Lecture 04: CNN Architecture and Loss - Convolution, Pooling, and Cross Entropy
CNNの仕組みと誤差関数
前回の振り返りと今回のテーマ
第三講では、深層学習(ディープラーニング)の全体像や、CNN(畳み込みニューラルネットワーク)が「特徴抽出部」と「分類部」の2つのステージで構成されていることを学びました。
今回の第四講では、その中でもCNNの核となる特徴抽出の具体的な3つの仕組み(畳み込み・プーリング・パディング)と、最終的な判定に使われるソフトマックス関数について詳しく見ていきましょう。
1. 畳み込み (Convolution)
■ 概要
画像から特徴を抽出する操作です。
入力画像に対して「フィルタ(カーネル)」を適用し、演算を行うことで特徴マップを作成します。
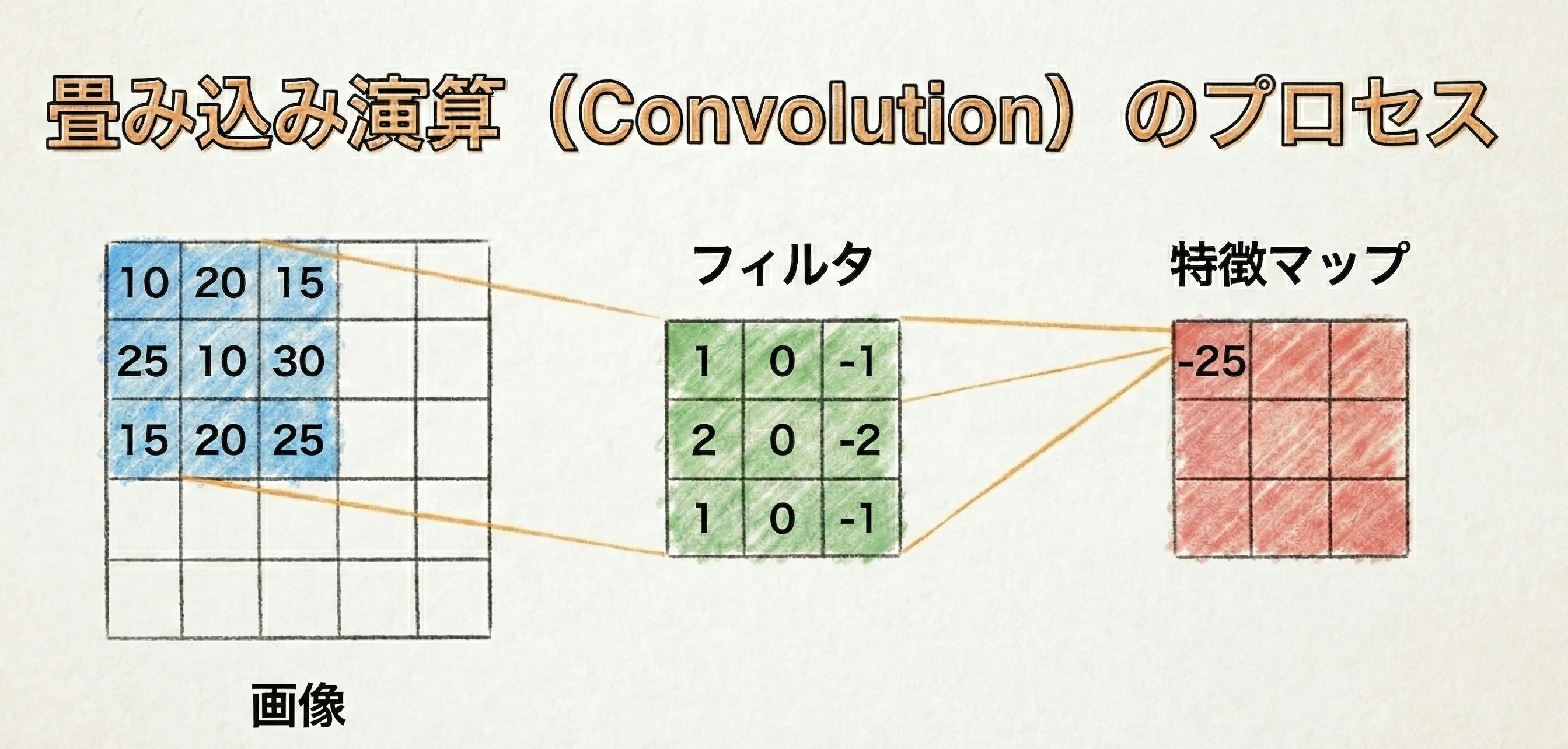
ストライド (Stride)
フィルタを画像上でスライドさせる際、何個ずつずらすかという移動幅のことです。
- ストライドが小さい(1など): 丁寧に出力を生成するが、計算量が増える。
- ストライドが大きい: 出力サイズが一気に小さくなり、情報を圧縮する。
2. プーリング (Pooling)
■ 概要
特徴マップをダウンサイズ(縮小)し、重要な情報を残しつつ計算量を削減する操作です。代表的なものにMax Poolingがあります。
■ 処理のイメージ(2×2 の領域を1つに集約する場合)
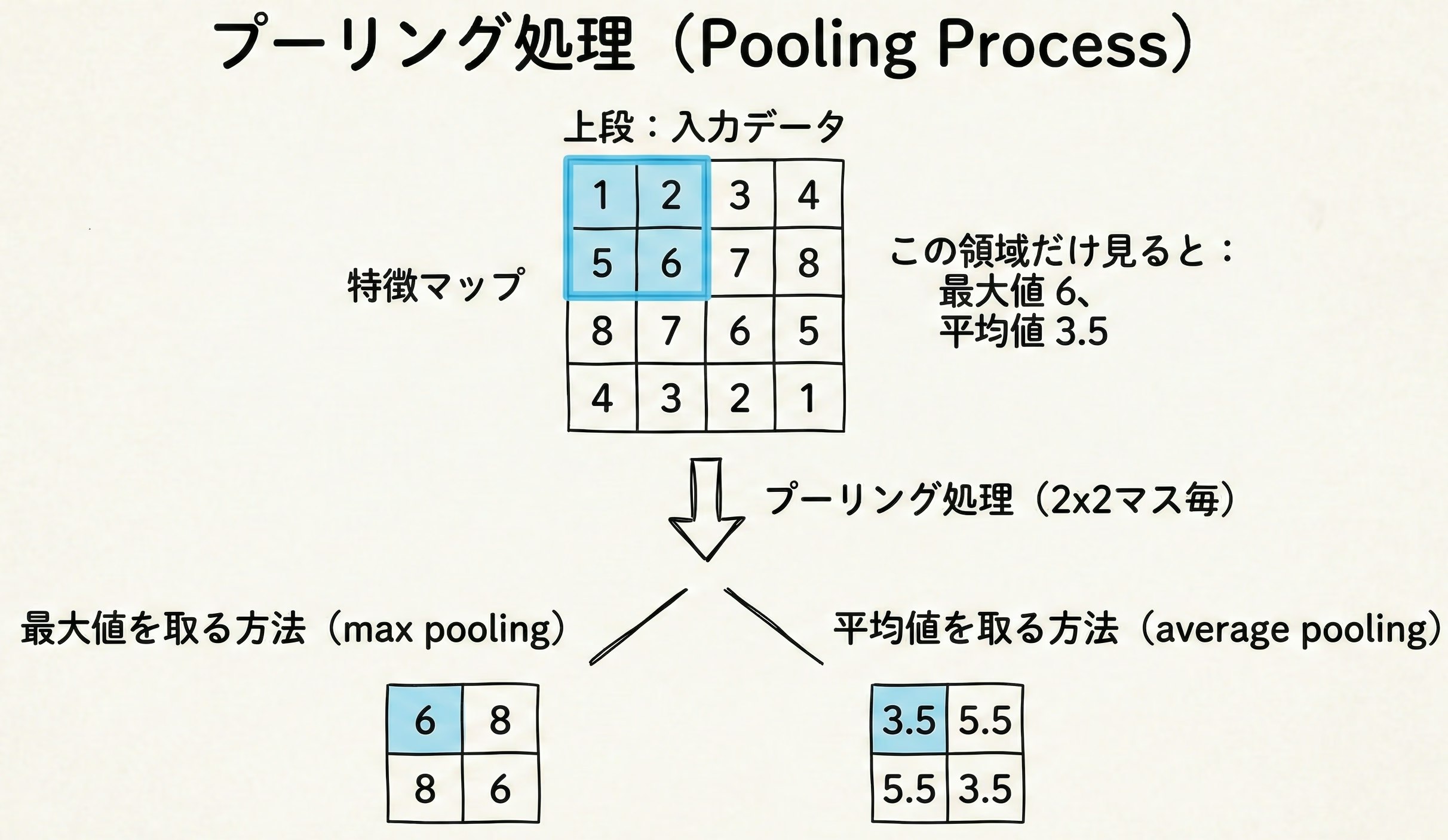
プーリングのメリット:不変性の向上
