Human Vision Constrained Super-Resolution (Karpenko, 2025)
3行要約
- 現代の超解像(SR)技術は、人間の視覚システム(HVS)の知覚能力を考慮せずに画像を均一に処理するため、知覚できないディテールに計算リソースを浪費するという課題がありました。
- 本研究は、HVSの感度と視聴条件に基づいてSR手法を動的にガイドするHuman Visual Processing Framework (HVPF) を提案し、画像の局所的な特性に応じて最適な計算コストで視覚的に最適な結果を提供します。
- 定量評価とユーザー調査により、このフレームワークが知覚品質を損なうことなく、FLOPSを2倍以上(最大76.4%)削減し、様々なSRモデルや動画、AR/VRアプリケーションにおける計算効率の大幅な改善を実証しました。

Q:何が問題で、それをどのように解決したのか、わかりやすく説明してください
A:
問題:SRの計算資源の「無駄」
現代のSuper-Resolution(SR)技術、特に深層学習に基づくものは、非常に高品質な画像を生成できます。しかし、ここに大きな問題があります。
主な問題点:
- HVSの限界: 人間の目(HVS: Human Visual System)は、画像中の全ての細部を無限に認識できるわけではありません。空間周波数、輝度、色、コントラスト、動き、そしてディスプレイからの距離や環境光といった様々な要因によって、人間の視覚が認識できる細部の限界は常に変動しています。
-
計算資源の浪費: ほとんどのSR手法は、これらの人間の視覚の限界を考慮せず、画像全体を一様に、最高品質で処理しようとします。その結果、人間の目には知覚できないような微細なディテールを生成するために、膨大な計算資源(電力、処理時間)が無駄に消費されてしまうのです。
- 例えば、ぼやけた背景や、高速で動いている物体、非常に暗い領域など、人間がそもそも細部を識別できないような部分に対しても、高価なSR処理が適用されてしまいます。
- リアルタイム応用の課題: VR/AR、ゲーム、リアルタイムメディア配信など、高解像度・高フレームレートが求められるアプリケーションでは、この計算負荷の高さが大きなボトルネックとなり、実用化を妨げています。
要するに、人間の目には見えないのに、コンピュータは一生懸命計算しているという状態が、この研究の根本的な問題意識です。
解決策:人間の視覚に合わせた「賢い」資源配分
この論文では、この「無駄」をなくし、計算資源を賢く使うために、** HVPF(Human Visual Processing Framework) **という新しいアプローチを提案しました。
解決策の核心:
HVPFは、人間が知覚できる品質を一切損なわずに、最も効率的なSR処理を選択することを目指します。そのために、人間の視覚システムの特性を深く理解し、それをSR処理に動的に組み込みます。
具体的な解決方法のステップ:
-
SRモデルの「能力診断」:
- まず、様々な種類のSRモデル(または同じモデルの異なる設定、例:ネットワークの深さや途中の分岐点)が、画像のどの周波数成分をどれだけ回復できるか、という「能力(減衰曲線)」を事前に徹底的に診断し、プロファイル化します。これは、各SRモデルが「得意なこと」と「苦手なこと」を数値で把握するようなものです。
-
人間の目の「要求レベル」を把握:
- 次に、入力画像(またはビデオフレーム)を小さなパッチに分割します。
- 各パッチに対して、その場所の明るさ、コントラスト、含まれる細かさ(空間周波数)、動きの速さなどを考慮して、「人間の目がこのパッチでどの程度の品質を要求しているか」を精密に計算します。これは、「知覚コントラストモデル」という、人間の視覚特性を再現するモデル(Contrast Sensitivity Functionやマスキング効果などを含む)を使って行われます。
- この計算のゴールは、「人間が品質の低下を全く感じない、ぎりぎりのライン」を正確に特定することです(1 JND: Just Noticeable Difference)。
-
最適な「組み合わせ」の選択:
- 最後に、ステップ1で診断したSRモデルの「能力」と、ステップ2で把握した人間の目の「要求レベル」を比較します。
- そして、各パッチに対して、「人間の目の要求レベルを満たしつつ、最も計算負荷の低いSRモデル(またはそのモデルの最も軽い設定)」を動的に選択し、適用します。
- 例えば、人間の目がほとんど細部を認識しないようなパッチには、シンプルな補間や非常に浅い(軽い)SRネットワークを適用します。
