2022/9/26 投稿
0. この記事の対象者
- Pythonの実行環境がある人
- Pythonをある程度触れる人
- Python pandasをある程度触れる人
- DataFrame形式のデータをランダム生成したい人
1. はじめに
Pythonではcsvやエクセルの表データを扱うためにpandasというモジュールを提供しています.
pandasには列データを扱うSeries型と二次元の表データを扱うDataFrame型が存在し,それぞれのデータに対して集計や分析,グラフ描画などが可能です.
そんなDataFrame型のデータだが,その生成方法は以下のようなやり方が代表的です.
- csv, excel, pickleデータを読み込んで生成
- 適当な二次元配列から生成
上記のケースで通常は満足するのですが,以下のようなケースで困ったことはないでしょうか.
- pandasの関数の挙動をパッと確認するために適当な表データを作成したいがスクラッチでいちいち作成するのは面倒
- 仕事でcsvデータを受領するまでに時間を要すが,項目名や大まかなデータの形式は割っており,受領までに簡単な実装をしておきたい
- 実装した分析プログラムのテストケースようにランダムなデータが作成したい
- 公開されている適当なツールを用いてランダムなcsvを生成したいが,端末にはPython環境しか整っておらず,それ以外の環境を整えるのは難しい
これらの困りごとを少しでも解消するためにipywidgetsを用いてjupyter上GUIでDataFrame pickleデータをランダム生成するプログラムを作成しました.
csvではなくpickleを生成するのは型の情報を保存するためです.
バグは存在すると思うので,見つけ次第修正し,この記事を更新していくつもりです.
※ipywidgetsの勉強がてら遊びながら作ったものなので,多少の不格好なコードは温かい目で見ていただけると幸いです
2. 実装環境
jupyter notebook, jupyter lab上でGUIボタンなどを作成できるipywidgetsというモジュールを使用します.
私の実装環境は以下.
- Python : 3.8.7
- jupyterlab : 3.4.7
- ipywidgets : 8.0.2
- pandas : 1.4.4
上記以外のバージョンでも動く可能性は十分あり得るのであまり気にしなくても大丈夫です.
4. 実装&実行
実装プログラムは以下のGithubより取得できます.
DataFrameランダム生成プログラム
プログラムは以下のようなシンプルな構成です.
.
├── test_dataframe.ipynb
├── make_df.py
└── make_df_widgets.py
- test_dataframe.ipynb : このjupyrter上でpickleデータランダム生成を行う
- make_df.py : DataFrameを設定ファイルからランダム生成する関数
- make_df_widgets.py : jupyter上でGUI生成する関数
実行するプログラムはtest_dataframe.ipynbのみで,その他の2つはnotebookでimportして使っています.
ランダム生成の流れは以下のようになっています.
- test_dataframe.ipynbを実行し,GUIで所望の項目や数値を入力
- DataFrameを作成するボタン押すとその設定ファイル(json)とpickleデータが生成
- これをpandasで読み込んで利用
生成されたjsonファイルは2回目以降でuploadすればその設定を読み込んでGUIが作成されます.
実行は以下の手順で行います.
- jupyterを起動
- test_dataframe.ipynbを開く
- Run all実行
5. プログラム詳細解説
5-1. test_dataframe.ipynb前半
これはnotebookファイルで,以下のような実装になっています.(※実際にはセルごとにコードが書かれていますが,ここでは見やすくひとまとまり&無駄な行を除去して記載しています)
import pandas as pd
import json
from make_df_widgets import DFWidgets
def upload_json(json_path):
try:
with open(json_path, mode='r') as f:
df_dict = json.load(f)
except Exception as e:
df_dict = {}
print(e)
return df_dict
df_dict = upload_json('{JSON_PATH}')
df_w = DFWidgets(df_dict)
df_w.show()
- 1~3行目 : ここで必要なモジュール,自作ライブラリをimport
- 5~12行目 : DataFrameを自動生成するためのjsonファイル読み込み関数
- 14行目 : DataFrameを自動生成するためのjsonファイル読み込み関数.2回目以降でjsonファイルを読み込ませたい場合に使う
- 16行目 : GUI描画用のインスタンスを生成
- 18行目 : GUIの描画
これをjupyter上で実行すればGUIが表示されます.
実際のGUI画面は以下です.
