初めに
初学者である私がこちらの記事をかなり参考にして
データ基盤を構築した際の備忘録となっています。
初めてデータ基盤を構築したい方のためにできるだけ詳細に記載していますので、
周りくどい内容であることをご承知ください。
前提条件
・Google Cloud Platformのアカウントを取得している
・YouTubeAPIを取得している
YouTube APIの取得に関しては以下の記事でわかりやすく説明されています!
【Python】YouTube Data API を使って、いろんな情報を取得してみた!
0.設計したアーキテクチャ

- Cloud Schedulerでメッセージを発行する
- Pub/SubがCloud Functionsにメッセージを通知
- Cloud Functionsでデータを取得し、Cloud Storageに保存
-
Cloud Storageにファイルがアップロードされたのをトリガーに、
Cloud Functionsが実行されBigQueryにデータをロード - BigQueryと連携しデータポータルでレポート作成
以下でそれぞれのコンポーネントについて詳しく説明していきます。
※GCPを使用するため、プロジェクトを作成しておく必要があります。
1.Pub/Subのトピックおよびサブスクリプションを作成
順番が前後しますが、Cloud Schedulerの設定のために
Pub/Subのトピックとサブスクリプションを作成する必要があります。
公式の手順に沿って作成していきます。
1.1.GCP上でShellを起動
下図の赤丸の部分をクリックするとShellが起動されます。

1.2.トピックの作成
my-topic を含むトピックを作成されます。
gcloud pubsub topics create <my-topic>
1.3.サブスクリプションの作成
my-sub を含むサブスクリプションを作成し、先ほど作成した my-topic に添付します。
gcloud pubsub subscriptions create <my-sub> --topic=<my-topic>
これでトピックおよびサブスクリプションの準備が完了です!
2.Cloud Schedulerでメッセージを発行
2.1.ジョブを作成

※頻度に関してはこちらを参照してください。
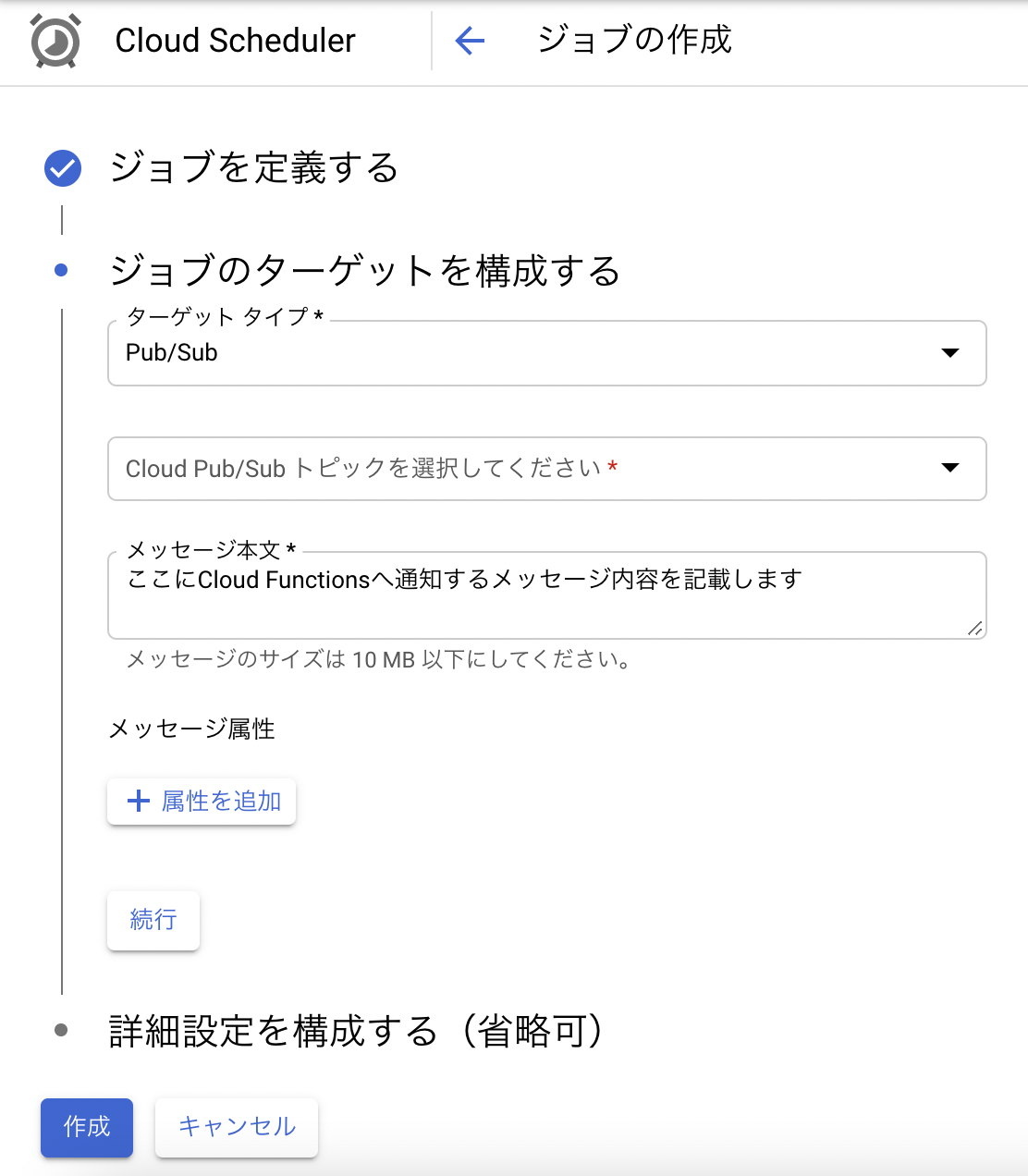
Cloud Pub/Sub トピックは「1.2.トピックの作成」で作成したものを選択してください。
3.Cloud FunctionsでYouTubeデータを取得する関数を作成
3.1.1. 事前に行っておくこと
1. GCS(Google Cloud Storage)にバケットを作成
2. 作成したバケットの中に**「'subscriberCount', 'viewCount', 'date'」**
のカラム名が入った空データのcsvファイルを保存(このcsvファイルにデータが保存されていく)
3.1.「チャンネルの登録者数、総再生回数」を取得する関数
関数を作成から以下の通りに記載します(関数名は好きなもので結構です)。

Cloud Pub/Sub トピックは「1.2.トピックの作成」で作成したものを選択してください。
ランチタイム:python3.9(Pythonであればなんでも大丈夫です)
ソースコードは:インラインエディタ
エントリポイント:youtube(main.pyにある関数を定義します)
ちなみに関数youtubeの引数にはPub/Subから通知されたメッセージが入ります。
Cloud Functions内に以下の5つのファイルを作成します
・main.py
・requirements.txt
・get_channel.py
・load_to_gcs.py
・settings.py
from apiclient.discovery import build
from get_channel import GetChannel
import settings
def youtube(event, context):
# 設定
API_KEY = settings.API_KEY
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
