株式会社ブレインパッドでMLエンジニアをしている松平と申します。
複数人のチームでML開発をする機会が最近あり、チーム内でのデータ・実験・モデルの管理方針やモデルのデプロイフローなど色々検討する機会に恵まれました。
今回は特に実験管理の部分にフォーカスしてご共有させていただきます。実験結果の共有や再現性という観点を重視した設計になっています。
チームでのML開発をいい感じに管理していきたい方々の参考になれば望外の喜びです。
1. はじめに
複数人で並行してML開発を実施する場合、開発者間で共通した管理方針を設計しないと以下のようなことが起こると想定されます。
- 実験結果の記録方法がバラバラ
- 結果共有やレビューのコストが高い
- 実験の再現ができない
これらを無理なく解決できる管理方法を用意したいところです。
そこで本記事では、チームでのML開発の管理構成の一案として、MLflow × DVC を組み合わせた構成を紹介します。MLflowは実験結果を管理するツールで、DVCはデータのバージョンを管理するツールです。
※ 本記事では実験管理や再現性にフォーカスしており、モデル管理やデプロイフローについては触れていません。ご了承ください。
2. 今回目指した状態
- 開発者間で 実験やデータの管理を統一 する
- 各開発者の 実験結果を簡単に確認 できる
- 他の人の 実験を再現 できる
3. 全体像:今回構築したもの
今回のポイントです。
- 各開発者はMLflowに実験結果を記録する
- MLflowが提供するUI上でみんなが実験結果を簡単に確認できる
- データをDVCで管理する
- 実験データのバージョンIDをMLflowに記録する
- DVCを使い、MLflowに記録されたデータのバージョンIDから実験データを再現する
