1. はじめに
本記事は、PostgreSQL16パフォーマンスチューニングシリーズの17対応版の一本です。
前回の記事では実行計画(EXPLAIN)の改善を実測しました。本記事は同じt3.micro環境で、PostgreSQL 17で改善された以下の3点を検証します。
- COPY性能向上:サーバ・クライアント間の不要なデータコピーを削減
- ストリームI/O:連続ブロックの先読みによるシーケンシャルスキャン高速化
-
ON_ERRORオプション:COPY FROMのエラー行スキップ機能(新機能)
計測にはpgbench_accountsから派生したpgbench_accounts_largeと、行サイズを大きくした独自テーブルt_copy_largeを使用します。
1.1 この記事でわかること
- COPY性能向上はt3.microで効果が出るのか
- ストリームI/Oはバッファ未ヒット時にどう効くのか
- ON_ERROR ignoreで何ができるようになったのか
2. 検証環境
2.1 環境構成
| 項目 | 内容 |
|---|---|
| OS | Amazon Linux 2023 |
| インスタンス | t3.micro(2vCPU・1GiB)EBS 30GB |
| PostgreSQL 16 | 16.12 |
| PostgreSQL 17 | 17.x(前回記事でバージョンアップ済み) |
| 計測テーブル(COPY) | t_copy_large(独自テーブル・1行約24KB・10万行・約2.4GB) |
| 計測テーブル(ストリームI/O) | pgbench_accounts_large(pgbench_accountsから派生・1行約1KB・-s 50で500万行・約5GB) |
2.2 postgresql.conf(16・17共通)
shared_buffers = 1024MB
autovacuum = off
設定の考え方:COPY計測では対象テーブルを共有バッファに載せてストレージI/Oの影響を排除します。ストリームI/O計測では逆に共有バッファを空にした状態で計測します。
autovacuum = offは計測中の自動VACUUM実行を防ぐためです。計測後は必ずonに戻してください。
2.3 設定の適用手順(16・17両環境で実施)
sudo vi /var/lib/pgsql/data/postgresql.conf
sudo systemctl restart postgresql
# 設定確認
psql -U postgres -d pgbench_test -c "SHOW shared_buffers;"
psql -U postgres -d pgbench_test -c "SHOW autovacuum;"
3. COPY性能向上を実測する
3.1 背景
PostgreSQL 17ではCOPY TO時の内部処理が効率化され、特に行サイズが大きいテーブルのエクスポートで性能が向上しています。
pgbench_accountsのfiller列はcharacter(88)の固定長型で88バイトしか入りません。そのまま使うと行サイズが小さく差が出にくいため、filler相当列を大きくした派生テーブルを作って計測します。
3.2 pgbenchの初期化
過去の計測で作成したテーブルが残っているとディスクを圧迫するため、データベースを一度削除して再作成してから初期化します。
# データベースを削除して再作成(過去の計測テーブルをまとめて削除)
sudo -u postgres psql -c "DROP DATABASE pgbench_test;"
sudo -u postgres psql -c "CREATE DATABASE pgbench_test;"
# 空き容量確認
df -h
# pgbenchを初期化
pgbench -i -s 50 -U postgres pgbench_test
3.3 計測用テーブルの作成(pgbench_accounts_large)
-- pgbench_accounts をベースに filler を約1KBに拡張したテーブルを作成
CREATE UNLOGGED TABLE pgbench_accounts_large AS
SELECT aid, bid, abalance,
repeat(md5(aid::text), 30) AS filler
FROM pgbench_accounts;
