概要
この記事ではAWS認定DASに出題されるリソースを使った構成をシリーズ化して紹介します。
はじめまして!
AWS認定DASの資格学習として出題サービスを使用した構成を組んでみようと思い
初投稿をしてみました。
私自身の経歴はインフラエンジニアとして2年半設計構築に携わってます。
SAAの資格学習時(昨年取得出来ました!)に実際に携わったことのあるサービスに関しては理解度が格段に上がることを実感したためこのような取り組みを行っております。
実現したい構成
早速ですが実現したい構成は以下です。
作成リージョンはap-northeast-1とします。
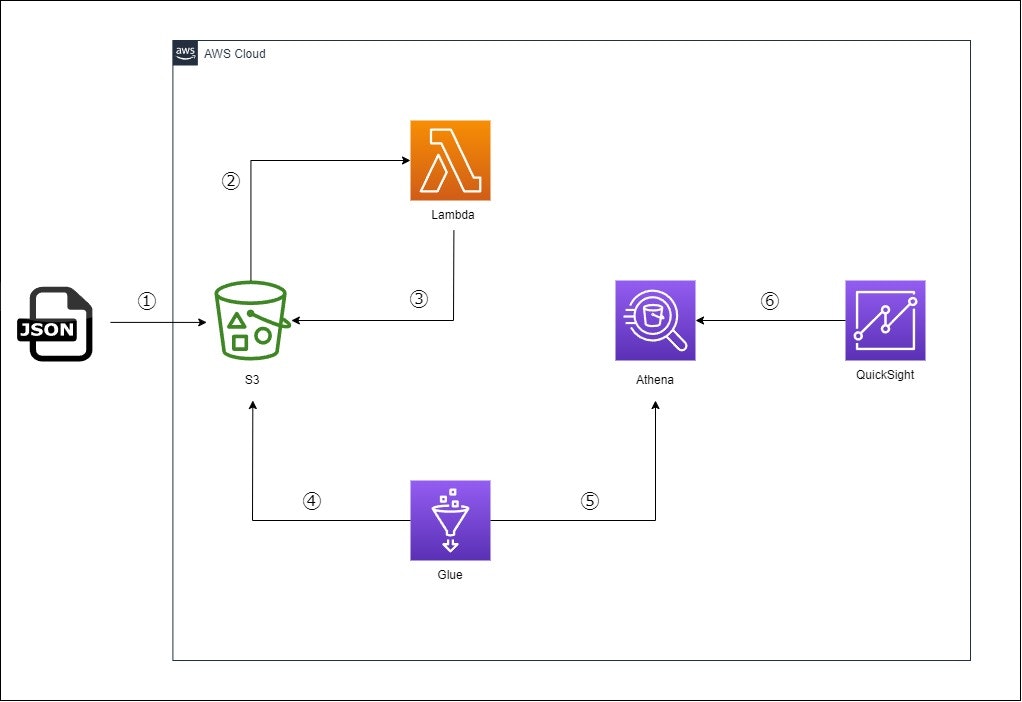
①JSONファイルをS3(inputフォルダ)にアップロード
②S3にJSONファイルがアップロードされたことをトリガーにLambdaを実行
③JSONのデータをCSVに変換してS3(outputフォルダ)に保存
④CSVのデータでテーブルを作成
⑤Glueのテーブルを操作
⑥AthenaのデータをQuicksightのグラフで可視化
実際に構築する流れ
今回Part1~5で実施していこうと思います。
- Part1
- JSONのダミーデータの作成
- S3バケットの作成
- Part2
- Lambda作成
- S3イベントとLambdaの連動
- Part3
- Glueの設定
- Part4
- Athenaの設定
- Part5
- Quicksightでの可視化
JSONのダミーデータの作成
今回使用するJSONファイルはS3にアップロード後、グラフとして可視化していきたいので
ある程度の量が必要です。
手作業で作成するのは酷なのでChatGPTに作成してもらいます。
以下の内容でお願いしました