- 一方で、人間の目が非常に敏感な、高コントラストで細部が多いパッチには、高性能で計算負荷の高いSRネットワークを適用します。
解決策によるメリット:
- 計算コストの大幅削減: 人間の知覚能力を超える「無駄な」計算を排除できるため、FLOPSを2倍、3倍、それ以上に削減することが可能です。
- 知覚品質の維持: 人間の視覚モデルに基づいているため、計算を削減しても、最終的な出力は人間の目には元の高品質なSR結果と区別がつかないレベルを維持します。これは、ユーザー研究によっても裏付けられています。
- 汎用性: このHVPFは、特定のSRネットワークアーキテクチャに限定されず、様々な既存のSR手法と組み合わせてその効率を向上させることができます。
- リアルタイム応用の促進: 計算負荷が軽減されることで、VR/AR、ゲーム、モバイルデバイスなど、リアルタイム性能が求められる多くのアプリケーションでのSR技術の実用化が加速されます。
このアプローチは、SR技術の「計算効率と知覚品質のトレードオフ」という長年の課題に対して、人間の視覚という最も重要な「最終受容者」の特性を最大限に活用することで、革新的な解決策を提供していると言えるでしょう。
Q:この論文の概要を教えてください
A:
本稿は、ディープラーニングに基づくSuper-Resolution(SR)技術が、人間の視覚系(HVS)の特性を考慮せずに画像を処理するという問題点に着目し、HVSの知覚限界を活用することで、視覚的品質を損なうことなく計算効率を向上させるHuman Visual Processing Framework(HVPF)を提案しています。HVSは、空間周波数、輝度、色、コントラスト、動き、表示条件(周囲光、視聴距離など)といった要因に応じて、画像細部に対する感度が変化します。この観察に基づき、人間の知覚能力を超えた細部の再構築は計算資源の浪費であるという洞察が本研究の出発点となっています。
提案手法の核心は、HVSの感度に合わせてSRメソッドを動的かつ局所的にガイドするHVPFです。HVPFは、SRモデルの周波数再構築能力を定量化し、HVSの知覚モデルと組み合わせて、画像/ビデオの各パッチに最適なSR処理レベルを決定します。
本稿の主要な構成と貢献は以下の通りです。
- HVSの利用: HVSの圧縮性(有限の分解能力)を利用し、画像やビデオの領域ごとにSR処理の強度を適応的に調整します。これにより、知覚可能な品質を維持しつつ、計算リソースの無駄を排除します。特に、動きによるコントラスト検出能力の低下や周辺視野における視覚能力の低下といったHVSの特性が考慮されます。
-
Attenuation Response Estimation (減衰応答推定): SRメソッドの再構築能力を定量化するために、減衰カーブ(attenuation curves)を使用します。これは、再構築された画像($\hat{I}$)とグラウンドトゥルース画像($I$)のフーリエ変換のマグニチュードの比率で定義されます。
$$ \alpha_{\phi k}(I, f) = \frac{|\mathcal{F}(\phi(I_{\downarrow k})) (f)|}{|\mathcal{F}(I) (f)|} $$
ここで、$\mathcal{F}$ はフーリエ変換、$\phi$ はSRメソッド、$I_{\downarrow k}$ は$k$倍にダウンサンプリングされた画像です。この減衰カーブは、複数の画像で平均化され、ガウス関数でモデル化されます。
$$ \alpha'(f) = \frac{1}{a\sqrt{2\pi}} \exp \left( -\frac{(f - b)^2}{2a^2} \right) + c $$
ここで、$f$ は空間周波数、$a, b, c$ は適合によって推定されるパラメータです。 - Perceived Contrast Modeling (知覚コントラストモデリング): 知覚輝度コントラストは、マルチスケールLaplacian-Gaussianピラミッドを用いて計算され、Contrast Sensitivity Function (CSF) と視覚マスキングモデルによって正規化されます。これにより、人間の知覚に基づいたコントラストがモデル化されます。
-
Optimization (最適化): 特定の画像パッチに対し、人間の視覚の分解能力以下である最大減衰を見つけることを目的とします。これは、元の画像と減衰した画像のコントラスト差がちょうど1 Just Noticeable Difference(JND)になるように減衰カーブを最適化することによって達成されます。許容される出力コントラスト $C'_n(f, p)$ は、HVSのモデルに基づいて入力パッチのコントラスト $C_n(f, p)$ から直接導出されます。