-- インデックスも追加しておく
ALTER TABLE pgbench_accounts_large ADD PRIMARY KEY (aid);
UNLOGGEDにすることでWALを排除し、INSERT自体の時間を短縮しています。1行あたり約1KB、-s 50(500万行)なら全体で約5GB(インデックス込みで6GB弱)になります。30GB EBSではOS・元テーブルと合わせて余裕を持って扱えます。作成前にdf -h /var/lib/pgsqlでディスク空き容量を確認してから実行してください。
3.4 共有バッファへのプリウォーム
ストレージI/Oの影響を排除するため、事前にデータを共有バッファに載せます。
CREATE EXTENSION IF NOT EXISTS pg_prewarm;
SELECT pg_prewarm('pgbench_accounts_large');
3.5 計測コマンド
# \COPY TO で全行エクスポート(出力は /dev/null に読み捨て)
time psql -h localhost -U postgres -d pgbench_test > /dev/null <<'EOS'
\copy pgbench_accounts_large TO STDOUT
EOS
計測の注意点:出力先を
/dev/nullにすることでクライアント側のディスクI/Oを排除します。-h localhostでTCP接続を使います。
3.6 結果
| バージョン | エクスポート時間 |
|---|---|
| PG16 | 57.8秒 |
| PG17 | 57.1秒 |
差異は約1%で、誤差範囲内とみなせます。
3.7 考察
ほぼ同等の結果となりました。COPY性能向上は行サイズが大きいほど効果が出やすい改善です。今回のrepeat(md5(aid::text), 30)では1行約660バイトで、差が出るほどの行サイズに達していませんでした。
差を明確に出すには行サイズを数KB〜数十KB規模にする必要があります。ただし「バージョンアップするだけで差が出るか」という観点では、小〜中規模の行サイズでは恩恵が薄く、大きな行を持つテーブルを多用する環境で効果が現れる改善といえます。
3.8 補足計測:行サイズを変えて差を確認する
3.7の考察の通り、行サイズが大きいほどCOPY性能向上の効果が出やすくなります。ここでは行サイズを段階的に変えた独自テーブルで、改善率の変化を確認します。
テーブルの作成(メイン計測:1行約24KB)
DROP TABLE IF EXISTS t_copy_large;
CREATE UNLOGGED TABLE t_copy_large (
id int,
c1 text, c2 text, c3 text, c4 text, c5 text
);
INSERT INTO t_copy_large
SELECT g,
repeat(md5(g::text), 800),
repeat(md5(g::text), 800),
repeat(md5(g::text), 800),
repeat(md5(g::text), 800),
repeat(md5(g::text), 800)
FROM generate_series(1, 100000) g;
1行約24KB×10万行で約2.4GBです。30GB EBSでも余裕を持って扱えます。
共有バッファへのプリウォーム
SELECT pg_prewarm('t_copy_large');
計測コマンド
time psql -h localhost -U postgres -d pgbench_test > /dev/null <<'EOS'
\copy t_copy_large TO STDOUT
EOS
結果
行サイズを変えて計測した結果をまとめます。
| 行サイズ | PG16 | PG17 | 改善率 |
|---|---|---|---|
| 約660B(pgbench_accounts_large) | 57.8秒 | 57.1秒 | 約1% |
| 約6KB(repeat×200) | 6.5秒 | 5.4秒 | 約17% |
| 約24KB(repeat×800) | 26.0秒 | 18.5秒 | 約29% |
| 約48KB(repeat×1600) | 59.4秒 | 43.1秒 | 約27% |
考察
