Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling (Li, 2025)

3行要約
- 本論文は、raw mesh から高解像度で watertight な3D形状を再構成・生成するための統合フレームワーク Sparc3D を提案します。
- Sparc3D は、高速な remeshing アルゴリズムである Sparcubes と、sparse convolutional VAE である Sparconv-VAE を中核としています。
- このフレームワークは、state-of-the-art の再構成品質と効率を実現し、高解像度3D asset 生成への応用可能性を示します。
Q:この論文の概要を教えてください
A:
高解像度3Dオブジェクトの生成は、メッシュデータの非構造的な性質や高密度な volumetric grid の立方体オーダーの複雑性のため、2D画像の生成に比べて著しく困難なままです。既存の2段階パイプライン、すなわちVAEVAE(2Dまたは3D監督を使用)によるメッシュ圧縮とその後の latent diffusion によるサンプリングは、非効率な表現やVAEで導入される modality mismatch により、しばしば深刻な詳細の損失を招きます。本研究は、sparse deformable marching cubes representation である Sparcubes と、新規な encoder である sparse convolutional VAE (Sparconv-VAE) を組み合わせた統合フレームワーク、Sparc3D を提案します。
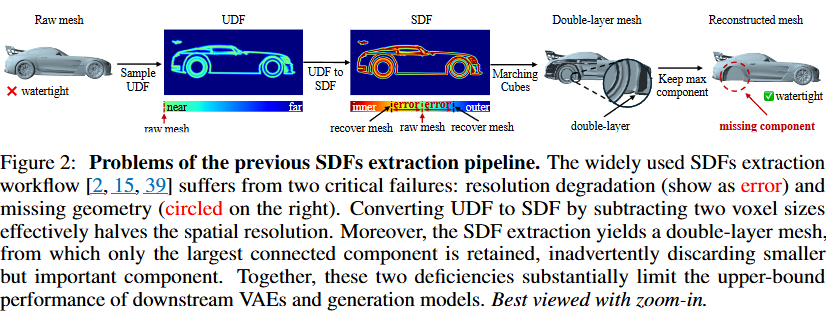
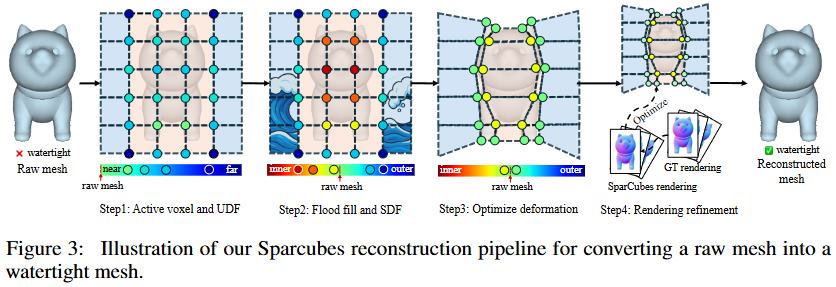
Sparcubes は、生のメッシュを、疎なキューブ上に signed distance field と deformation field を散布することで微分可能な最適化を可能にする、任意トポロジーを持つ高解像度 (1024^3) のサーフェスに変換します。このパイプラインは、以下のステップから構成されます。
まず、Step 1では、入力サーフェスの狭帯域内の active voxel を抽出し、各 corner vertex $x \in \mathbb{R}^3$ について unsigned distance
$UDF(x) = min_{y in M} |x - y|_2$
を計算して疎な volumetric grid $\Phi$ を構築します。
Step 2では、外部領域からの flood fill によりバイナリの occupancy label $T(x)$ を得て、粗い signed distance field $SDF(x) = (1 - 2T(x)) \cdot UDF(x)$ を生成します。
Step 3では、sparse cube structure の幾何学的変形 $(V + \Delta V, C, \Phi_v)$ を gradient-based optimization によって実行し、頂点を UDF 勾配に沿って微小に変位させることで、ゼロレベルセットのアライメントを修正し、符号推定の精度を向上させます:$x' = x - \eta \cdot \nabla UDF(x)$, $\delta(x) \approx \delta(x')$。最終的なデータ構造は $(V, C, \Phi_v, \Delta V)$ となります。
Step 4(任意)では、reconstructed mesh $M_r$ からの differentiable rendering loss $L_{\text{render}} = |R_D(M_r) - I_{D_{\text{obs}}}|_2^2 + |R_N(M_r) - I_{N_{\text{obs}}}|_2^2$ を用いて、視覚的信号による refinement を行います。
Sparconv-VAE は、sparse convolutional network のみで完全に構築された、初の modality-consistent な variational autoencoder です。これは、Sparcubes パラメータ ${\phi \in \Phi_v, \delta \in \Delta V}$ を直接 sparse latent feature $z$ に圧縮し、modality conversion なしで同じフォーマットにデコードします。Encoder は sparse residual convolutional block と軽量な local attention module からなり、Decoder は sparse residual convolution と self-pruning upsample block をインターリーブします。