1.前置き
最近、データ分析について学びだしたので、練習としてタイトルのテーマに取り組んでみたいと思います。
全国各所には私鉄や地下鉄、路面電車、モノレールなど様々な鉄道系の移動手段があるわけですが、そのなかで、それぞれの移動手段が採用されている要因として、都市の規模や移動距離の長さがあるんじゃないか?と思っていたわけです。
最近では宇都宮ライトレールの成功例も記事で目にしますが、ここにも何か宇都宮という都市の特徴と路面電車との親和性が隠れているのではないかと考えました。
これを習いたてのデータ分析でどこまで調査できるか試してみたいという思いがモチベーションとなっています。
それでは早速始めていきます。
本当に初心者なので、温かい目でご覧ください、、、。
2.ゴール設定
分析のテーマは上記の通り、日本全国の鉄道系移動手段の路線タイプ分類モデルの作成です。
加えてタイプ分類に影響する要素の分析も実施したいと思います。
行は各駅ごととし、説明変数には「その駅の存在する市区町村の人口」「その駅が含まれる路線の営業キロ」「その駅の運行本数」などを用います。
3.環境について
・Python 3.11.1
・pip 22.3.1
4.データ収集
今回扱うデータは冒頭に説明したゴールを達成するために「全国 鉄道 オープンデータ」あたりでgoogle検索してヒットした下記のデータをもとに進めています。
| ファイル名 | データ種別 | データ説明 | 出典 |
|---|---|---|---|
| station20240426free.csv | 駅データ | 日本全国の駅名のデータ(2024年4月26日更新版)。路線データとも紐づけられる。本分析ではこれが頭になる。 | 駅データ.jp(https://ekidata.jp/ ) |
| line20240426.csv | 路線データ | 路線ごとのタイプを6つ(0:その他、1:新幹線、2:一般、3:地下鉄、4:市電・路面電車、5:モノレール・新交通)に分類しており、これが今回の目的変数となる。(2024年4月26日更新版) | 駅データ.jp(https://ekidata.jp/ ) |
| unkohonsu2024_eki_sjis.csv | 事業者別・駅別発着本数データ2024 | 駅別に発着本数を集計したデータ。各駅について当該駅を通る各路線の発着本数データとその合計データがある。(2024年9月24日更新版) | 全国鉄道運行本数データ公開ページ(https://gtfs-gis.jp/railway_honsu/ ) |
| SSDSE-A-2024.csv | SSDSE-市区町村(SSDSE-A) | 市区町村別、多分野データ(1741市区町村×多分野125項目)。 | 独立行政法人 統計センター SSDSE-市区町村(https://www.nstac.go.jp/use/literacy/SSDSE/ ) |
5.分析・前処理
データの内容確認
各種データの内容を確認していきます。
import pandas as pd
df1 = pd.read_csv('station20240426free.csv', encoding='utf-8')
