2016年に作った資料を公開します。もう既にいろいろ古くなってる可能性が高いです。
Jupyter Notebook (IPython Notebook) とは
-
Python という名のプログラミング言語が使えるプログラミング環境。計算コードと計算結果を同じ場所に時系列で保存できるので、実験系における実験ノートのように、いつどんな処理を行って何を得たのか記録して再現するのに便利。
-
本実習では、人工知能の一分野である「機械学習」のうち、サポートベクトルマシン(SVM: Support Vector Machine)を使います。
- 機械学習とは→ コンピューターに"学習"させる
- サポートベクターマシン ・ サポートベクターマシンとは
-
各自の画面中の IPython Notebook のセルに順次入力して(コピペ可)、「Shift + Enter」してください。
-
最後に、課題を解いてもらいます。課題の結果を、指定する方法で指定するメールアドレスまで送信してください。
import matplotlib.pyplot as plt # 図やグラフを図示するためのライブラリ
import pylab as pl # これも図やグラフを図示するためのライブラリ
# Jupyter Notebook 上で表示させるための呪文
%matplotlib inline
import urllib # URL によるリソースへのアクセスを提供するライブラリ
import random #乱数を発生させるライブラリ
import numpy as np # 数値計算ライブラリ
import pandas as pd # データフレームワーク処理のライブラリ
from pandas.tools import plotting # 高度なプロットを行うツールのインポート
# 機械学習のためのいろんなライブラリ
import sklearn.svm as svm
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import roc_curve, precision_recall_curve, auc, classification_report, confusion_matrix
from sklearn import cross_validation as cv
from sklearn import svm, grid_search, datasets
総合実験1日目でも用いたデータをまた使います。
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/iris.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
urllib.urlretrieve(url, 'iris.txt')
('iris.txt', <httplib.HTTPMessage instance at 0x116ed0908>)
とりあえずデータを確認するには、こんな方法もあります
# 先頭N行を表示する。カラムのタイトルも確認する。
pd.DataFrame(pd.read_csv('iris.txt', sep='\t', na_values=".")).head()
| Unnamed: 0 | Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
色分けした Scatter Matrix を描く
# "Species" 列の値を重複を除いて全てリストアップする。
print list(set(pd.read_csv('iris.txt', sep='\t', na_values=".")["Species"]))
['setosa', 'versicolor', 'virginica']
# それぞれに与える色を決める。
color_codes = {'setosa':'#00FF00', 'versicolor':'#FF0000', 'virginica':'#0000FF'}
# サンプル毎に色を与える。
colors = [color_codes[x] for x in list(pd.read_csv('iris.txt', sep='\t', na_values=".")["Species"])]
# 色分けした Scatter Matrix を描く。
df = pd.read_csv('iris.txt', sep='\t', na_values=".") # データの読み込み
plotting.scatter_matrix(df[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']], figsize=(10, 10), color=colors) #データのプロット
plt.show()
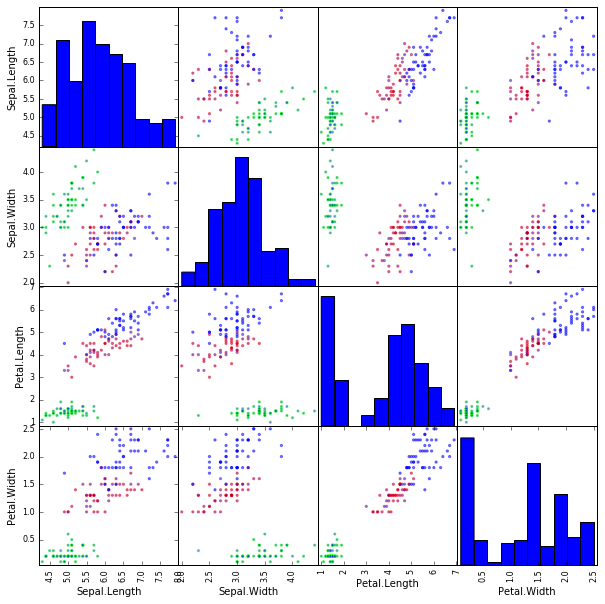
データの整形
Nをサンプル数、Mを特徴量の数とする。__data__から__target__を予測する問題を解く。
- feature_names : 特徴量の名前(M次元のベクトル)
- sample_names : サンプルの名前(N次元のベクトル)
- target_names : 目的変数の名前(N次元のベクトル)
- data : 説明変数(N行M列の行列)
- target : 目的変数(N次元のベクトル)
# 説明変数と目的変数に分ける。
data = []
target = []
feature_names = []
sample_names = []
target_names = []
for i, line in enumerate(open("iris.txt")):
a = line.replace("\n", "").split("\t")
if i == 0:
for j, word in enumerate(a):
if j == 0:
continue
elif j == len(a) - 1:
continue
else:
feature_names.append(word)
else:
vec = []
for j, word in enumerate(a):
if j == 0:
sample_names.append(word)
elif j == len(a) - 1:
word = word.strip()
if word not in target_names:
target_names.append(word)
target.append(target_names.index(word))
else:
vec.append(float(word))
data.append(vec)
# 名前の確認
print feature_names
print sample_names
print target_names
['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']
['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130', '131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144', '145', '146', '147', '148', '149', '150']
['setosa', 'versicolor', 'virginica']
# 説明変数の確認
print data
[[5.1, 3.5, 1.4, 0.2], [4.9, 3.0, 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2], [5.0, 3.6, 1.4, 0.2], [5.4, 3.9, 1.7, 0.4], [4.6, 3.4, 1.4, 0.3], [5.0, 3.4, 1.5, 0.2], [4.4, 2.9, 1.4, 0.2], [4.9, 3.1, 1.5, 0.1], [5.4, 3.7, 1.5, 0.2], [4.8, 3.4, 1.6, 0.2], [4.8, 3.0, 1.4, 0.1], [4.3, 3.0, 1.1, 0.1], [5.8, 4.0, 1.2, 0.2], [5.7, 4.4, 1.5, 0.4], [5.4, 3.9, 1.3, 0.4], [5.1, 3.5, 1.4, 0.3], [5.7, 3.8, 1.7, 0.3], [5.1, 3.8, 1.5, 0.3], [5.4, 3.4, 1.7, 0.2], [5.1, 3.7, 1.5, 0.4], [4.6, 3.6, 1.0, 0.2], [5.1, 3.3, 1.7, 0.5], [4.8, 3.4, 1.9, 0.2], [5.0, 3.0, 1.6, 0.2], [5.0, 3.4, 1.6, 0.4], [5.2, 3.5, 1.5, 0.2], [5.2, 3.4, 1.4, 0.2], [4.7, 3.2, 1.6, 0.2], [4.8, 3.1, 1.6, 0.2], [5.4, 3.4, 1.5, 0.4], [5.2, 4.1, 1.5, 0.1], [5.5, 4.2, 1.4, 0.2], [4.9, 3.1, 1.5, 0.2], [5.0, 3.2, 1.2, 0.2], [5.5, 3.5, 1.3, 0.2], [4.9, 3.6, 1.4, 0.1], [4.4, 3.0, 1.3, 0.2], [5.1, 3.4, 1.5, 0.2], [5.0, 3.5, 1.3, 0.3], [4.5, 2.3, 1.3, 0.3], [4.4, 3.2, 1.3, 0.2], [5.0, 3.5, 1.6, 0.6], [5.1, 3.8, 1.9, 0.4], [4.8, 3.0, 1.4, 0.3], [5.1, 3.8, 1.6, 0.2], [4.6, 3.2, 1.4, 0.2], [5.3, 3.7, 1.5, 0.2], [5.0, 3.3, 1.4, 0.2], [7.0, 3.2, 4.7, 1.4], [6.4, 3.2, 4.5, 1.5], [6.9, 3.1, 4.9, 1.5], [5.5, 2.3, 4.0, 1.3], [6.5, 2.8, 4.6, 1.5], [5.7, 2.8, 4.5, 1.3], [6.3, 3.3, 4.7, 1.6], [4.9, 2.4, 3.3, 1.0], [6.6, 2.9, 4.6, 1.3], [5.2, 2.7, 3.9, 1.4], [5.0, 2.0, 3.5, 1.0], [5.9, 3.0, 4.2, 1.5], [6.0, 2.2, 4.0, 1.0], [6.1, 2.9, 4.7, 1.4], [5.6, 2.9, 3.6, 1.3], [6.7, 3.1, 4.4, 1.4], [5.6, 3.0, 4.5, 1.5], [5.8, 2.7, 4.1, 1.0], [6.2, 2.2, 4.5, 1.5], [5.6, 2.5, 3.9, 1.1], [5.9, 3.2, 4.8, 1.8], [6.1, 2.8, 4.0, 1.3], [6.3, 2.5, 4.9, 1.5], [6.1, 2.8, 4.7, 1.2], [6.4, 2.9, 4.3, 1.3], [6.6, 3.0, 4.4, 1.4], [6.8, 2.8, 4.8, 1.4], [6.7, 3.0, 5.0, 1.7], [6.0, 2.9, 4.5, 1.5], [5.7, 2.6, 3.5, 1.0], [5.5, 2.4, 3.8, 1.1], [5.5, 2.4, 3.7, 1.0], [5.8, 2.7, 3.9, 