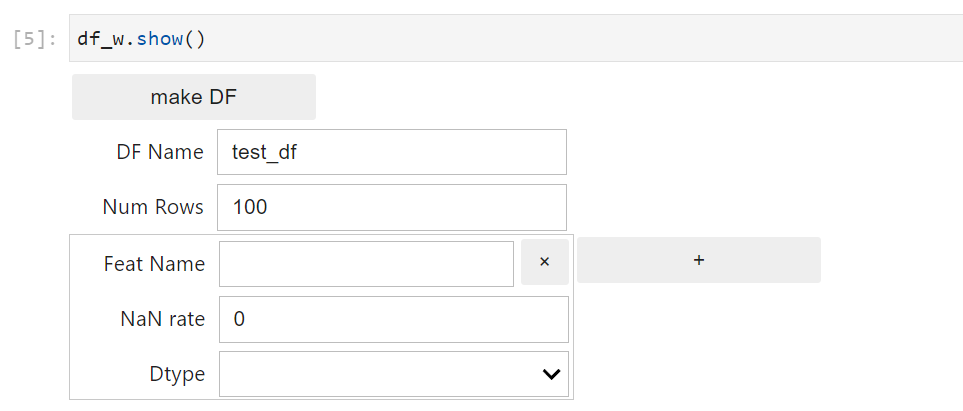
各項目の意味は以下です.
- make DF : 最終的にこのボタンを押すと「DF Name」に記述されている名前のjsonとpickleが生成される
- DF Name : 生成するjsonとpickleの名前
- Num Rows : レコード(行)数
- Feat Name : 項目(列)名
- Nan rate : 全体のNanの割合
- Dtype : str, int, float, datetimeのいずれかを選択
- + : 項目(列)を追加する
Dtypeをそれぞれ実際に選択した画面は以下.
str
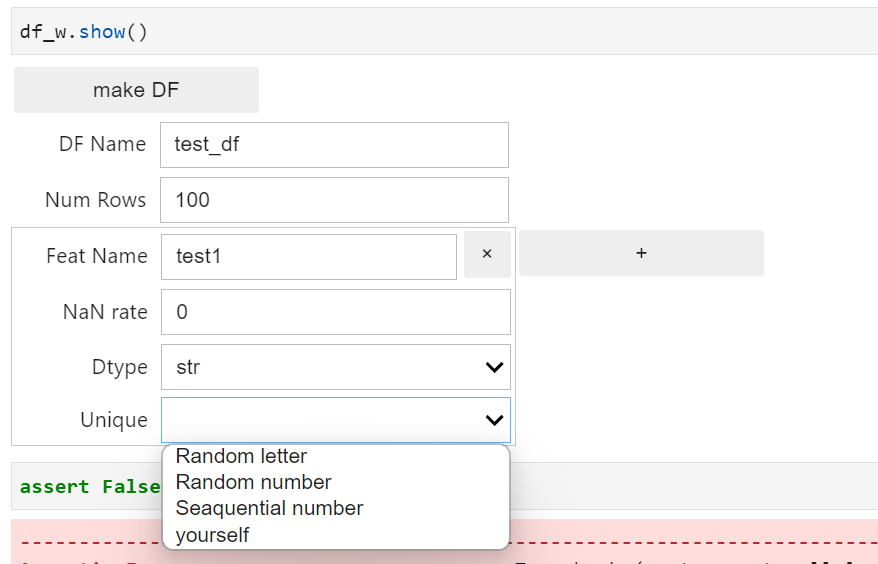
- Unique : Random letter, Random number, Seaquential number, yourselfを選択
- Random letter : ランダムな文字列を生成する
- Randomn number : ランダムな数値文字列を生成する. 桁数が足りない部分は0埋めされる
- Seaquential number : 連番文字列を生成する.最初の数字を指定できる
- yourself : カンマ区切りで記述したものが生成される
int
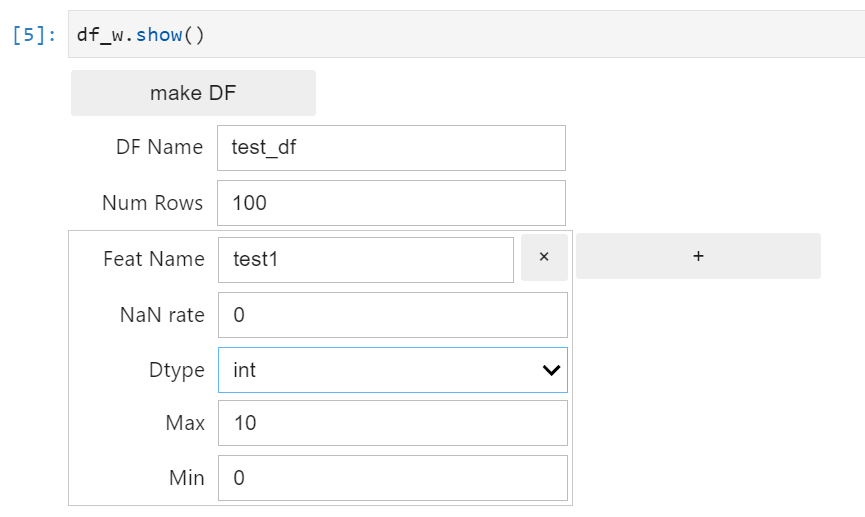
- Max : 最大値
- Min : 最小値
float
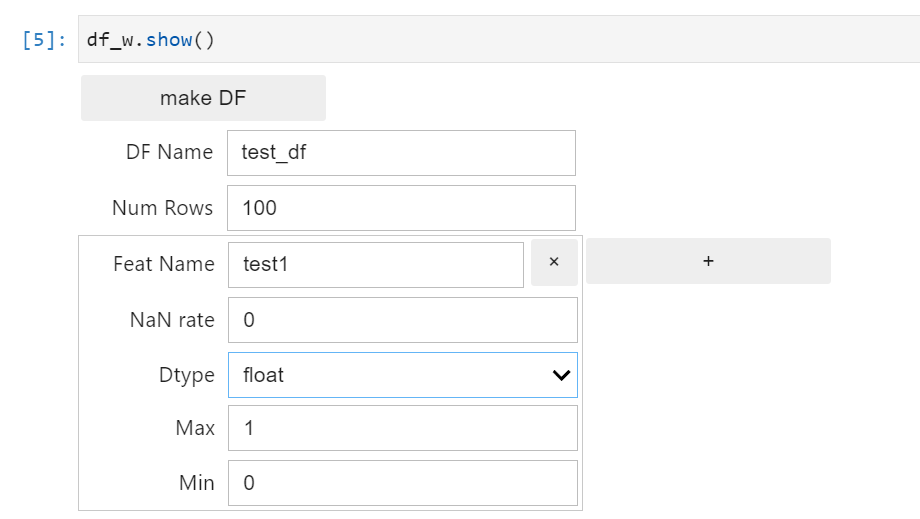
- Max : 最大値
- Min : 最小値
datetime
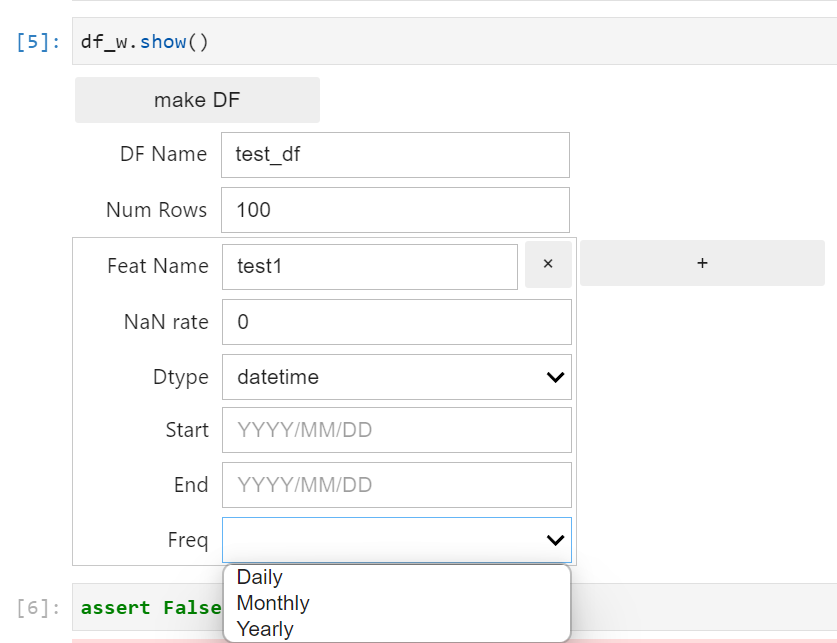
- Start : 期間のはじめ