print(df1.head())
# station_cd station_g_cd station_name station_name_k station_name_r \
#0 1110101 1110101 函館 NaN NaN
#1 1110102 1110102 五稜郭 NaN NaN
#2 1110103 1110103 桔梗 NaN NaN
#3 1110104 1110104 大中山 NaN NaN
#4 1110105 1110105 七飯 NaN NaN
# line_cd pref_cd post address lon lat \
#0 11101 1 040-0063 北海道函館市若松町12-13 140.726413 41.773709
#1 11101 1 041-0813 函館市亀田本町 140.733539 41.803557
#2 11101 1 041-0801 北海道函館市桔梗3丁目41-36 140.722952 41.846457
#3 11101 1 041-1121 亀田郡七飯町大字大中山 140.713580 41.864641
#4 11101 1 041-1111 亀田郡七飯町字本町 140.688556 41.886971
# open_ymd close_ymd e_status e_sort
#0 1902-12-10 0000-00-00 0 1110101
#1 0000-00-00 0000-00-00 0 1110102
#2 1902-12-10 0000-00-00 0 1110103
#3 0000-00-00 0000-00-00 0 1110104
#4 0000-00-00 0000-00-00 0 1110105
df2 = pd.read_csv('line20240426.csv', encoding='utf-8')
print(df2.head())
# line_cd company_cd line_name line_name_k line_name_h line_color_c \
#0 1001 3 中央新幹線 チュウオウシンカンセン 中央新幹線 NaN
#1 1002 3 東海道新幹線 トウカイドウシンカンセン 東海道新幹線 0000FF
#2 1003 4 山陽新幹線 サンヨウシンカンセン 山陽新幹線 0000FF
#3 1004 2 東北新幹線 トウホクシンカンセン 東北新幹線 008000
#4 1005 2 上越新幹線 ジョウエツシンカンセン 上越新幹線 008000
# line_color_t line_type lon lat zoom e_status e_sort
#0 無し 1 137.493896 35.411438 8 1 1001
#1 ブルー 1 137.721489 35.144122 7 0 1002
#2 ブルー 1 133.147896 34.419338 7 0 1003
#3 グリーン 1 140.763192 38.274267 7 0 1004
#4 グリーン 1 139.121488 36.798565 8 0 1005