1.2], [6.0, 2.7, 5.1, 1.6], [5.4, 3.0, 4.5, 1.5], [6.0, 3.4, 4.5, 1.6], [6.7, 3.1, 4.7, 1.5], [6.3, 2.3, 4.4, 1.3], [5.6, 3.0, 4.1, 1.3], [5.5, 2.5, 4.0, 1.3], [5.5, 2.6, 4.4, 1.2], [6.1, 3.0, 4.6, 1.4], [5.8, 2.6, 4.0, 1.2], [5.0, 2.3, 3.3, 1.0], [5.6, 2.7, 4.2, 1.3], [5.7, 3.0, 4.2, 1.2], [5.7, 2.9, 4.2, 1.3], [6.2, 2.9, 4.3, 1.3], [5.1, 2.5, 3.0, 1.1], [5.7, 2.8, 4.1, 1.3], [6.3, 3.3, 6.0, 2.5], [5.8, 2.7, 5.1, 1.9], [7.1, 3.0, 5.9, 2.1], [6.3, 2.9, 5.6, 1.8], [6.5, 3.0, 5.8, 2.2], [7.6, 3.0, 6.6, 2.1], [4.9, 2.5, 4.5, 1.7], [7.3, 2.9, 6.3, 1.8], [6.7, 2.5, 5.8, 1.8], [7.2, 3.6, 6.1, 2.5], [6.5, 3.2, 5.1, 2.0], [6.4, 2.7, 5.3, 1.9], [6.8, 3.0, 5.5, 2.1], [5.7, 2.5, 5.0, 2.0], [5.8, 2.8, 5.1, 2.4], [6.4, 3.2, 5.3, 2.3], [6.5, 3.0, 5.5, 1.8], [7.7, 3.8, 6.7, 2.2], [7.7, 2.6, 6.9, 2.3], [6.0, 2.2, 5.0, 1.5], [6.9, 3.2, 5.7, 2.3], [5.6, 2.8, 4.9, 2.0], [7.7, 2.8, 6.7, 2.0], [6.3, 2.7, 4.9, 1.8], [6.7, 3.3, 5.7, 2.1], [7.2, 3.2, 6.0, 1.8], [6.2, 2.8, 4.8, 1.8], [6.1, 3.0, 4.9, 1.8], [6.4, 2.8, 5.6, 2.1], [7.2, 3.0, 5.8, 1.6], [7.4, 2.8, 6.1, 1.9], [7.9, 3.8, 6.4, 2.0], [6.4, 2.8, 5.6, 2.2], [6.3, 2.8, 5.1, 1.5], [6.1, 2.6, 5.6, 1.4], [7.7, 3.0, 6.1, 2.3], [6.3, 3.4, 5.6, 2.4], [6.4, 3.1, 5.5, 1.8], [6.0, 3.0, 4.8, 1.8], [6.9, 3.1, 5.4, 2.1], [6.7, 3.1, 5.6, 2.4], [6.9, 3.1, 5.1, 2.3], [5.8, 2.7, 5.1, 1.9], [6.8, 3.2, 5.9, 2.3], [6.7, 3.3, 5.7, 2.5], [6.7, 3.0, 5.2, 2.3], [6.3, 2.5, 5.0, 1.9], [6.5, 3.0, 5.2, 2.0], [6.2, 3.4, 5.4, 2.3], [5.9, 3.0, 5.1, 1.8]]
# 目的変数の確認
print target
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
データのシャッフル
- 今のままだと、同じ目的変数同士でサンプルが固まっているので、サンプルの順番をランダムに入れ替えます。
# データをシャッフルする
p = range(len(sample_names)) # Python 2 の場合
# p = list(range(len(sample_names))) # Python 3 の場合
random.seed(0)
random.shuffle(p)
sample_names = list(np.array(sample_names)[p])
data = np.array(data)[p]
target = list(np.array(target)[p])
# シャッフル後のデータを確認
print sample_names
['137', '29', '14', '142', '99', '138', '111', '125', '118', '40', '80', '91', '9', '70', '4', '139', '101', '55', '30', '17', '23', '3', '130', '135', '26', '61', '120', '108', '78', '73', '121', '21', '110', '100', '19', '33', '22', '115', '28', '144', '150', '143', '79', '105', '10', '6', '133', '12', '42', '69', '102', '114', '5', '43', '77', '62', '88', '72', '106', '90', '36', '56', '109', '134', '18', '47', '132', '123', '140', '148', '126', '67', '65', '57', '7', '37', '84', '82', '15', '16', '24', '48', '97', '86', '38', '51', '53', '136', '96', '74', '50', '66', '52', '11', '89', '49', '32', '8', '45', '81', '98', '25', '145', '20', '92', '35', '27', '94', '124', '1', '146', '93', '46', '141', '2', '64', '129', '31', '103', '58', '117', '112', '76', '54', '13', '60', '87', '116', '95', '41', '119', '107', '131', '122', '34', '85', '104', '147', '71', '128', '83', '68', '44', '149', '59', '75', '39', '63', '113', '127']
# シャッフル後のデータを確認
print data
[[ 6.3 3.4 5.6 2.4]
[ 5.2 3.4 1.4 0.2]
[ 4.3 3. 1.1 0.1]
[ 6.9 3.1 5.1 2.3]
[ 5.1 2.5 3. 1.1]
[ 6.4 3.1 5.5 1.8]
[ 6.5 3.2 5.1 2. ]
[ 6.7 3.3 5.7 2.1]
[ 7.7 3.8 6.7 2.2]
[ 5.1 3.4 1.5 0.2]
[ 5.7 2.6 3.5 1. ]
[ 5.5 2.6 4.4 1.2]
[ 4.4 2.9 1.4 0.2]
[ 5.6 2.5 3.9 1.1]
[ 4.6 3.1 1.5 0.2]
[ 6. 3. 4.8 1.8]
[ 6.3 3.3 6. 2.5]
[ 6.5 2.8 4.6 1.5]
[ 4.7 3.2 1.6 0.2]
[ 5.4 3.9 1.3 0.4]
[ 4.6 3.6 1. 0.2]
[ 4.7 3.2 1.3 0.2]
[ 7.2 3. 5.8 1.6]
[ 6.1 2.6 5.6 1.4]
[ 5. 3. 1.6 0.2]
[ 5. 2. 3.5 1. ]
[ 6. 2.2 5. 1.5]
[ 7.3 2.9 6.3 1.8]
[ 6.7 3. 5. 1.7]
[ 6.3 2.5 4.9 1.5]
[ 6.9 3.2 5.7 2.3]
[ 5.4 3.4 1.7 0.2]
[ 7.2 3.6 6.1 2.5]
[ 5.7 2.8 4.1 1.3]
[ 5.7 3.8 1.7 0.3]
[ 5.2 4.1 1.5 0.1]
[ 5.1 3.7 1.5 0.4]
[ 5.8 2.8 5.1 2.4]
[ 5.2 3.5 1.5 0.2]
[ 6.8 3.2 5.9 2.3]
[ 5.9 3. 5.1 1.8]
[ 5.8 2.7 5.1 1.9]
[ 6. 2.9 4.5 1.5]
[ 6.5 3. 5.8 2.2]
[ 4.9 3.1 1.5 0.1]
[ 5.4 3.9 1.7 0.4]
[ 6.4 2.8 5.6 2.2]
[ 4.8 3.4 1.6 0.2]
[ 4.5 2.3 1.3 0.3]
[ 6.2 2.2 4.5 1.5]
[ 5.8 2.7 5.1 1.9]
[ 5.7 2.5 5. 2. ]
[ 5. 3.6 1.4 0.2]
[ 4.4 3.2 1.3 0.2]
[ 6.8 2.8 4.8 1.4]
[ 5.9 3. 4.2 1.5]
[ 6.3 2.3 4.4 1.3]
[ 6.1 2.8 4. 1.3]
[ 7.6 3. 6.6 2.1]
[ 5.5 2.5 4. 1.3]
[ 5. 3.2 1.2 0.2]
[ 5.7 2.8 4.5 1.3]
[ 6.7 2.5 5.8 1.8]
[ 6.3 2.8 5.1 1.5]
[ 5.1 3.5 1.4 0.3]
[ 5.1 3.8 1.6 0.2]
[ 7.9 3.8 6.4 2. ]
[ 7.7 2.8 6.7 2. ]
[ 6.9 3.1 5.4 2.1]
[ 6.5 3. 5.2 2. ]
[ 7.2 3.2 6. 1.8]
[ 5.6 3. 4.5 1.5]
[ 5.6 2.9 3.6 1.3]
[ 6.3 3.3 4.7 1.6]
[ 4.6 3.4 1.4 0.3]
[ 5.5 3.5 1.3 0.2]
[ 6. 2.7 5.1 1.6]
[ 5.5 2.4 3.7 1. ]
[ 5.8 4. 1.2 0.2]
[ 5.7 4.4 1.5 0.4]
[ 5.1 3.3 1.7 0.5]
[ 4.6 3.2 1.4 0.2]
[ 5.7 2.9 4.2 1.3]
[ 6. 3.4 4.5 1.6]
[ 4.9 3.6 1.4 0.1]
[ 7. 3.2 4.7 1.4]
[ 6.9 3.1 4.9 1.5]
[ 7.7 3. 6.1 2.3]
[ 5.7 3. 4.2 1.2]
[ 6.1 2.8 4.7 1.2]
[ 5. 3.3 1.4 0.2]
[ 6.7 3.1 4.4 1.4]
[ 6.4 3.2 4.5 1.5]
[ 5.4 3.7 1.5 0.2]
[ 5.6 3. 4.1 1.3]
[ 5.3 3.7 1.5 0.2]
[ 5.4 3.4 1.5 0.4]
[ 5. 3.4 1.5 0.2]
[ 5.1 3.8 1.9 0.4]
[ 5.5 2.4 3.8 1.1]
[ 6.2 2.9 4.3 1.3]
[ 4.8 3.4 1.9 0.2]
[ 6.7 3.3 5.7 2.5]
[ 5.1 3.8 1.5 0.3]
[ 6.1 3. 4.6 1.4]
[ 4.9 3.1 1.5 0.2]
[ 5. 3.4 1.6 0.4]
[ 5. 2.3 3.3 1. ]
[ 6.3 2.7 4.9 1.8]
[ 5.1 3.5 1.4 0.2]
[ 6.7 3. 5.2 2.3]
[ 5.8 2.6 4. 1.2]
[ 4.8 3. 1.4 0.3]
[ 6.7 3.1 5.6 2.4]
[ 4.9 3. 1.4 0.2]
[ 6.1 2.9 4.7 1.4]
[ 6.4 2.8 5.6 2.1]
[ 4.8 3.1 1.6 0.2]
[ 7.1 3. 5.9 2.1]
[ 4.9 2.4 3.3 1. ]