MLflow(実験集約)× DVC(データバージョン管理)の全体像
全体像を図示します。

全体像の図に沿って先のポイントをもう少し具体的に書くと、以下になります。
- 開発者全員が以下のような情報をMLflowのトラッキングサーバ経由で記録する。
- params: ハイパラ → DBに保存
- metrics: 評価指標 → DBに保存
- tags: タグ → DBに保存
- artifacts: 図、設定ファイル、モデルなどのファイル類 → ストレージに保存
- トラッキングサーバが提供するWebUIでみんなが実験結果を簡単に確認できる。
- 学習に使うデータ実体は DVC remote(共有ストレージ)に置き、Gitでポインタファイル(.dvc)管理する。
- DVCはGitを利用したデータ管理ツールです。DVC管理下にデータを置くと、DVCはポインタファイル(.dvc)を生成します。
- 開発者はMLflowのtagsに利用データのバージョンIDを記録する。バージョンIDはGit tagや commitIDで表す。
- 他開発者はMLflowのRunsからデータのバージョンIDを確認し、dvc pullを行うことで実験データを取得できる
以降の章で、図のMLflow側とDVC側をそれぞれもう少し解説していきます。
4. MLflow:実験結果を集約
この構成における MLflow の役割は一言でいうと、「実験結果をチームの共通フォーマットで集約し、UIから結果を確認できる状態を作ること」です。
4.1 今回のMLflowの構成
全体像図で示したように、今回のMLflowの構成要素は以下の三つです。
- トラッキングサーバ(UI + API)