df3 = pd.read_csv('unkohonsu2024_eki_sjis.csv', encoding='shift-jis')
print(df3.head())
# ID 事業者コード 事業者名 事業者駅番号 駅名 路線数 両方向発着計 両方向着計 両方向発計 方向1発着計 ... \
#2 3 101 JR北海道 3 桔梗 1 90 45 45 48 ...
#3 4 101 JR北海道 4 大中山 1 90 45 45 48 ...
#4 5 101 JR北海道 5 七飯 2 89 44 45 47 ...
#5 6 101 JR北海道 6 新函館北斗 1 74 36 38 33 ...
#6 7 101 JR北海道 7 仁山 1 42 21 21 16 ...
# 路線11路線名 路線11駅順 路線11方向1 路線11方向1着数 路線11方向1発数 路線11方向2 路線11方向2着数 \
#2 NaN NaN NaN NaN NaN NaN NaN
#3 NaN NaN NaN NaN NaN NaN NaN
#4 NaN NaN NaN NaN NaN NaN NaN
#5 NaN NaN NaN NaN NaN NaN NaN
#6 NaN NaN NaN NaN NaN NaN NaN
# 路線11方向2発数 緯度 経度
#2 NaN 41.846350 140.722985
#3 NaN 41.864780 140.713500
#4 NaN 41.887010 140.688560
#5 NaN 41.904843 140.648815
#6 NaN 41.930035 140.635200
#都道府県名のデータセット
df_pref = pd.read_csv('pref.csv', encoding='utf-8')
print(df_pref.head())
# pref_cd pref_name
#0 1 北海道
#1 2 青森県
#2 3 岩手県
#3 4 宮城県
#4 5 秋田県
df4 = pd.read_csv(r'data_population\SSDSE-A-2024.csv', encoding='shift-jis', skiprows=2)
print(df4.head())
# 地域コード 都道府県 市区町村 総人口 総人口(男) 総人口(女) 日本人人口 日本人人口(男) 日本人人口(女) \
#0 R01100 北海道 札幌市 1973395 918682 1054713 1933094 897727 1035367
#1 R01202 北海道 函館市 251084 113965 137119 248208 112718 135490
#2 R01203 北海道 小樽市 111299 50136 61163 109971 49441 60530
#3 R01204 北海道 旭川市 329306 152108 177198 325287 150318 174969
#4 R01205 北海道 室蘭市 82383 40390 41993 81658 39960 41698
# 15歳未満人口 ... 小売店数 飲食店数 大型小売店数 一般病院数 一般診療所数 歯科診療所数 医師数 歯科医師数 \
#0 215366 ... 10370 7354 348 177 1413 1206 6978 2142