[ 6.5 3. 5.5 1.8]
[ 6.4 2.7 5.3 1.9]
[ 6.6 3. 4.4 1.4]
[ 5.5 2.3 4. 1.3]
[ 4.8 3. 1.4 0.1]
[ 5.2 2.7 3.9 1.4]
[ 6.7 3.1 4.7 1.5]
[ 6.4 3.2 5.3 2.3]
[ 5.6 2.7 4.2 1.3]
[ 5. 3.5 1.3 0.3]
[ 7.7 2.6 6.9 2.3]
[ 4.9 2.5 4.5 1.7]
[ 7.4 2.8 6.1 1.9]
[ 5.6 2.8 4.9 2. ]
[ 5.5 4.2 1.4 0.2]
[ 5.4 3. 4.5 1.5]
[ 6.3 2.9 5.6 1.8]
[ 6.3 2.5 5. 1.9]
[ 5.9 3.2 4.8 1.8]
[ 6.1 3. 4.9 1.8]
[ 5.8 2.7 3.9 1.2]
[ 5.8 2.7 4.1 1. ]
[ 5. 3.5 1.6 0.6]
[ 6.2 3.4 5.4 2.3]
[ 6.6 2.9 4.6 1.3]
[ 6.4 2.9 4.3 1.3]
[ 4.4 3. 1.3 0.2]
[ 6. 2.2 4. 1. ]
[ 6.8 3. 5.5 2.1]
[ 6.2 2.8 4.8 1.8]]
# シャッフル後のデータを確認
print target
[2, 0, 0, 2, 1, 2, 2, 2, 2, 0, 1, 1, 0, 1, 0, 2, 2, 1, 0, 0, 0, 0, 2, 2, 0, 1, 2, 2, 1, 1, 2, 0, 2, 1, 0, 0, 0, 2, 0, 2, 2, 2, 1, 2, 0, 0, 2, 0, 0, 1, 2, 2, 0, 0, 1, 1, 1, 1, 2, 1, 0, 1, 2, 2, 0, 0, 2, 2, 2, 2, 2, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 2, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 2, 0, 1, 0, 0, 1, 2, 0, 2, 1, 0, 2, 0, 1, 2, 0, 2, 1, 2, 2, 1, 1, 0, 1, 1, 2, 1, 0, 2, 2, 2, 2, 0, 1, 2, 2, 1, 2, 1, 1, 0, 2, 1, 1, 0, 1, 2, 2]
データの分割
交差検定をするため、データを学習用とテスト用に分割します。
- data_train : 説明変数(学習用)
- data_test : 説明変数(テスト用)
- target_train : 目的変数(学習用)
- target_test : 目的変数(テスト用)
交差検定 (cross-validation) とは → 交差検定
- 現在取得できているデータを「学習用」と「テスト用」に分け、「学習用」だけを使って予測モデルを構築し、「評価用」を使ってモデルの性能を評価する。
# データを分割。test_size=0.8 は、学習:テスト のデータ量比が 2:8 であることを指す。
data_train, data_test, target_train, target_test, sample_names_train, sample_names_test = train_test_split(
data, target, sample_names, test_size=0.8, random_state=0)
# 分割後のデータの確認(学習用)
print sample_names_train
print target_train
print data_train
['4', '76', '17', '73', '119', '69', '104', '81', '97', '16', '64', '75', '65', '82', '61', '48', '83', '44', '144', '106', '96', '126', '136', '22', '3', '40', '20', '123', '31', '12']
[0, 1, 0, 1, 2, 1, 2, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 2, 2, 1, 2, 2, 0, 0, 0, 0, 2, 0, 0]
[[ 4.6 3.1 1.5 0.2]
[ 6.6 3. 4.4 1.4]
[ 5.4 3.9 1.3 0.4]
[ 6.3 2.5 4.9 1.5]
[ 7.7 2.6 6.9 2.3]
[ 6.2 2.2 4.5 1.5]
[ 6.3 2.9 5.6 1.8]
[ 5.5 2.4 3.8 1.1]
[ 5.7 2.9 4.2 1.3]
[ 5.7 4.4 1.5 0.4]
[ 6.1 2.9 4.7 1.4]
[ 6.4 2.9 4.3 1.3]
[ 5.6 2.9 3.6 1.3]
[ 5.5 2.4 3.7 1. ]
[ 5. 2. 3.5 1. ]
[ 4.6 3.2 1.4 0.2]
[ 5.8 2.7 3.9 1.2]
[ 5. 3.5 1.6 0.6]
[ 6.8 3.2 5.9 2.3]
[ 7.6 3. 6.6 2.1]
[ 5.7 3. 4.2 1.2]
[ 7.2 3.2 6. 1.8]
[ 7.7 3. 6.1 2.3]
[ 5.1 3.7 1.5 0.4]
[ 4.7 3.2 1.3 0.2]
[ 5.1 3.4 1.5 0.2]
[ 5.1 3.8 1.5 0.3]
[ 7.7 2.8 6.7 2. ]
[ 4.8 3.1 1.6 0.2]
[ 4.8 3.4 1.6 0.2]]
# 分割後のデータの確認(テスト用)
print sample_names_test
print target_test
print data_test
['2', '109', '100', '94', '125', '98', '150', '53', '84', '67', '34', '114', '57', '77', '134', '115', '15', '50', '6', '101', '112', '132', '26', '118', '87', '130', '10', '8', '11', '120', '147', '38', '108', '116', '131', '90', '30', '86', '56', '52', '46', '14', '68', '105', '80', '36', '129', '59', '58', '124', '148', '85', '88', '24', '54', '122', '27', '39', '102', '63', '51', '121', '25', '89', '18', '74', '66', '60', '42', '70', '93', '49', '23', '139', '5', '142', '127', '45', '111', '140', '1', '32', '9', '145', '117', '92', '95', '133', '91', '146', '13', '143', '113', '29', '141', '128', '79', '99', '41', '55', '28', '138', '43', '149', '35', '137', '19', '78', '62', '37', '33', '135', '7', '21', '103', '72', '107', '47', '110', '71']
[0, 2, 1, 1, 2, 1, 2, 1, 1, 1, 0, 2, 1, 1, 2, 2, 0, 0, 0, 2, 2, 2, 0, 2, 1, 2, 0, 0, 0, 2, 2, 0, 2, 2, 2, 1, 0, 1, 1, 1, 0, 0, 1, 2, 1, 0, 2, 1, 1, 2, 2, 1, 1, 0, 1, 2, 0, 0, 2, 1, 1, 2, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 2, 0, 2, 2, 0, 2, 2, 0, 0, 0, 2, 2, 1, 1, 2, 1, 2, 0, 2, 2, 0, 2, 2, 1, 1, 0, 1, 0, 2, 0, 2, 0, 2, 0, 1, 1, 0, 0, 2, 0, 0, 2, 1, 2, 0, 2, 1]
[[ 4.9 3. 1.4 0.2]
[ 6.7 2.5 5.8 1.8]
[ 5.7 2.8 4.1 1.3]
[ 5. 2.3 3.3 1. ]
[ 6.7 3.3 5.7 2.1]
[ 6.2 2.9 4.3 1.3]
[ 5.9 3. 5.1 1.8]
[ 6.9 3.1 4.9 1.5]
[ 6. 2.7 5.1 1.6]
[ 5.6 3. 4.5 1.5]
[ 5.5 4.2 1.4 0.2]
[ 5.7 2.5 5. 2. ]
[ 6.3 3.3 4.7 1.6]
[ 6.8 2.8 4.8 1.4]
[ 6.3 2.8 5.1 1.5]
[ 5.8 2.8 5.1 2.4]
[ 5.8 4. 1.2 0.2]
[ 5. 3.3 1.4 0.2]
[ 5.4 3.9 1.7 0.4]
[ 6.3 3.3 6. 2.5]
[ 6.4 2.7 5.3 1.9]
[ 7.9 3.8 6.4 2. ]
[ 5. 3. 1.6 0.2]
[ 7.7 3.8 6.7 2.2]
[ 6.7 3.1 4.7 1.5]
[ 7.2 3. 5.8 1.6]
[ 4.9 3.1 1.5 0.1]
[ 5. 3.4 1.5 0.2]
[ 5.4 3.7 1.5 0.2]
[ 6. 2.2 5. 1.5]
[ 6.3 2.5 5. 1.9]
[ 4.9 3.6 1.4 0.1]
[ 7.3 2.9 6.3 1.8]
[ 6.4 3.2 5.3 2.3]
[ 7.4 2.8 6.1 1.9]
[ 5.5 2.5 4. 1.3]
[ 4.7 3.2 1.6 0.2]
[ 6. 3.4 4.5 1.6]
[ 5.7 2.8 4.5 1.3]
[ 6.4 3.2 4.5 1.5]
[ 4.8 3. 1.4 0.3]
[ 4.3 3. 1.1 0.1]
[ 5.8 2.7 4.1 1. ]
[ 6.5 3. 5.8 2.2]
[ 5.7 2.6 3.5 1. ]
[ 5. 3.2 1.2 0.2]
[ 6.4 2.8 5.6 2.1]
[ 6.6 2.9 4.6 1.3]
[ 4.9 2.4 3.3 1. ]
[ 6.3 2.7 4.9 1.8]
[ 6.5 3. 5.2 2. ]
[ 5.4 3. 4.5 1.5]
[ 6.3 2.3 4.4 1.3]
[ 5.1 3.3 1.7 0.5]
[ 5.5 2.3 4. 1.3]
[ 5.6 2.8 4.9 2. ]
[ 5. 3.4 1.6 0.4]
[ 4.4 3. 1.3 0.2]
[ 5.8 2.7 5.1 1.9]
[ 6. 2.2 4. 1. ]
[ 7. 3.2 4.7 1.4]
[ 6.9 3.2 5.7 2.3]
[ 4.8 3.4 1.9 0.2]
[ 5.6 3. 4.1 1.3]
[ 5.1 3.5 1.4 0.3]
[ 6.1 2.8 4.7 1.2]
[ 6.7 3.1 4.4 1.4]
[ 5.2 2.7 3.9 1.4]
[ 4.5 2.3 1.3 0.3]
[ 5.6 2.5 3.9 1.1]
[ 5.8 2.6 4. 1.2]
[ 5.3 3.7 1.5 0.2]
[ 4.6 3.6 1. 0.2]
[ 6. 3. 4.8 1.8]
[ 5. 3.6 1.4 0.2]
[ 6.9 3.1 5.1 2.3]
[ 6.2 2.8 4.8 1.8]