- メタデータDB(params/metrics/tagsを保存)
- ストレージ(artifactsを保存)
開発者が実験結果を記録するときは、トラッキングサーバのURLに向かって結果を送ります。 トラッキングサーバは裏側で、メタデータはDBへ、ファイルはストレージへ保存します。
トラッキングサーバは実験結果を確認できるUIも提供します。UIについては次節で見ていきます。
これら三つのサービス要素は同じリソース上に構築しても良いし、分離しても良いです。ユースケースやプロジェクト状況に合わせてインフラ構成を選択する必要があるかと思います。
MLflowの公式サイトにも以下の図で説明されています。
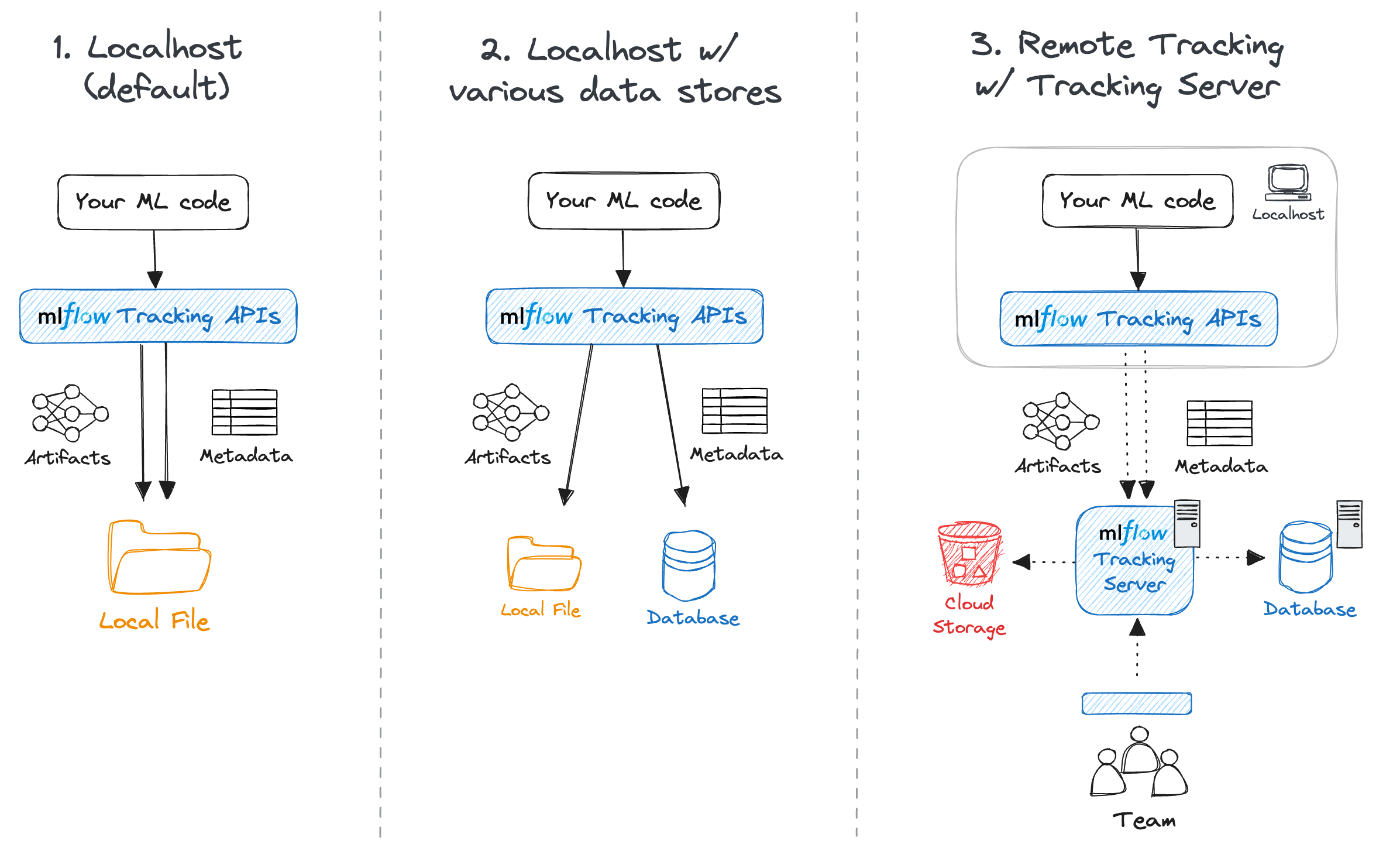
4.2 実験結果を確認できるUI
MLflowの優れているところは実験結果を確認するための良いUIを持っていることです。DBやストレージに保存された実験結果を開発者やレビュアーがUIから自由に見ることができます。
UIから実験結果を確認するイメージをつけていただくために、以下の画面スクショで説明していきます。
Experiments
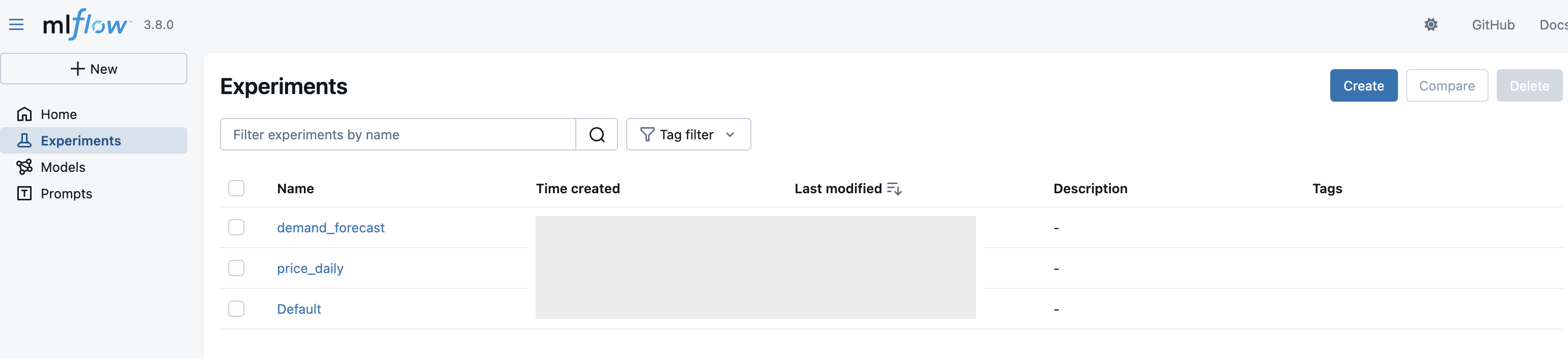
Experimentsは実験の意味的まとまりの単位になります。タスクや目的単位で作ることが多いかもしれないです。
※ (一応説明すると)MLflowの構成要素は以下のようになります。
Experiments └── Runs ├── params ├── metrics ├── artifacts └── tags
Runs
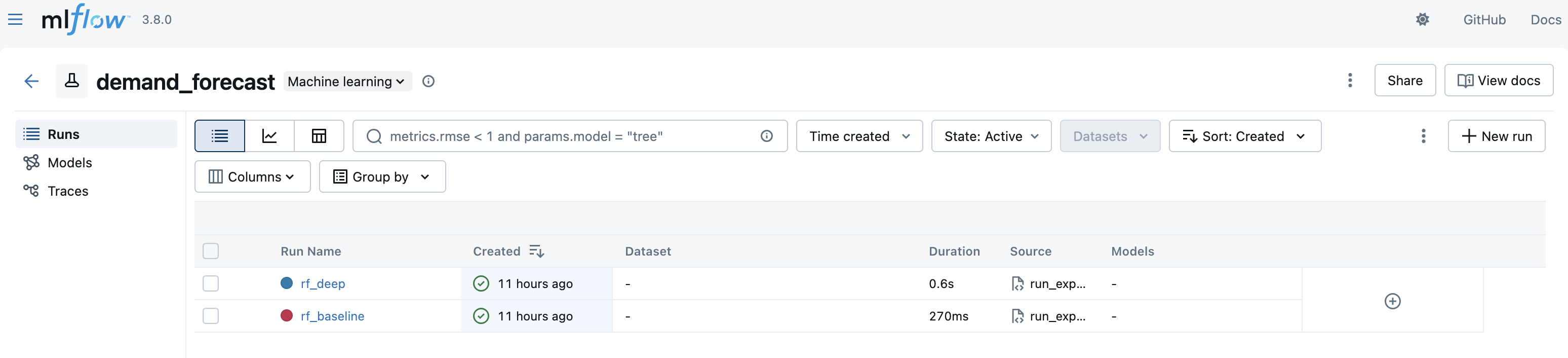