#1 23560 ... 2163 1256 41 26 206 122 822 182
#2 9169 ... 1097 616 17 11 79 78 338 105
#3 34691 ... 2409 1503 67 33 227 170 1364 246
#4 7769 ... 621 447 13 6 52 39 249 56
# 薬剤師数 保育所等数(基本票)
#0 5758 368
#1 683 54
#2 334 23
#3 876 72
#4 193 12
データのマージ
各種データをマージして分析を行うためのデータセットを用意します。
#データのマージ
df1 = df1.drop_duplicates(subset='station_name', keep=False)
df_all = pd.merge(df1, df2, left_on='line_cd', right_on='line_cd', how='left')
df3 = df3.drop_duplicates(subset='駅名', keep=False)
df_all = pd.merge(df_all, df3, left_on='station_name', right_on='駅名', how='left')
df_all = pd.merge(df_all, df_pref, on='pref_cd', how='left')
さらに、市区町村名をキー列として市区町村別他分野データをマージしていきます。
住所文字列から正規表現によって市区町村の抽出を行う方法については下記の記事を参考にさせていただきました。
import re
# 市区町村の情報を抽出する関数
def extract_municipality(address):
munici = re.sub(r'...??[都道府県]', '', address) if re.match(r'...??[都道府県]', address) else address
gun = re.sub(r'.+?郡', '', munici) if re.match(r'.+?郡', munici) else munici
match = re.search(r'\
(?:旭川|伊達|石狩|盛岡|奥州|田村|南相馬|那須塩原|東村山|武蔵村山|羽村|十日町|上越|富山|野々市|大町|蒲郡|\
四日市|姫路|大和郡山|廿日市|下松|岩国|田川|大村)市|.+?郡.+?[町村]|.+?[市区町村]', gun)
return match.group(0) if match else None
# df4, df_allのそれぞれでキー列となる 'pref-municipality' 列を作成
df4['pref-municipality'] = df4['都道府県'] + df4['市区町村']
df_all['municipality'] = df_all['address'].apply(extract_municipality)
