2016年に作った資料を公開します。もう既にいろいろ古くなってる可能性が高いです。
Jupyter Notebook (IPython Notebook) とは
- Python という名のプログラミング言語が使えるプログラミング環境。計算コードと計算結果を同じ場所に時系列で保存できるので、実験系における実験ノートのように、いつどんな処理を行って何を得たのか記録して再現するのに便利。
まずは、意味が分からなくてもいいので使ってみましょう
- 本実習ではまず、下のプログラムを順次実行してもらいます。各自の画面中の IPython Notebook のセルに順次入力して(コピペ可)、「Shift + Enter」してください。
# URL によるリソースへのアクセスを提供するライブラリをインポートする。
# import urllib # Python 2 の場合
import urllib.request # Python 3 の場合
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/iris.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
# urllib.urlretrieve(url, 'iris.txt') # Python 2 の場合
urllib.request.urlretrieve(url, 'iris.txt') # Python 3 の場合
('iris.txt', <httplib.HTTPMessage instance at 0x10621c638>)
# ダウンロードしたファイルの中身を確認する。
for line in open('iris.txt'):
print (line)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
11 5.4 3.7 1.5 0.2 setosa
12 4.8 3.4 1.6 0.2 setosa
13 4.8 3 1.4 0.1 setosa
14 4.3 3 1.1 0.1 setosa
15 5.8 4 1.2 0.2 setosa
16 5.7 4.4 1.5 0.4 setosa
17 5.4 3.9 1.3 0.4 setosa
18 5.1 3.5 1.4 0.3 setosa
19 5.7 3.8 1.7 0.3 setosa
20 5.1 3.8 1.5 0.3 setosa
21 5.4 3.4 1.7 0.2 setosa
22 5.1 3.7 1.5 0.4 setosa
23 4.6 3.6 1 0.2 setosa
24 5.1 3.3 1.7 0.5 setosa
25 4.8 3.4 1.9 0.2 setosa
26 5 3 1.6 0.2 setosa
27 5 3.4 1.6 0.4 setosa
28 5.2 3.5 1.5 0.2 setosa
29 5.2 3.4 1.4 0.2 setosa
30 4.7 3.2 1.6 0.2 setosa
31 4.8 3.1 1.6 0.2 setosa
32 5.4 3.4 1.5 0.4 setosa
33 5.2 4.1 1.5 0.1 setosa
34 5.5 4.2 1.4 0.2 setosa
35 4.9 3.1 1.5 0.2 setosa
36 5 3.2 1.2 0.2 setosa
37 5.5 3.5 1.3 0.2 setosa
38 4.9 3.6 1.4 0.1 setosa
39 4.4 3 1.3 0.2 setosa
40 5.1 3.4 1.5 0.2 setosa
41 5 3.5 1.3 0.3 setosa
42 4.5 2.3 1.3 0.3 setosa
43 4.4 3.2 1.3 0.2 setosa
44 5 3.5 1.6 0.6 setosa
45 5.1 3.8 1.9 0.4 setosa
46 4.8 3 1.4 0.3 setosa
47 5.1 3.8 1.6 0.2 setosa
48 4.6 3.2 1.4 0.2 setosa
49 5.3 3.7 1.5 0.2 setosa
50 5 3.3 1.4 0.2 setosa
51 7 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4 1.3 versicolor
55 6.5 2.8 4.6 1.5 versicolor
56 5.7 2.8 4.5 1.3 versicolor
57 6.3 3.3 4.7 1.6 versicolor
58 4.9 2.4 3.3 1 versicolor
59 6.6 2.9 4.6 1.3 versicolor
60 5.2 2.7 3.9 1.4 versicolor
61 5 2 3.5 1 versicolor