プーリングを行うことで、画像内の対象物が多少動いたり回転したりしても、抽出される特徴(最大値など)が大きく変わらなくなります。これにより、AIが「位置ズレ」に強くなります。
3. パディング (Padding)
■ 概要
畳み込みを行うと、出力される特徴マップのサイズは入力より一回り小さくなってしまいます。これを防ぐため、画像の周囲を「0」などの値で埋める処理をパディングと呼びます。
■ 目的
- サイズの一致: 入力と出力のサイズを同じに保つ。
- 情報の損失防止: 画像の端(エッジ)の部分が畳み込み回数とともに消失するのを防ぐ。
- 層の深化: サイズが小さくなりすぎるのを防ぎ、ネットワークをより深くすることができる。
■ イメージ図
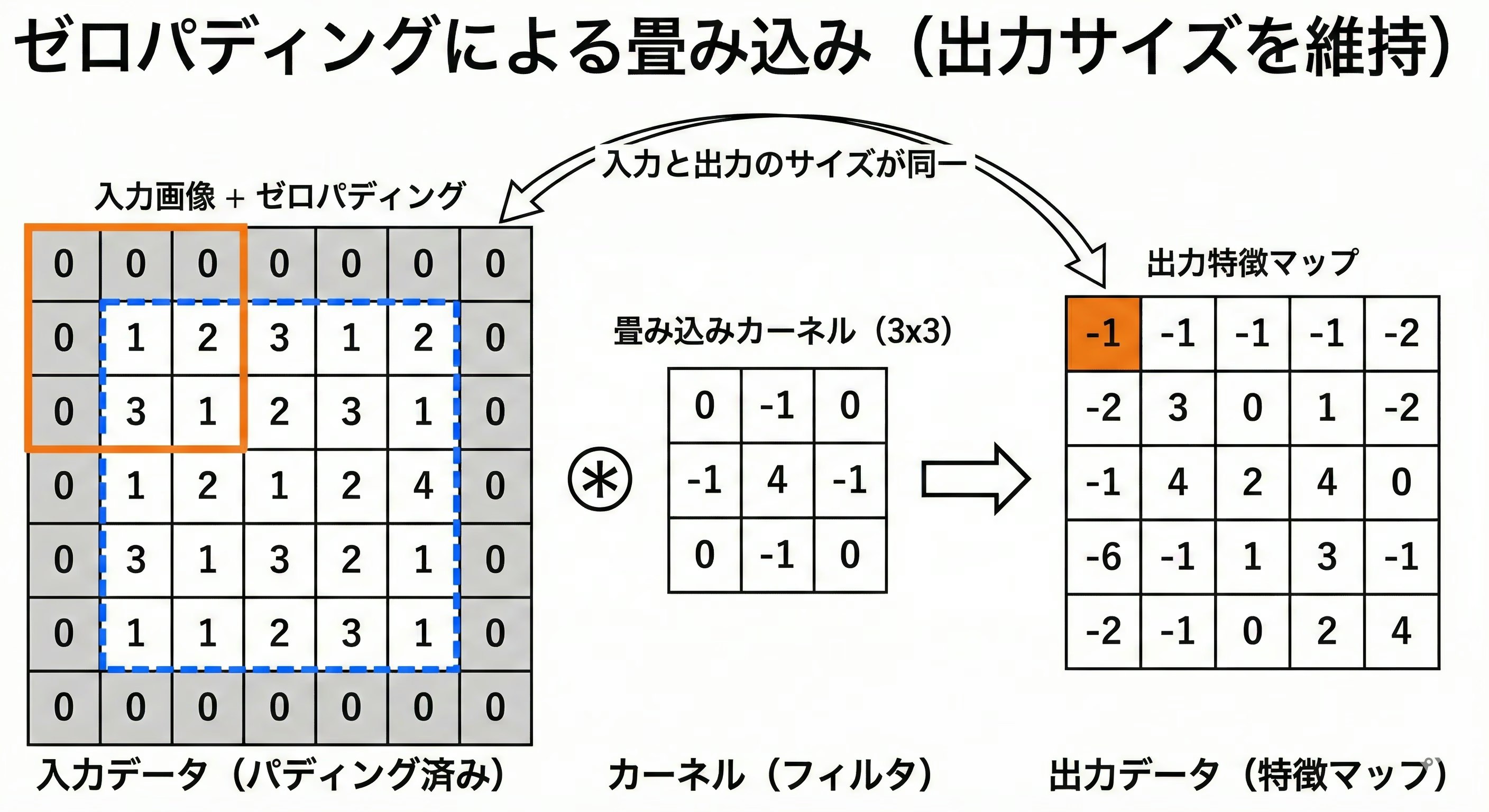
4. ソフトマックス関数(Softmax):出力を「確率」として解釈する
■ 概要
ソフトマックス関数は、ディープラーニングの多クラス分類問題の出力層で主に使用される関数です。
最大の特徴は、複数の出力値の合計が必ず「1(100%)」になるように変換する点にあります。
■ 数式
定義式は以下の通りです。
$$y_i = \frac{e^{i}}{\sum_{j} e^{j}}$$
- $y_i$: 出力(各クラスに属する確率)
- $e^i$: 入力値(中間層の出力)を指数関数の肩に乗せたもの
- $\sum_{j} e^{j}$: 全ての入力値の指数関数の合計(正規化のための分母)
■ 具体的な変換イメージ
例えば、中間層から「6」と「4」という数値が出力された場合、ソフトマックス関数を通すと以下のように変換されます。
| 項目 | 中間層の出力(入力) | ソフトマックス後の出力 |
|---|---|---|
| ノード1 | 6 | 0.88 (88%) |