[ 5.1 3.8 1.9 0.4]
[ 6.5 3.2 5.1 2. ]
[ 6.9 3.1 5.4 2.1]
[ 5.1 3.5 1.4 0.2]
[ 5.4 3.4 1.5 0.4]
[ 4.4 2.9 1.4 0.2]
[ 6.7 3.3 5.7 2.5]
[ 6.5 3. 5.5 1.8]
[ 6.1 3. 4.6 1.4]
[ 5.6 2.7 4.2 1.3]
[ 6.4 2.8 5.6 2.2]
[ 5.5 2.6 4.4 1.2]
[ 6.7 3. 5.2 2.3]
[ 4.8 3. 1.4 0.1]
[ 5.8 2.7 5.1 1.9]
[ 6.8 3. 5.5 2.1]
[ 5.2 3.4 1.4 0.2]
[ 6.7 3.1 5.6 2.4]
[ 6.1 3. 4.9 1.8]
[ 6. 2.9 4.5 1.5]
[ 5.1 2.5 3. 1.1]
[ 5. 3.5 1.3 0.3]
[ 6.5 2.8 4.6 1.5]
[ 5.2 3.5 1.5 0.2]
[ 6.4 3.1 5.5 1.8]
[ 4.4 3.2 1.3 0.2]
[ 6.2 3.4 5.4 2.3]
[ 4.9 3.1 1.5 0.2]
[ 6.3 3.4 5.6 2.4]
[ 5.7 3.8 1.7 0.3]
[ 6.7 3. 5. 1.7]
[ 5.9 3. 4.2 1.5]
[ 5.5 3.5 1.3 0.2]
[ 5.2 4.1 1.5 0.1]
[ 6.1 2.6 5.6 1.4]
[ 4.6 3.4 1.4 0.3]
[ 5.4 3.4 1.7 0.2]
[ 7.1 3. 5.9 2.1]
[ 6.1 2.8 4. 1.3]
[ 4.9 2.5 4.5 1.7]
[ 5.1 3.8 1.6 0.2]
[ 7.2 3.6 6.1 2.5]
[ 5.9 3.2 4.8 1.8]]
SVMで学習・予測
学習用データ( data_train と target_train ) の関係を学習して、テスト用データ( data_test )から正解( target_test ) を予測する、という流れになります。
# Linear SVM で学習・予測
classifier = svm.SVC(kernel='linear', probability=True)
# probas = classifier.fit(data_train, target_train).predict_proba(data_test)
pred = classifier.fit(data_train, target_train).predict(data_test)
# 予測結果
pd.DataFrame(pred).T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 1 | 0 | 0 | 2 | 1 | 1 | 0 | 2 | 1 |
1 rows × 120 columns
# 正解
pd.DataFrame(target_test).T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 1 | ... | 0 | 2 | 0 | 0 | 2 | 1 | 2 | 0 | 2 | 1 |
1 rows × 120 columns
予測モデルの評価
性能評価の指標はたくさんありますが、とりあえず以下の5つは覚えておいてください。
- 正解率 (Accuracy) = (TP + TN) / (TP + FP + FN + TN)
- 適合率 (Precision) = TP / (TP + FP)
- 再現率 (Recall) = TP / (TP + FN)
- 特異度 (Specificity) = TN / (TN + FP)
- F値 (F-measure) = 2 x Precision x Recall / (Precision + Recall)
参考資料は右記→ モデルの評価
混同行列 (confusion matrix)
データの分類で、うまくできた・できなかった回数を数えた表
# 予測と正解の比較。第一引数が行、第二引数が列を表す。
pd.DataFrame(confusion_matrix(pred, target_test))
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 39 | 0 | 0 |
| 1 | 0 | 38 | 18 |
| 2 | 0 | 0 | 25 |
正解率 (Accuracy) の計算
# cv=5 で5分割クロスバリデーションし精度を計算
score=cv.cross_val_score(classifier,data,target,cv=5,n_jobs=-1)
print("Accuracy: {0:04.4f} (+/- {1:04.4f})".format(score.mean(),score.std()))
Accuracy: 0.9667 (+/- 0.0365)
AUPRスコア と AUCスコア
性能評価によく使われるのがAUPRスコアとAUCスコア
- AUPRスコア : Precision-Recallカーブ下の面積。 → Precision-Recallカーブの例
- AUCスコア : ROCカーブ下の面積。→ ROC曲線・ROC曲線
# AUPR や AUC スコアを出そうと思ったらターゲットをバイナリ(二値)にしないといけないっぽい。
# そこで、ラベルが2のものを無視して、ラベル0のものとラベル1のものを区別する。
data2 = []
target2 = []
for da, ta in zip(data, target):
if ta == 2:
continue
data2.append(da)
target2.append(ta)
# 二値になっていることを確認
print target2
[0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1]
# データをシャッフル
p = range(len(data2))
random.seed(0)
random.shuffle(p)
sample_names = list(np.array(sample_names)[p])
data2 = np.array(data2)[p]
target2 = list(np.array(target2)[p])
# データを分割。test_size=0.8 は、学習:テスト のデータ量比が 2:8 であることを指す。
data_train, data_test, target_train, target_test, sample_names_train, sample_names_test = train_test_split(
data2, target2, sample_names, test_size=0.8, random_state=0)
# Linear SVM で学習・予測
classifier = svm.SVC(kernel='linear', probability=True)
probas = classifier.fit(data_train, target_train).predict_proba(data_test)
pred = classifier.fit(data_train, target_train).predict(data_test)
# AUPR score を出す。ラベル0とラベル1の区別は簡単
precision, recall, thresholds = precision_recall_curve(target_test, probas[:, 1])
area = auc(recall, precision)
print "AUPR score: %0.2f" % area
AUPR score: 1.00
# AUC scoreを出す。ラベル0とラベル1の区別は簡単
fpr, tpr, thresholds = roc_curve(target_test, probas[:, 1])
roc_auc = auc(fpr, tpr)
print "AUC score: %f" % roc_auc
AUC score: 1.000000
予測が簡単すぎてツマラナイので、もう少し難しくします。
# ラベルが0のものを無視して、ラベル1のものとラベル2のものを区別する。
# ラベルはバイナリ(0か1)でないといけないので、ここでは1のものを0と呼び、2のものを1と呼ぶように変換する。
data2 = []
target2 = []
for da, ta in zip(data, target):
if ta == 0:
continue
data2.append(da)
target2.append(ta - 1)
# データをシャッフル
p = range(len(data2))
random.seed(0)
random.shuffle(p)
shuffled_sample_names = list(np.array(sample_names)[p])
shuffled_data = np.array(data2)[p]
shuffled_target = list(np.array(target2)[p])
# データを分割。test_size=0.8 は、学習:テスト のデータ量比が 2:8 であることを指す。
data_train, data_test, target_train, target_test, sample_names_train, sample_names_test = train_test_split(
data2, target2, sample_names, test_size=0.8, random_state=0)
# Linear SVM で学習・予測
classifier = svm.SVC(kernel='linear', probability=True)
probas = classifier.fit(data_train, target_train).predict_proba(data_test)
pred = classifier.fit(data_train, target_train).predict(data_test)
# AUPRスコアを出す
precision, recall, thresholds = precision_recall_curve(target_test, probas[:, 1])
area = auc(recall, precision)
print "AUPR score: %0.2f" % area
AUPR score: 0.99
# AUCスコアを出す。
fpr, tpr, thresholds = roc_curve(target_test, probas[:, 1])
roc_auc = auc(fpr, tpr)
print "ROC score : %f" % roc_auc
ROC score : 0.988743
# PR curve を描く
pl.clf()
pl.plot(recall, precision, label='Precision-Recall curve')
pl.xlabel('Recall')
pl.ylabel('Precision')
pl.ylim([0.0, 1.05])
pl.xlim([0.0, 1.0])
pl.title('Precision-Recall example: AUPR=%0.2f' % area)
pl.legend(loc="lower left")
pl.show()
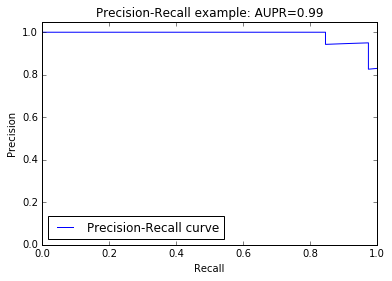