channel_name = '<ここに取得したいチャンネル名を記載>'
youtube = build(
YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=API_KEY,
cache_discovery=False
)
channel = GetChannel(youtube, channel_name)
channel.get_channel_details()
google-api-core==1.23.0
google-api-python-client==1.12.8
google-cloud-storage==1.33.0
google-auth==1.23.0
pandas==1.1.5
python-dotenv==0.15.0
from datetime import datetime
from apiclient.discovery import build
import pandas as pd
import load_to_gcs
class GetChannel(object):
def __init__(self, youtube, channel_name):
self.youtube = youtube
self.channel_name = channel_name
def get_channel_basic(self):
response = self.youtube.search()\
.list(q=self.channel_name, part='id,snippet', maxResults=1).execute()
for item in response.get('items', []):
if item['id']['kind'] == 'youtube#channel':
return item['id']['channelId']
def get_channel_details(self):
response = self.youtube.channels().list(
part = 'snippet,statistics',
id = self.get_channel_basic()
).execute()
for item in response.get("items", []):
if item["kind"] == "youtube#channel":
series = pd.Series([item['statistics']['subscriberCount'],
item['statistics']['viewCount'],
datetime.now().strftime('%Y-%m-%d')],
['subscriberCount', 'viewCount', 'date'])
load_to_gcs.read_from_gcs_and_append(series)
import datetime
from io import BytesIO
from google.cloud import storage as gcs
import pandas as pd
import settings
def read_from_gcs_and_append(series):
project_id = settings.project_id
bucket_name = settings.bucket_name
gcs_path = '<GCSに保存したファイル名>.csv' # csv形式
client = gcs.Client(project_id)
bucket = client.get_bucket(bucket_name)
blob_read = bucket.blob(gcs_path)
content_read = blob_read.download_as_string()
df = pd.read_csv(BytesIO(content_read))
df = df.append(series, ignore_index=True)
blob_write = bucket.blob(gcs_path)
blob_write.upload_from_string(df.to_csv(index=False, header=True), content_type='text/csv')