Loss function は、occupancy $L_{\text{occ}} = \text{BCE}(\hat{o}, o)$、符号 $L_{\phi_{\text{sign}}} = \text{BCE}(\text{sign}(\hat{\phi}), \text{sign}(\phi))$、値 $L_{\phi_{\text{mag}}} = |\hat{\phi}, \phi|_2^2$、変形 $L_{\delta} = |\hat{\delta}, \delta|_2^2$、そしてVAEVAEの Kullback–Leibler divergence $L_{\text{KL}} = \text{KL}(q(z|\delta, \phi)|p(z))$ の合計として定義されます:$L = \lambda_{\text{occ}} L_{\text{occ}} + \lambda_{\phi_{\text{sign}}} L_{\phi_{\text{sign}}} + \lambda_{\phi_{\text{mag}}} L_{\phi_{\text{mag}}} + \lambda_{\delta} L_{\delta} + \lambda_{\text{KL}} L_{\text{KL}}$。小さな穴は、boundary half-edges から boundary loop を再構築し、classic ear-filling pipeline を用いて triangulate することで塞がれます。
実験結果では、Sparcubes は ABO, Objaverse, Wild データセットにおいて、Chamfer Distance, Absolute Normal Consistency, F1 score の全ての指標で従来手法 (Dora-wt) を上回り、wt-512 の結果が従来手法の wt-1024 を凌駕することを示しました (Table 1, Figure 4)。Sparconv-VAE の再構築も、TRELLIS, Craftsman, Dora, XCubes と比較して優れた性能を示しました (Table 2, Figure 5)。Latent diffusion と組み合わせた生成実験でも、より詳細な watertight な 3D 形状を合成できることを確認しました (Figure 6)。Ablation study では、Sparcubes による変換コストと Sparconv-VAE の訓練コストが従来手法より大幅に削減されることを示しました。
結論として、Sparc3D は、トポロジーを保持する remeshing と modality-consistent な latent encoding という2つのボトルネックを解決する統合フレームワークです。Sparcubes は、生の non-watertight メッシュを高解像度 watertight サーフェスに変換し、Sparconv-VAE はその表現を効率的に圧縮・再構築します。これにより、state-of-the-art の再構築 fidelity、訓練コストの削減、そして latent diffusion とのシームレスな統合による高解像度3D生成が可能となります。制限として、Sparcubes は元のテクスチャ情報を保持せず、内部構造は remeshing 時に破棄される場合があります。
Q:提案手法の処理の流れを順序だてて説明してください
本論文で提案されている Sparc3D は、大きく分けて2つの主要なコンポーネントから構成される統合フレームワークです。1つは Sparcubes と呼ばれる、元の raw mesh を高解像度でウォータータイトな疎な表現に変換するパイプライン、もう1つは Sparconv-VAE と呼ばれる、その疎な表現を扱うための variational autoencoder (VAE) です。
処理の流れを順序立てて説明します。
-
入力: Raw Mesh
- フレームワークの入力は、必ずしもウォータータイトであったり、内部構造が完全であったりしない raw mesh データです。
-
Sparcubes によるSparse Representationの構築とWatertight Meshの再構築
- これは、入力 raw mesh から、後段の Sparconv-VAE が処理できる高解像度の疎なボクセル表現(Sparcubes表現)を構築し、同時に高精度なウォータータイトメッシュを再構築するプロセスです。処理は以下のステップで行われます (図3を参照)。
-
Step 1: Active voxel抽出とUDF計算
- 入力 mesh の表面のごく近傍にあるボクセルを特定し、「active voxel」とします。