# ROC curve を描く
pl.clf()
pl.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
pl.plot([0, 1], [0, 1], 'k--')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('Receiver operating characteristic example')
pl.legend(loc="lower right")
pl.show()
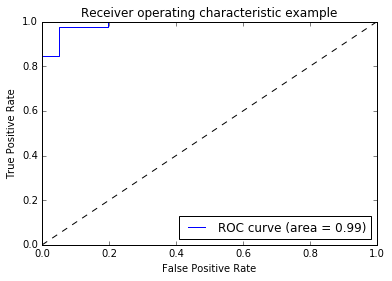
まだ予測が簡単すぎてツマラナイので、さらに難しくします。
# 予測を難しくするため、不要な特徴量(ノイズ)を加える
np.random.seed(0)
data2 = np.c_[data2, np.random.randn(len(target2), 96)]
# 新しいデータを確認。
# 左の4列は元々のデータにあった数字なので、正しい分類に使える数字のはず。
# 右の96列はランダムなノイズなので、正しい分類には使えない数字のはず。
pd.DataFrame(data2)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6.3 | 3.4 | 5.6 | 2.4 | 1.764052 | 0.400157 | 0.978738 | 2.240893 | 1.867558 | -0.977278 | ... | 1.178780 | -0.179925 | -1.070753 | 1.054452 | -0.403177 | 1.222445 | 0.208275 | 0.976639 | 0.356366 | 0.706573 |
| 1 | 6.9 | 3.1 | 5.1 | 2.3 | 0.010500 | 1.785870 | 0.126912 | 0.401989 | 1.883151 | -1.347759 | ... | -0.643618 | -2.223403 | 0.625231 | -1.602058 | -1.104383 | 0.052165 | -0.739563 | 1.543015 | -1.292857 | 0.267051 |
| 2 | 5.1 | 2.5 | 3.0 | 1.1 | -0.039283 | -1.168093 | 0.523277 | -0.171546 | 0.771791 | 0.823504 | ... | -2.030684 | 2.064493 | -0.110541 | 1.020173 | -0.692050 | 1.536377 | 0.286344 | 0.608844 | -1.045253 | 1.211145 |
| 3 | 6.4 | 3.1 | 5.5 | 1.8 | 0.689818 | 1.301846 | -0.628088 | -0.481027 | 2.303917 | -1.060016 | ... | 0.049495 | 0.493837 | 0.643314 | -1.570623 | -0.206904 | 0.880179 | -1.698106 | 0.387280 | -2.255564 | -1.022507 |
| 4 | 6.5 | 3.2 | 5.1 | 2.0 | 0.038631 | -1.656715 | -0.985511 | -1.471835 | 1.648135 | 0.164228 | ... | -2.016407 | -0.539455 | -0.275671 | -0.709728 | 1.738873 | 0.994394 | 1.319137 | -0.882419 | 1.128594 | 0.496001 |
| 5 | 6.7 | 3.3 | 5.7 | 2.1 | 0.771406 | 1.029439 | -0.908763 | -0.424318 | 0.862596 | -2.655619 | ... | 0.354758 | 0.616887 | 0.008628 | 0.527004 | 0.453782 | -1.829740 | 0.037006 | 0.767902 | 0.589880 | -0.363859 |
| 6 | 7.7 | 3.8 | 6.7 | 2.2 | -0.805627 | -1.118312 | -0.131054 | 1.133080 | -1.951804 | -0.659892 | ... | 0.452489 | 0.097896 | -0.448165 | -0.649338 | -0.023423 | 1.079195 | -2.004216 | 0.376877 | -0.545712 | -1.884586 |
| 7 | 5.7 | 2.6 | 3.5 | 1.0 | -1.945703 | -0.912783 | 0.219510 | 0.393063 | -0.938982 | 1.017021 | ... | 0.039767 | -1.566995 | -0.451303 | 0.265688 | 0.723100 | 0.024612 | 0.719984 | -1.102906 | -0.101697 | 0.019279 |
| 8 | 5.5 | 2.6 | 4.4 | 1.2 | 1.849591 | -0.214167 | -0.499017 | 0.021351 | -0.919113 | 0.192754 | ... | -1.032643 | -0.436748 | -1.642965 | -0.406072 | -0.535270 | 0.025405 | 1.154184 | 0.172504 | 0.021062 | 0.099454 |
| 9 | 5.6 | 2.5 | 3.9 | 1.1 | 0.227393 | -1.016739 | -0.114775 | 0.308751 | -1.370760 | 0.865653 | ... | -0.947489 | 0.244443 | 1.401345 | -0.410382 | 0.528944 | 0.246148 | 0.863520 | -0.804754 | 2.346647 | -1.279161 |
| 10 | 6.0 | 3.0 | 4.8 | 1.8 | -0.365551 | 0.938093 | 0.296733 | 0.829986 | -0.496102 | -0.074805 | ... | 0.435546 | -0.599224 | 0.033090 | -0.854161 | -0.719941 | -0.893574 | -0.156024 | 1.049093 | 3.170975 | 0.189500 |
| 11 | 6.3 | 3.3 | 6.0 | 2.5 | -1.348413 | 1.264983 | -0.300784 | -0.660609 | 0.209849 | -1.240625 | ... | 1.518759 | -1.171160 | 0.764497 | -0.268373 | -0.169758 | -0.134133 | 1.221385 | -0.192842 | -0.033319 | -1.530803 |
| 12 | 6.5 | 2.8 | 4.6 | 1.5 | 0.206691 | 0.531043 | 0.239146 | 1.397896 | 0.055171 | 0.298977 | ... | -0.549499 | -1.098571 | 2.320800 | 0.117091 | 0.534201 | 0.317885 | 0.434808 | 0.540094 | 0.732424 | -0.375222 |
| 13 | 7.2 | 3.0 | 5.8 | 1.6 | -0.291642 | -1.741023 | -0.780304 | 0.271113 | 1.045023 | 0.599040 | ... | -0.612626 | -0.822828 | -1.490265 | 1.496140 | -0.972403 | 1.346221 | -0.467493 | -0.862493 | 0.622519 | -0.631192 |
| 14 | 6.1 | 2.6 | 5.6 | 1.4 | 0.568459 | -0.332812 | 0.480424 | -0.968186 | 0.831351 | 0.487973 | ... | 0.665967 | -2.534554 | -1.375184 | 0.500992 | -0.480249 | 0.936108 | 0.809180 | -1.198093 | 0.406657 | 1.201698 |
| 15 | 5.0 | 2.0 | 3.5 | 1.0 | 0.147434 | -0.977465 | 0.879390 | 0.635425 | 0.542611 | 0.715939 | ... | -0.104980 | 1.367415 | -1.655344 | 0.153644 | -1.584474 | 0.844454 | -1.212868 | 0.283770 | -0.282196 | -1.158203 |
| 16 | 6.0 | 2.2 | 5.0 | 1.5 | -1.619360 | -0.511040 | 1.740629 | -0.293485 | 0.917222 | -0.057043 | ... | -0.796775 | 1.548067 | -0.061743 | -0.446836 | -0.183756 | 0.824618 | -1.312850 | 1.414874 | 0.156476 | -0.216344 |
| 17 | 7.3 | 2.9 | 6.3 | 1.8 | 0.442846 | 0.218397 | -0.344196 | -0.252711 | -0.868863 | 0.656391 | ... | 0.246649 | 0.607993 | -0.839632 | -1.368245 | 1.561280 | -0.940270 | -0.659943 | 0.213017 | 0.599369 | -0.256317 |
| 18 | 6.7 | 3.0 | 5.0 | 1.7 | 0.460794 | -0.400986 | -0.971171 | 1.426317 | 2.488442 | 1.695970 | ... | -0.762362 | -1.446940 | 2.620574 | -0.747473 | -1.300347 | -0.803850 | -0.774295 | -0.269390 | 0.825372 | -0.298323 |
| 19 | 6.3 | 2.5 | 4.9 | 1.5 | -0.922823 | -1.451338 | 0.021857 | 0.042539 | 1.530932 | 0.092448 | ... | 1.257744 | -2.086635 | 0.040071 | -0.327755 | 1.455808 | 0.055492 | 1.484926 | -2.123890 | 0.459585 | 0.280058 |
| 20 | 6.9 | 3.2 | 5.7 | 2.3 | 1.390534 | -1.641349 | -0.155036 | 0.066060 | -0.495795 | 1.216578 | ... | -0.770784 | -0.480845 | 0.703586 | 0.929145 | 0.371173 | -0.989823 | 0.643631 | 0.688897 | 0.274647 | -0.603620 |