行サイズが大きくなるほど改善率が上がり、約24KB(×800)で約29%に達しました。それ以上(×1600)では改善率がほぼ横ばいになってます。
小さい行サイズ(約660B)では差がほぼ出なかった一方、JSONBや長いテキスト列を多く持つ業務テーブルではバージョンアップするだけで大きな恩恵が得られます。
4. ストリームI/Oを実測する
4.1 背景
PostgreSQL 17では複数ブロックをまとめて読み込むストリームI/Oが導入されました。一度に読み込む最大サイズはio_combine_limit(デフォルト128KB)で指定でき、シーケンシャルスキャンとANALYZEで使用されます。
4.2 計測手順
ストレージI/Oの差を測るため、毎回PostgreSQLを再起動してバッファを空にしてから実行します。3章で作成したpgbench_accounts_largeをそのまま流用します。
# カーネルキャッシュを空にする
sudo sh -c 'sync; echo 3 > /proc/sys/vm/drop_caches'
# PostgreSQL を起動
sudo systemctl start postgresql
# 共有バッファが空の状態でシーケンシャルスキャンを実行
psql -U postgres -d pgbench_test <<'EOS'
\timing on
SELECT count(1) FROM pgbench_accounts_large;
EOS
# 計測後にPostgreSQLを停止(次回計測のために毎回繰り返す)
sudo systemctl stop postgresql
4.3 結果
| バージョン | 1回目 | 2回目 | 3回目 |
|---|---|---|---|
| PG16 | 38.067秒 | 38.054秒 | 38.051秒 |
| PG17 | 38.067秒 | 38.047秒 | 38.081秒 |
3回ともほぼ同一の結果となり、16と17の間に差は見られませんでした。
なお、実行プランは16・17ともに完全に同一です。
EXPLAIN SELECT count(*) FROM pgbench_accounts_large;
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=652065.88..652065.89 rows=1 width=8)
-> Gather (cost=652065.67..652065.88 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=651065.67..651065.68 rows=1 width=8)
-> Parallel Seq Scan on pgbench_accounts_large (cost=0.00..645857.33 rows=2083333 width=0)
(5 rows)
Workers Planned: 2の並列Seq Scanで実行されており、実行計画レベルでの差はありません。
4.4 EBSがボトルネックになっていた
計測中のEBSスループットをAWS CloudWatchで確認したところ、PostgreSQL17では約87MB/sで頭打ちになっていました。
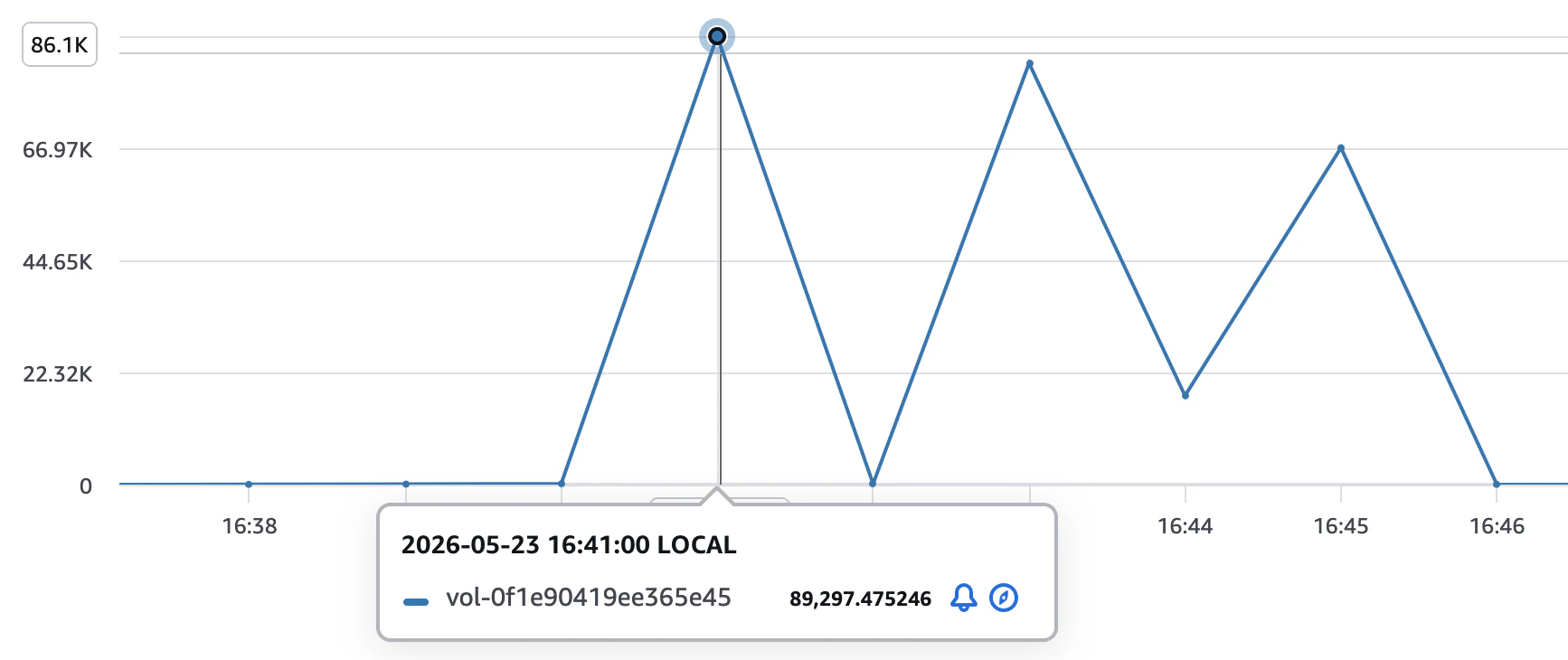
図:PG17計測中のEBSボリューム平均スループット(最大約87MB/s)
t3.microのEBSは通常時のスループットが約40〜90MB/s程度に制限されており、16も17も同じ上限に達していたことが差が出なかった原因です。ストリームI/Oの改善がEBSの限界に隠れてしまっている状態といえます。
4.5 考察
ストリームI/Oの効果はストレージのスループットに余裕がある環境で発揮されます。t3.microのgp3(デフォルト125MB/s)ではEBSがボトルネックになるため、差が現れませんでした。
株式会社SRA OSS PostgreSQL 17 検証レポート
株式会社SRA OSSにて公開されている検証結果ではストレージスループットに余裕があるためストリームI/Oの効果が出ています。今回はgp3のスループット上限(約87MB/s)に張り付いており、まとめ読みにしても「EBSを待つ時間」が支配的で差が出なかったといえます。
5. ON_ERRORオプションを確認する
5.1 背景