$$ C'_n(f, p) = \left( \frac{1 + \frac{1} {|N|} \sum_{q \in N(p)} |C_n(f, q)|^ \beta - |C_n(f, p)|^\alpha}{\alpha} \right)^{1/ \alpha} $$
ここで、$N(p)$ はパッチ $p$ の近傍、$\alpha, \beta$ はマスキングパラメータです。これにより、各パッチに対する許容可能な減衰率 $t_i = C'_n(f_i, p) / C_n(f_i, p)$ が計算されます。
そして、この許容減衰率ベクトル $t$ と最も類似した減衰カーブを持つSRネットワーク/ブランチを選択します。
$$ \text{branch/network} = \arg \max_j \frac{t \cdot \hat{t}_j}{|t| |\hat{t}_j|} $$
ここで、$\hat{t}_j$ は候補SRメソッド $j$ の減衰カーブから得られるベクトルです。 - 応用と評価: 本フレームワークは、SRネットワークの分岐(earlier exit points)やネットワーク深度の変更といったシナリオで適用されます。VDSRとEDSRをベースラインモデルとして使用し、画像およびビデオデータセットで定量的な評価(PSNR、SSIM、FLOPS)と定性的な評価(ユーザー評価)を行いました。結果として、提案手法は知覚品質を維持しつつ、FLOPSを2倍以上削減できることを示しています。特に、ユーザー研究では、提案手法と元のSRネットワークの出力間で知覚的な違いがないことが示されました。
- 将来の展望: VR/ARディスプレイにおけるfoveated SR(視線位置に応じたSR)への拡張、色情報を用いたCSFの統合、ビデオ特有のSR技術との組み合わせなどが挙げられています。
本稿は、人間の視覚特性を深く理解し、それを計算効率と視覚的品質のトレードオフを最適化するSRフレームワークに統合した点で、重要な貢献をしています。
Q:提案手法の処理の流れを順序だてて説明してください
A:
この論文で提案されているHVPF(Human Visual Processing Framework)の処理フローは、人間の視覚特性を利用して、Super-Resolution(SR)処理の計算コストを動的に最適化することを目的としています。主要なステップは以下の通りです。
-
SR手法の復元能力の定量化(事前計算):
- まず、様々なSR手法(または同じ手法の異なるバリアント、例:異なるネットワークの深さや分岐点)の周波数応答を特性評価します。
- 具体的には、高解像度画像 $I$ をダウンサンプリングして低解像度画像 $I_{\downarrow k}$ を作成し、これをSR手法 $\phi$ でアップスケールして $\hat{I} = \phi(I_{\downarrow k})$ を得ます。
- $\hat{I}$ と $I$ のフーリエ変換の振幅を比較することで、各空間周波数 $f$ におけるSR手法の復元能力を示す減衰曲線 $\alpha_{\phi, k}(I, f) = \frac{|F(\phi(I_{\downarrow k}))(f)|}{|F(I)(f)|}$ を計算します。
- この計算を多数の画像に対して行い、平均化することで、SR手法固有の総合的な減衰曲線 $\alpha_{\phi, k}(f)$ を求め、これをガウス関数でモデル化します。
- これにより、各SRバリアントがどの空間周波数帯域をどれだけ再構築できるかを示す「性能プロファイル」が事前に準備されます。
-
入力画像のパッチ分割:
- SR処理を行う入力画像やビデオフレームは、複数の小さなパッチに分割されます。
- このパッチサイズは、使用するSRモデルのリceptive field(受容野)に基づいて決定されます。
-
知覚コントラストのモデリング(各パッチごと):
- 各画像パッチ $p$ について、その物理的な輝度コントラスト $C(f, p)$ を、多重解像度のラプラシアン-ガウシアンピラミッドを用いて計算します。
- この物理コントラストを、人間の視覚系の特性をモデル化したコントラスト感度関数 (CSF) で正規化し、$C_n(f, p)$ を求めます。CSFは、空間周波数、輝度、色、運動などに応じて人間のコントラスト感度が変化することを考慮します。
