大規模なデータをラスタライズし、可視化・要約を行うHolovizのDatashaderで地図描写試してみたという話。
この記事の要約
- datashaderでは、ver0.16からgeopandasを読みこむことが出来る
- 画面のピクセルサイズを先に決めてしまい、データをピクセルに対応付け・集計する
- plotlyで利用する時は、画像が対応する緯度経度を取り出してmapboxレイヤー作る
これは何するの?
下のようなことができます。
- 公式トップページ
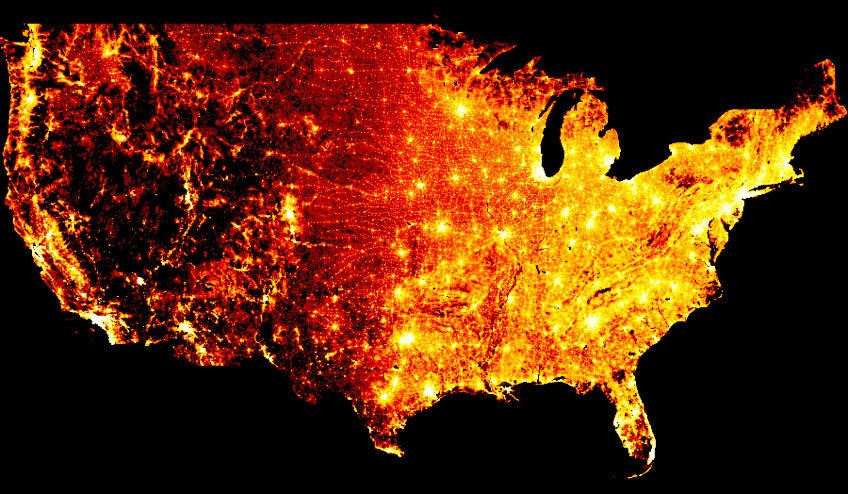
With code just like the above, you can plot 300 million points of data (one per person in the USA) from the 2010 census without any parameter tuning:
(訳)上記のようなコードを使用するとパラメーターを調整せずに、2010年の国勢調査から3億ポイントのデータ(米国の一人ひとり) をプロットできます。
https://datashader.org/#
This dataset contains over 40 million rows of data, each row including several cell tower features in addition to the latitude/longitude location of the