API_KEY = '<自分のYouTube API を入力>'
project_id = '<自分のproject_idを入力>'
bucket_name = '<load_to_gcs.pyでcsvファイルを保存したbucket_nameを入力>'
3.2.「アップされた動画の詳細情報」を取得する関数
Cloud Pub/Sub トピックは「1.2.トピックの作成」で作成したものを選択してください。
ランチタイム:python3.9(Pythonであればなんでも大丈夫です)
ソースコードは:インラインエディタ
エントリポイント:youtube(main.pyにある関数を定義します)
ちなみに関数youtubeの引数にはPub/Subから通知されたメッセージが入ります。
今回は以下の6つのファイルを作成します
・main.py
・requirements.txt
・get_channel.py
・load_to_gcs.py
・settings.py
・get_video.py
※ settings.py、requirements.pyは上記と同じコードなので記載してません。
from apiclient.discovery import build
from get_channel import GetChannel
from get_video import GetVideo
import settings
def youtube(event, context):
# 設定
API_KEY = settings.API_KEY
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
channel_name = '<ここに取得したいチャンネル名を記載>'
youtube = build(
YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=API_KEY,
cache_discovery=False
)
videos = GetVideo(youtube, channel_name)
videos.get_video_details_csv()
from apiclient.discovery import build
class GetChannel(object):
def __init__(self, youtube, channel_name):
self.youtube = youtube
self.channel_name = channel_name
def get_channel_basic(self):
response = self.youtube.search().list(q=self.channel_name,
part='id,snippet',
maxResults=1).execute()
for item in response.get('items', []):
if item['id']['kind'] == 'youtube#channel':
return item['id']['channelId']
import datetime
from google.cloud import storage as gcs
import pandas as pd
import settings
def load_to_gcs_csv(df):
now = datetime.datetime.now()
project_id = settings.project_id
bucket_name = settings.bucket_name
gcs_path = '{}-test.csv'.format(now.strftime('%Y-%m-%d-%H:%M'))
client = gcs.Client(project_id)
bucket = client.get_bucket(bucket_name)
blob = bucket.blob(gcs_path)
blob.upload_from_string(df.to_csv(index=False, header=True), content_type='text/csv')