- さらに、視覚マスキングモデルを組み込むことで、周辺のコントラストが知覚に与える影響を考慮し、最終的な知覚コントラスト $C_t(f, p)$ を計算します。
-
最適な減衰曲線の決定(各パッチごと):
- 知覚コントラストモデルに基づき、「人間の視覚が品質の低下を感知しないギリギリのライン」を決定します。
- 具体的には、元のパッチの知覚コントラスト $C_t(f, p)$ と、SR処理後の出力パッチの知覚コントラスト $C'_t(f, p)$ の差が「1 JND(Just Noticeable Difference、知覚最小差)」となるような $C'_t(f, p)$ を求めます。
- この $C'_t(f, p)$ と $C_t(f, p)$ から、各空間周波数における「許容可能な減衰率」 $t_i = \frac{C'_n(f_i, p)}{C_n(f_i, p)}$ を計算します。これは、人間の目には品質の劣化が知覚されない範囲で、どの周波数成分をどの程度まで減衰させても良いかを示すターゲットの減衰曲線となります。
-
最適なSRバリアントの選択(各パッチごと):
- ステップ1で事前に計算した各SRバリアントの減衰曲線(性能プロファイル)と、ステップ4で求めた各パッチの許容可能な減衰率(ターゲットの減衰曲線)を比較します。
- コサイン類似度などの指標を用いて、許容可能な減衰曲線に最も近い(しかしそれを上回らない)減衰曲線を持つSRバリアントを選択します。これにより、知覚品質を損なわずに、最も計算コストの低いSR処理(例:ネットワークの浅い分岐、チャネル数の少ないネットワーク)が選ばれます。
-
SR処理と合成:
- 選択されたSRバリアントを用いて、各パッチがSR処理されます。
- 処理されたパッチは、元の画像の位置に合わせて再構成され、最終的な高解像度画像が出力されます。
このHVPFのオーバーヘッドは最小限に抑えられており、GPU上で効率的に実装できるとされています。結果として、このフレームワークは、知覚品質を維持しつつ、計算コストを大幅に削減することができます。特にAR/VRアプリケーションや、画面上の注視点に応じて品質を調整するfoveated rendering(中心窩レンダリング)への応用も視野に入れています。
Q:関連手法との比較について詳しく説明してください
A:
提案手法であるHuman Vision Constrained Super-Resolutionは、既存のSuper-Resolution (SR) 手法や視覚モデル、効率化手法の文脈でいくつかの重要な比較点と差別化があります。
1. 従来のSR手法との比較
-
従来の補間ベース手法 (Nearest-Neighbor, Bilinear, Bicubic):
- これらの手法は、入力画像のみを考慮し、失われた高周波情報を回復する能力が根本的に限られています。計算コストは低いですが、品質向上には限界があります。
- 提案手法との違い: 提案手法は、深い学習モデルの能力を活用して高周波を再構築しつつ、人間の視覚が感知できない部分の計算を削減します。つまり、補間ベースの手法が提供できない高品質な再構築を、効率的に実現します。
-
ディープラーニングベースのSR手法 (CNNベース, Transformerベース, Diffusionモデル):
- 初期のCNNベース(例: SRCNN [13], VDSR [21, 22])から、残差ネットワーク(例: EDSR [28])、GANベース(例: SRGAN [49])、そして最近のVision Transformer [5, 14, 27, 29] やDiffusionモデル [26, 41, 52] など、非常に高品質な結果を生成できるようになりました。
-
提案手法との違い:
- コンテンツ・視聴条件の独立性: ほとんどの現代的な深層学習SR手法は、基礎となるコンテンツや視聴条件に依存せず、一様に画像を処理します。これに対し、提案手法は「人間の視覚システム (HVS) の感度が、空間周波数、輝度、色、コントラスト、動きなどの画像特性や、環境光、視聴距離などの視聴条件によって変化する」という観察に基づいています。
- 計算資源の浪費の回避: 既存の手法は、視聴者が知覚できないレベルの細部まで画像をアップサンプリングするために計算資源を費やしている可能性があります。提案手法は、HVSの解像能力を超える詳細が生成される場合に、その計算を「無駄な資源」とみなし、これを削減します。