df_all['pref-municipality'] = df_all['pref_name'] + df_all['municipality']
#'pref-municipality'をキー列としてdf4とdf_allをマージ
df_all = pd.merge(df_all, df4, on='pref-municipality', how='left')
これでひとまず使いたいデータを一つのデータセットにマージする作業が完了しました。
(いくらかはうまく市区町村の取得ができずにちゃんとマージがなされていない行がありましたが、全体の2%程度でしたのでご勘弁を、、、)
用意したデータセットの大まかな傾向をつかむために、データセットの中から路線タイプに関係がありそうな項目として駅の両方向発着数、駅が存在する市区町村の総人口・可住地面積・従業者数(民営)・経常収支比率(市町村財政)、そして路線タイプを選択します。
df_focus = df_all[['両方向発着計','総人口','可住地面積','従業者数(民営)','経常収支比率(市町村財政)', 'line_type']]
上記の着目する項目のそれぞれの関係性を可視化させるため、試しにseabornのペアプロット図を作成してみました。(文字が小さくてすみません、、!)
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
#グラフの表示
sns.pairplot(df_focus, hue='line_type', plot_kws={'alpha':0.5}, size=5, palette='Set1')
plt.show()
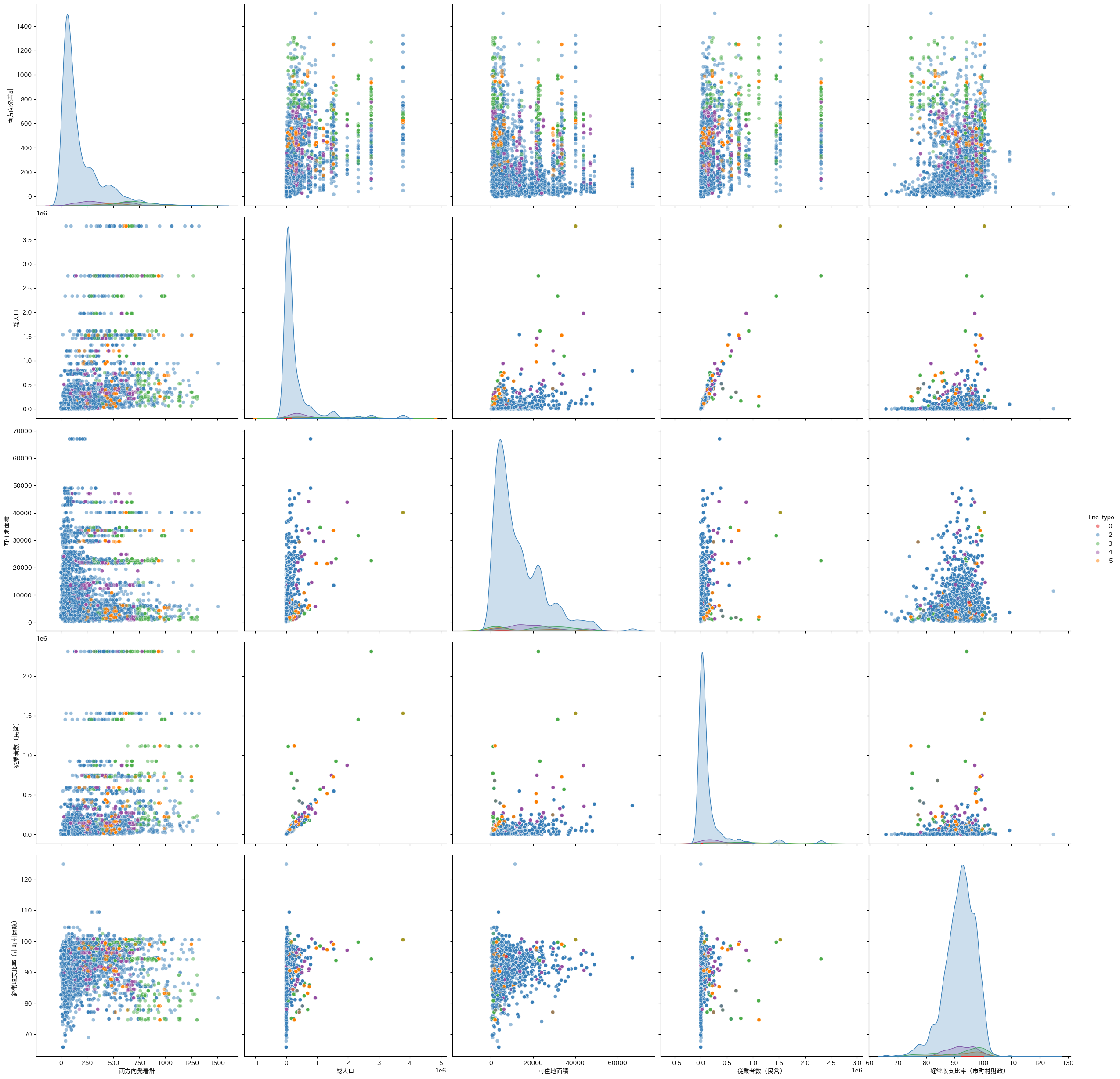
まるっきりきれいに分離されているわけではないですが、
・地下鉄(3)は発着本数が多く、一般鉄道(2)は本数が少ない側に集中。路面電車(4)やモノレール(5)はその中間。
・地下鉄(3)従業者数が多い地域に採用されやすい。
といった特徴がありそうです。
欠損処理、データ不均衡の調整
上記の傾向予想を踏まえつつ、説明変数としては両方向発着計と各種市区町村データのうち数値データである項目を適用します。
#市区町村データのうち数値データ列のみ抽出
df4_int = df4.select_dtypes(include=['int64','float64'])
#説明変数:両方向発着計+各種市区町村データ(数値)、目的変数:路線種別 としてデータセット用意
df_focus2 = df_all[df4_int.columns.tolist()+['両方向発着計','line_type']]
欠損値の処理を行います。本データにおける欠損は、もともとな入力がなかったり、マージする際にうまくはまらずに欠損値となったものが主であり、欠損のメカニズムとしてはMCARであると考えますので、シンプルにリストワイズ削除にて対応します。
#欠損行を削除
df_focus2 = df_focus2.dropna()
モデル構築のため、先んじてテストデータと訓練データに分割したのちに、データ不均衡を確認します。
#説明変数、目的変数の選択
y2 = df_focus2['line_type']