PostgreSQL 17ではCOPY FROMにON_ERRORオプションが追加されました。
PostgreSQL 16まではCOPY FROM実行中にデータ型変換エラーが発生すると即座に処理が中断し、それまでに取り込んだ行もすべてロールバックされていました。ON_ERROR ignoreを指定すると、変換エラーの発生した行をスキップして処理を継続できるようになります。
同時にLOG_VERBOSITYオプションも追加されており、スキップした行の詳細をNOTICEで出力できます。
注意:
ON_ERROR ignoreが適用されるのはデータ型変換エラーのみです。主キー重複などの制約違反はスキップされず、エラーで終了します。
5.2 PostgreSQL 16 までの動作
pgbench_accountsのabalance列はinteger型です。ここに文字列を混入させたCSVをCOPY FROMすることで型変換エラーを再現します。
-- 型変換エラーを含むデータを COPY FROM で流し込む
COPY pgbench_accounts(aid, bid, abalance, filler) FROM STDIN WITH (FORMAT csv);
9999991, 1, 100, x
9999992, 1, 200, x
9999993, 1, invalid_balance, x
9999994, 1, 300, x
\.
実行結果(PostgreSQL 16)
psql:test17_copy_error01.sql:7: ERROR: invalid input syntax for type integer: " invalid_balance"
CONTEXT: COPY pgbench_accounts, line 3, column abalance: " invalid_balance"
-- データが1行も入っていないことを確認
SELECT * FROM pgbench_accounts WHERE aid >= 9999991;
-- aid | bid | abalance | filler
-- -----+-----+----------+--------
-- (0 rows)
エラーで中断され、正常な行も取り込まれません。
5.3 ON_ERROR ignoreの動作(PostgreSQL 17)
-- ON_ERROR ignore を指定して同じデータを流し込む
COPY pgbench_accounts(aid, bid, abalance, filler) FROM STDIN WITH (FORMAT csv, ON_ERROR ignore);
9999991, 1, 100, x
9999992, 1, 200, x
9999993, 1, invalid_balance, x
9999994, 1, 300, x
\.
実行結果
psql:test17_copy_error02.sql:7: NOTICE: 1 row was skipped due to data type incompatibility
COPY 3
SELECT * FROM pgbench_accounts WHERE aid >= 9999991;
-- aid | bid | abalance | filler
-- ---------+-----+----------+--------
-- 9999991 | 1 | 100 | x
-- 9999992 | 1 | 200 | x
-- 9999994 | 1 | 300 | x
-- (3 rows)
エラーのあった aid=9999993 行がスキップされ、残り3行が取り込まれました。
5.4 LOG_VERBOSITY verboseでエラー詳細を出力する
-- 前の手順で追加した行を削除してから再実行
DELETE FROM pgbench_accounts WHERE aid >= 9999991;
COPY pgbench_accounts(aid, bid, abalance, filler) FROM STDIN WITH (FORMAT csv, ON_ERROR ignore, LOG_VERBOSITY verbose);
9999991, 1, 100, x
9999992, 1, 200, x
9999993, 1, invalid_balance, x
9999994, 1, 300, x
\.