tower. To handle this fairly large dataset, this app makes use of Dask for parallel processing, and Datashader for server side rendering.
(訳)このデータセットには4000万行を超えるデータが含まれており、各行には基地局の緯度/経度の位置に加えて、いくつかの付随する情報が含まれています。このかなり大きなデータセットを処理するために、このアプリは並列処理にDaskを使用し、サーバー側のレンダリングにDatashaderを使用します。
https://github.com/plotly/dash-world-cell-towers
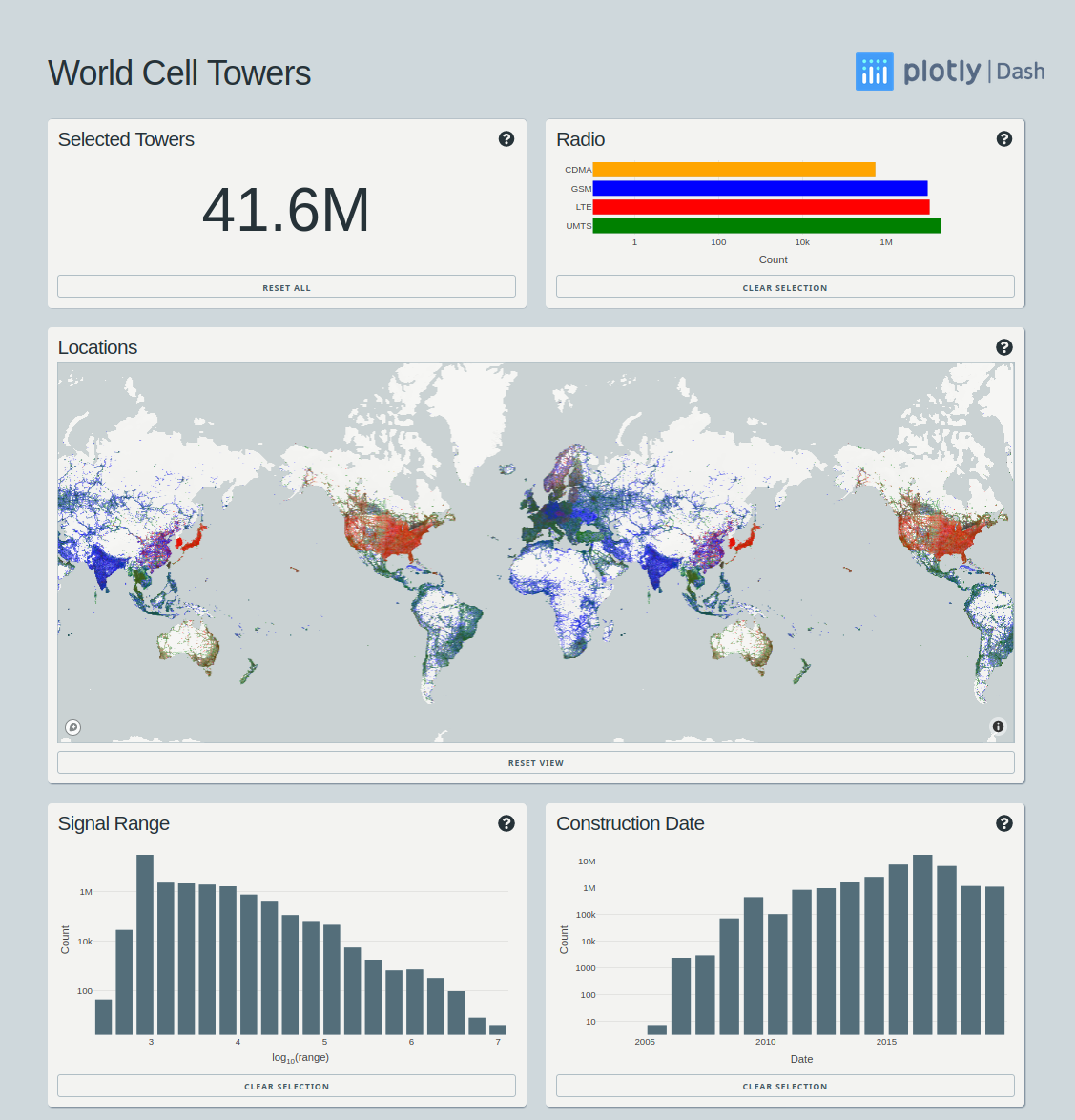
やっていることとしては、画面のピクセルサイズを先に決めてしまい、データをピクセルに対応付け・集計を行っているみたいです。
集約関数は複数用意されており、目的に応じて利用できます。
↓この辺に書いてあります。
Plotlyのmapbox系プロットでとりあえず使ってみる
公式の説明の通り。
Plotly and Datashader in PythonMapbox Map Layers in Python
How to use datashader to rasterize large datasets, and visualize the generated raster data with plotly.