| 21 | 7.2 | 3.6 | 6.1 | 2.5 | 0.708860 | 0.422819 | -3.116857 | 0.644452 | -1.913743 | 0.663562 | ... | 0.409552 | -0.799593 | 1.511639 | 1.706468 | 0.701783 | 0.073285 | -0.461894 | -0.626490 | 1.710837 | 1.414415 |
| 22 | 5.7 | 2.8 | 4.1 | 1.3 | -0.063661 | -1.579931 | -2.832012 | -1.083427 | -0.130620 | 1.400689 | ... | -1.098289 | 0.572613 | -0.861216 | -0.509595 | 1.098582 | -0.127067 | 0.813452 | 0.473291 | 0.753866 | -0.888188 |
| 23 | 5.8 | 2.8 | 5.1 | 2.4 | -0.221574 | 0.424253 | -0.849073 | 1.629500 | -0.777228 | -0.300004 | ... | 2.464322 | 0.193832 | 1.132005 | -0.560981 | -1.362941 | -0.791757 | -0.268010 | -0.496608 | 1.336386 | -0.120041 |
| 24 | 6.8 | 3.2 | 5.9 | 2.3 | 0.461469 | -0.046481 | -0.433554 | 0.037996 | 1.714051 | -0.767949 | ... | -0.110591 | -0.432432 | 1.077037 | -0.224827 | -0.576242 | 0.574609 | -0.489828 | 0.658802 | -0.596917 | -0.222959 |
| 25 | 5.9 | 3.0 | 5.1 | 1.8 | 0.152177 | -0.374126 | -0.013451 | 0.815472 | 0.410602 | 0.480970 | ... | 0.704643 | 0.155591 | 0.936795 | 0.770331 | 0.140811 | 0.473488 | 1.855246 | 1.415656 | -0.302746 | 0.989679 |
| 26 | 5.8 | 2.7 | 5.1 | 1.9 | 0.585851 | 1.136388 | 0.671617 | -0.974167 | -1.619685 | 0.572627 | ... | 0.295779 | 0.842589 | 0.245616 | -0.032996 | -1.562014 | 1.006107 | -0.044045 | 1.959562 | 0.942314 | -2.005125 |
| 27 | 6.0 | 2.9 | 4.5 | 1.5 | 0.755050 | -1.396535 | -0.759495 | -0.250757 | -0.094062 | 0.397565 | ... | -0.875155 | -0.593520 | 0.662005 | -0.340874 | -1.519974 | -0.216533 | -0.784221 | 0.731294 | -0.343235 | 0.070774 |
| 28 | 6.5 | 3.0 | 5.8 | 2.2 | -0.405472 | 0.433939 | -0.183591 | 0.325199 | -2.593389 | 0.097251 | ... | 0.100564 | -0.954943 | -1.470402 | 1.010428 | 0.496179 | 0.576956 | -1.107647 | 0.234977 | 0.629000 | 0.314034 |
| 29 | 6.4 | 2.8 | 5.6 | 2.2 | -0.745023 | 1.012261 | -1.527632 | 0.928742 | 1.081056 | 1.572330 | ... | 0.826126 | -0.057757 | -0.726712 | -0.217163 | 0.136031 | -0.838311 | 0.561450 | -1.259596 | -0.332759 | -0.204008 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 70 | 6.7 | 3.1 | 5.6 | 2.4 | -0.881016 | -0.676689 | 0.071754 | -0.094366 | -0.881015 | 1.513925 | ... | -0.306563 | 0.367911 | 1.268154 | 0.065453 | 0.834569 | -1.115651 | 0.847658 | 0.238571 | -0.463588 | -1.145754 |
| 71 | 6.1 | 2.9 | 4.7 | 1.4 | -0.018751 | 0.538716 | 0.254868 | -0.091577 | 1.068479 | 1.085213 | ... | -0.194306 | -1.368116 | -1.163993 | 0.430824 | 0.133907 | -0.811671 | -0.528279 | 0.462801 | 1.313237 | 0.833175 |
| 72 | 6.4 | 2.8 | 5.6 | 2.1 | -0.201892 | 0.093311 | -1.009972 | 0.417053 | 0.433208 | -0.200063 | ... | -1.032532 | -0.901072 | -0.514878 | 0.417854 | -2.048833 | -0.989744 | -0.338294 | 1.503827 | -0.258209 | -0.154596 |
| 73 | 7.1 | 3.0 | 5.9 | 2.1 | -1.655827 | -0.093555 | -1.090081 | 0.778008 | 2.168954 | 0.587482 | ... | -0.178279 | 0.923813 | 0.714544 | -1.021254 | 0.232299 | -0.154917 | -0.399993 | -2.658387 | -1.003429 | 1.389284 |
| 74 | 4.9 | 2.4 | 3.3 | 1.0 | -0.071352 | 0.138888 | -0.096762 | 0.403115 | 0.628149 | 0.567997 | ... | -0.426025 | -0.869334 | 0.332105 | -0.223230 | 0.185918 | 0.075560 | 0.481256 | 0.080554 | -0.188178 | -1.311192 |
| 75 | 6.5 | 3.0 | 5.5 | 1.8 | -0.088724 | 1.512770 | 0.573708 | -0.541004 | 0.101177 | 0.994552 | ... | -1.214615 | -0.363353 | -1.016375 | 0.816155 | -2.642065 | -0.999590 | -0.684297 | -1.378620 | -0.116662 | -0.500927 |
| 76 | 6.4 | 2.7 | 5.3 | 1.9 | 1.304927 | -1.170061 | 0.427337 | -0.486877 | -0.939968 | 0.193671 | ... | -0.243211 | -0.137261 | 0.523465 | -1.265604 | 0.480674 | 3.003123 | -0.151272 | -0.724395 | 0.038790 | -0.119819 |
| 77 | 6.6 | 3.0 | 4.4 | 1.4 | 0.820849 | -1.007497 | -0.667793 | 0.048303 | 0.175038 | 0.208316 | ... | -1.266621 | 1.586552 | 0.061099 | -0.177095 | -0.585432 | -0.438535 | 0.017596 | 1.331462 | 1.584075 | -0.323664 |
| 78 | 5.5 | 2.3 | 4.0 | 1.3 | 2.341122 | -0.613557 | 0.924924 | -0.223781 | 0.891121 | 0.145156 | ... | 0.142588 | 0.887803 | 1.384392 | -2.063531 | 0.418131 | -1.678002 | 2.865602 | -0.675515 | -1.213975 | -1.723544 |
| 79 | 5.2 | 2.7 | 3.9 | 1.4 | -0.011559 | -1.283446 | 0.660915 | -0.115704 | 0.300711 | -0.961867 | ... | 1.438354 | -1.400189 | -1.954720 | -0.758857 | 0.119426 | 0.736410 | -0.665872 | -0.052111 | 0.142015 | -1.200824 |
| 80 | 6.7 | 3.1 | 4.7 | 1.5 | -0.014129 | 0.172282 | 1.018502 | 0.362555 | -0.219281 | 0.685341 | ... | 1.654254 | -1.763229 | -1.941552 | -1.190738 | -0.004849 | 0.422242 | 0.034198 | 1.521315 | -0.176605 | 0.224400 |
| 81 | 6.4 | 3.2 | 5.3 | 2.3 | 0.728263 | 0.115932 | -1.415487 | 0.316568 | 0.878322 | -1.156103 | ... | -0.142926 | -0.014118 | -0.541292 | 0.915340 | 0.768111 | 0.101635 | 0.809442 | 0.000456 | -0.226717 | 1.281717 |
| 82 | 5.6 | 2.7 | 4.2 | 1.3 | -0.073499 | 1.069635 | 0.792015 | 0.339708 | 0.633513 | -0.312690 | ... | 1.193671 | 0.142021 | 0.990304 | 1.024855 | 0.781983 | -1.515585 | -0.120473 | -0.264603 | -0.478156 | -1.257802 |