X2 = df_focus2[df_focus2.columns[df_focus2.columns != 'line_type']]
#テストデータと訓練データに分割
from sklearn.model_selection import train_test_split
X_train2, X_test2, y_train2, y_test2 = train_test_split(X2, y2, test_size = 0.3, random_state = 71, stratify=y2)
y_train2.value_counts()
#2 4145
#4 247
#3 222
#5 112
#0 3
#Name: line_type, dtype: int64
路線タイプ0(その他)が非常に小さい値となっています。その他のデータは除外してモデル構築でもよいかと思いましたが、いったんそのまま残しておきます。
また、路線タイプ2(一般鉄道)とそれ以外3(地下鉄)、4(市電・路面電車)、5(モノレール・新交通)でもデータの偏りがあるため、対策を行います。
今回はSMOTE-ENNにて調整を行いました。
#SMOTE-ENN法を使った不均衡データの調整
import numpy as np
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import EditedNearestNeighbours
from imblearn.combine import SMOTEENN
np.random.seed(0)
sm_enn = SMOTEENN(smote=SMOTE(k_neighbors=2), enn=EditedNearestNeighbours(n_neighbors=3))
X_train_resampled2, y_train_resampled2 = sm_enn.fit_resample(X_train2, y_train2)
y_train_resampled2.value_counts()
#0 4145
#2 3784
#4 3737
#3 3386
#5 3058
#Name: line_type, dtype: int64
6.モデル構築・評価
いよいよモデルを構築します。
今回はランダムフォレストによる手法を選択しました。
#ランダムフォレストによる学習と分類予測
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
# モデルの構築
model = RandomForestClassifier()
# モデルの学習
model.fit(X_train_resampled2, y_train_resampled2)
# テストデータの予測
y_pred2 = model.predict(X_test2)
# 正解率の算出
print(accuracy_score(y_test2, y_pred2))
#0.9383629191321499
正解率は0.94。思いのほか高く出ました。
さらにここからパラメータの変更や改良など試してみたいところですが、いったんこのまま考察に進めます。
