Lecture 03: Deep Learning Mechanics and CNN Architectures
深層学習とCNNの構造
前回の振り返りと今回のテーマ
第二講では、機械学習の全体像や、代表的な3つの学習法(教師あり・教師なし・強化学習)、そして教師あり学習における「分類」と「回帰」の違いを学びました。
今回の第三講では、現在主流となっている「深層学習(ディープラーニング)」に焦点を当てます。その核となる仕組みや、画像認識において圧倒的な成果を上げているCNN(畳み込みニューラルネットワーク)の基本的な構造について学んでいきましょう。
1. 深層学習(Deep Learning)の仕組み
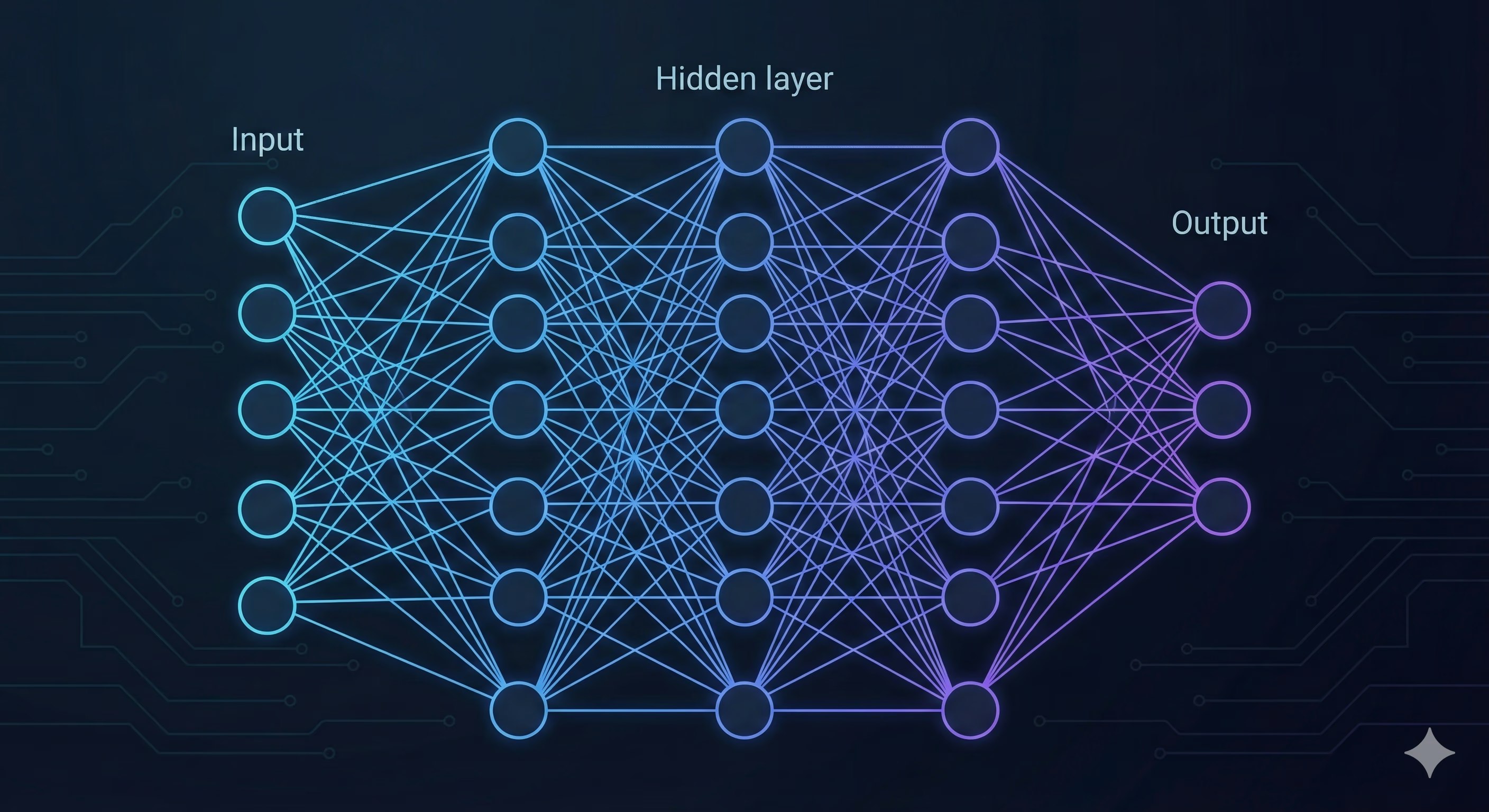
■ ディープニューラルネットワーク (DNN) とは
- 定義: 機械学習の中で自ら特徴量を選定する学習モデル
- 構造: 人間の神経回路を模したネットワークを多層積み重ねたもの
-
主なモデル:
- CNN: 画像認識
- RNN / LSTM / Transformer: 自然言語処理
- WaveNet: 音声処理
- DQN: ロボット制御(強化学習)
■ ネットワークの構造
データは入力層から中間層を経て出力層へと伝播します。
2. 畳み込みニューラルネットワーク(CNN)の概要
CNNは、主に画像認識や動画解析で威力を発揮するディープラーニングのモデルです。 大きな特徴は、データから直接「重要な特徴(エッジや模様など)」を自動的に学習する点にあります。
