本記事は2024/12月時点のGenUで構築しています。
今後の更新で設定箇所が変更となる可能性がある点ご了承ください。
皆さん、Generative AI Use Cases JP (略称:GenU)は利用していますか?
AWSが展開している生成 AI を安全に業務活用するための、ビジネスユースケース集を備えたアプリケーションをすぐに実装出来ます。
アプリケーション知識がほぼ皆無のわたし。
インフラ畑のエンジニアでも簡単に実装が出来るという優れモノです!
自身のAWS環境に生成AI基盤を構築することになるため、ChatGPTなどの野良生成AI利用を禁止している企業でも導入検討が可能なアプリケーションとなります。
ワークショップなども出ており、社内で生成AIを利用したい方にも刺さる一品となっています👏
今回はGenUを展開後、RAGにS3バケットを追加する際の設定でハマったので設定箇所をご紹介します。
GenUではポリシー類が厳密に設定されていたので、S3バケットを追加するだけではエラーが出ます。追加設定が必要な箇所の参考にしていただければ幸いです。
本記事ではGenUのCDKでRAGを構築した状態から開始します。
GenUの構築方法についてはワークショップ等をご覧ください。

最初に結論
修正は下記のIAMロール2つです。
- RagKnowledgeBaseStack-KnowledgeBaseRole...(Bedrock用)
- GenerativeAiUseCasesStack-APIGetFileDownloadSignedU-...(Lambda用)