- これらの active voxel の各頂点について、元の mesh 表面までの符号なし距離関数 (UDF) を計算します。これにより、表面近くに距離情報が集中した疎な volumetric grid Φ が得られます。
-
Step 2: Flood fillによるCoarse Sign LabelingとSDF計算
- Bounding box の角など、既知の外部領域から volumetric flood fill アルゴリズムを実行します。これにより、各点が形状の内部か外部かを示すバイナリの occupancy ラベル T(x) を取得します。
- この occupancy ラベルと Step 1 で計算した UDF を組み合わせて、大まかな符号付き距離関数 (SDF) を計算します: $\text{SDF}(x) = (1 - 2T(x)) \cdot \text{UDF}(x)$。
-
Step 3: Gradient-based Deformation Optimization
- 疎な cube 構造(active voxel の集合)の頂点位置を直接最適化します。各頂点を UDF の gradient の方向にわずかに変位させることで、疎な SDF volume が mesh 表面のゼロレベルセットに、より正確に沿うように変形させます。これにより、符号推定の精度や幾何学的整合性を向上させます。結果として、各 cube 頂点に SDF 値 (Φv) と変位ベクトル (∆V) を持つ疎な cube grid が得られます。これが Sparcubes 表現です。
-
Step 4: Rendering-based Refinement (Optional)
- 入力 raw mesh に対応する多視点画像などが利用可能な場合、微分可能な mesh 抽出機能を利用して、再構築された mesh Mr と観測データ(rendered depth RD, rendered normal RN)との間の rendering loss を計算し、これを最小化するように Sparcubes 表現をさらに fine-tuning します。これにより、視覚的なリアリズムと幾何学的整合性を向上させます。
-
Step 1: Active voxel抽出とUDF計算
- この Sparcubes パイプラインの出力は、高解像度 (例: 1024³) でウォータータイトな mesh と、その元となる疎な表現 {Φv, ∆V} です。ウォータータイト mesh は VAE の ground truth として使用されます。
- これは、入力 raw mesh から、後段の Sparconv-VAE が処理できる高解像度の疎なボクセル表現(Sparcubes表現)を構築し、同時に高精度なウォータータイトメッシュを再構築するプロセスです。処理は以下のステップで行われます (図3を参照)。
-
Sparconv-VAE による圧縮と再構築
- Sparcubes によって得られた疎な表現 {Φv, ∆V} を入力として、これを効率的に圧縮し、潜在空間 z にエンコードし、元の表現を再構築します。
- Encoder: 疎な residual convolutional block を重ねることで、入力の疎な特徴を段階的に downsample し、低次元の疎な潜在特徴 z を得ます。最も粗い解像度では、軽量な local attention module で近傍情報を集約します。
- Decoder: Encoder と mirror する形で、疎な residual convolution と self-pruning upsample block を組み合わせて使用します。潜在特徴 z から、元の解像度で Sparcubes パラメータ {ˆΦv, ˆ∆V} を予測します。Decoder は、サブディビジョンされたボクセルの occupancy mask ˆo、符号 ˆϕ の符号 sign(ˆϕ)、符号 ˆϕ の大きさ ∥ˆϕ∥、変位ベクトル ˆδ を個別に予測します。
- Loss Function: 予測されたパラメータ {ˆo, sign(ˆϕ), ∥ˆϕ∥, ˆδ} と Sparcubes の出力 {o, sign(ϕ), ∥ϕ∥, δ} との間の再構築誤差 (Locc, Lϕsign, Lϕmag, Lδ) および潜在空間の正規化 (LKL) を合計した目的関数 L を最小化するように学習します。
- Hole Filling: Decoder の予測には小さな穴が含まれる場合がありますが、基となる Sparcubes 表現が本質的にウォータータイトであることを利用し、境界 edge を検出して ear-filling アルゴリズムで穴を埋める後処理を行います。
- この Sparconv-VAE は、疎な表現を modality-consistent に処理するため、heavy な global attention を必要とせず、高効率かつ near-lossless な再構築を実現します。