| 83 | 7.7 | 2.6 | 6.9 | 2.3 | -0.887962 | 0.883404 | 0.368100 | -0.345552 | -0.108353 | 0.836264 | ... | -0.774274 | 1.214965 | 0.760617 | 0.317108 | -0.167219 | 0.123047 | -0.534006 | -0.062328 | 0.499380 | -0.611262 |
| 84 | 4.9 | 2.5 | 4.5 | 1.7 | 0.227978 | -1.263296 | -1.077302 | 0.360745 | -0.257662 | 0.781847 | ... | -2.124691 | 1.672370 | -0.716988 | -0.534827 | 0.357596 | -0.239539 | 1.992326 | 0.198205 | -1.463027 | -0.505329 |
| 85 | 7.4 | 2.8 | 6.1 | 1.9 | 0.865052 | -1.306580 | -0.652815 | 1.701400 | 0.220198 | -1.617604 | ... | 0.653622 | 0.117515 | -1.226595 | 0.284589 | -0.334194 | -0.903473 | 0.381607 | -0.052080 | 1.359030 | 0.240198 |
| 86 | 5.6 | 2.8 | 4.9 | 2.0 | -0.510340 | 1.403989 | 1.009901 | -0.468205 | -0.190315 | 0.227571 | ... | -0.379471 | 0.595397 | -0.891139 | 1.254901 | 1.070941 | 1.368118 | 0.754042 | -1.361790 | 0.214890 | 0.766670 |
| 87 | 5.4 | 3.0 | 4.5 | 1.5 | -0.572147 | -0.932604 | -1.346319 | -1.058354 | 0.308220 | 0.126306 | ... | -0.318538 | -1.872091 | 0.072127 | 0.291206 | -0.278348 | 0.604955 | 0.670609 | 0.728398 | 1.335929 | -0.872750 |
| 88 | 6.3 | 2.9 | 5.6 | 1.8 | -0.182048 | -0.276649 | 0.538549 | -1.242191 | -0.648934 | -0.894170 | ... | 0.017709 | -1.055375 | 0.053726 | 0.892005 | -0.143683 | 0.542886 | 2.615181 | 0.908922 | -0.670107 | 0.146299 |
| 89 | 6.3 | 2.5 | 5.0 | 1.9 | -0.417750 | -0.307175 | 0.270318 | 0.006145 | -0.041413 | 1.252048 | ... | 0.853689 | 0.661952 | 0.194043 | 1.251985 | 1.454035 | -1.487691 | -0.528628 | -0.561362 | 0.459419 | 0.461485 |
| 90 | 5.9 | 3.2 | 4.8 | 1.8 | -0.841556 | -2.404757 | -1.494455 | -2.204729 | -0.710470 | -0.686504 | ... | -0.017775 | 1.537601 | 1.584035 | -1.507334 | 0.066576 | 0.377961 | 0.902158 | 0.017875 | -0.106061 | 0.949775 |
| 91 | 6.1 | 3.0 | 4.9 | 1.8 | 1.145574 | 1.176222 | -0.837864 | -0.506493 | -0.500535 | 0.074223 | ... | -1.391425 | 1.187411 | 0.136741 | 0.446020 | -1.261147 | 0.038625 | -0.964237 | 0.414514 | -0.175222 | -2.575418 |
| 92 | 5.8 | 2.7 | 3.9 | 1.2 | -1.654025 | -0.034928 | 0.044896 | -0.401898 | -0.718010 | -0.079427 | ... | -0.647734 | -0.563837 | 0.104988 | -0.084172 | -0.506115 | -1.237672 | -1.230211 | -0.241843 | -0.047562 | 0.347055 |
| 93 | 5.8 | 2.7 | 4.1 | 1.0 | -0.790745 | 0.082979 | -0.965247 | -0.895353 | 0.756129 | 0.493720 | ... | 0.726356 | 1.206265 | -1.037853 | -0.245858 | -1.389653 | -0.078631 | 0.979513 | -0.207132 | -0.494727 | -1.672523 |
| 94 | 6.2 | 3.4 | 5.4 | 2.3 | 0.215002 | -0.672310 | -0.216854 | -0.900317 | -1.247777 | -0.177184 | ... | -1.147052 | 0.719630 | -0.939569 | -1.248523 | 0.977258 | -0.974969 | -0.919455 | 0.155265 | -1.340796 | 1.057030 |
| 95 | 6.6 | 2.9 | 4.6 | 1.3 | -0.077869 | 1.703830 | -0.273921 | -0.310248 | -1.754890 | 0.419147 | ... | -0.356165 | -2.244161 | 0.572133 | -0.042063 | 0.833380 | -0.129480 | 0.218202 | 0.362546 | -0.340090 | -1.353757 |
| 96 | 6.4 | 2.9 | 4.3 | 1.3 | -1.295209 | 0.772378 | -0.064841 | -1.240077 | 1.682795 | 1.140158 | ... | 0.471884 | 1.167628 | -1.280400 | -1.577651 | 0.437270 | -1.103348 | 0.647573 | 0.447371 | -0.146771 | 0.779457 |
| 97 | 6.0 | 2.2 | 4.0 | 1.0 | -0.680326 | 0.962252 | -0.858723 | 1.217500 | 0.289700 | -2.598197 | ... | 0.135432 | -0.434221 | 0.835055 | -1.538043 | 2.201508 | -1.292014 | 1.650376 | 0.437087 | -0.692241 | -1.832737 |
| 98 | 6.8 | 3.0 | 5.5 | 2.1 | -0.117562 | 0.018905 | -0.107093 | -1.765298 | 0.571350 | -0.833247 | ... | 0.646027 | -0.456958 | 1.722247 | 0.248672 | -0.594782 | -0.572446 | -1.292801 | 0.351857 | -0.276844 | 0.174488 |
| 99 | 6.2 | 2.8 | 4.8 | 1.8 | 0.771581 | -0.315522 | -0.601200 | -0.077892 | 0.654753 | -1.526880 | ... | -0.776623 | -0.248674 | -1.735269 | -0.049026 | 0.382293 | 0.736216 | 0.776332 | -0.152795 | 1.248565 | 0.223998 |
100 rows × 100 columns
# データをシャッフル
p = range(len(data2))
random.seed(0)
random.shuffle(p)
shuffled_sample_names = list(np.array(sample_names)[p])
shuffled_data = np.array(data2)[p]
shuffled_target = list(np.array(target2)[p])
# データを分割。test_size=0.8 は、学習:テスト のデータ量比が 2:8 であることを指す。
data_train, data_test, target_train, target_test, sample_names_train, sample_names_test = train_test_split(
data2, target2, sample_names, test_size=0.8, random_state=0)
# Linear SVM で学習・予測
classifier = svm.SVC(kernel='linear', probability=True)
probas = classifier.fit(data_train, target_train).predict_proba(data_test)
pred = classifier.fit(data_train, target_train).predict(data_test)
# AUPRスコアを出す
precision, recall, thresholds = precision_recall_curve(target_test, probas[:, 1])
area = auc(recall, precision)
print "AUPR score: %0.2f" % area
AUPR score: 0.69
# AUCスコアを出す
fpr, tpr, thresholds = roc_curve(target_test, probas[:, 1])
roc_auc = auc(fpr, tpr)
print "AUC curve : %f" % roc_auc
AUC curve : 0.689806
# PR curve を描く
pl.clf()
pl.plot(recall, precision, label='Precision-Recall curve')
pl.xlabel('Recall')
pl.ylabel('Precision')
pl.ylim([0.0, 1.05])
pl.xlim([0.0, 1.0])
pl.title('Precision-Recall curve: AUPR=%0.2f' % area)
pl.legend(loc="lower left")
pl.show()
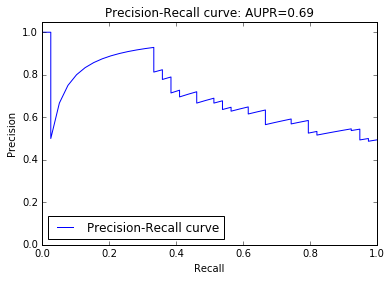
# ROC curve を描く
pl.clf()
pl.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
pl.plot([0, 1], [0, 1], 'k--')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('ROC curve: AUC=%0.2f' % roc_auc)
