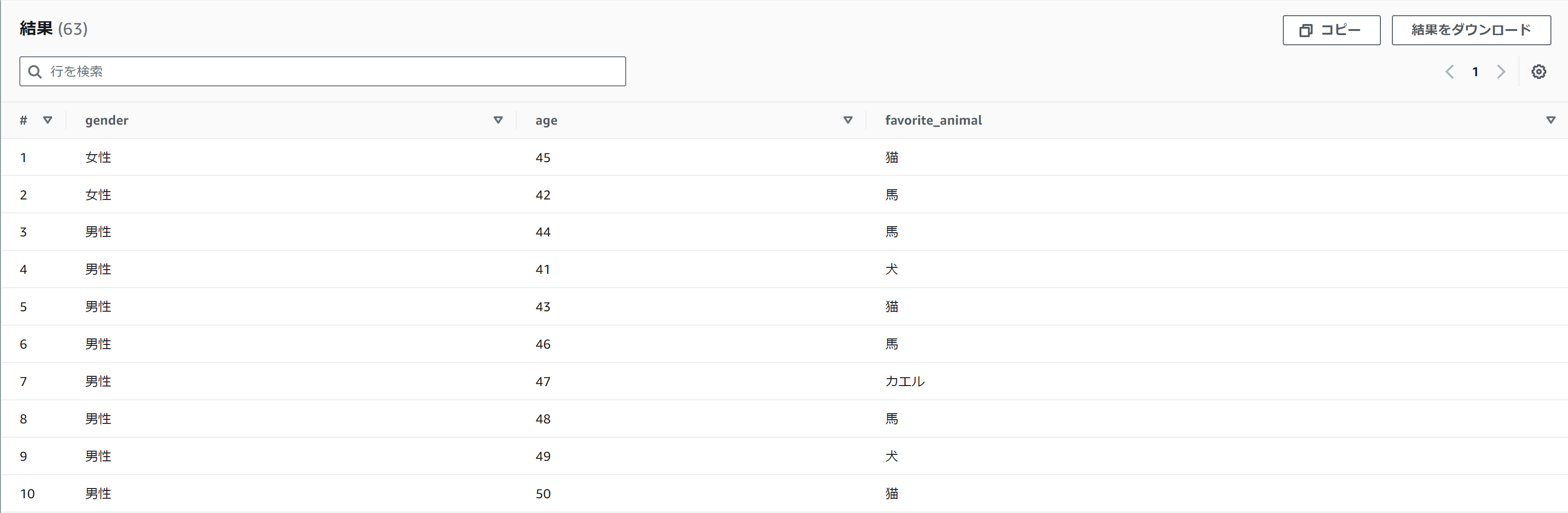
- ageが「40」以上のデータのみ抽出
SELECT
*
FROM
output
WHERE
40 <= age
- favorite_animalのそれぞれのカウント数を抽出
SELECT favorite_animal, Count(favorite_animal)
FROM output
GROUP BY favorite_animal;

まとめ
ここまで読んでくださりありがとうございました!
無事にGlueのデータをAthenaで操作するところまで来ました。
普段VPCフローログからの簡単なデータ抽出でしか操作したことがなかったので
今回SQLクエリを調べてみて知らない内容がまだまだあることを再認識しました。。
データ分析には最低限必要な知識だと思うので深堀をしていきます。
次回最後の回となりました!Quicksightで可視化を試していきたいと思います。
参考にさせていただいたサイト
https://dev.classmethod.jp/articles/sugano-037-glue-for-athena/#toc-6
https://blog.serverworks.co.jp/2022/02/28/192222