概要
この記事ではAWS認定DASに出題されるリソースを使った構成をシリーズ化して紹介します。
前回までの内容は以下をご覧ください!
【AWS DAS】S3上のデータをQuicksightで可視化するまでやってみた Part1
【AWS DAS】S3上のデータをQuicksightで可視化するまでやってみた Part2
今回の実施内容
前回Part2の内容を行いました。今回はGlueの設定を行います。
- Part1
- JSONのダミーデータの作成
- S3バケットの作成
- Part2
- Lambda作成
- S3イベントとLambdaの連動
- Part3
- Glueの設定
- Part4
- Athenaの設定
- Part5
- Quicksightでの可視化
AWS Glueとは?
AWS GlueはAWSで提供しているETLツールです。
ETLとは「Extract(抽出)」「Transform(変換)」「Load(書き出し)」の略称で
DBやS3などのデータソースから必要なデータを取り出し、分析しやすいデータ形式へ変換してデータ分析基盤へ書き出す役割があります。
(今回はLamdaを使用しましたが、GlueでJSONからCSVへの変換も可能です。)
今回はS3の特定のフォルダからCSVファイルを抽出し、Amazon Athenaで操作する
データベースとテーブル作成を担当してくれます。
詳しい動きは以下になります。
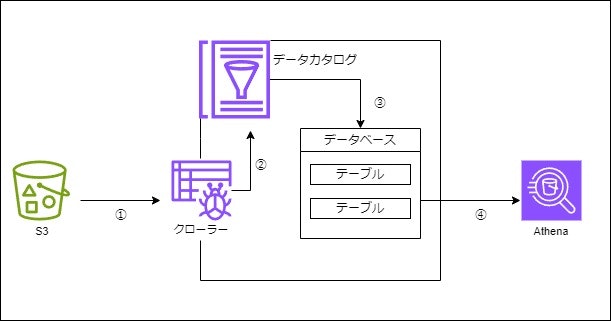
①データソースからメタデータを取得 ※実データではなくメタデータを取得する
②クローラーがデータカタログにメタデータを登録
③データカタログのデータベースにメタデータのテーブルが作成される
④作成されたテーブルをAthenaで操作する
クローラーの設定
クローラーを作成していきます。
- AWS Glueの画面からCrawlersを選択し、「Create crawler」をクリックします。

- Step1ではクローラーの名前を設定します。
「crawler-csv」にしました。そのほかの設定値はデフォルト値のまま「Next」をクリックします。

- Step2ではデータソースを設定します。
「Is your data already mapped to Glue tables?」にはまだデータをテーブルにマッピングしていないので「No yet」を選択。
「Add a data source」をクリックします。

- データソースを指定します。以下を設定しました。
設定後「Add an S3 data source」をクリックします。
| 項目 | 設定値 |
|---|---|
| Data source | S3 |
| Location of S3 data | In this account |
| S3 path | s3://transbucket-2024/output/ |
| Subsequent crawler runs | Crawl all sub-folders |
S3 pathはフォルダ名まで指定します。

- 「Data sources」一覧に追加されているのを確認して「Next」をクリックします。

- Step3ではクローラーのIAMロールを選択します。
事前に作成していないので「Create new IAM role」をクリックし新たに作成します。
ロール名を入力し、そのほかの設定値はデフォルト値のまま「Next」をクリックします。

- Step4ではメタデータをテーブルで保管するためのデータベースを選択します。
こちらも事前に作成していないので「Add database」をクリックし新たに作成します。

- 別タブが開くのでそちらでデータベース名を入力して「Create database」をクリックします。
「csv-db」にしました。

- AWS Glueの画面に戻り「Target database」のプルダウンから作成したデータベースを選択。
そのほかの設定値はデフォルト値のまま「Next」をクリックします。

- Step5で設定した内容を確認し「Create crawler」をクリックします。
- 作成したクローラーの画面が表示されるので「Crawler runs」タブから「Run crawler」をクリックします。

- 「Status」がCompletedになればメタデータのテーブルが作成されます。

まとめ
ここまで読んでくださりありがとうございました!
今回はAWS Glueの設定を行いました。
Glueはクローラー、データカタログ、ETLジョブ、ワークフローなどの様々な機能を合わせているのでそれぞれの役割が明確に理解できていませんでしたが実際に構築を行い理解が深まりました。
今回のようにデータソースからデータを抽出してデータカタログのテーブルに保存するだけでなく、データ変換もできるため次回は違う使い方を実践していきたいと思います。
参考にさせていただいたサイト