これらに新規追加するS3バケットのARNを追記することで、GenUのRAGチャットのデータソースとして利用することが出来ます。
0. 事前準備
まずは新規データソースの置き場としてS3バケットを作成し、ナレッジベースへの登録を行います。
新規データソースを追加
S3バケットの作成 / 設定
GenUで構築したリージョンに新規S3バケットを作成し、ナレッジベースに追加します。
- 【リージョン】
- us-west-2(米国西部 オレゴン)
- 【新規作成】
- RAG追加用S3バケット:knowledge-base-rag-add-test-20241222
- データソース:knowledge-base-rag-s3-add

ナレッジデータの追加
続いて作成したS3バケットにナレッジデータをアップロードします。
今回はサンプルとして、AWSワークショップのデータを使います。
- 保存先:[S3バケット]/docs 配下
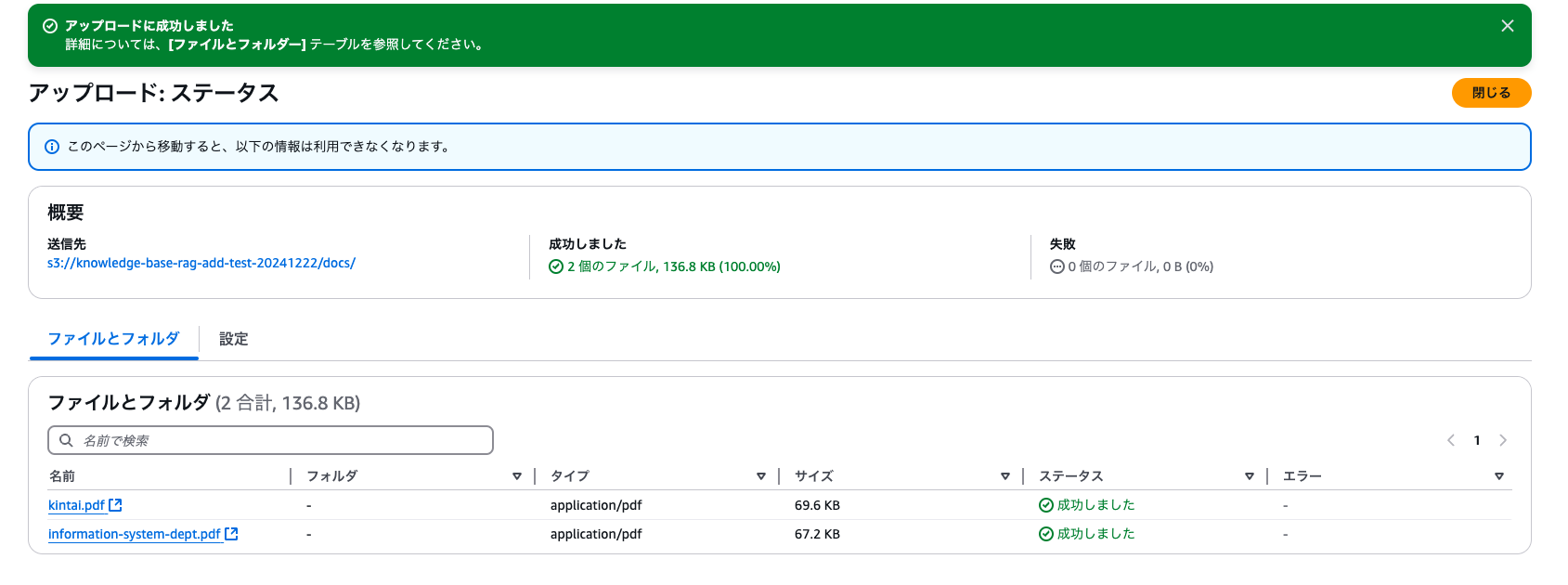
ここまではGenUのデフォルト権限で可能な範囲となります。
ここからの作業はエラーが発生するため修正していきます。
変更前 動作確認(GenUデフォルト設定)
作成したナレッジベースで動作確認をしてみます。
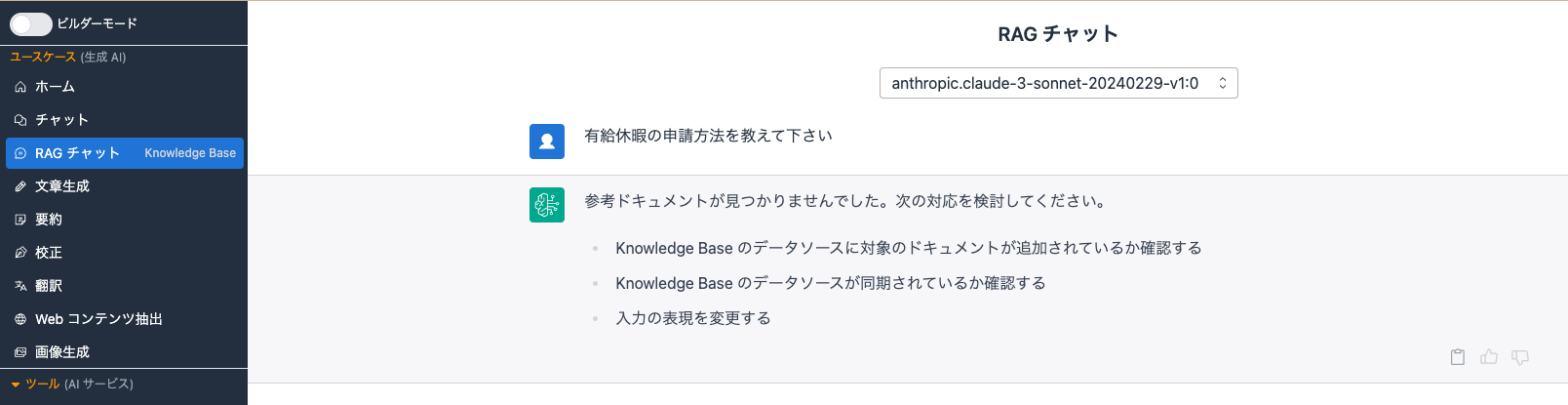
何も保存していないため、参考ドキュメントが見つからないと返ってきました。
それでは追加したS3バケット「knowledge-base-rag-add-test-20241222」に追加したデータをRAGとして使えるように同期していきます。