from apiclient.discovery import build
import pandas as pd
from google.cloud import storage as gcs
from get_channel import GetChannel
from load_to_gcs import load_to_gcs_csv
class GetVideo(GetChannel):
def get_video_basic(self):
nextPagetoken = None
video_ids = []
while True:
if nextPagetoken != None:
nextpagetoken = nextPagetoken
response = self.youtube.search().list(
part = "snippet",
channelId = self.get_channel_basic(),
maxResults = 50,
order = "date", #日付順にソート
pageToken = nextpagetoken
).execute()
for item in response.get("items", []):
if item["id"]["kind"] == "youtube#video":
video_ids.append(item["id"]["videoId"])
try:
nextPagetoken = response["nextPageToken"]
except:
break
return video_ids
def get_video_details_csv(self):
videos = []
for video_id in self.get_video_basic():
response = self.youtube.videos().list(
part = 'snippet,statistics',
id = video_id
).execute()
for item in response.get("items", []):
if item["kind"] == "youtube#video":
videos.append(
[item["snippet"]["title"],
item["statistics"]["viewCount"],
item["statistics"]["likeCount"],
item["statistics"]["dislikeCount"],
item["statistics"]["favoriteCount"] if "favoriteCount" in item["statistics"].keys() else None,
item["statistics"]["commentCount"] if "commentCount" in item["statistics"].keys() else None,
item["snippet"]["tags"] if "tags" in item["snippet"].keys() else None,
item["snippet"]["publishedAt"]
])
df_video = pd.DataFrame(videos,
columns=['title', 'viewCount', 'likeCount', 'dislikeCount', 'favoriteCount', 'commentCount', 'tags', 'publishAt'])
load_to_gcs_csv(df_video)
3.3.「GCSからBigQueryへロード」する関数
事前に行っておくこと
BigQueryにdetasetおよびtable(2つ)を作成します。
Cloud Shell上から以下のコマンドでdatasetとtableを作成できます
PROJECT=<自分のproject ID>
DATASET=<作成するDetaset名>
bq --project_id ${PROJECT} mk ${DATASET}
bq --project_id ${PROJECT} mk --time_partitioning_type=DAY ${DATASET}.<作成するtable名1>