62 5.9 3 4.2 1.5 versicolor
63 6 2.2 4 1 versicolor
64 6.1 2.9 4.7 1.4 versicolor
65 5.6 2.9 3.6 1.3 versicolor
66 6.7 3.1 4.4 1.4 versicolor
67 5.6 3 4.5 1.5 versicolor
68 5.8 2.7 4.1 1 versicolor
69 6.2 2.2 4.5 1.5 versicolor
70 5.6 2.5 3.9 1.1 versicolor
71 5.9 3.2 4.8 1.8 versicolor
72 6.1 2.8 4 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3 5 1.7 versicolor
79 6 2.9 4.5 1.5 versicolor
80 5.7 2.6 3.5 1 versicolor
81 5.5 2.4 3.8 1.1 versicolor
82 5.5 2.4 3.7 1 versicolor
83 5.8 2.7 3.9 1.2 versicolor
84 6 2.7 5.1 1.6 versicolor
85 5.4 3 4.5 1.5 versicolor
86 6 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
89 5.6 3 4.1 1.3 versicolor
90 5.5 2.5 4 1.3 versicolor
91 5.5 2.6 4.4 1.2 versicolor
92 6.1 3 4.6 1.4 versicolor
93 5.8 2.6 4 1.2 versicolor
94 5 2.3 3.3 1 versicolor
95 5.6 2.7 4.2 1.3 versicolor
96 5.7 3 4.2 1.2 versicolor
97 5.7 2.9 4.2 1.3 versicolor
98 6.2 2.9 4.3 1.3 versicolor
99 5.1 2.5 3 1.1 versicolor
100 5.7 2.8 4.1 1.3 versicolor
101 6.3 3.3 6 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
103 7.1 3 5.9 2.1 virginica
104 6.3 2.9 5.6 1.8 virginica
105 6.5 3 5.8 2.2 virginica
106 7.6 3 6.6 2.1 virginica
107 4.9 2.5 4.5 1.7 virginica
108 7.3 2.9 6.3 1.8 virginica
109 6.7 2.5 5.8 1.8 virginica
110 7.2 3.6 6.1 2.5 virginica
111 6.5 3.2 5.1 2 virginica
112 6.4 2.7 5.3 1.9 virginica
113 6.8 3 5.5 2.1 virginica
114 5.7 2.5 5 2 virginica
115 5.8 2.8 5.1 2.4 virginica
116 6.4 3.2 5.3 2.3 virginica
117 6.5 3 5.5 1.8 virginica
118 7.7 3.8 6.7 2.2 virginica
119 7.7 2.6 6.9 2.3 virginica
120 6 2.2 5 1.5 virginica
121 6.9 3.2 5.7 2.3 virginica
122 5.6 2.8 4.9 2 virginica
123 7.7 2.8 6.7 2 virginica
124 6.3 2.7 4.9 1.8 virginica
125 6.7 3.3 5.7 2.1 virginica
126 7.2 3.2 6 1.8 virginica
127 6.2 2.8 4.8 1.8 virginica
128 6.1 3 4.9 1.8 virginica
129 6.4 2.8 5.6 2.1 virginica
130 7.2 3 5.8 1.6 virginica
131 7.4 2.8 6.1 1.9 virginica
132 7.9 3.8 6.4 2 virginica
133 6.4 2.8 5.6 2.2 virginica
134 6.3 2.8 5.1 1.5 virginica
135 6.1 2.6 5.6 1.4 virginica
136 7.7 3 6.1 2.3 virginica
137 6.3 3.4 5.6 2.4 virginica
138 6.4 3.1 5.5 1.8 virginica