- Sparcubes によって得られた疎な表現 {Φv, ∆V} を入力として、これを効率的に圧縮し、潜在空間 z にエンコードし、元の表現を再構築します。
-
Latent Diffusion Model との統合 (高解像度生成)
- Sparconv-VAE によって学習された潜在空間を利用して、TRELLIS [32] のような既存の latent diffusion model を fine-tuning または学習します。
- テキストや単一画像などの条件から、この潜在空間で高解像度な 3D 形状に対応する潜在表現を生成します。
- 生成された潜在表現を Sparconv-VAE の Decoder に通すことで、最終的な高解像度 3D mesh を生成します。
このように、Sparc3D はまず Sparcubes で入力 raw mesh を効率的な疎な表現に変換・再構築し、次に Sparconv-VAE でその疎な表現を学習・圧縮・再構築可能にすることで、高解像度かつ高忠実度な3D形状生成パイプラインを実現しています。
Q:関連手法との比較について詳しく説明してください
A:
Sparc3D は、疎な表現である Sparcubes と、それを扱うための疎な畳み込みベースの VAE である Sparconv-VAE という、2つの核となる技術で構成されています。これらの技術が、従来の3D形状処理および生成パイプラインにおける長年の課題を克服することを目指しています。
主な比較点は以下の通りです。
-
3D 形状表現について
-
既存手法の課題:
- Mesh/Point Cloud: 表面の詳細や任意のトポロジーを表現できますが、グラフ構造が不規則なため、ニューラルネットワークでの学習が困難です。また、Point cloud は watertight 表面への変換が容易ではありません。
- Dense Volumetric Grids: 空間を密なボクセルで表現するため、解像度を上げると計算量とメモリ使用量が解像度の3乗で増加し、高解像度化が非現実的になります。
- 既存の Isosurface (Marching Cubes/Dual Marching Cubes): 通常、均一なボクセルサイズに依存しており、詳細の表現に限界があります。FlexiCubes [26] のように deformable なものもありますが、パイプライン全体での利用に課題があります。
-
Sparc3D のアプローチ:
- Sparcubes は、入力メッシュの表面近くに限定された疎なボクセルキューブの集合として形状を表現します。各キューブの頂点は、符号付き距離値と変位ベクトルを持ちます。
- この表現は、密なグリッドに比べて計算効率とメモリ使用量が大幅に削減されます。
- さらに、FlexiCubes [26] に似た変形可能なメカニズムを組み込むことで、疎な構造でありながらローカルな形状に柔軟に適応し、高精細な詳細を捉えることができます。
- メッシュや点群のような unstructured なデータや、密なグリッドの計算コストの問題を避けつつ、Isosurface ベースの利点(watertight 化など)を活かしています。
-
既存手法の課題:
-
VAE アーキテクチャと Modality 一貫性について
-
既存手法の課題:
- 多くの3D生成パイプライン [2, 15, 28, 32, 39] は、VAE で形状を潜在空間に圧縮し、その後 latent diffusion モデルで生成するという2段階のアプローチを採用しています。
-
Modality Mismatch: 既存の VAE は、多くの場合、入力モダリティ(例: 点群の特徴量、2D画像の特徴量)と出力モダリティ(例: SDF値)の間にギャップがあります。
- VecSet-based VAEs [2, 15, 37, 38, 39]: 表面の点や法線などのローカルな特徴をグローバルな潜在ベクトルセットに圧縮し、SDF 値としてデコードします。この過程で、特徴の抽象化とモダリティ変換の両方を VAE が行う必要があり、高価な attention 機構に大きく依存し、モデルの複雑さが増します。
- Sparse Voxel-based VAEs [23, 32]: メッシュを疎なボクセルグリッドに変換しますが、入力特徴(例: 点の法線、DINOv2 特徴 [22])から SDF フィールドをデコードする際にモダリティ変換が必要です。
- これらの modality ギャップは、詳細の損失や、 underlying な矛盾の増幅につながる可能性があります。
-
Sparc3D (Sparconv-VAE) のアプローチ:
- Sparconv-VAE は、Sparcubes によって得られた疎な表現(符号付き距離 Φv と変位 ∆V)を、同じ疎な表現 {ˆΦv, ˆ∆V} として直接再構築します。
- これにより、入力と出力の間で modality が完全に一致します。