変更1. ナレッジベースデータソースの同期設定
先ほど配置したデータソースをナレッジベースに同期させようとしますが、エラーになります。
ナレッジベースから新規追加したデータソースを開く > [同期] をクリック
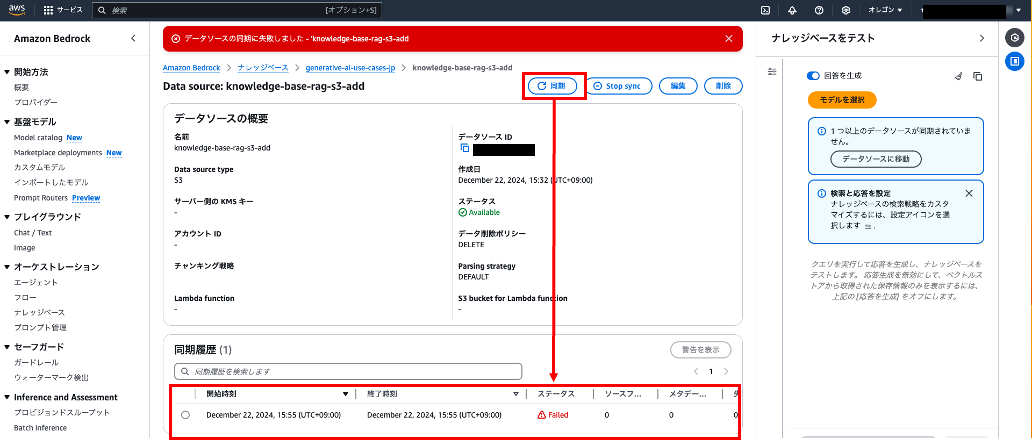
エラー内容の確認
同期履歴を選択 > [警告を表示] をクリック
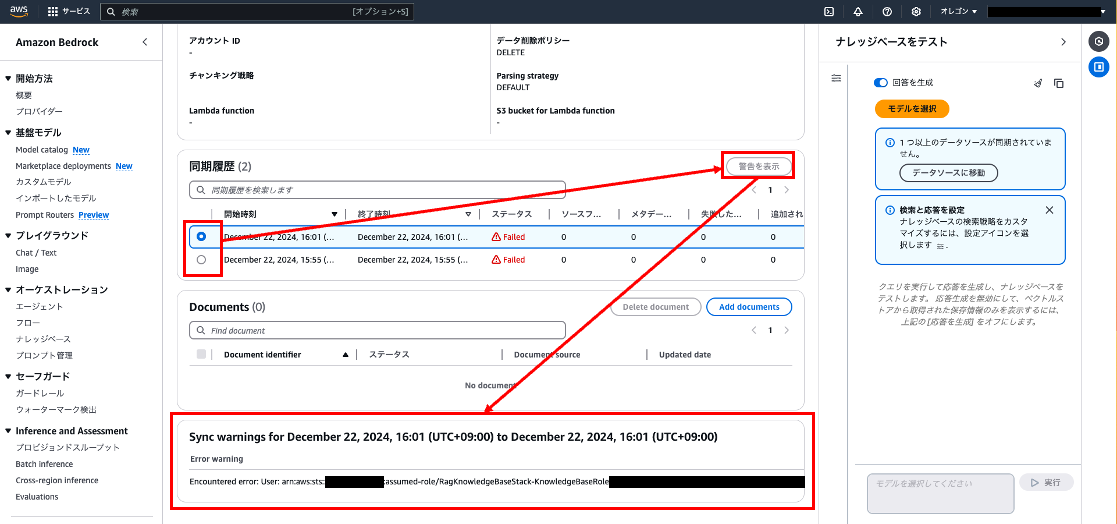
下部にエラー内容が表示されました。
Error warning
Encountered error: User: arn:aws:sts::123456789012:assumed-role/RagKnowledgeBaseStack-KnowledgeBaseRoleA2345678-abcdef123456/S3SourceFileCrawler-ABCDE1234 is not authorized to perform: s3:ListBucket on resource: "arn:aws:s3:::knowledge-base-rag-add-test-20241222" because no identity-based policy allows the s3:ListBucket action (Service: S3, Status Code: 403, Request ID: A..., Extended Request ID: qd...). Call to Amazon S3 Source did not succeed.
