教師あり機械学習法はたくさんありますが、scikit-learn に入ってるもののうち主なものを全部使って、optunaでハイパーパラメーターチューニングして、できたモデルをさらにstackingしてしまうという一連の作業をまとめて行うライブラリ ScikitAllStars を作りました。
なぜこんなツールを作ったかって?めんどいからです。
また、ScikitAllStars の特徴として、教師あり機械学習が「回帰問題」なのか「分類問題」なのかという違いをほとんど意識せずに使えるというところもあります。
以下のコードは全て Google Colaboratory 上で動作を確認済みです。
必要なツールのインストール
# Optuna のインストール
!pip install optuna
# ScikitAllStars のインストール
!pip install git+https://github.com/maskot1977/scikitallstars.git
データの用意
下記は Numpy array 形式のデータを用いていますが、Pandas DataFrame 形式のデータでも使えるはずです。
まず、分類用データを使ってみましょう。
import sklearn.datasets
dataset = sklearn.datasets.load_breast_cancer() # 分類用データ例
# dataset = sklearn.datasets.load_diabetes() # 回帰用データ例
訓練データ・テストデータへ分割を行います。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=.4) # 訓練データ・テストデータへのランダムな分割
AllStarsモデルの学習
次のようにして、ScikitAllStarsに登録してある全ての手法に対してoputunaでチューニングしながら学習を行います。feature_selection=True とすることで、RandomForestによる特徴選択を事前に行ないます。
from scikitallstars import allstars, depict