- アーキテクチャに依存しないアプローチ: 提案手法は、特定のSRネットワークアーキテクチャに限定されません。既存のSRモデル(VDSR, EDSR, SwinIRなど)と組み合わせて、それらの計算効率を向上させることができます。これは、SRアルゴリズムが周波数ドメインでどのように動作するかを定量化し、それをHVSモデルでガイドするという汎用的な原則に基づいているためです。
2. temporally-consistent Video SR との比較
-
従来のVideo SR手法:
- これらの手法は、複数のフレームを利用して空間的再構築を向上させることを目指します(例: モーションベクトルやオプティカルフローを用いてフレーム間の一貫性を確保 [36])。
- 提案手法との違い: 提案手法は、従来のVideo SRとは異なる視点を持っています。それは「動きによって人間の空間的細部への感度が低下する」というHVSの特性に着目することです。そのため、動きの大きさに応じてSRの品質を低下させても、視覚的な劣化は知覚されにくいという事実を利用し、フレームごとのSRを高速化します。提案モデルは、動きによる視覚感度の低下を定量化し、それに応じて空間品質を適切に低下させます。
3. 効率的なSR手法や適応型計算手法との比較
-
ネットワークの枝分かれ (Network Branching) や深さの変更:
- 一部の効率化手法では、ネットワークに途中の終了点(exit points)を設けたり、ネットワークの深さやチャネル数を変えることで、計算量を調整します [19, 20, 23, 48, 53]。
- 提案手法との違い: 提案手法は、これらの手法の「制御メカニズム」として機能します。どのパッチにどの深さのネットワークやどの分岐点を使用すべきかを、人間の視覚モデルに基づいて動的に決定します。つまり、計算効率を向上させるための既存のネットワーク設計アプローチと「シームレスに統合」できる点が強みです。
4. Visual Difference Predictors (VDP) との比較
-
VDPフレームワーク (Daly [11], HDR-VDP [30], FOVVideoVDP [31], ColorVideoVDP [33]):
- VDPは、人間の視覚の圧縮的な性質に触発され、2つの画像間の知覚差を予測するモデルです。初期視覚系の周波数選択的な性質を頑健にモデル化します。
- 提案手法との違い: 提案手法のHVPFは、「Deep LearningベースのSR問題に対するリアルタイムアプリケーションのために特別に調整されたVDPフレームワーク」と見なすことができます。従来のVDPが主に画像の忠実度評価や圧縮率制御に使われてきたのに対し、提案手法は、深層学習SRモデルの「動的な計算資源配分」という新しい応用領域を開拓しています。著者らは、頑健な人間の視覚フレームワークを効率的なニューラルネットワークベースの画像/ビデオ処理に適用した最初の事例であると述べています。
5. foveated rendering (中心窩レンダリング) との比較
-
Foveated Rendering手法 (Patney et al. [39]):
- AR/VRディスプレイにおいて、視線から離れるほど視覚の鮮明度が著しく低下するという人間の周辺視覚の特性を利用し、中心窩(視線がある場所)の解像度を高く保ちつつ、周辺の解像度を下げてレンダリング効率を向上させる手法です。
- 提案手法との違い: 提案手法は、StelaCSF [32] のような視線中心からの距離(eccentricity)に応じたコントラスト感度をモデル化できるCSFを使用することで、foveated SR(視線追跡型超解像)への拡張を提案しています。これにより、VR/ARアプリケーションにおいて、計算コスト削減をさらに推し進めることができます。Figure 6やFigure 9でその可能性を示しており、これは既存のfoveated renderingとSRを組み合わせるという新しい方向性を示唆しています。
まとめ
提案手法の核となる強みは、人間の視覚の「圧縮的な性質」と「周波数選択性」という根本的な特性に深く根ざしている点です。これにより、既存の高性能なSRモデルの能力を維持しつつ、視覚的に冗長な計算を特定し、削減することが可能になります。これは、PSNRやSSIMといった従来の客観的指標が捉えきれない「人間が知覚する品質」に焦点を当てることで、これまでのSR研究が直面していた計算効率と品質のトレードオフに対する、洗練された解決策を提示していると言えるでしょう。

Q:提案手法の限界と今後の課題はなんですか?