| ノード2 | 4 | 0.12 (12%) |
| 合計 | - | 1.00 (100%) |
このように、出力値を合計1の範囲に収めることで、「どのクラスである可能性が最も高いか」を確率として扱うことができます。
■ なぜ指数関数を用いるのか?
単に「各数値を合計値で割る」だけでも合計を1にすることは可能ですが、あえてネイピア数 $e$ の累乗を用いるのには重要な理由があります。
ポイント:学習(逆伝播)の効率化
後の処理である逆伝播(バックプロパゲーション)の計算を楽にするためです。
指数関数は微分の形が非常にシンプルになる性質を持っており、交差エントロピー誤差関数と組み合わせることで、勾配の計算が劇的に簡略化されます。
5. 誤差関数・学習
■ 概要
- CNNの多クラス分類問題では、誤差関数(損失関数)に 交差エントロピー (Cross Entropy) を用います。
■ 交差エントロピー誤差の式
モデルの予測確率と正解ラベルの間の「ズレ」を計算する式です。
$$ L = -\sum_{i=1}^{N} \sum_{k=1}^{K} y_{k}^{(i)} \log \hat{y}_{k}^{(i)} $$
■ 変数の定義
この式における各変数の意味は以下の通りです。
- $N$: バッチサイズ(何個のデータで平均をとるか)
- $K$: クラスの数(分類するカテゴリー数)
- $i$: $i$ 番目のデータ(データセット内のインデックス)
- $k$: $k$ 番目のクラス
-
$y_{k}^{(i)}$: $i$ 番目のデータの $k$ 番目のクラスに対する正解ラベル (0 or 1)
- 正解のクラスなら1、それ以外なら0(One-hot表現)。
-