結果
しっかりと作成してくれました。

ダミーデータ
[
{"性別": "男性", "年齢": 25, "好きな動物": "犬"},
{"性別": "女性", "年齢": 30, "好きな動物": "猫"},
{"性別": "男性", "年齢": 22, "好きな動物": "鳥"},
{"性別": "女性", "年齢": 35, "好きな動物": "ウサギ"},
{"性別": "男性", "年齢": 28, "好きな動物": "象"},
{"性別": "女性", "年齢": 32, "好きな動物": "クマ"},
{"性別": "男性", "年齢": 26, "好きな動物": "ペンギン"},
{"性別": "女性", "年齢": 29, "好きな動物": "カメレオン"},
{"性別": "男性", "年齢": 24, "好きな動物": "ライオン"},
{"性別": "女性", "年齢": 31, "好きな動物": "サル"},
{"性別": "男性", "年齢": 27, "好きな動物": "イルカ"},
{"性別": "女性", "年齢": 33, "好きな動物": "カンガルー"},
{"性別": "男性", "年齢": 23, "好きな動物": "カメ"},
{"性別": "女性", "年齢": 34, "好きな動物": "ゾウ"},
{"性別": "男性", "年齢": 21, "好きな動物": "カラフルな魚"},
{"性別": "女性", "年齢": 36, "好きな動物": "カワウソ"},
{"性別": "男性", "年齢": 20, "好きな動物": "パンダ"},
{"性別": "女性", "年齢": 37, "好きな動物": "ハムスター"},
{"性別": "男性", "年齢": 19, "好きな動物": "チーター"},
{"性別": "女性", "年齢": 38, "好きな動物": "コアラ"},
{"性別": "男性", "年齢": 18, "好きな動物": "カブトムシ"},
{"性別": "女性", "年齢": 39, "好きな動物": "ヘビ"},
{"性別": "男性", "年齢": 17, "好きな動物": "ハト"},
{"性別": "女性", "年齢": 40, "好きな動物": "カジキマグロ"},
{"性別": "男性", "年齢": 31, "好きな動物": "フクロウ"},
{"性別": "女性", "年齢": 29, "好きな動物": "カメレオン"},
{"性別": "男性", "年齢": 28, "好きな動物": "ラマ"},
{"性別": "女性", "年齢": 27, "好きな動物": "アヒル"},
{"性別": "男性", "年齢": 26, "好きな動物": "カッコウ"},
{"性別": "女性", "年齢": 25, "好きな動物": "キリン"},
{"性別": "男性", "年齢": 24, "好きな動物": "トラ"},
{"性別": "女性", "年齢": 23, "好きな動物": "アシカ"},
{"性別": "男性", "年齢": 22, "好きな動物": "キツネ"},
{"性別": "女性", "年齢": 21, "好きな動物": "ネズミ"},
{"性別": "男性", "年齢": 30, "好きな動物": "ゴリラ"},
{"性別": "女性", "年齢": 31, "好きな動物": "クジラ"},
{"性別": "男性", "年齢": 32, "好きな動物": "シマウマ"},
{"性別": "女性", "年齢": 33, "好きな動物": "ヒョウ"},
{"性別": "男性", "年齢": 34, "好きな動物": "ヤギ"},
{"性別": "女性", "年齢": 35, "好きな動物": "ハシビロコウ"},
{"性別": "男性", "年齢": 36, "好きな動物": "クモ"},
{"性別": "女性", "年齢": 37, "好きな動物": "カンガルー"},
{"性別": "男性", "年齢": 38, "好きな動物": "カメレオン"},
{"性別": "女性", "年齢": 39, "好きな動物": "アヒル"},
{"性別": "男性", "年齢": 40, "好きな動物": "キリン"}
]
S3バケットの作成
データ加工に使用するS3バケットを作成していきます。
名前は「transbucket-2024」としました。
以降の設定はデフォルト値にしています。

構成図にもある通り、inputフォルダとoutputフォルダでフォルダ分けをします。
Lambdaにて使用する一時フォルダとしてtmpフォルダも作成しました。

まとめ
ここまで読んでくださりありがとうございました!
本日は今回実現したい構成の紹介とダミーデータ、S3の作成を行いました。
次回はLambdaの作成、実際にS3との連動を行っていきます。
参考にさせていただいたサイト