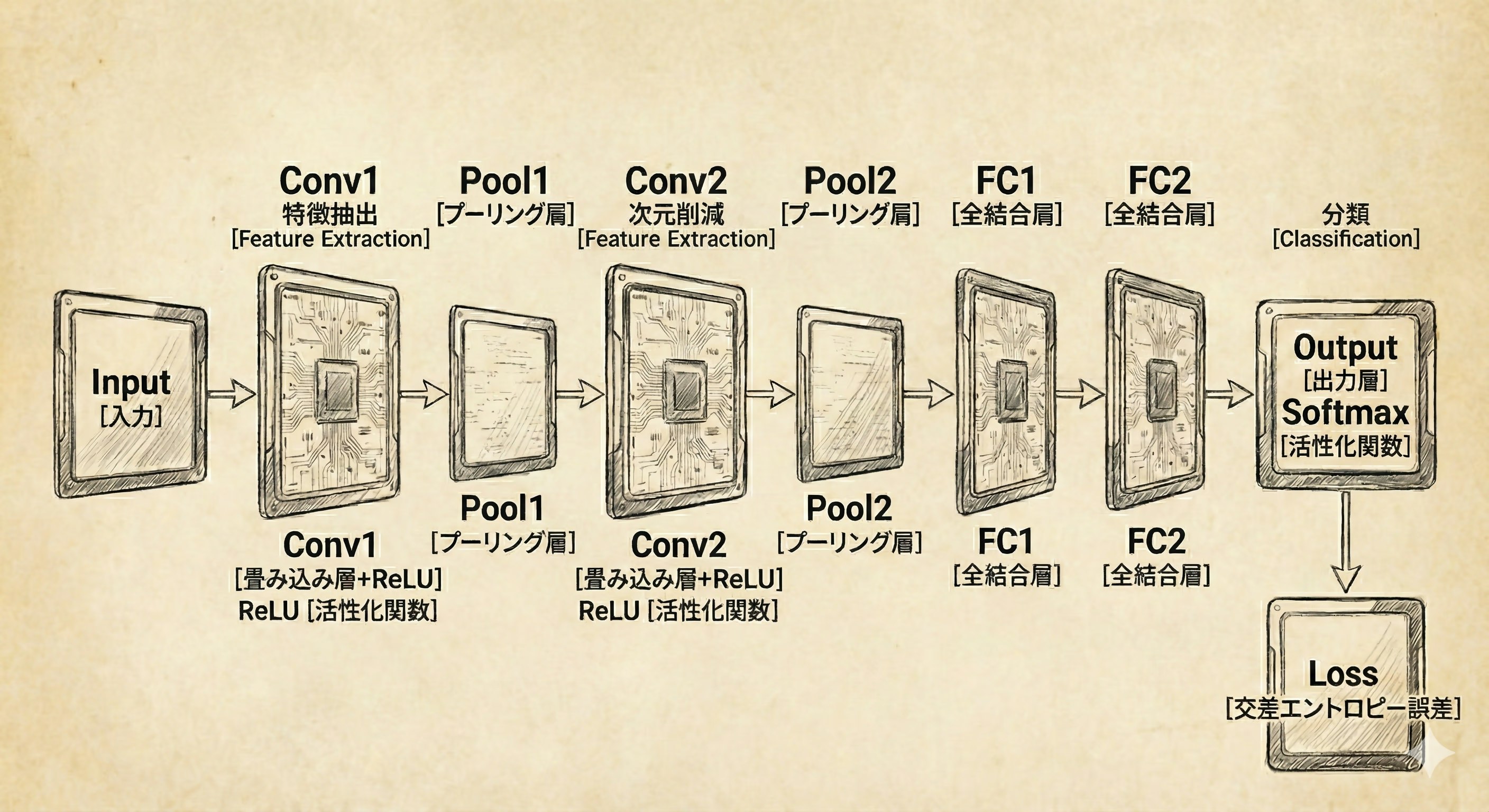
■ CNNの構成要素
CNNは大きく分けて特徴抽出部と分類部の2つのステージで構成されます。
■ ステージ1:特徴抽出部 (Feature Extraction)
-
畳み込み層 (Conv)
- フィルタ処理によって画像から特徴(エッジ、形状など)を取り出します。
-
活性化関数 (ReLU)
- 非線形な処理を加え、複雑なパターンの学習を可能にします。
-
プーリング層 (Pool)
- データのサイズを圧縮し、計算コストを抑えるとともに、多少の位置ズレを許容する性質(不変性)を与えます。
■ ステージ2:分類部 (Classification)
-
全結合層 (FC)
- 抽出された特徴を1列に並べ(Flatten)、最終的な判断を行います。
-
出力層 (Softmax)
- 各クラス(犬、猫など)に該当する確率を算出します。
■ 層構造の流れ
3.活性化関数の種類
■ 定義
ニューラルネットワークにおいて、線形の出力を非線形にするために用いる関数です。
これがないと、層をいくら重ねても単なる線形変換(掛け算と足し算)の繰り返しになってしまい、複雑な表現ができません。
■ 主な活性化関数一覧
| 名前 | 数式(概要) | 出力範囲 | 特徴 | 主な用途 |
|---|---|---|---|---|
| ReLU | $f(x) = \max(0, x)$ | $[0, \infty]$ | 計算が軽く、勾配消失が少ない。 現在のデファクトスタンダード。 |