https://plotly.com/python/datashader/
datashaderでは、ver0.16からgeopandasを読みこむことが出来る。
そのver0.16がpython 3.8などまだ割と使われているバージョンに対応していないことに留意。
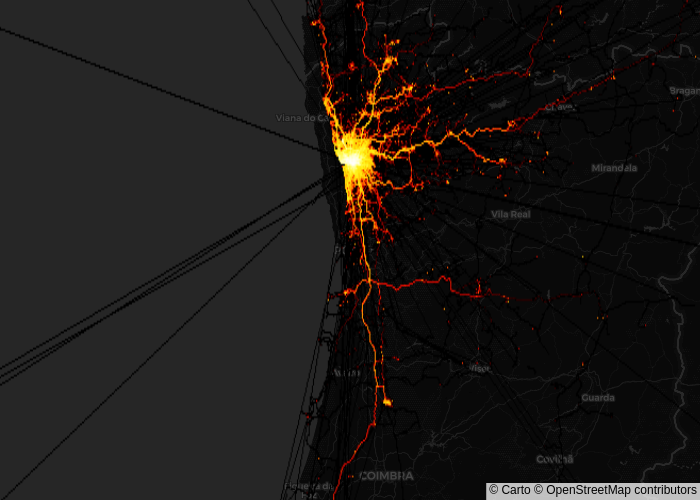
kaggle Taxi Trajectory Dataを可視化してみる
このデータは、ポルトガルを走るタクシーの軌跡データで、約170万!!の移動軌跡が収録されています。
描写対象として、軌跡の長さが、2より大きい166万行、点の数に直すと、8341万点に対して描写しています。
前処理で死にそうなほどメモリ食ってますが、datashaderの処理自体は割とサクサク動きます。
描写してしまえば、画像なので言わずもがなです。
前処理
import polars as pl
import geopandas as gpd
import shapely
import datashader as ds
from colorcet import fire
import plotly.express as px
from IPython.display import Image
df = pl.read_csv(
'TaxiTrajectoryData.csv',
schema=dict(
TRIP_ID=pl.Int64,
CALL_TYPE=pl.Utf8,
ORIGIN_CALL=pl.Utf8,
ORIGIN_STAND=pl.Int16,
TAXI_ID=pl.Int32,
TIMESTAMP=pl.Int64,
DAY_TYPE=pl.Utf8,
MISSING_DATA=pl.Boolean,
POLYLINE=pl.Utf8
)
)
df
| TRIP_ID | CALL_TYPE | ORIGIN_CALL | ORIGIN_STAND | TAXI_ID | TIMESTAMP | DAY_TYPE | MISSING_DATA | POLYLINE |
|---|---|---|---|---|---|---|---|---|
| i64 | str | str | i16 | i32 | i64 | str | bool | str |
| 1372636858620000589 | "C" | "" | null | 20000589 | 1372636858 | "A" | false | "[[-8.618643,41.141412],[-8.618… |
| 1372637303620000596 | "B" | "" | 7 | 20000596 | 1372637303 | "A" | false | "[[-8.639847,41.159826],[-8.640… |
| 1372636951620000320 | "C" | "" | null | 20000320 | 1372636951 | "A" | false | "[[-8.612964,41.140359],[-8.613… |
| 1372636854620000520 | "C" | "" | null | 20000520 | 1372636854 | "A" | false | "[[-8.574678,41.151951],[-8.574… |
| 1372637091620000337 | "C" | "" | null | 20000337 | 1372637091 | "A" | false | "[[-8.645994,41.18049],[-8.6459… |
| … | … | … | … | … | … | … | … | … |
| 1404171463620000698 | "C" | "" | null | 20000698 | 1404171463 | "A" | false | "[[-8.612469,41.14602],[-8.6124… |
| 1404171367620000670 | "C" | "" | null | 20000670 | 1404171367 | "A" | false | "[[-8.610138,41.140845],[-8.610… |
| 1388745716620000264 | "C" | "" | null | 20000264 | 1388745716 | "A" | false | "[]" |
| 1404141826620000248 | "B" | "" | 12 | 20000248 | 1404141826 | "A" | false | "[[-8.630712,41.154885],[-8.630… |
| 1404157147620000079 | "B" | "" | 34 | 20000079 | 1404157147 | "A" | false | "[[-8.615538,41.140629],[-8.615… |
# 死ぬほどメモリ喰うので注意
# ポイント=行として変換する例
#ddf = df\