Bedrock用に作成されたIAMロール(RagKnowledgeBaseStack-KnowledgeBaseRole...)が、対象のS3バケット(knowledge-base-rag-add-test-20241222)にアクセスする権限が無い様子。
BedrockのIAMロールに権限を追加
- Amazon Bedrock > ナレッジベース > generative-ai-use-cases-jp を開く
- サービスロールの「RagKnowledgeBaseStack-KnowledgeBaseRole...」をクリック

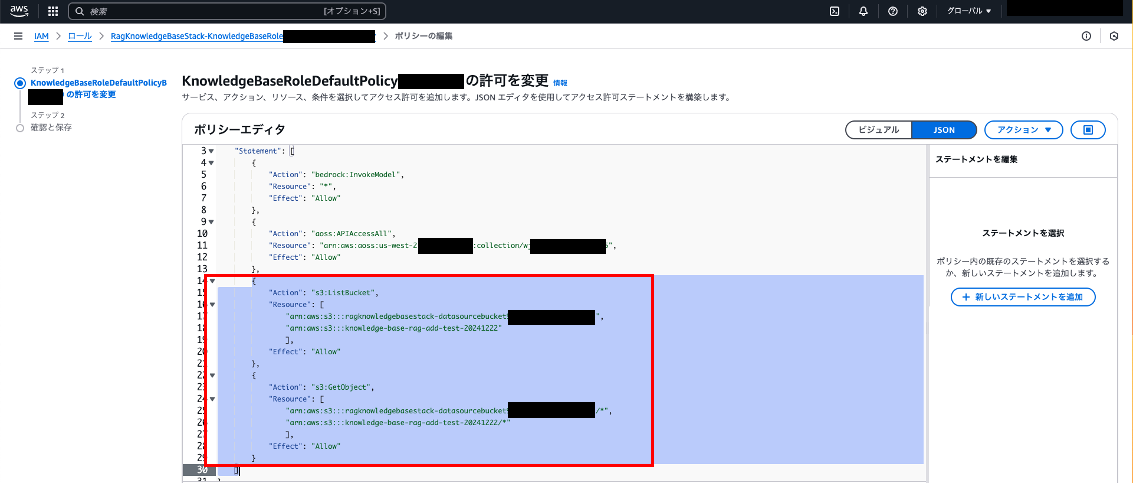
IAMポリシー「KnowledgeBaseRoleDefaultPolicy...」に新規作成したS3バケットへの権限を追加します。
{
"Action": "s3:ListBucket",
"Resource": [
"arn:aws:s3:::ragknowledgebasestack-datasourcebucket...",
"arn:aws:s3:::knowledge-base-rag-add-test-20241222"
],
"Effect": "Allow"
},
{
"Action": "s3:GetObject",
"Resource": [
"arn:aws:s3:::ragknowledgebasestack-datasourcebucket.../*",
"arn:aws:s3:::knowledge-base-rag-add-test-20241222/*"
],
"Effect": "Allow"
}
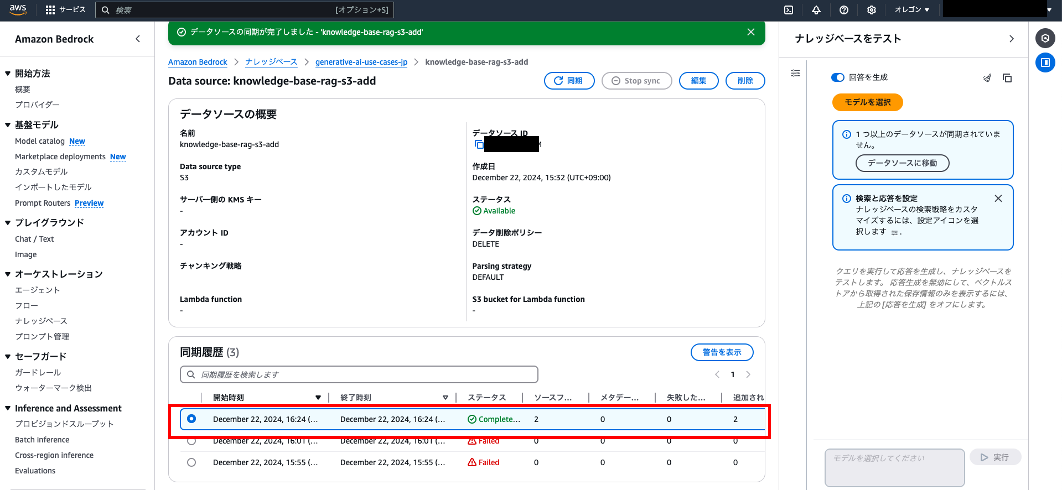
同期実行のリトライ
IAMロールの権限を修正後、改めて同期を実行します。
ステータスが[Complete]となり正常に同期されるようになりました。