A:
この提案手法Human Vision Constrained Super-Resolution(HVPF)は、非常に有望なアプローチですが、どのような研究にも限界と今後の課題が存在します。この論文で挙げられている点と、研究者として考えられる追加の課題を以下にまとめます。
論文で言及されている限界と今後の課題
-
ビデオコンテンツにおけるエイリアシング問題:
- 限界: 各ビデオフレームを独立した静止画として処理しているため、エイリアシング(ジャギーやモアレのような偽信号)の問題が生じる可能性があります。これは、フレーム間の時間的連続性を十分に考慮できていないことに起因します。
- 今後の課題: ビデオに特化したSR技術との連携を深めることが重要です。時間的整合性を保証するようなビデオSR手法の特性をHVPFに統合することで、エイリアシング問題の解決や、より滑らかな動画生成が可能になるでしょう。
-
パッチ間の空間的整合性:
- 限界: 提案手法は画像をパッチに分割し、各パッチで異なるSRバリアントを選択するため、隣接するパッチ間で空間的な不整合が生じる可能性があります。ただし、ユーザー実験では参加者からこのような不整合は報告されていないとのことです。
- 今後の課題: 実際には知覚されなかったとはいえ、理論的には不整合のリスクがあるため、パッチ間の境界領域で品質やスタイルの一貫性を保証するようなメカニズム(例:重なり合ったパッチの処理、境界領域のブレンド、より大きな文脈の考慮)を導入することが考えられます。
-
輝度情報への依存と色情報の欠如:
- 限界: 現在のモデルは、画像の輝度情報のみに基づいて評価を行っています。
- 今後の課題: 色覚に特化したCSF(例:CastleCSF [3])などの最近の進歩を取り入れることで、色情報をさらに活用し、より包括的な人間の視覚モデルを構築できます。これにより、色の忠実度に関する知覚的な最適化も可能になるでしょう。
-
foveation-awareフレームワークとの統合:
- 限界: 現状では、foveated rendering(中心窩レンダリング)の概念を初期的に導入している段階であり、完全な統合は今後の課題とされています。
- 今後の課題: 視線追跡技術と密接に連携し、StelaCSF [32] のような離心率(視線中心からの距離)に応じたコントラスト感度をモデル化する機能を利用して、AR/VRデバイスにおけるfoveated SRを本格的に実装・評価することです。これにより、周辺視野の計算資源を大幅に削減し、さらなる性能向上を実現できる可能性があります。


Q:Supplementary Materialに書かれている内容に関してわかりやすくまとめて、解説してください
A:
補足資料の概要とポイント
この補足資料は、提案手法の有効性をさらに裏付けるための詳細情報と追加結果を提供しており、主に以下の3つのセクションに分かれています。
- A. Subjective Quality Study Setup(主観的品質評価のセットアップ): ユーザー研究の実施環境に関する詳細。
- B. Additional Subjective Quality Results(追加の主観的品質評価結果): 本編で触れられた以外のユーザー研究結果。
- C. FLOPS for evaluation and performance bottleneck(評価のためのFLOPSとパフォーマンスのボトルネック): 計算効率の指標に関する考察。
- D. Framework input(フレームワーク入力): HVPFの入力パッチサイズに関する詳細。
- E. Extension - AR/VR Display(拡張 - AR/VRディスプレイ): AR/VR向けアプリケーションへの拡張に関する初期結果。
- F. More Qualitative Results(さらなる定性的な結果): 定性的評価のための追加画像。
順番に解説します。
A. Subjective Quality Study Setup(主観的品質評価のセットアップ)
-
目的: ユーザー研究がどのような環境で行われたかを詳細に説明することで、結果の信頼性と再現性を示します。
-
内容:
- 視聴環境: 標準的なオフィス環境を想定。
- ディスプレイ: 27インチ Dell U2723QE(解像度 3840 × 2160、ピーク輝度 400 cd/m$^2$)。