Experiment下にはRunsがぶら下がっています。このRunsの一つ一つが実験になります。モデル、特徴量、ハイパラの条件を変えて学習するとRunsのレコードが増えていくイメージです。
Runsの中身
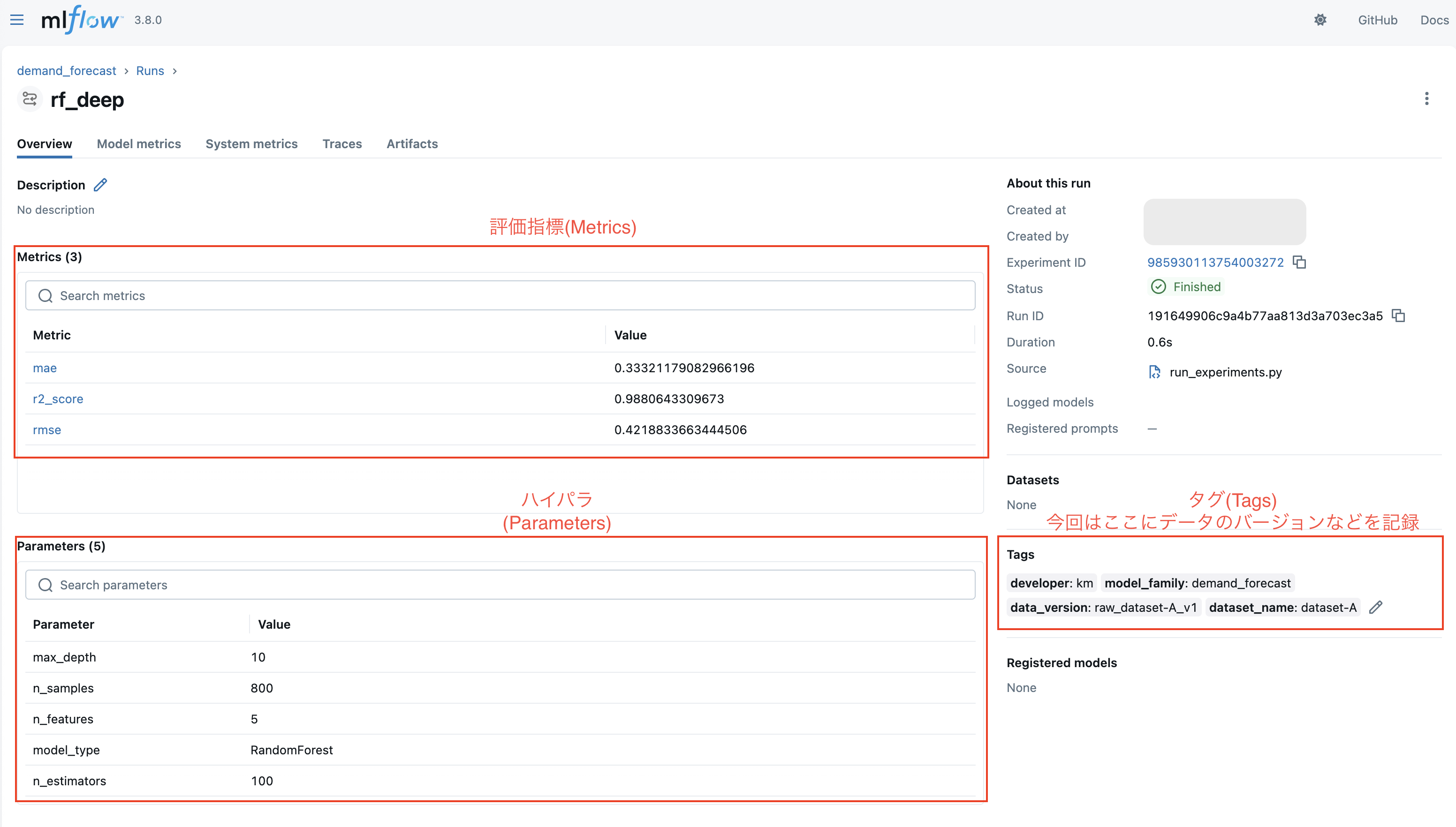
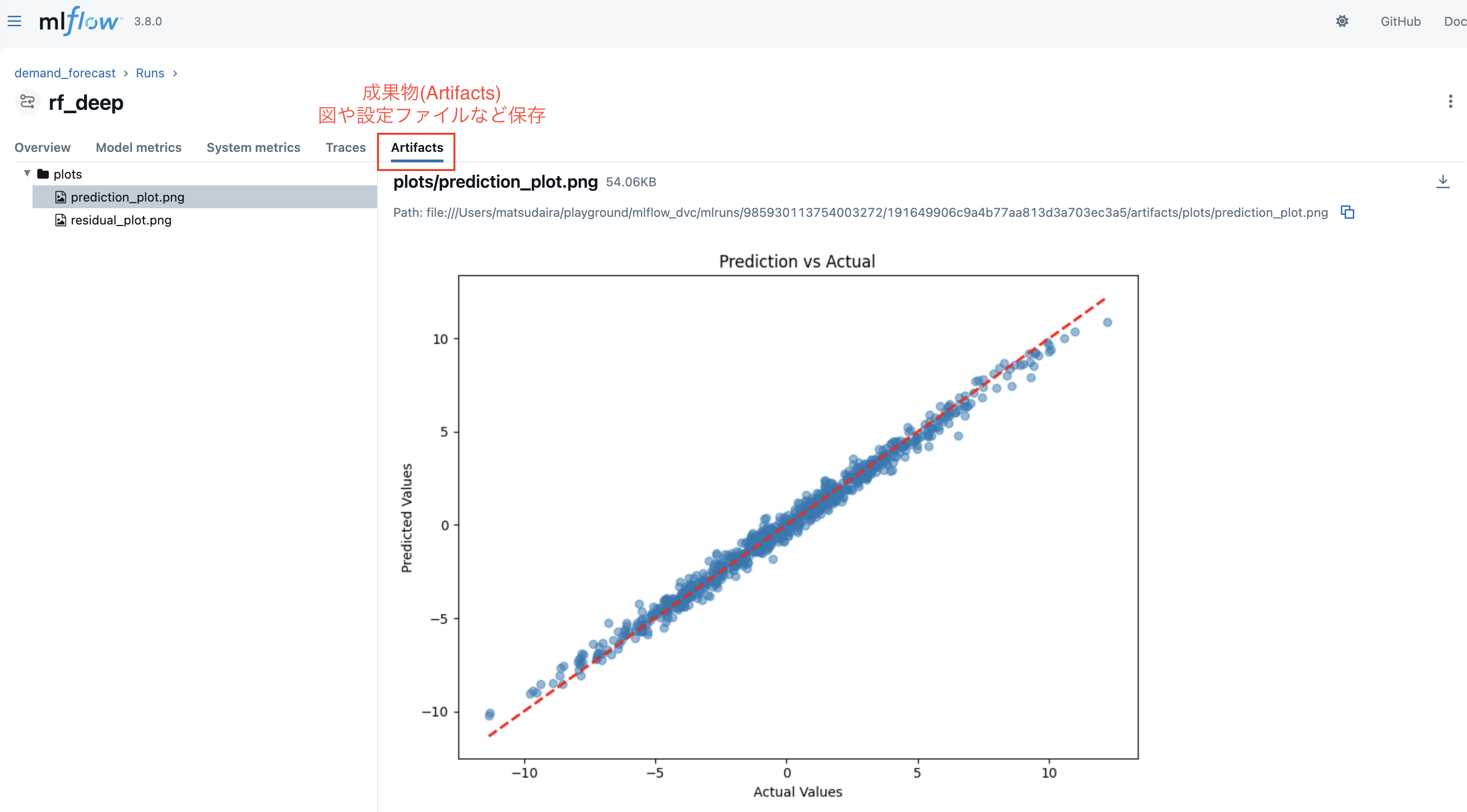
Runsの中にはハイパラ(params)/ 評価指標(metrics)/ タグ(Tags) / 図などの成果物(artifacts)などが記録されています。
5. 実験再現のためのデータ共有に向けて
ここまでで、
- 開発者全員がトラッキングサーバに向けて記録することで一つの場所に実験結果を集約できること
- MLflowが提供するUI上でチーム全員が実験結果を確認できること
を理解できたかと思います。
今回の管理設計を考える上で、再現性という点を一つキーワードとして置いていました。再現するにはハイパラやデータ等が特定できていないといけません。
ハイパラは大丈夫ですが、実験に使ったデータの実体ファイルをartifactsに入れるのは流石に重くなります。
なので、データのIDみたいものを開発者間で共有し、そのIDから同じデータを取得できるような仕組みが必要になるかと思います。
そこで登場するのがDVCです。
6. DVC:データのバージョン管理
この構成における DVC の役割は、データ本体をGitに入れずに、チームで同じデータのバージョンを共有・復元できるようにすることです。
6.1 ざっくり仕組み(ポインタと実体の分離)
DVCはGitを利用したデータ管理のツールです。
DVC管理下にデータを置くと、DVCはポインタファイル(.dvc)を生成します。そのポインタファイルをGit管理下に置くことでデータのバージョンが管理できます。