画面の右カラムにある「ナレッジベースをテスト」を実行すると、先ほどのPDFデータが参照されていることが確認できました。
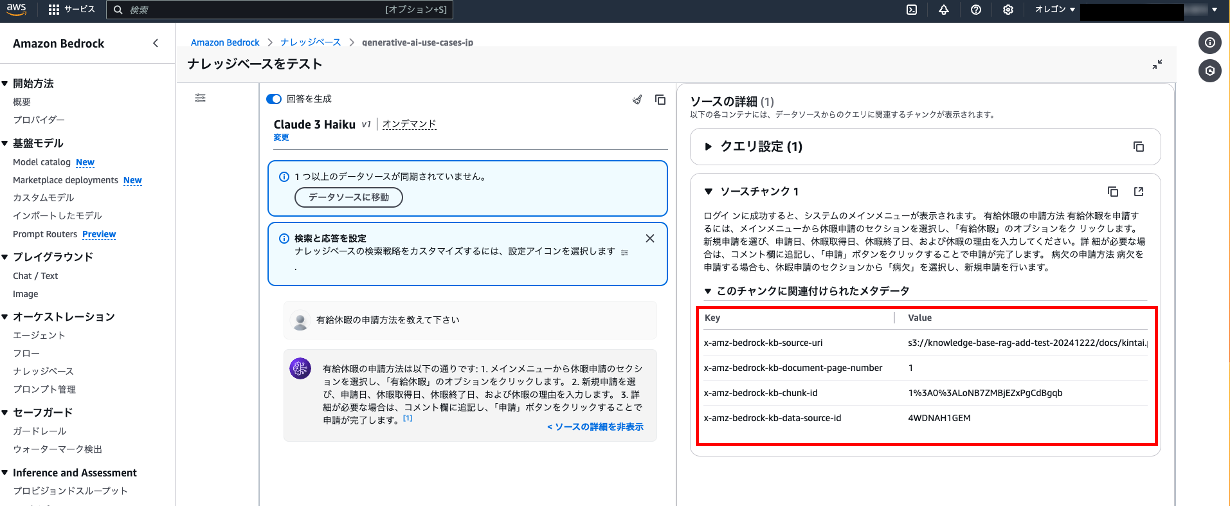
テスト時に「1つ以上のデータソースが同期されていません。」が出ていても、同期が成功していればテスト可能でした。
動作確認(1):Bedrock IAMロール変更後
実際にCloudFrontのURLから、GenU上で正常動作となるか確認します。
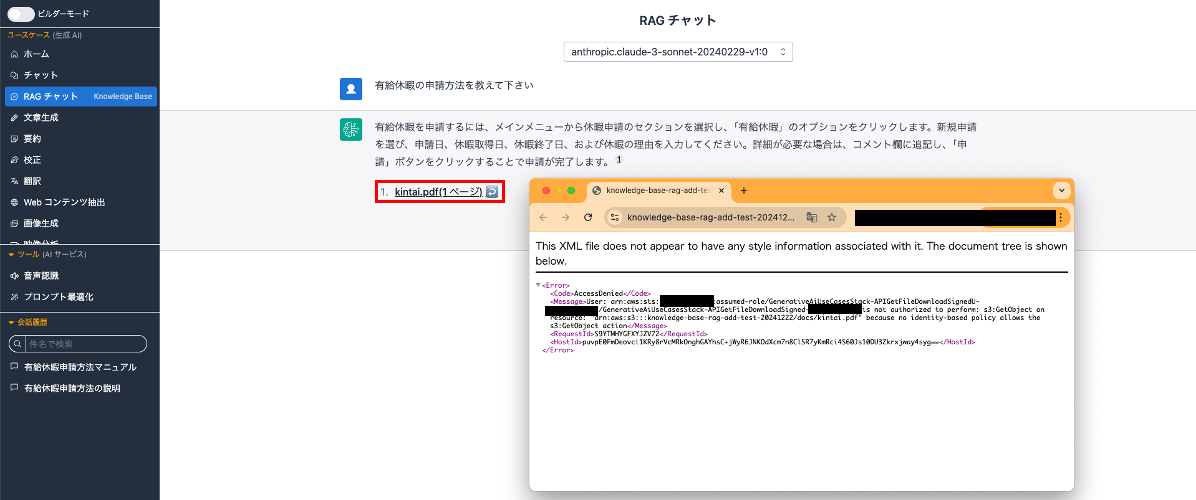
- データソースから取得して回答が表示される
- 参照したデータソースのリンクが表示される
- データソースの閲覧がアクセス拒否される
GenU上でRAGとしての機能は、Bedrockのサービスロール「RagKnowledgeBaseStack-KnowledgeBaseRole...」に権限付与するのみで可能となりました。
参照データにアクセスさせたくない場合はココまでの対応で完了です。
参照データへのアクセスするためにさらに読み解きましょう。
変更2.CloudFront経由のS3バケットアクセス設定
CloudFront→API Gateway→Lambda→S3バケットのどこかで権限が不足しています。
GenU上で表示されたWeb画面からエラーを確認し、対象リソースを予測します。
エラー内容の確認
<Error>
<Code>AccessDenied</Code>
<Message>User: arn:aws:sts::123456789012:assumed-role/GenerativeAiUseCasesStack-APIGetFileDownloadSignedU-abcdef123456/GenerativeAiUseCasesStack-APIGetFileDownloadSigned-ABCD1234efgh