- 視聴距離: 60 cm(顎置きを使って固定)。
- 設定: 全ての計算と評価はこの設定に基づいて行われたことが強調されています。
-
解説: このセクションは、本編で示されたユーザー研究の結果が、どのような標準化された条件下で得られたかを示すものです。研究の科学的な厳密さを保証するために重要です。
B. Additional Subjective Quality Results(追加の主観的品質評価結果)
このセクションでは、本編で一部紹介されたユーザー研究の、より詳細な結果が示されています。
-
B.1. Channel Depth Application(チャンネル深度アプリケーション)
- 目的: EDSRネットワークのチャンネル数(深さ)を変化させることで計算量を最適化するケース(本編のFigure 3 bottom)に関するユーザー研究結果。
- 設定: 5種類のEDSRネットワーク(チャンネル数: 256, 128, 64, 16, 8)を用意。ベースラインは256チャンネルのEDSRを画像全体に一様に適用したもので、HVPFはパッチごとにこれら5つから最適なものを選択。
- 結果 (Figure 7): 平均してユーザーの選好度が約50%に集中していることが示されています。
- 削減効果: HVPFを用いることで、76.4%ものFLOPS削減を達成しながらも、ユーザーはベースラインとの知覚的な違いをほとんど感じられませんでした。
- 解説: 本編ではVDSRの分岐(branching)に関するユーザー研究が中心でしたが、こちらはEDSRのチャンネル深度を調整するケースでもHVPFが有効であることを示しています。大幅な計算削減にもかかわらず、人間は品質の低下を知覚できないという、本手法の主要な主張を裏付けています。
-
B.2. Video Content(ビデオコンテンツ)
- 目的: ビデオコンテンツに対するHVPF(VDSRの分岐アプリケーション)の有効性を評価するユーザー研究結果。
- 設定: Inter4kデータセットから7つの自然なビデオを使用。各フレームを8倍にダウンサンプリング後、4倍にアップサンプリング。VDSRネットワークの分岐アプリケーション(本編のFigure 3 top)を適用。
- 結果 (Figure 8): 平均選好度が約50%であり、ユーザーはテストケース間の違いを感知できませんでした。
- 削減効果: HVPFを使用することで、51.3%のFLOPS削減を達成。
- 解説: 動画の場合、動きによって人間の空間的詳細への感度が低下するという特性をHVPFが利用できることを示しています。これにより、動画SRにおいても計算効率を大幅に向上させつつ、知覚品質を維持できることが実証されました。
-
B.3. Information about participants(参加者に関する情報)
- 内容: 全てのユーザー研究の参加者は、CS学部の学生(20〜30歳)、正常または矯正視力があり、実験の目的を知らされていませんでした。各研究の参加者数(分岐15名、深度9名、動画14名)と性別内訳が示されています。
- 解説: 参加者の属性を明確にすることで、研究結果の信頼性と一般化可能性に関する情報を提供します。
C. FLOPS for evaluation and performance bottleneck(評価のためのFLOPSとパフォーマンスのボトルネック)
- 目的: 計算効率の指標としてFLOPSを採用した理由と、パフォーマンスのボトルネックに関する考察。
-
内容:
- FLOPS採用の理由: FLOPSは、特定の機械や実装に依存しない汎用的な指標であり、類似研究でも広く使われているため採用されました。
- ボトルネックに関する考察: HVPFでは、特定のパッチが大規模な/高能力のネットワークを必要とする場合、それがボトルネックになる可能性があります。平均FLOPSだけではこの情報が伝わりにくいという問題があります。
-
解決策の提案:
- プロセッサ数がパッチ数より少ない場合、スケジューリングによって負荷が均等に分散される。
- 複数の連続するフレームを処理に考慮することで、負荷をさらに均等に分散できる。
- 画像内にフルネットワークを必要とするパッチが全く存在しない可能性もあり、その場合フルネットワークは使われない。