- Gitが管理する:
.dvc(ポインタファイル) - DVCが管理する:データ本体(実体)
この仕組みにより、リポジトリのサイズを増やしすぎずに、あるバージョンのデータを再現することができます。
6.2 DVCはデータ版のGitのようなもの
DVCはデータ版のGitのようなもので、ローカルとリモートの関係性・操作フローがGitと非常によく似ています。DVCにおけるローカル環境とリモートの関係を図示しておきます。

データの新規追加、データ更新、データ取得の操作を見るとgitと似ていることがわかるかと思います。
新しいデータを追加するとき(例:data/raw//)
# データを置く
# data/dataset_A/...
# dvc add を実行すると dataset_A.dvc が生成される
dvc add data/dataset_A
git add data/dataset_A.dvc data/.gitignore
git commit -m "Track dataset_A with DVC"
dvc push
データを更新したとき
# data/dataset_A/ の中身を更新した後
dvc status
dvc commit data/dataset_A.dvc
git add data/dataset_A.dvc
git commit -m "Update dataset dataset_A: add Nov 2025 data"
dvc push
他メンバが同じデータ版を取得するとき
git checkout <commitID>
dvc pull
6.3 データのバージョンをどう表現するか
本記事の構成では、MLflowのRunsに利用データのバージョンIDを記録します。