139 6 3 4.8 1.8 virginica
140 6.9 3.1 5.4 2.1 virginica
141 6.7 3.1 5.6 2.4 virginica
142 6.9 3.1 5.1 2.3 virginica
143 5.8 2.7 5.1 1.9 virginica
144 6.8 3.2 5.9 2.3 virginica
145 6.7 3.3 5.7 2.5 virginica
146 6.7 3 5.2 2.3 virginica
147 6.3 2.5 5 1.9 virginica
148 6.5 3 5.2 2 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3 5.1 1.8 virginica
# ダウンロードしたファイルの中身を確認する(行番号付き)
for i, line in enumerate(open('iris.txt')):
print (i, line)
if i > 5:
break
0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5 3.6 1.4 0.2 setosa
6 6 5.4 3.9 1.7 0.4 setosa
# ダウンロードしたファイルの中身を確認する(先頭行を無視して、空白でデータ区切りをする)
for i, line in enumerate(open('iris.txt')):
if i == 0:
continue
else:
a = line.split()
print (a)
if i > 5:
break
['1', '5.1', '3.5', '1.4', '0.2', 'setosa']
['2', '4.9', '3', '1.4', '0.2', 'setosa']
['3', '4.7', '3.2', '1.3', '0.2', 'setosa']
['4', '4.6', '3.1', '1.5', '0.2', 'setosa']
['5', '5', '3.6', '1.4', '0.2', 'setosa']
['6', '5.4', '3.9', '1.7', '0.4', 'setosa']
# ダウンロードしたファイルから、指定した列の数字をリストに入れる。
x1 = []
for i, line in enumerate(open('iris.txt')):
if i == 0:
continue
else:
a = line.split()
x1.append(float(a[1]))
# リスト x1 の中身を確認する。
print (x1)
[5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4.8, 4.3, 5.8, 5.7, 5.4, 5.1, 5.7, 5.1, 5.4, 5.1, 4.6, 5.1, 4.8, 5.0, 5.0, 5.2, 5.2, 4.7, 4.8, 5.4, 5.2, 5.5, 4.9, 5.0, 5.5, 4.9, 4.4, 5.1, 5.0, 4.5, 4.4, 5.0, 5.1, 4.8, 5.1, 4.6, 5.3, 5.0, 7.0, 6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4, 6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7, 6.3, 5.8, 7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7, 6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9]
# ダウンロードしたファイルから、4つの列の数字をそれぞれ4つのリストに入れる。
x1 = []
x2 = []
x3 = []
x4 = []
for i, line in enumerate(open('iris.txt')):
if i == 0:
continue
else:
a = line.split()
x1.append(float(a[1]))
x2.append(float(a[2]))
x3.append(float(a[3]))
x4.append(float(a[4]))
# リスト x1 の中身を確認する。
print (x1)