7.分析結果考察
ランダムフォレストのfeature importanceを使って、各特徴量の重要度から今回の分析の考察をしていきます。
import matplotlib.pyplot as plt
labels = X_train_resampled2.columns
importances = model.feature_importances_
plt.figure(figsize = (10,25))
plt.barh(y = range(len(importances)), width = importances)
plt.yticks(ticks = range(len(labels)), labels = labels)
plt.show()
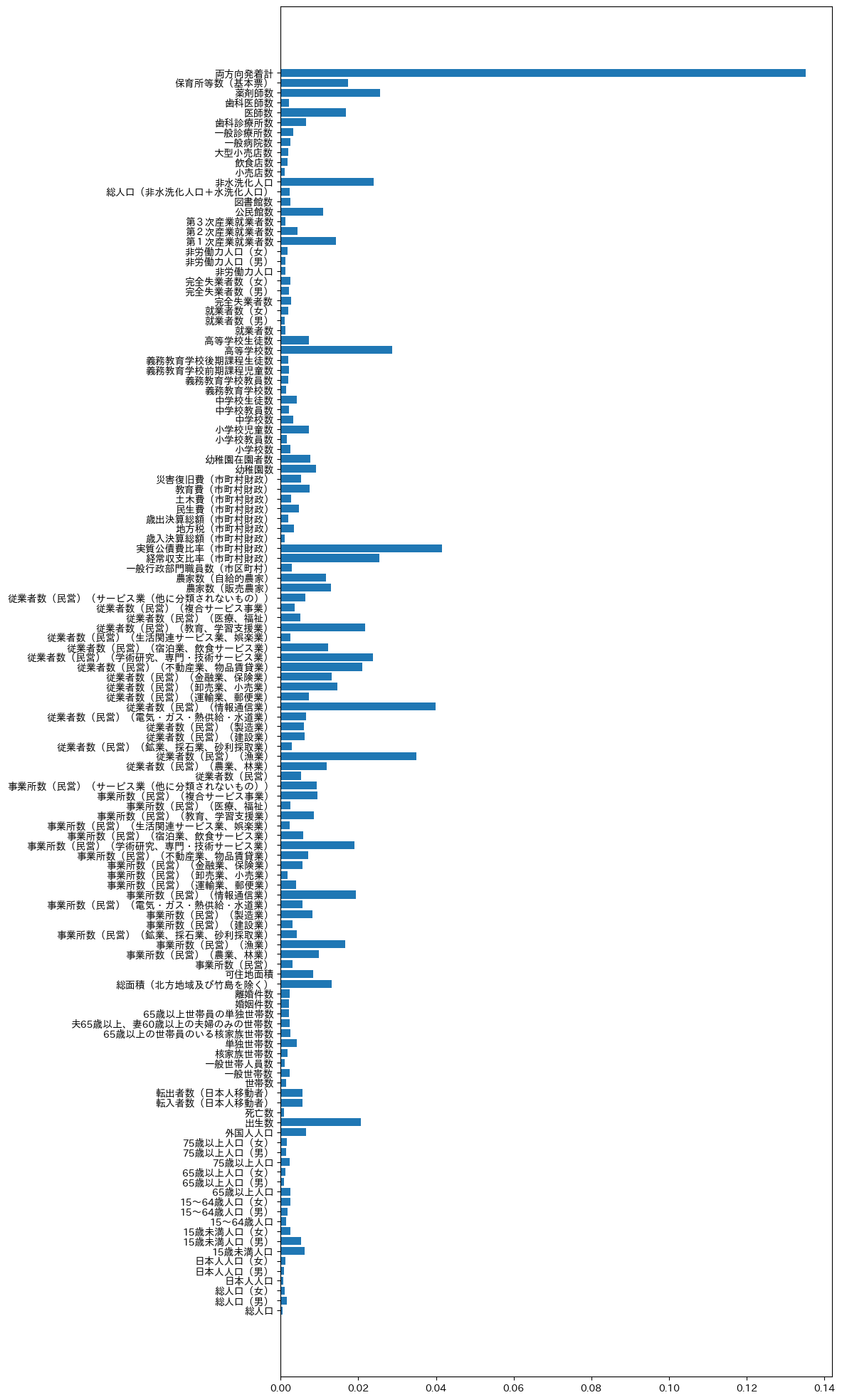
モデル構築前のペアプロット図でも触れたように発着本数の路線タイプへの影響度は特に大きそうです。
それ以外で影響度が大きそうな項目としては、以下が特徴的です。
・高等学校数
・実質公債費比率(市町村財政)
・従業者数(民営)(情報通信業)
・従業者数(民営)(漁業)
・出生数
上記の影響度の大きいものについて再びペアプロット図で可視化してみます。
#グラフの表示
matplotlib.rcParams['font.size'] = 18
sns.pairplot(df_focus2_forplot, hue='line_type', plot_kws={'alpha':1}, size=5, palette='Set1', )
plt.show()
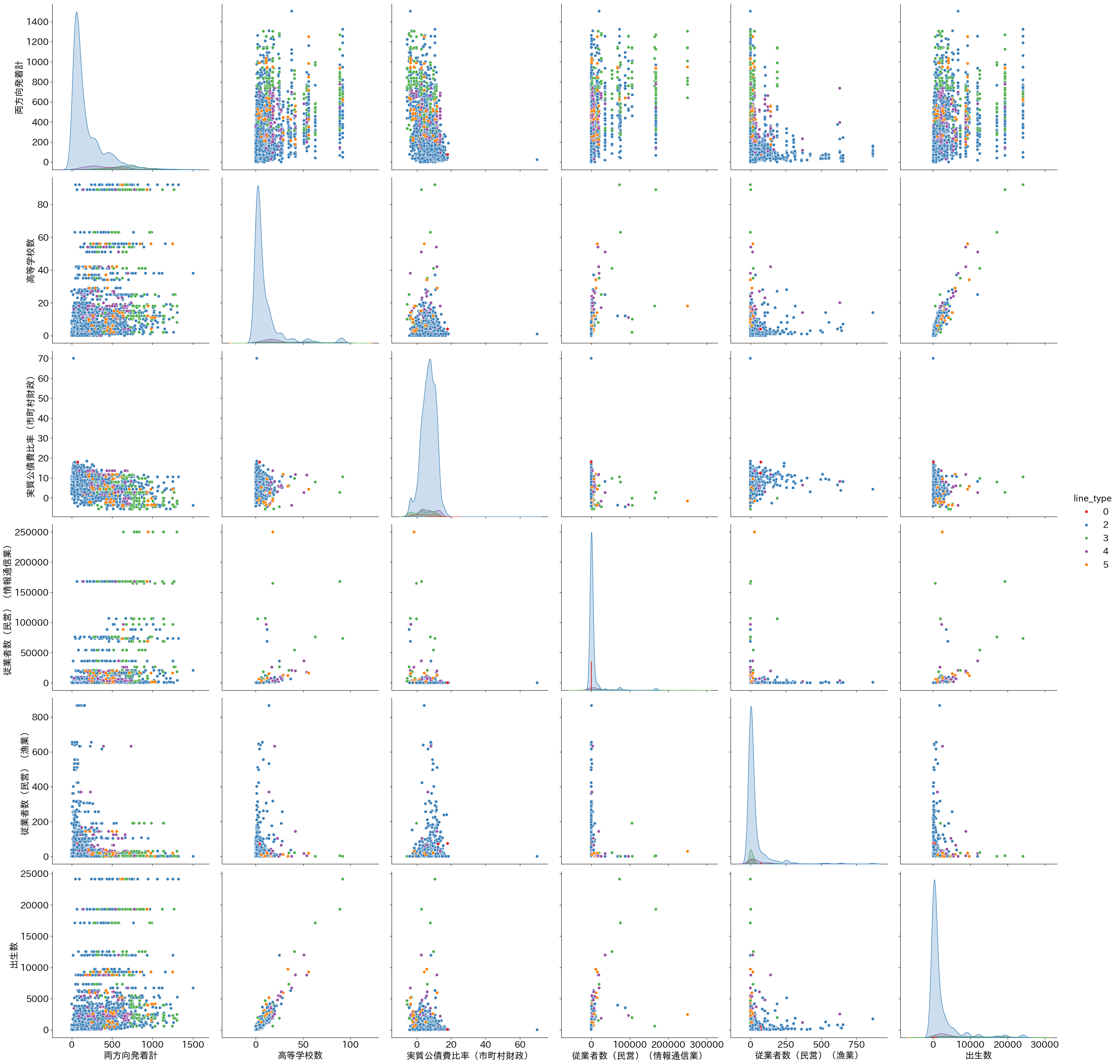
出生数や高等学校数の数が多い地域のほうが地下鉄の採用が多く、少ない地域では一般鉄道が走ることが多い傾向が見られます。若い層の通学経路として地下鉄や路面電車が使われることが多いものと予想します。
対照的で興味深いのは「従業者数(民営)(情報通信業)」と「従業者数(民営)(漁業)」で情報通信業などは都市部に多く、通勤にも地下鉄などの利用客が多い一方で、漁業従事者は普段の生活や通勤には鉄道は使わず、長距離移動時などでJRのような一般鉄道を利用する場面が多いことが反映されていると考えます。
また、ペアプロット図を見ると、地域差の比較的少ない項目(従業者数(民営)(運輸業・郵便業)、従業者数(民営)(電気・ガス・熱供給・水道業)など)は路線タイプへの影響度も小さいことがわかります。
高等学校数の影響度に比べて小学校数、中学校数の影響度が小さいのも、高校に比べて義務教育である小学校・中学校のほうが数の地域差が小さいことが影響していると予想します。
8.まとめ
ここまで読んでいただきありがとうございました。
今回は分析までとしましたが、これをもとに開発予定地へ新たな交通機関を設ける場合にどの路線タイプが適しているかを予想するところまでできると面白いなと思っています。
その点では、本モデルに路線ごとの走行距離や、路線の経営状況のデータなども含めると、新しく鉄道系交通手段を敷設する際の推奨のタイプを予測してくれるようになるのではと思います。
今後も楽しみながら勉強していきたいと思います!