pl.legend(loc="lower right")
pl.show()
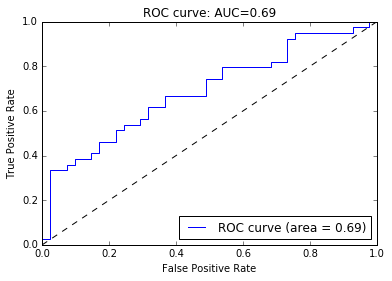
ということで、分類に寄与しない余計な成分が増えると、分類が難しくなることが分かりましたね。
グリッドサーチによるパラメータ最適化
グリッドサーチとは、機械学習モデルのハイパーパラメータをいろいろ変えながら予測と評価を繰り返し、最適なものを探す手法。
# グリッドサーチを行うためのパラメーター
parameters = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4],
'C': [1, 10, 100, 1000]},
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
# ベストなパラメーターを探し当てるためのグリッドサーチ
clf = grid_search.GridSearchCV(SVC(C=1), parameters, cv=5, n_jobs=-1)
clf.fit(data_train, target_train)
print(clf.best_estimator_)
SVC(C=10, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# 結果発表
scores = ['accuracy', 'precision', 'recall']
for score in scores:
print '\n' + '='*50
print score
print '='*50
clf = grid_search.GridSearchCV(SVC(C=1), parameters, cv=5, scoring=score, n_jobs=-1)
clf.fit(data_train, target_train)
print "\n+ ベストパラメータ:\n"
print clf.best_estimator_
print"\n+ トレーニングデータでCVした時の平均スコア:\n"
for params, mean_score, all_scores in clf.grid_scores_:
print "{:.3f} (+/- {:.3f}) for {}".format(mean_score, all_scores.std() / 2, params)
print "\n+ テストデータでの識別結果:\n"
target_true, target_pred = target_test, clf.predict(data_test)
print classification_report(target_true, target_pred)
==================================================
accuracy
==================================================
+ ベストパラメータ:
SVC(C=10, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
+ トレーニングデータでCVした時の平均スコア:
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.001}
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.0001}
0.700 (+/- 0.096) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.001}
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.0001}
0.700 (+/- 0.096) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.001}
0.700 (+/- 0.096) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.0001}
0.700 (+/- 0.096) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.001}
0.700 (+/- 0.096) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.0001}
0.700 (+/- 0.096) for {'kernel': 'linear', 'C': 1}
0.700 (+/- 0.096) for {'kernel': 'linear', 'C': 10}
0.700 (+/- 0.096) for {'kernel': 'linear', 'C': 100}
0.700 (+/- 0.096) for {'kernel': 'linear', 'C': 1000}
+ テストデータでの識別結果:
precision recall f1-score support
0 0.66 0.66 0.66 41
1 0.64 0.64 0.64 39
avg / total 0.65 0.65 0.65 80
==================================================
precision
==================================================
+ ベストパラメータ:
SVC(C=10, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
+ トレーニングデータでCVした時の平均スコア:
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.001}
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.0001}
0.808 (+/- 0.105) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.001}
0.550 (+/- 0.034) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.0001}
0.808 (+/- 0.105) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.001}
0.808 (+/- 0.105) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.0001}
0.808 (+/- 0.105) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.001}
0.808 (+/- 0.105) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.0001}
0.808 (+/- 0.105) for {'kernel': 'linear', 'C': 1}
0.808 (+/- 0.105) for {'kernel': 'linear', 'C': 10}
0.808 (+/- 0.105) for {'kernel': 'linear', 'C': 100}
0.808 (+/- 0.105) for {'kernel': 'linear', 'C': 1000}
+ テストデータでの識別結果:
precision recall f1-score support
0 0.66 0.66 0.66 41
1 0.64 0.64 0.64 39
avg / total 0.65 0.65 0.65 80
==================================================
recall
==================================================
+ ベストパラメータ:
SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
+ トレーニングデータでCVした時の平均スコア:
1.000 (+/- 0.000) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.001}
1.000 (+/- 0.000) for {'kernel': 'rbf', 'C': 1, 'gamma': 0.0001}
0.717 (+/- 0.113) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.001}
1.000 (+/- 0.000) for {'kernel': 'rbf', 'C': 10, 'gamma': 0.0001}
0.717 (+/- 0.113) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.001}
0.717 (+/- 0.113) for {'kernel': 'rbf', 'C': 100, 'gamma': 0.0001}
0.717 (+/- 0.113) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.001}
0.717 (+/- 0.113) for {'kernel': 'rbf', 'C': 1000, 'gamma': 0.0001}
0.717 (+/- 0.113) for {'kernel': 'linear', 'C': 1}
0.717 (+/- 0.113) for {'kernel': 'linear', 'C': 10}
0.717 (+/- 0.113) for {'kernel': 'linear', 'C': 100}
0.717 (+/- 0.113) for {'kernel': 'linear', 'C': 1000}
+ テストデータでの識別結果:
precision recall f1-score support
0 0.00 0.00 0.00 41
1 0.49 1.00 0.66 39
avg / total 0.24 0.49 0.32 80
課題
新しいノートを開いて、以下の課題を解いてください。
-
課題1:下記リンクのデータを用い、図1のような Scatter Matrix を描いてください。ただしこのとき、真札を青色、偽札を赤色にしてプロットすること。
-
https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/sbnote_dataJt.txt
ここでは、以下の列を使います。
- 'Note' : スイスフラン紙幣のID番号
- 'length' : 横幅長
- 'left': 左縦幅長
- 'right': 右縦幅長
- 'bottom': 下枠内長
- 'top': 上枠内長
- 'diagonal': 対角長
- 'class': 0 = 真札、1= 偽札
-
-
課題2: 上記のデータを使って学習し、サポートベクトルマシンを使って真札と偽札を区別する予測モデルを構築し、その性能を正解率 (Accuracy) で評価してください。
総合実験(Pythonプログラミング)4日間コース
本稿は「総合実験(Pythonプログラミング)4日間コース」シリーズ記事です。興味ある方は以下の記事も合わせてお読みください。