[5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4.8, 4.3, 5.8, 5.7, 5.4, 5.1, 5.7, 5.1, 5.4, 5.1, 4.6, 5.1, 4.8, 5.0, 5.0, 5.2, 5.2, 4.7, 4.8, 5.4, 5.2, 5.5, 4.9, 5.0, 5.5, 4.9, 4.4, 5.1, 5.0, 4.5, 4.4, 5.0, 5.1, 4.8, 5.1, 4.6, 5.3, 5.0, 7.0, 6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4, 6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7, 6.3, 5.8, 7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7, 6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9]
# リスト x2 の中身を確認する。
print (x2)
[3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3.0, 3.0, 4.0, 4.4, 3.9, 3.5, 3.8, 3.8, 3.4, 3.7, 3.6, 3.3, 3.4, 3.0, 3.4, 3.5, 3.4, 3.2, 3.1, 3.4, 4.1, 4.2, 3.1, 3.2, 3.5, 3.6, 3.0, 3.4, 3.5, 2.3, 3.2, 3.5, 3.8, 3.0, 3.8, 3.2, 3.7, 3.3, 3.2, 3.2, 3.1, 2.3, 2.8, 2.8, 3.3, 2.4, 2.9, 2.7, 2.0, 3.0, 2.2, 2.9, 2.9, 3.1, 3.0, 2.7, 2.2, 2.5, 3.2, 2.8, 2.5, 2.8, 2.9, 3.0, 2.8, 3.0, 2.9, 2.6, 2.4, 2.4, 2.7, 2.7, 3.0, 3.4, 3.1, 2.3, 3.0, 2.5, 2.6, 3.0, 2.6, 2.3, 2.7, 3.0, 2.9, 2.9, 2.5, 2.8, 3.3, 2.7, 3.0, 2.9, 3.0, 3.0, 2.5, 2.9, 2.5, 3.6, 3.2, 2.7, 3.0, 2.5, 2.8, 3.2, 3.0, 3.8, 2.6, 2.2, 3.2, 2.8, 2.8, 2.7, 3.3, 3.2, 2.8, 3.0, 2.8, 3.0, 2.8, 3.8, 2.8, 2.8, 2.6, 3.0, 3.4, 3.1, 3.0, 3.1, 3.1, 3.1, 2.7, 3.2, 3.3, 3.0, 2.5, 3.0, 3.4, 3.0]
# リスト x3 の中身を確認する。
print (x3)
[1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.5, 1.5, 1.6, 1.4, 1.1, 1.2, 1.5, 1.3, 1.4, 1.7, 1.5, 1.7, 1.5, 1.0, 1.7, 1.9, 1.6, 1.6, 1.5, 1.4, 1.6, 1.6, 1.5, 1.5, 1.4, 1.5, 1.2, 1.3, 1.4, 1.3, 1.5, 1.3, 1.3, 1.3, 1.6, 1.9, 1.4, 1.6, 1.4, 1.5, 1.4, 4.7, 4.5, 4.9, 4.0, 4.6, 4.5, 4.7, 3.3, 4.6, 3.9, 3.5, 4.2, 4.0, 4.7, 3.6, 4.4, 4.5, 4.1, 4.5, 3.9, 4.8, 4.0, 4.9, 4.7, 4.3, 4.4, 4.8, 5.0, 4.5, 3.5, 3.8, 3.7, 3.9, 5.1, 4.5, 4.5, 4.7, 4.4, 4.1, 4.0, 4.4, 4.6, 4.0, 3.3, 4.2, 4.2, 4.2, 4.3, 3.0, 4.1, 6.0, 5.1, 5.9, 5.6, 5.8, 6.6, 4.5, 6.3, 5.8, 6.1, 5.1, 5.3, 5.5, 5.0, 5.1, 5.3, 5.5, 6.7, 6.9, 5.0, 5.7, 4.9, 6.7, 4.9, 5.7, 6.0, 4.8, 4.9, 5.6, 5.8, 6.1, 6.4, 5.6, 5.1, 5.6, 6.1, 5.6, 5.5, 4.8, 5.4, 5.6, 5.1, 5.1, 5.9, 5.7, 5.2, 5.0, 5.2, 5.4, 5.1]
# リスト x4 の中身を確認する。
print (x4)