- End : 期間の終わり
- Freq : Daily, Monthly, Yearlyを選択
※期間の範囲よりも行数が多い場合は繰り返して期間が生成されます.
5-2. test_dataframe.ipynb後半
生成されたpickleファイルを読み込んで期待するランダムデータを取得します.
df = pd.read_pickle('{GUIで指定したDF Name}.pkl')
5-3. make_df_widgets.py
このpyファイルにはjupyter上でのGUIを作成する関数が実装されています.
あまりきれいな方法ではないかもしれませんが,GUIを生成するクラスを用意し,共通で触れるwidgetsを保持させておくことで描画の更新などを行えるようにしました.
※ここのコードは長く汚いので要望があり次第解説を出します.
5-4. make_df.py
このpyファイルにはGUIで記述した情報をもとに生成されたjson辞書データを使ってDataFrameを生成する関数が実装されています.
生成されるjson辞書は以下のような構成です.(下記は抽象化しています)
{
df_name: "XXXXX"
num_rows: XXXXX
features:{
項目名1:{
Nan rate: XXXXX
Dtype: XXXXX
...
}
項目名2:{
Nan rate: XXXXX
Dtype: XXXXX
...
}
...
}
}
※ここのコードも長く汚いので要望があり次第解説を出します.
6. ひとこと
pythonだけの環境でGUIを使った何かを作ってみたく,今回はipywidgets×pandasをやってみました.
不格好なコードは温かい目で見ていただけると幸いです.
読みづらい点も多かったともいますが,読んでいただきありがとうございます.