- 解説: FLOPSは客観的な指標として有用ですが、リアルタイム性能(wall clock time)を直接示すものではありません。特にパッチごとの適応型処理では、最も重い処理がボトルネックとなる可能性があります。このセクションは、FLOPSの限界を認識しつつ、HVPFが実際にどのような条件下でリアルタイム性能を発揮するか、そのためのヒント(並列処理、スケジューリング、マルチフレーム処理など)を提供しています。
D. Framework input(フレームワーク入力)
- 目的: HVPFに入力されるパッチサイズに関する具体的な詳細。
-
内容:
- VDSRの場合: 入力パッチサイズは低解像度画像で10x10ピクセル(結果的にアップサンプリング後の画像では40x40ピクセルに対応)で、これはVDSRの受容野サイズに相当します。LR画像はSRネットワークに渡される前にbicubic補間されます。
- EDSRの場合: 入力パッチサイズは低解像度画像で48x48ピクセル。EDSRはbicubic補間を事前に含まないため、そのままのLR画像パッチが入力されます。
- 汎用性: SRネットワークの受容野より小さい入力パッチも、特に小さい画像の場合には有利である可能性があります。
- 解説: HVPFがどのように入力画像(低解像度)をパッチに分割し、それをSRネットワークにどう渡すかに関する技術的な詳細です。パッチサイズは、SRネットワークの設計(受容野、事前補間の有無など)によって異なることが示されています。
E. Extension - AR/VR Display(拡張 - AR/VRディスプレイ)
- 目的: AR/VRヘッドセットでの視線追跡型超解像(foveated SR)への応用可能性と初期結果の提示。
-
内容:
- 必要性: 次世代のAR/VRヘッドセットは、高画質、高フレームレート、低消費電力が求められ、広視野角ディスプレイでは周辺視野の視覚鮮明度が著しく低下するというHVSの特性(網膜細胞の分布 inhomogeneity [10, 51])を考慮することが重要です。
- StelaCSFの利用: StelaCSF [32] のような、離心率(視線中心からの距離)に応じたコントラスト感度をモデル化できる関数を利用することで、HVPFを視覚野全体での視覚鮮明度に対応させることが可能です。
- 実装: 現代のVR/ARヘッドセットに搭載されているアイトラッカーでHVPFを制御できます。
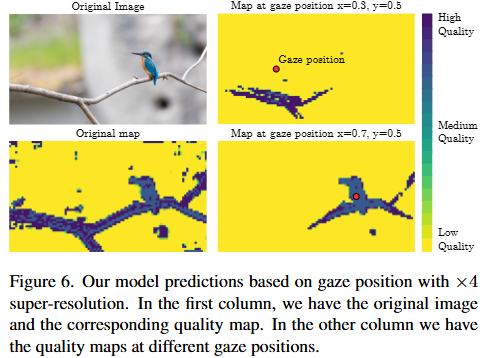
- 初期結果 (Figure 9): 視線位置に応じて、HVPFが予測する「必要なSR品質マップ」がどのように変化するかが視覚的に示されています。視線が向いている中央(fovea)では高画質が予測され、周辺(periphery)では最低画質で十分と予測されています。
- 解説: これは提案手法の将来的な方向性を示す非常に重要なセクションです。人間の視覚特性(特に周辺視野での視覚低下)を最大限に活用することで、AR/VRのような計算資源制約の厳しいアプリケーションにおいて、HVPFが大幅な計算削減と知覚品質維持の両立を可能にすることを示唆しています。この応用は、今後の研究で大きなインパクトを持つ可能性を秘めています。
F. More Qualitative Results(さらなる定性的な結果)
- 目的: HVPFの性能を視覚的に示すための追加画像。
-
内容:
- Figure 10: HVPFが生成する「品質マップ」を示しており、コントラストや詳細が高い領域では高画質なSRを、低い領域では低画質なSRを選択している様子がわかります。
- Figure 11〜15: 提案手法とオリジナルネットワークによるSR結果の比較画像。オリジナルネットワークの出力とHVPFの出力が視覚的にほとんど区別できないことを示しています。
- 解説: 主観的評価の結果を補完する形で、実際の画像でHVPFがどのように機能し、視覚的な品質を維持しながら計算資源を賢く配分しているかを示しています。これにより、HVPFの有効性が直感的に理解しやすくなります。
全体的なまとめ
補足資料は、提案手法が単なる理論的なアイデアではなく、様々なシナリオ(異なるネットワークタイプ、動画コンテンツ、AR/VR応用)において、人間の知覚品質を損なうことなく計算効率を向上させる、実用的で堅牢なフレームワークであることを具体的に示しています。特に、VR/AR分野への拡張は、今後のHVPFの大きな可能性を秘めていると言えるでしょう。