# .drop(['ORIGIN_STAND','DAY_TYPE'])\
# .with_columns(
# (pl.col('TIMESTAMP') * 10 ** 6).cast(pl.Datetime),
# pl.col('POLYLINE').str.json_decode()
# )\
# .with_columns(
# pl.int_ranges(0,pl.col('POLYLINE').list.len()).alias('SEC')
# )\
# .explode(['POLYLINE','SEC'])\
# .with_columns(
# pl.col('TIMESTAMP')+pl.duration(seconds=(pl.col('SEC') * 15))
# )
# ラインストリングにとして扱うための下準備
ddf = df\
.drop(['ORIGIN_STAND','DAY_TYPE','MISSING_DATA'])\
.with_columns(
(pl.col('TIMESTAMP') * 10 ** 6).cast(pl.Datetime),
pl.col('POLYLINE').str.json_decode()
)\
.filter(pl.col('POLYLINE').list.len() > 2)
%%time
# 死ぬほどメモリ喰うので注意
t=ddf.to_pandas()
t['POLYLINE'] = t['POLYLINE'].apply(lambda x: shapely.LineString(x))
gdf = gpd.GeoDataFrame(t,geometry='POLYLINE')
# ポイントとして整形する例
# a=ddf.to_pandas()
# gdf = gpd.GeoDataFrame(
# a,
# geometry=gpd.points_from_xy(
# a['POLYLINE'].apply(lambda x: x[0]),
# a['POLYLINE'].apply(lambda x: x[1])
# )
# )
CPU times: user 2min 42s, sys: 8.94 s, total: 2min 51s
Wall time: 2min 51s
gdf
| TRIP_ID | CALL_TYPE | ORIGIN_CALL | TAXI_ID | TIMESTAMP | POLYLINE | |
|---|---|---|---|---|---|---|
| 0 | 1372636858620000589 | C | 20000589 | 2013-07-01 00:00:58 | LINESTRING (-8.61864 41.14141, -8.6185 41.1413... | |
| 1 | 1372637303620000596 | B | 20000596 | 2013-07-01 00:08:23 | LINESTRING (-8.63985 41.15983, -8.64035 41.159... | |
| 2 | 1372636951620000320 | C | 20000320 | 2013-07-01 00:02:31 | LINESTRING (-8.61296 41.14036, -8.61338 41.140... | |
| 3 | 1372636854620000520 | C | 20000520 | 2013-07-01 00:00:54 | LINESTRING (-8.57468 41.15195, -8.5747 41.1519... | |
| 4 | 1372637091620000337 | C | 20000337 | 2013-07-01 00:04:51 | LINESTRING (-8.64599 41.18049, -8.64595 41.180... | |
| ... | ... | ... | ... | ... | ... | ... |
| 1666761 | 1388660427620000585 | C | 20000585 | 2014-01-02 11:00:27 | LINESTRING (-8.60697 41.16228, -8.60697 41.162... | |
| 1666762 | 1404171463620000698 | C | 20000698 | 2014-06-30 23:37:43 | LINESTRING (-8.61247 41.14602, -8.61249 41.145... | |
| 1666763 | 1404171367620000670 | C | 20000670 | 2014-06-30 23:36:07 | LINESTRING (-8.61014 41.14084, -8.61017 41.140... | |
| 1666764 | 1404141826620000248 | B | 20000248 | 2014-06-30 15:23:46 | LINESTRING (-8.63071 41.15488, -8.63073 41.154... | |