[0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.1, 0.2, 0.2, 0.1, 0.1, 0.2, 0.4, 0.4, 0.3, 0.3, 0.3, 0.2, 0.4, 0.2, 0.5, 0.2, 0.2, 0.4, 0.2, 0.2, 0.2, 0.2, 0.4, 0.1, 0.2, 0.2, 0.2, 0.2, 0.1, 0.2, 0.2, 0.3, 0.3, 0.2, 0.6, 0.4, 0.3, 0.2, 0.2, 0.2, 0.2, 1.4, 1.5, 1.5, 1.3, 1.5, 1.3, 1.6, 1.0, 1.3, 1.4, 1.0, 1.5, 1.0, 1.4, 1.3, 1.4, 1.5, 1.0, 1.5, 1.1, 1.8, 1.3, 1.5, 1.2, 1.3, 1.4, 1.4, 1.7, 1.5, 1.0, 1.1, 1.0, 1.2, 1.6, 1.5, 1.6, 1.5, 1.3, 1.3, 1.3, 1.2, 1.4, 1.2, 1.0, 1.3, 1.2, 1.3, 1.3, 1.1, 1.3, 2.5, 1.9, 2.1, 1.8, 2.2, 2.1, 1.7, 1.8, 1.8, 2.5, 2.0, 1.9, 2.1, 2.0, 2.4, 2.3, 1.8, 2.2, 2.3, 1.5, 2.3, 2.0, 2.0, 1.8, 2.1, 1.8, 1.8, 1.8, 2.1, 1.6, 1.9, 2.0, 2.2, 1.5, 1.4, 2.3, 2.4, 1.8, 1.8, 2.1, 2.4, 2.3, 1.9, 2.3, 2.5, 2.3, 1.9, 2.0, 2.3, 1.8]
平均値を求める関数を作る
- 同じ計算を繰り返すために、何度も同じプログラムを書くのは面倒です。関数を定義して、使いまわしましょう。
# 平均値を求める関数
def average(data):
sum = 0.0
n = 0.0
for x in data:
sum += x
n += 1.0
return sum / n
# リスト x1 の平均値を求める。
average(x1)
5.843333333333335
# すべてのリストの平均値をそれぞれ求める。
print (average(x1))
print (average(x2))
print (average(x3))
print (average(x4))
5.84333333333
3.05733333333
3.758
1.19933333333
分散を求める関数を作る
- 同じ計算を繰り返すために、何度も同じプログラムを書くのは面倒です。関数を定義して、使いまわしましょう。
- 分散とは何か?標準偏差とは何か?忘れてしまった人は右記を参照。 http://www.cybernet.co.jp/cetol/kousa/kousa7.html
# 分散を求める関数
def variance(data):
ave = average(data)
accum = 0.0
n = 0.0
for x in data:
accum += (x - ave) ** 2.0
n += 1.0
return accum / n
# すべてのリストの分散をそれぞれ求める。
print (variance(x1))
print (variance(x2))
print (variance(x3))
print (variance(x4))
0.681122222222
0.188712888889
3.09550266667
0.577132888889
標準偏差を求める関数を作る
- 同じ計算を繰り返すために、何度も同じプログラムを書くのは面倒です。関数を定義して、使いまわしましょう。
- 分散とは何か?標準偏差とは何か?忘れてしまった人は右記を参照。 http://www.cybernet.co.jp/cetol/kousa/kousa7.html
- 1行で書ける関数は、上の「平均を求める関数」や「分散を求める関数」のような定義もできますが、下の例のように lambda というキーワードを使って関数を定義することができます。
- 「import math」は、平方根(sqrt)などの数学関数を使うためのライブラリをインポートするために唱えます。
# 標準偏差を求める関数
import math
standard_deviation = lambda data: math.sqrt(variance(data))
# すべてのリストの標準偏差をそれぞれ求める。
print (standard_deviation(x1))
print (standard_deviation(x2))
print (standard_deviation(x3))
print (standard_deviation(x4))
0.825301291785
0.434410967735
1.75940406578
0.759692627902
共分散を求める関数を作る
- 同じ計算を繰り返すために、何度も同じプログラムを書くのは面倒です。関数を定義して、使いまわしましょう。
- 共分散とは何か?相関係数とは何か?忘れてしまった人は右記を参照。 http://kogures.com/hitoshi/webtext/stat-soukan/index.html