bq --project_id ${PROJECT} mk --time_partitioning_type=DAY ${DATASET}.<作成するtable名2>
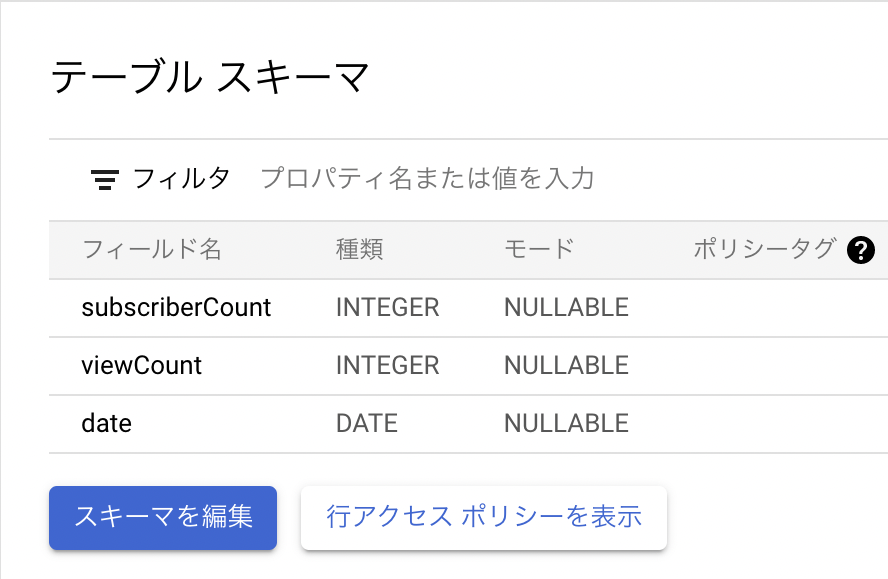
作成できれば、以下のようにtableのスキーマを設定します
・<上記で作成したtable名1>のスキーマ
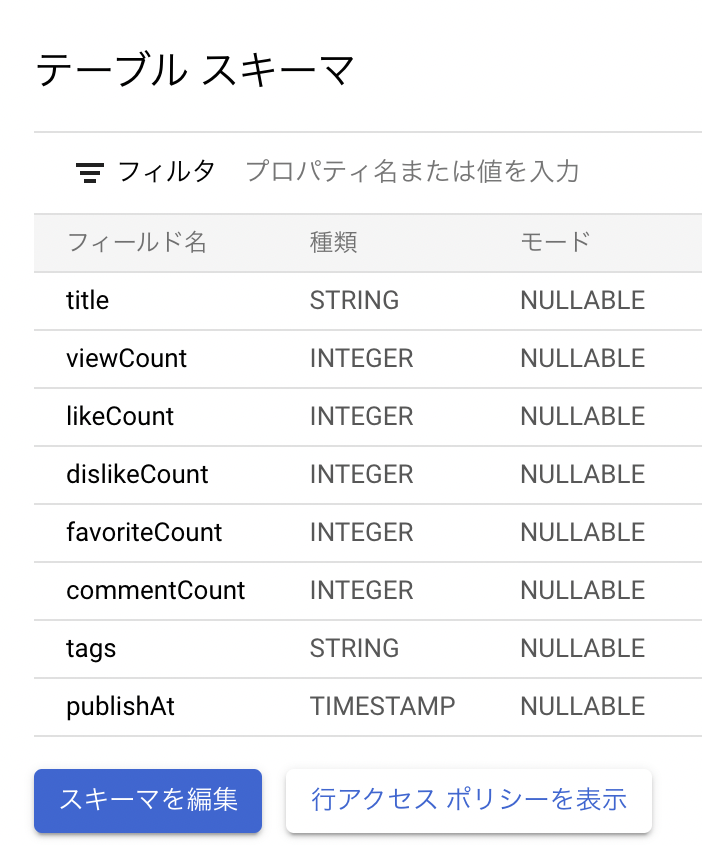
 ###### ・<上記で作成したtable名2>のスキーマ
###### ・<上記で作成したtable名2>のスキーマ
関数の定義
Storageへの保存をトリガーにするため、
以下の通りに設定する。

ランチタイム:python3.9(Pythonであればなんでも大丈夫です)
ソースコードは:インラインエディタ
エントリポイント:youtube(main.pyにある関数を定義します)
ちなみに関数youtubeの引数にはPub/Subから通知されたメッセージが入ります。
今回は以下の3つのファイルを作成します
・main.py
・requirements.txt
・settings.py
from google.cloud import bigquery
import settings
def load_data(data, context):
# check content-type
if data['contentType'] != 'text/csv':
print('Not supported file type: {}'.format(data['contentType']))
return
# get file info
bucket_name = data['bucket']
file_name = data['name']
uri = 'gs://{}/{}'.format(bucket_name, file_name)
dataset_id = settings.dataset_id
if file_name == '<GCSに保存してあるcsvファイル名>':
table_id = settings.<上記で作成したtable名1>
else:
table_id = settings.<上記で作成したtable名2>
client = bigquery.Client()
dataset_ref =client.dataset(dataset_id)
# Set Load Config
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.source_format = bigquery.SourceFormat.CSV
job_config.write_disposition = 'WRITE_TRUNCATE'
# Load data
load_job = client.load_table_from_uri(
uri, dataset_ref.table(table_id), job_config=job_config
)
print("Starting job {}".format(load_job.job_id))
load_job.result()
print("Job finished.")
google-cloud-bigquery==1.24.0
python-dotenv==0.15.0
dataset_id = 'test_dataset'
table_view_subscriber_id = 'table_view_subscriber_id'
table_video_id = 'table_video_id'
最後に
これでBigQueryへのロードまでを自動化することができたと思います!
データを取得するタイミングをずらしたい場合は、
Pub/Subのトピック・サブスクリプションを1つ追加して、
Cloud Schedulerの時間を指定することで簡単に変更することができます。
また、得られたデータはCloud Data Portalで簡単に可視化することができます。
興味のある方は是非チャレンジしてください!
初学者であるが故に至らぬ点が多くあると思いますので
ご指摘・修正点があればコメントください!
また、ご不明点があれば、お気軽にコメントしてください!