is not authorized to perform: s3:GetObject on resource: "arn:aws:s3:::knowledge-base-rag-add-test-20241222/docs/kintai.pdf" because no identity-based policy allows the s3:GetObject action</Message>
<RequestId>S9...</RequestId>
<HostId>puv...==</HostId>
</Error>
次はIAMロール「GenerativeAiUseCasesStack-APIGetFileDownloadSignedU-...」に「s3:GetObject」の権限が無いと表示されました。
IAM > ロール > [GenerativeAiUseCasesStack-APIGetFileDownloadSignedU-...] > 許可ポリシーを確認します。
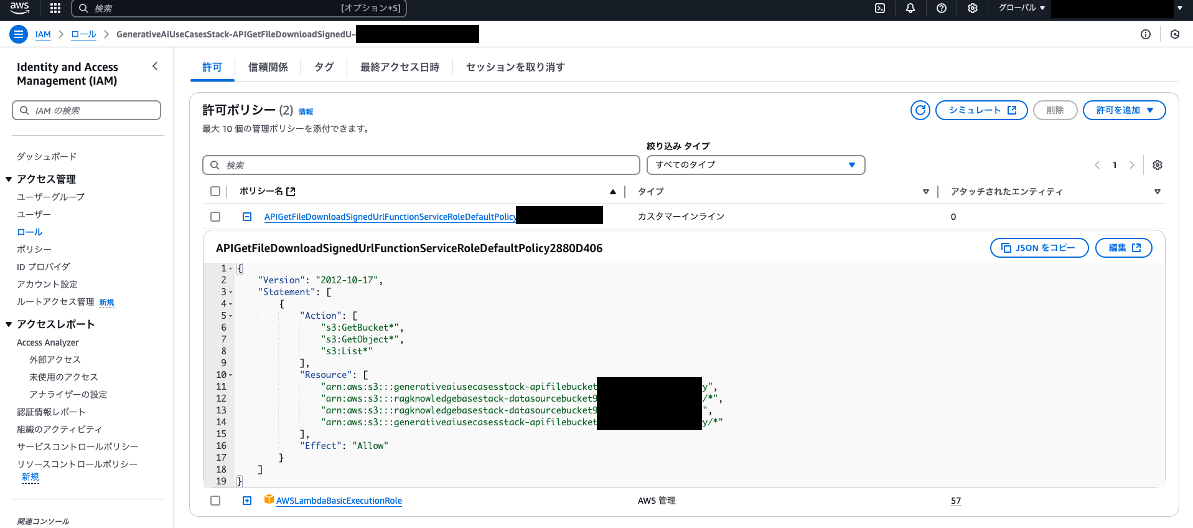
「APIGetFileDownloadSignedUrlFunctionServiceRoleDefaultPolicy...」と「AWSLambdaBasicExecutionRole」の2つがあります。
カスタムポリシーの「API...」を開くと、RAGに必要とするS3バケットが記載されています。
今回は「APIGetFileDownloadSignedUrlFunctionServiceRoleDefaultPolicy...」へ、ナレッジベース用のS3バケットを追記します。
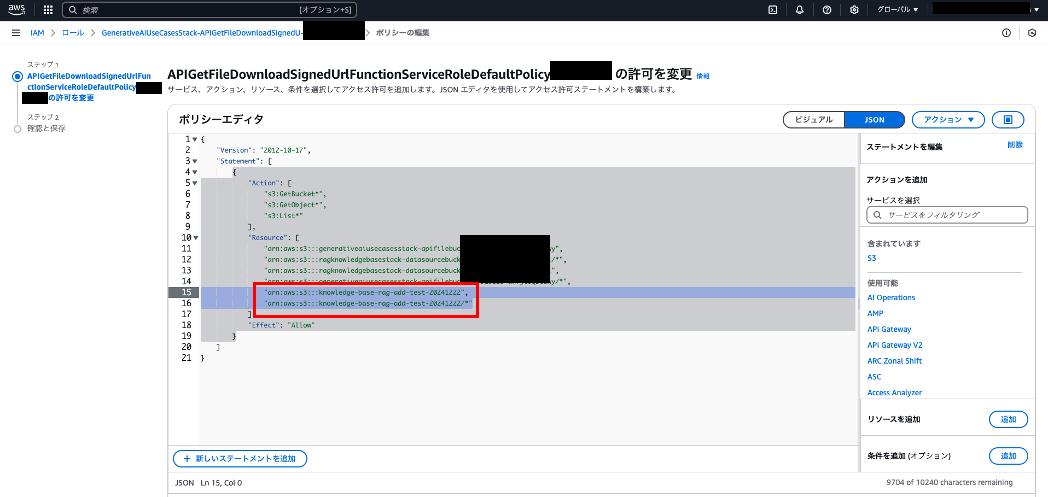
Lambda:APIGetFile用のIAMロール修正
恐らくGetで利用しているLambdaに権限が不足しているのでしょう。