- Modality ギャップがないため、heavy な global attention 機構に頼る必要がなく、軽量なアーキテクチャで高効率な処理が可能です。
- Sparse Convolutional Network と Self-Pruning Decoder を用いることで、疎なデータの構造を活かしつつ、near-lossless な再構築を実現します。
-
既存手法の課題:
-
Watertight Remeshing 性能について (Sparcubes)
- 比較対象: Dora-wt [2] (他の既存手法 [15, 39] の代表として)
-
既存手法の課題 (図2を参照):
- 多くの raw mesh は非ウォータータイトです。
- 従来の SDF 抽出パイプラインは、UDF から SDF への変換時に2つのボクセルサイズを減算することで実効解像度を半分にし、エラーを導入します。
- Marching Cubes や Dual Marching Cubes [18, 25] の適用後、二重層のメッシュが生成され、最大の連結成分のみを残す処理で小さく重要なジオメトリが失われることがあります。
-
Sparcubes の優位性 (表1, 図4を参照):
- raw mesh を30秒以内(1024³ 解像度)でウォータータイトメッシュに変換します。これは既存手法 [2, 15, 39] より約3倍高速です。
- UDF から SDF への変換エラーや、最大の連結成分のみを残すことによるジオメトリの損失を防ぎ、細かい詳細や小さなコンポーネント(例: 車のホイール、棚のフレーム)を忠実に保持・再構築します。
- 定量評価(Chamfer Distance, Absolute Normal Consistency, F1 Score)において、既存手法を全てのデータセットで一貫して上回ります。特に "Wild" データセットのような挑戦的な入力に対して、既存手法と比較して大幅に高い F1 スコアと低い CD を達成しています(表1)。
- 驚くべきことに、Sparcubes による 512³ 解像度の結果が、既存手法の 1024³ 解像度の結果の品質を超えることもあります(図4)。
-
VAE 再構築性能について (Sparconv-VAE)
- 比較対象: TRELLIS [32], Craftsman [15], Dora [2], XCubes [23]
-
Sparconv-VAE の優位性 (表2, 図5を参照):
- State-of-the-art の再構築精度を達成しています(表2)。全てのデータセットにおいて、既存手法よりも優れた Chamfer Distance, Absolute Normal Consistency, F1 Score を示しています。
- 複雑な形状や細かい詳細を忠実に再構築できます(図5の全てのカラム)。
- オープンな表面をウォータータイトな(二重層の)メッシュに変換できます(図5の1, 4, 6カラム)。
- 通常見えない隠れた内部構造を明らかにすることも可能です(図5の6カラム)。
- これは、前述の modality 一貫性のある疎なアーキテクチャと、Sparcubes による高品質な疎な表現を入力としていることによるものです。

-
生成結果について
- 比較対象: TRELLIS [32] (同じ拡散アーキテクチャとモデルサイズを使用)
-
Sparc3D との統合の優位性 (図6を参照):
- Sparconv-VAE の潜在空間で学習した latent diffusion model (TRELLIS を fine-tuning) は、既存手法よりも高忠実度で豊かな詳細を持つウォータータイトな3D形状を合成します。
- 例えば、東屋の鋭い軒先、人物の繊細な顔立ち、ロボットの複雑な構造要素などをより鮮明に捉えています(図6)。
- これは、VAE がより高品質で情報を保持した潜在空間を学習できていることの証です。

-
計算コストについて (Ablation Studies)
- Conversion Cost: Sparcubes による変換は、既存手法 [2, 15, 39] よりも大幅に高速です。512³ で約15秒 (既存手法の半分)、1024³ で約30秒 (既存手法は約90秒) です。VAE の設計において modality 変換を排除したことで、既存パイプラインにある SDF の再サンプリングステップ(512³ で約20秒、1024³ で約70秒)も不要になります。
- Training Cost: Sparconv-VAE は、modality 一貫性のある設計により、既存手法(Sparse voxel-based の TRELLIS [32] や Vecset-based の手法 [2, 15] はそれぞれ約7日かかる)に比べて約4倍速い、2日未満で収束します。
Q:提案手法の限界と今後の課題はなんですか?