# 共分散(偏差積の平均)を求める関数
def covariance(data1, data2):
ave1 = average(data1)
ave2 = average(data2)
accum = 0.0
n = 0.0
for d1, d2 in zip(data1, data2):
accum += (d1 - ave1) * (d2 - ave2)
n += 1.0
return accum / n
# すべてのリスト対の共分散をそれぞれ求める。
print (covariance(x1, x2))
print (covariance(x1, x3))
print (covariance(x1, x4))
print (covariance(x2, x3))
print (covariance(x2, x4))
print (covariance(x3, x4))
-0.0421511111111
1.26582
0.512828888889
-0.327458666667
-0.120828444444
1.286972
相関係数を求める関数を作る
- 同じ計算を繰り返すために、何度も同じプログラムを書くのは面倒です。関数を定義して、使いまわしましょう。
- 共分散とは何か?相関係数とは何か?忘れてしまった人は右記を参照。 http://kogures.com/hitoshi/webtext/stat-soukan/index.html
- 1行で書ける関数は、上の「平均を求める関数」や「分散を求める関数」のような定義もできますが、下の例のように lambda というキーワードを使って関数を定義することができます。
# 相関係数を求める関数
correlation = lambda data1, data2: covariance(data1, data2) / (standard_deviation(data1) * standard_deviation(data2))
# すべてのリスト対の相関係数をそれぞれ求める。
print (correlation(x1, x2))
print (correlation(x1, x3))
print (correlation(x1, x4))
print (correlation(x2, x3))
print (correlation(x2, x4))
print (correlation(x3, x4))
-0.117569784133
0.871753775887
0.817941126272
-0.428440104331
-0.366125932536
0.962865431403
データを図示する
- 平均、分散、標準偏差、共分散、相関係数などの数字だけ見て満足せずに、データをヒストグラムで表したり、散布図にプロットしてデータの特徴を把握しましょう。
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
%matplotlib inline
ヒストグラム
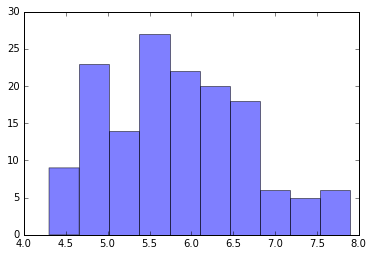
# x1のヒストグラム
plt.hist(x1, alpha=0.5)
(array([ 9., 23., 14., 27., 22., 20., 18., 6., 5., 6.]),
array([ 4.3 , 4.66, 5.02, 5.38, 5.74, 6.1 , 6.46, 6.82, 7.18,
7.54, 7.9 ]),
<a list of 10 Patch objects>)
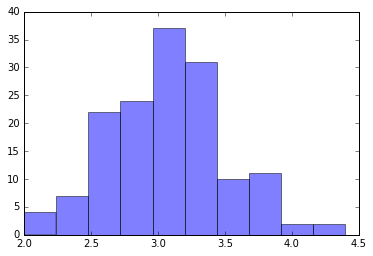
# x2のヒストグラム
plt.hist(x2, alpha=0.5)
(array([ 4., 7., 22., 24., 37., 31., 10., 11., 2., 2.]),
array([ 2. , 2.24, 2.48, 2.72, 2.96, 3.2 , 3.44, 3.68, 3.92,
4.16, 4.4 ]),
<a list of 10 Patch objects>)
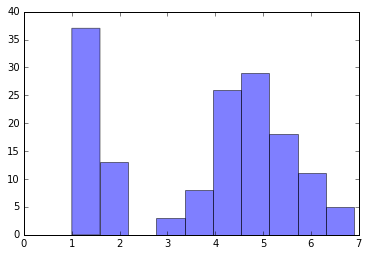
# x3のヒストグラム
plt.hist(x3, alpha=0.5)
(array([ 37., 13., 0., 3., 8., 26., 29., 18., 11., 5.]),
array([ 1. , 1.59, 2.18, 2.77, 3.36, 3.95, 4.54, 5.13, 5.72,
6.31, 6.9 ]),
<a list of 10 Patch objects>)
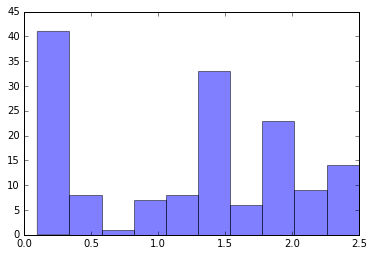
# x4のヒストグラム
plt.hist(x4, alpha=0.5)