allstars_model = allstars.fit(X_train, y_train, timeout=1000, n_trials=100, feature_selection=True)
feature selection: X_train (341, 30) -> (341, 9)
feature_selection=True とした場合は、次のようにすると、重要な特徴量についての知見が得られます。
depict.feature_importances(allstars_model)
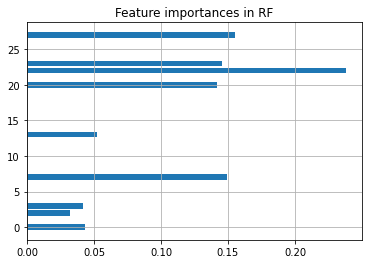
次のようにして、学習経過のサマリーが得られます。
depict.training_summary(allstars_model)
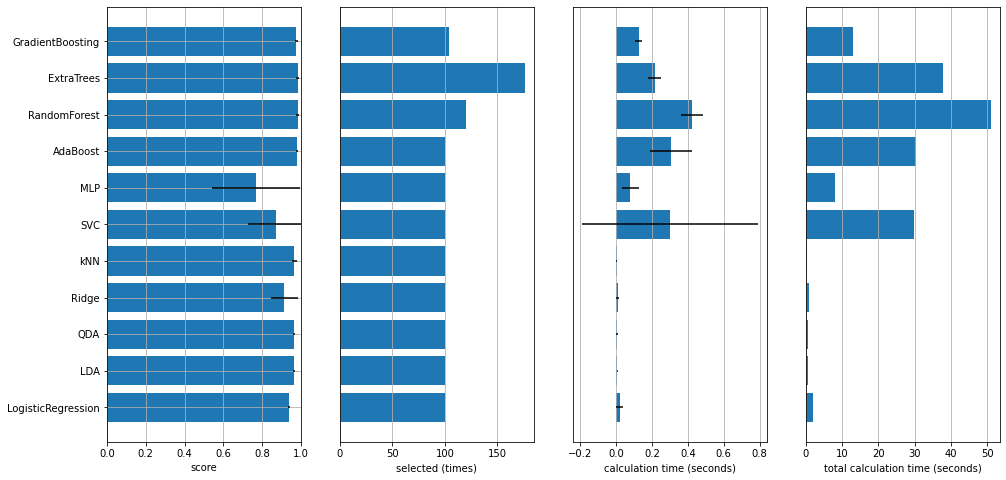
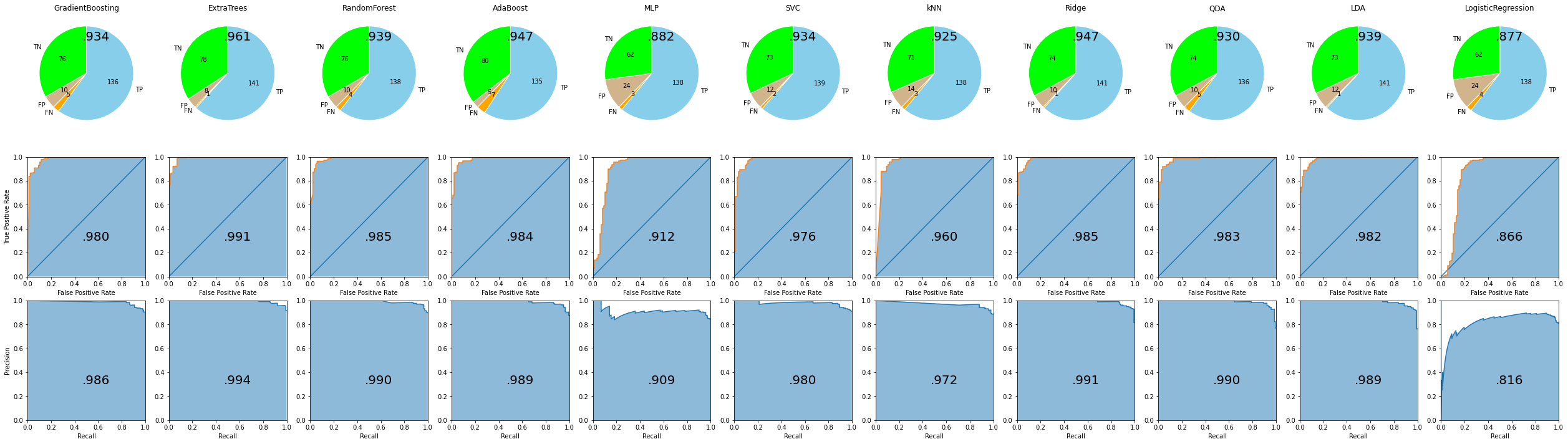
次のようにして、手法ごとのベストモデルの性能を確認できます。
depict.best_scores(allstars_model)
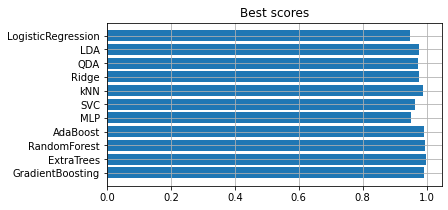
depict.all_metrics(allstars_model, X_train, y_train)
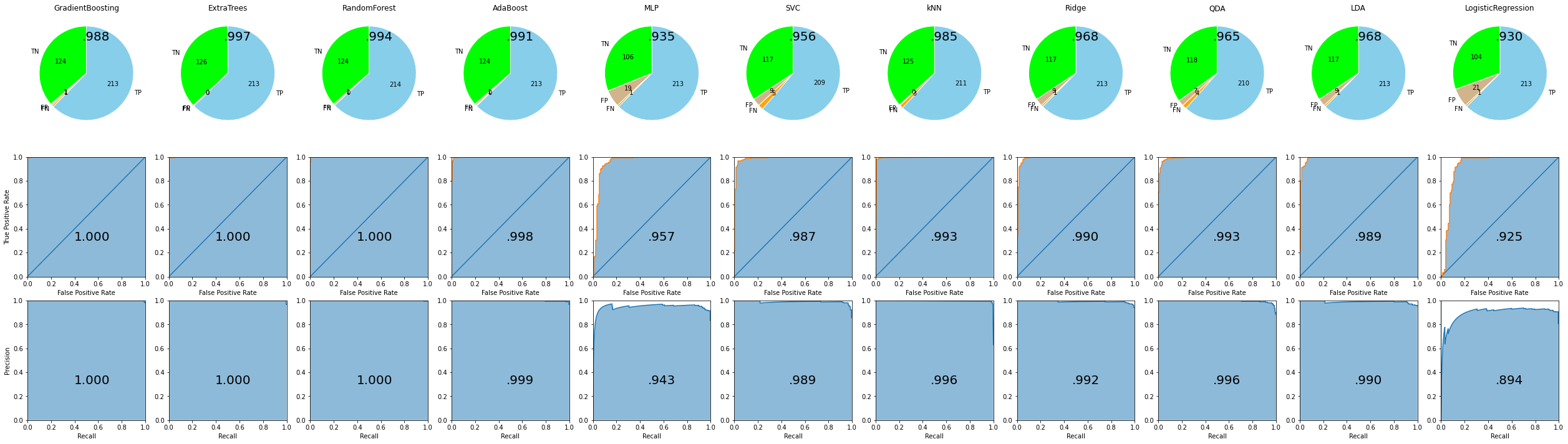
depict.all_metrics(allstars_model, X_test, y_test)
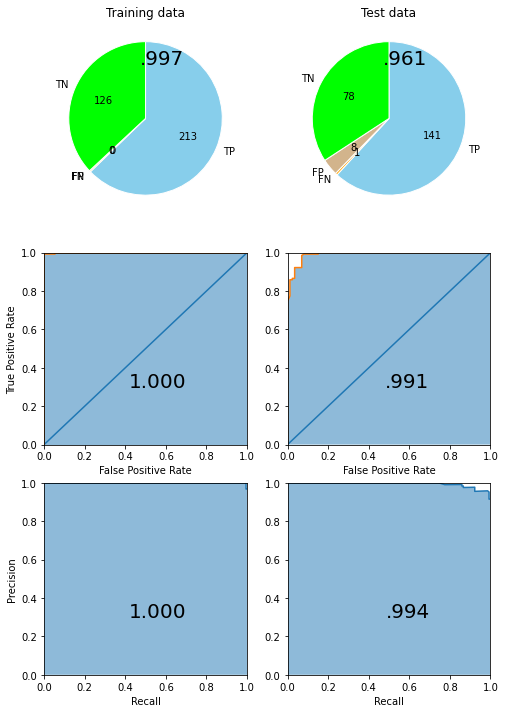
AllStarsモデル全体でのベストモデルの性能は次のようにして確認できます。
allstars_model.score(X_train, y_train), allstars_model.score(X_test, y_test)
(0.9976689976689977, 0.9690721649484537)
depict.metrics(allstars_model, X_train, y_train, X_test, y_test)
ベストモデルを用いた新規予測は次のようにして行えます。
allstars_model.predict(X_test)