実行結果
DELETE 3
psql:test17_copy_error03.sql:9: NOTICE: skipping row due to data type incompatibility at line 3 for column "abalance": " invalid_balance"
psql:test17_copy_error03.sql:9: NOTICE: 1 row was skipped due to data type incompatibility
COPY 3
LOG_VERBOSITY verboseを追加すると、スキップした行の行番号・列名・値が出力されます。どの行が除外されたかをその場で確認できるため、データ品質の確認に役立ちます。
5.5 制約違反はスキップされない
pgbench_accountsのaid列は主キーです。既存のaid=1と重複するデータを混入させてCOPY FROMすると、制約違反がON_ERROR ignoreでスキップされないことを確認できます。
-- 前の手順で追加した行を削除してから再実行
DELETE FROM pgbench_accounts WHERE aid >= 9999991;
COPY pgbench_accounts(aid, bid, abalance, filler) FROM STDIN WITH (FORMAT csv, ON_ERROR ignore);
9999991, 1, 100, x
1, 1, 200, x
9999994, 1, 300, x
\.
実行結果
DELETE 3
psql:test17_copy_error04.sql:8: ERROR: duplicate key value violates unique constraint "pgbench_accounts_pkey"
DETAIL: Key (aid)=(1) already exists.
CONTEXT: COPY pgbench_accounts, line 2
制約違反はON_ERROR ignoreの対象外で、エラーで終了します。この点は運用時に注意が必要です。
5.6 考察
ON_ERROR ignoreが役立つのは主に以下のようなケースです。
- 外部システムから取り込むCSVに型不一致が混入する可能性がある場合
- 大量データの初回ロード時に一部の不正行を後回しにしたい場合
ただし、制約違反はスキップされない点と、スキップした行を後から追いかけるにはLOG_VERBOSITY verboseのNOTICEを拾う必要がある点を把握して使うことが重要です。 - 但し、本番環境では大量にログ出力される可能性があるので、このオプションを有効にして実行するには注意が必要です。
6. まとめ
| 項目 | PG16 | PG17 | 改善 |
|---|---|---|---|
| COPY TO(バッファヒット・約660B行) | 57.8秒 | 57.1秒 | 約1%(誤差範囲) |
| COPY TO(バッファヒット・約24KB行) | 26.0秒 | 18.5秒 | 約29% |
| 順スキャン(バッファ未ヒット) | 38.1秒 | 38.1秒 | 差なし(EBSがボトルネック) |
| COPY FROM エラー行スキップ | 非対応(即エラー) | ON_ERROR ignore で対応 | 新機能 |
- COPY性能向上:行サイズが大きいほど効果が出やすく、約24KB行で約29%の改善。小さい行サイズでは差が出にくい
- ストリームI/O:t3.microのEBSがボトルネックとなり差は出なかった。高スループットストレージ環境では改善が期待できる
- ON_ERROR ignore:型変換エラー行をスキップして処理継続が可能に。制約違反はスキップ対象外である点に注意
7. 計測後の後片付け
# autovacuumを必ず戻す
sudo vi /var/lib/pgsql/data/postgresql.conf
# autovacuum = on に変更
sudo systemctl restart postgresql
psql -U postgres -d pgbench_test -c "SHOW autovacuum;"
8. 参考資料
| ページ | URL |
|---|---|
| PostgreSQL 17 リリースノート | https://www.postgresql.org/docs/17/release-17.html |
| COPY コマンドリファレンス | https://www.postgresql.jp/docs/17/sql-copy.html |
| SRA OSS PostgreSQL 17検証レポート | https://www.sraoss.co.jp/tech-blog/pgsql/pg17report/ |
9. さいごに
今回はデータ転送まわりの改善を3本立てで検証しました。COPY性能向上は行サイズが大きいテーブルで効果が出やすく、t3.microでも約24KB行で約29%の改善が確認できました。ストリームI/OはEBSのスループット上限に阻まれ差が出なかったものの、高スループットストレージ環境では効果が期待できます。ON_ERROR ignoreは「型変換エラーはスキップ、制約違反はエラー」という切り分けを押さえておくと、実務での適用場面が見えてきます。
PostgreSQL16から17への改善ポイントで、実際にバージョンアップによる効果が得られる部分との切り分けを実施する事で、バージョンアップするかの判断基準になります。こちらの記事を有効活用してもらえると嬉しいです。