A:
本論文で明記されている限界は以下の2点です(Page 10):
- オリジナルのテクスチャ情報を保持しないこと: Sparcubes による remeshing プロセスは、形状のジオメトリに焦点を当てており、入力メッシュが持っていたテクスチャ情報やマテリアル情報を引き継ぎません。これは、生成される3Dモデルの写実性や、テクスチャリングが必要なアプリケーションへの応用において、別途テクスチャ生成のステップが必要になることを意味します。
- 完全に閉じたメッシュの内部構造を破棄すること: Watertight で内部構造を持つメッシュに対して Sparcubes による remeshing を適用した場合、その内部の要素は remeshing プロセス中に破棄されてしまいます。Sparcubes は主に外部表面の accurate かつ watertight な表現に重点を置いており、複雑な内部ジオメトリを維持するようには設計されていません。これは、医療用データ(臓器など)や、機械部品のような詳細な内部構造が重要な形状の処理において制約となります。
これらの明記された限界に加え、論文全体から推測される今後の課題や探求すべき方向性として、以下のような点が考えられます。
-
Sparcubes の汎用性とロバスト性の向上:
- 現在の Sparcubes は、疎なボクセルへのサンプリング、flood fill による coarse な sign 割り当て、そして gradient-based な変形最適化というステップを踏みます。これらのステップは、入力メッシュのノイズや非常に複雑なトポロジーに対して、常に完全にロバストであるとは限りません。例えば、極端に薄いシェル構造や非常に密な網状構造などに対して、sign の割り当てや変形の最適化が困難になる可能性が考えられます。より多様で挑戦的な入力データに対して、ロバスト性を向上させるためのアルゴリズム改良が課題となります。
- Rendering-based refinement がオプションであり、VAE 再構築においては「negligible improvement」であったという記述がありますが、これは特定のタスクにおける結果であり、Sparcubes 自体の出力品質をより多くのデータや視点データを用いてさらに向上させる余地はあるかもしれません。
-
Sparconv-VAE の更なる洗練:
- VAE の Decoder による occupancy の予測が不完全な場合があり、後処理として穴埋めが必要であると述べられています。この穴埋めは「classic ear-filling pipeline」で行われますが、より複雑なケースや、非常に大きな穴に対して常に最適な結果が得られるとは限りません。VAE がより正確な occupancy を予測できるようになるか、あるいはより高度な穴埋め手法を統合することが課題となります。
- Sparse Convolutional Network の効率性は大きな利点ですが、特定のタスクやデータ構造に対して、他の疎なネットワークアーキテクチャ(例:point-based、graph-based など)との組み合わせや比較検討も有益かもしれません。
-
テクスチャおよび内部構造の取り扱い:
- これは明記された限界に直結する課題です。Sparcubes パイプラインの中で、どのようにテクスチャ情報やマテリアル情報を効率的に表現し、Sparconv-VAE で学習・生成できるようにするかは、今後の重要な研究方向です。
- 内部構造については、外部表面と同時に内部構造も表現できるような Sparse representation の拡張や、それらを同時に扱うための VAE アーキテクチャの開発が必要になります。現在の Sparcubes は表面に焦点を当てているため、根本的なアプローチの見直しや拡張が求められます。
-
生成モデルの多様性と制御性:
- 本研究では TRELLIS [32] を fine-tuning する形で生成モデルを構築していますが、Sparconv-VAE の潜在空間が持つ可能性を最大限に引き出すために、より多様な生成モデル(例:異なる拡散モデル、GAN、Transformer ベースの手法など)との統合を探求することも価値があります。
- テキストや画像からの生成に加え、スケッチ [9, 19, 22]、既存の3Dモデルの編集 [12]、物理的な制約 [34] など、よりリッチで直感的な入力や制御を用いた生成方法の開発も、Sparc3D のフレームワークを活かせる分野でしょう。
これらの課題は、Sparc3D が切り開いた高解像度かつ効率的な疎な表現と学習の道を、さらに広げ、より多くの現実世界の3Dモデリングや生成タスクに応用するために重要です。特にテクスチャや内部構造の取り込みは、実用的な3Dアセット生成には不可欠な要素です。