そのバージョンIDの表現は色々ありますが、今回は以下の運用方針としました。
-
Git tag(例:
dataset-A_v1)をデータ更新コミットに付ける - MLflowのRunsのTagsに
data_version=dataset-A_v1を記録する
こうしておくと、開発者はMLflowのRuns → Tags(バージョンID)→ Git checkout + dvc pull の順でデータを再現できます。
まとめ
本記事では、チームでのML開発を進めるうえで起きがちな
- 実験結果の記録方法がバラバラ
- 結果共有やレビューのコストが高い
- 実験の再現ができない
という問題に対して、MLflow(実験集約) × DVC(データのバージョン管理) という構成案を紹介しました。
- 実験結果はMLflow、データ実体はDVCで管理することで、チーム内で保存先と形式が揃う
- MLflowのWebUIで確認・レビューの入口が一本化される
- 実験データのバージョンIDの情報がMLflowに残るため、同じデータをDVCで取得して実験再現をしやすい
この構成で当初目指した状態には一応なったかなと思います。
が、運用面で実際まだまだ課題はあると考えています。実際にML開発で試行錯誤を繰り返していると学習に使うデータのバリエーションは結構な数になりますが、それをいちいちバージョンで分けたりするのはまあまあな手間ですし、同じデータの違うバージョンとするのか、そもそも違うデータとするのかなど考え始めると色々あります。
今後も保守性や信頼性の高い管理方針・設計を考え、日々実践していきたいと考えています。ML開発のいい感じの管理方針があればぜひご共有いただけると幸いです。
それではまた今度!