| 1666765 | 1404157147620000079 | B | 20000079 | 2014-06-30 19:39:07 | LINESTRING (-8.61554 41.14063, -8.61542 41.140... |
描写
重要なのは、agg = canvas.line(source=gdf, geometry="POLYLINE",agg=ds.count())とimg = ds.tf.shade(agg, cmap=fire)[::-1].to_pil()の部分。
agg=ds.count()でどうゆう集約をするか?どの列を参照するか?決定する。この例だと、「何回ピクセル上にマッピングされたか?」のカウント。
参考: Datashader - api #reductions
# From https://plotly.com/python/datashader/
canvas = ds.Canvas(plot_width=2000, plot_height=2000)
agg = canvas.line(source=gdf, geometry="POLYLINE",agg=ds.count())
# agg is an xarray object, see http://xarray.pydata.org/en/stable/ for more details
coords_lat, coords_lon = agg.coords['y'].values, agg.coords['x'].values
# Corners of the image, which need to be passed to mapbox
# 要するに上の行と合わせ、作成した画像がどのに位置するのか?エリア(lon,lat)と画像の頂点(角)の対応を取るために必要
coordinates = [[coords_lon[0], coords_lat[0]],
[coords_lon[-1], coords_lat[0]],
[coords_lon[-1], coords_lat[-1]],
[coords_lon[0], coords_lat[-1]]]
# import datashader.transfer_functions as tf
img = ds.tf.shade(agg, cmap=fire)[::-1].to_pil()
# Trick to create rapidly a figure with mapbox axes
# トリックを使用しないとこうなるらしい https://github.com/plotly/dash-world-cell-towers/blob/18fe0d3e2966a3e0b8b8fb03fe40e8daae565687/dash_opencellid/app.py#L720
x,y = gdf.POLYLINE.iloc[0].xy
fig = px.scatter_mapbox(
gdf.iloc[0],
lon=x,
lat=y,
zoom=7,
# height=800,
# width=800
opacity=0,
)
# Add the datashader image as a mapbox layer image
fig.update_layout(
mapbox_style="carto-darkmatter",
# mapbox_style="carto-positron",
mapbox_layers = [{
"sourcetype": "image",
"source": img,
"coordinates": coordinates
}]
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# fig.show()
Image(fig.to_image())
町丁ポリゴンを塗り分けてみる
山形県の全域(!!)の町丁目ポリゴンを適当に塗り分けてプロットします。
4428のポリゴンがあります。数としては少ないですが、複雑な形状も含まれます。普通に描写したらplotlyだとまともに動かんです…
ちなみに、乱数で塗り分けているので、隣り合うポリゴンが違う色になる保証はないです。
(N100・12GBメモリのノートでも難なく動いたので、試すにはこちらのほうが向いているかも…)
データの出典: e-stat - 境界データダウンロード 山形県全域
ほとんど同じなのでGistのみ貼っておきます。(こっちは、agg=ds.by('r')のように集約しています)
↓こんな具合に描写できる
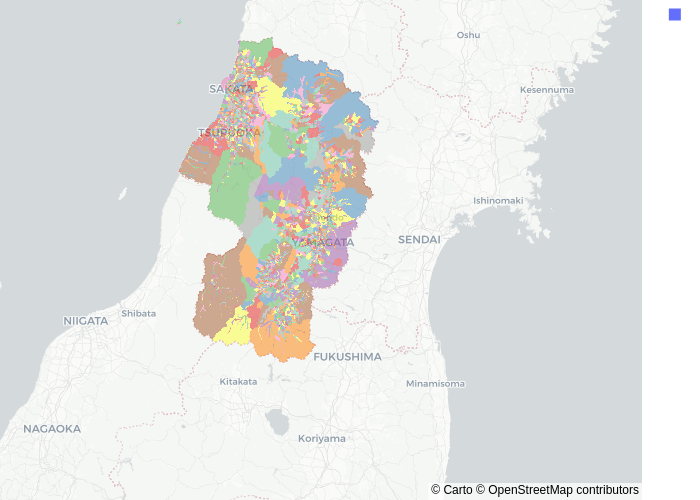
HoloViewsでの描写
holoviewsで可視化する場合、データの座標系をWEBメルカトル法にする必要があるみたいです。
座標系の変換にはややこい計算が必要ですが、pyprojとか使うと簡単ですgeopandas.to_crsしたほうが簡単だとあとから気づいた人
(この例ではデータ量が多すぎるので1万件に絞っています)
その他はチュートリアル通り。
参考
- Holoviz - Datashader
- 座標系関連
- マップタイルの変更
- HoloViz - Colorcet