今回RAGのデータソースとして追加したS3バケット「knowledge-base-rag-add-test-20241222」とその配下オブジェクトに対して権限を付与します。
"Resource": [
"arn:aws:s3:::generativeaiusecasesstack-apifilebucket...",
"arn:aws:s3:::ragknowledgebasestack-datasourcebucket.../*",
"arn:aws:s3:::ragknowledgebasestack-datasourcebucket...",
"arn:aws:s3:::generativeaiusecasesstack-apifilebucket.../*",
"arn:aws:s3:::knowledge-base-rag-add-test-20241222",
"arn:aws:s3:::knowledge-base-rag-add-test-20241222/*"
],
動作確認(2):Get Lambda IAMロール変更後
IAMロール変更後に改めてGenUからRAGチャットを試してみます。

- RAGからの情報取得OK!
- ソースのデータ取得OK!
GenUから新規に追加したS3バケットに対して、RAGチャット&ソースデータダウンロードが出来るようになりました!
最後に
CDKを利用して一括で構築出来る反面、対象リソースへのアクセスなどセキュリティ面も考慮されていて拡張の難しさを感じました。
こういった拡張作業などで権限エラーが出る場合はインフラエンジニアとしての知見が強みに思えます。GenUのCDKが日々更新されていくため、アプリケーションレイヤーが苦手なわたしでも関われるのは非常に有り難いです🥹
今後も生成AI関係でCDKを利用する機会は増えそうなため、アップデートを追いかけていきたい所存です。
参考サイト