$\hat{y}_{k}^{(i)}$: $i$ 番目のデータの $k$ 番目のクラスに対する予測確率
- モデル(Softmax関数など)が出力した確率値。
6.学習計算について(交差エントロピーの場合)
■ 学習の定義
損失関数(ここでは交差エントロピー)の値を最適化(最小化)するパラメータ(重み)を探索することを「学習」といいます。
■ 計算の具体例
正解ラベル(Ground Truth)に対して、AIが出した予測値(Prediction)がどれくらい合っているかによって、算出される誤差(Error)の大きさが変わります。
前提:正解ラベル $d$
「クラス1」が正解である場合(One-hot表現)
$$
(d_1, d_2, d_3) = (1, 0, 0)
$$
パターン1:予測がよく当たっている場合
AIが「クラス1である確率が高い(0.8)」と予測したケース。
- 予測値 $y$: $(0.8, 0.1, 0.1)$
-
計算式:
E = -1 \times \log(0.8) \approx 0.09 - 結果: 誤差 $0.09$ $\to$ 誤差が小さい(優秀なモデル)
パターン2:予測が外れている場合
AIが「クラス1である確率は低い(0.2)」と間違った予測をしたケース。
- 予測値 $y$: $(0.2, 0.7, 0.1)$
-
計算式:
E = -1 \times \log(0.2) \approx 1.61 - 結果: 誤差 $1.61$ $\to$ 誤差が大きい(学習が必要)
学習のゴール
この誤差 $E$ を $1.61 \to 0.09$ のように小さくしていくために、ネットワーク内の「重み(パラメータ)」を少しずつ修正していく作業が学習です。
← 第三講へ | まとめページに戻る → | 第五講へ →