(array([ 41., 8., 1., 7., 8., 33., 6., 23., 9., 14.]),
array([ 0.1 , 0.34, 0.58, 0.82, 1.06, 1.3 , 1.54, 1.78, 2.02,
2.26, 2.5 ]),
<a list of 10 Patch objects>)
散布図(scatter plot)
# x1 と x2 の関係をプロットする。
plt.scatter(x1, x2, alpha=0.5)
<matplotlib.collections.PathCollection at 0x10f6a8390>
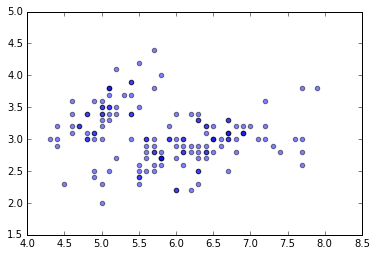
# x1 と x3 の関係をプロットする。
plt.scatter(x1, x3, alpha=0.5)
<matplotlib.collections.PathCollection at 0x10fa314d0>
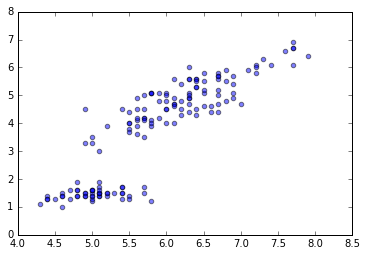
# x1 と x4 の関係をプロットする。
plt.scatter(x1, x4, alpha=0.5)
<matplotlib.collections.PathCollection at 0x10fb8ad10>
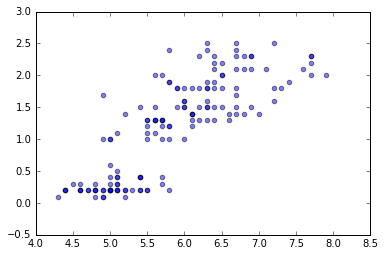
# x2 と x3 の関係をプロットする。
plt.scatter(x2, x3, alpha=0.5)
<matplotlib.collections.PathCollection at 0x10fe34d90>
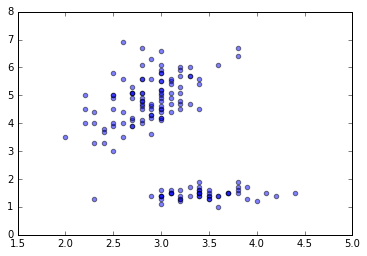
# x2 と x4 の関係をプロットする。
plt.scatter(x2, x4, alpha=0.5)
<matplotlib.collections.PathCollection at 0x10fef72d0>
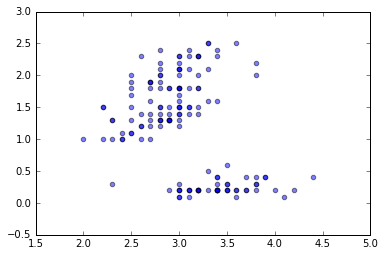
# x3 と x4 の関係をプロットする。
plt.scatter(x3, x4, alpha=0.5)
<matplotlib.collections.PathCollection at 0x110046b10>
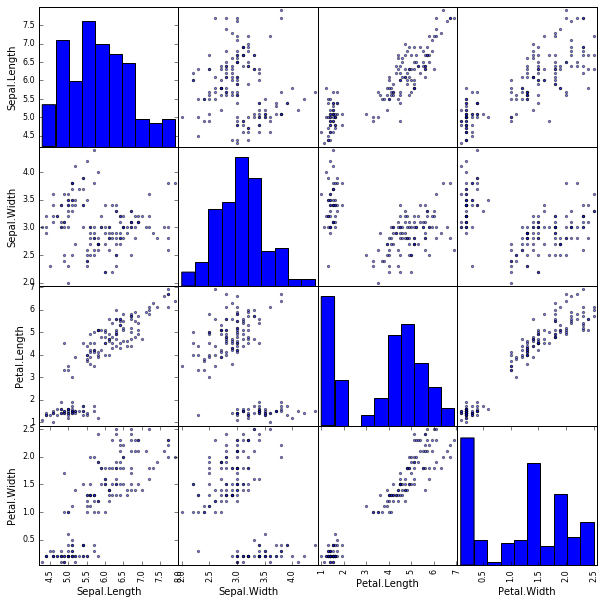
Scatter Matrix
- データの全体像を眺めたいと思った時、こういう方法も便利です。本日の実習では「こんな方法もあるんだな」と知っておく程度で十分です。
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
%matplotlib inline
import pandas # データフレームワーク処理のライブラリをインポート
from pandas.tools import plotting # 高度なプロットを行うツールのインポート
df = pandas.read_csv('iris.txt', sep='\t', na_values=".") # データの読み込み
plotting.scatter_matrix(df[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']], figsize=(10, 10)) #データのプロット
plt.show()
課題
新しいノートを開いて、以下の課題を解いてください。
-
課題1:下記URLからデータをダウンロードしてください。
-
https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/anscombe.txt
-
課題2: x1, x2, x3, x4, y1, y2, y3, y4 の平均値をそれぞれ求めてください。
-
課題3: x1, x2, x3, x4, y1, y2, y3, y4 の分散をそれぞれ求めてください。
-
課題4: x1, x2, x3, x4, y1, y2, y3, y4 の標準偏差をそれぞれ求めてください。
-
課題5: x1とy1の共分散、x2とy2の共分散、x3とy3の共分散、x4とy4の共分散をそれぞれ求めてください。
-
課題6: x1とy1の相関係数、x2とy2の相関係数、x3とy3の相関係数、x4とy4の相関係数をそれぞれ求めてください。
-
課題7: x1とy1の関係、x2とy2の関係、x3とy3の関係、x4とy4の関係をそれぞれ散布図としてプロットしてください。
総合実験(Pythonプログラミング)4日間コース
本稿は「総合実験(Pythonプログラミング)4日間コース」シリーズ記事です。興味ある方は以下の記事も合わせてお読みください。