array([1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0,
1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1,
1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1,
1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1,
1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1,
1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1])
スタッキングモデルの学習
上記のようにして学習した AllStars モデルを用いて、下記のようなコードでスタッキングモデルを組んでハイパラチューニングしながら学習することができます。
from scikitallstars import stacking
stacking_model = stacking.get_best_stacking(allstars_model, X_train, y_train, timeout=1000, n_trials=100)
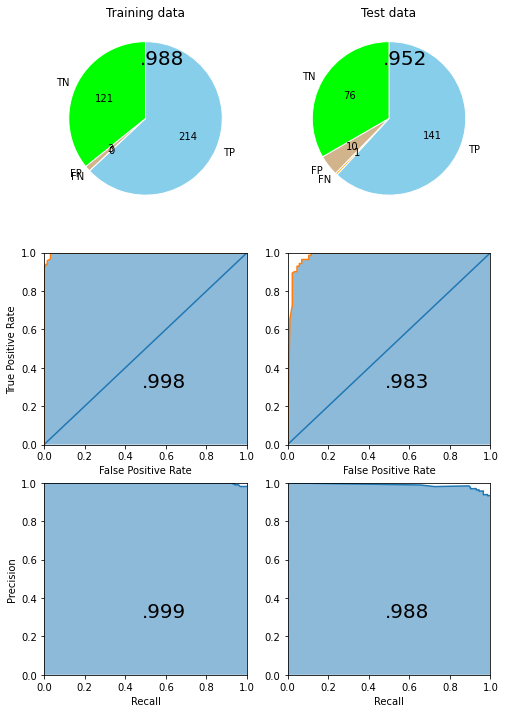
得られたスタッキングのベストモデルの性能は次のようにして確認できます。
stacking_model.score(X_train, y_train), stacking_model.score(X_test, y_test)
(0.9882697947214076, 0.9517543859649122)
depict.metrics(stacking_model, X_train, y_train, X_test, y_test)
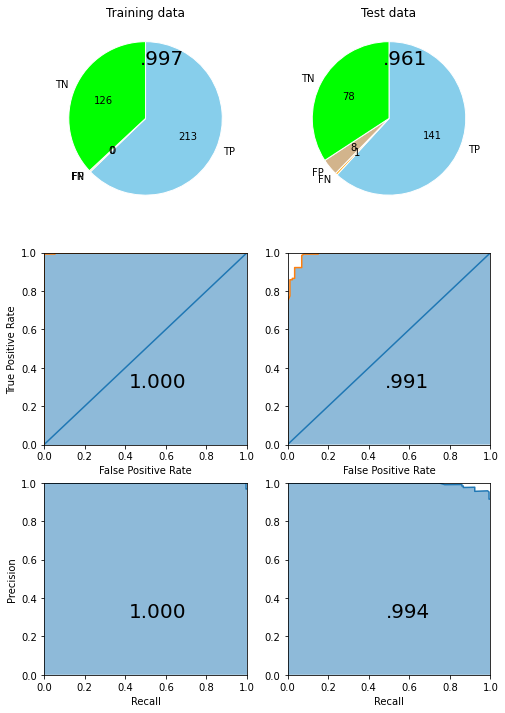
AllStarsベストモデルと比較してみましょう。
depict.metrics(allstars_model, X_train, y_train, X_test, y_test)
スタッキングのベストモデルにおける、各機械学習手法の重要度が次のようにして確認できます。
depict.model_importances(stacking_model)
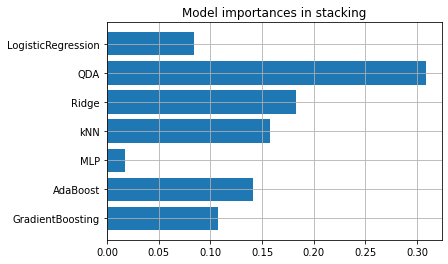
スタッキングのベストモデルによる新規予測は次のようにして得られます。
stacking_model.predict(X_test)
array([1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0,
1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1,
1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1,
1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1,
1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1,
1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1])
分類モデル、回帰モデルの切り替え
ScikitAllStars では、取り扱う問題が分類なのか回帰なのかという違いをほとんど意識せずに使える設計を心がけています。なぜって?めんどいからです。
上記のコードのうち、データの部分だけを次のように書き換えるだけで、自動的に「回帰問題」だと認識して回帰モデルを全部やっちゃってくれます。他の部分は書き換える必要がありません。
import sklearn.datasets
# dataset = sklearn.datasets.load_breast_cancer() # 分類用データ例
dataset = sklearn.datasets.load_diabetes() # 回帰用データ例
結果は省略。気になる方は、各自試してみてくださいね。
今後
細かい設定が色々あるんですが、最小限の動作は上記のコードを参考に行えると思います。詳しくは https://github.com/maskot1977/scikitallstars.git のコードを読んでみてください。