中間層 (基本) |
| Leaky ReLU | $f(x) = \max(0.01x, x)$ | $(-\infty, \infty)$ | 入力が負の時もわずかに値を通すことで、ReLUの「死んだニューロン」問題を軽減する。 |
中間層 (ReLUの代替) |
| Sigmoid | $\displaystyle \frac{1}{1 + e^{-x}}$ | $(0, 1)$ | 0〜1の範囲に収まるため確率として扱いやすいが、層が深いと勾配消失しやすい。 |
出力層 (2クラス分類) |
| Tanh | $\tanh(x)$ | $(-1, 1)$ | Sigmoidより中心が0付近で安定しやすい。 | 古典的中間層 出力制限ありの回帰 |
| Softmax | $\displaystyle \frac{e^{x_i}}{\sum e^{x_k}}$ | $(0, 1)$ 合計1 |
複数の出力の合計が1になる(確率分布として扱える)。 |
出力層 (多クラス分類) |
4.損失関数の種類
■ 定義
損失関数(Loss Function)は誤差関数とも呼ばれ、モデルの「出力結果」と「正解ラベル」との差を表すものです。
■ タスク別:損失関数の一覧表
| タスク種別 | 損失関数名 | 数式定義($L$) | 主な用途 |
|---|---|---|---|
| 2クラス分類 | 二値クロスエントロピー | $-\frac{1}{n} \sum [y \log \hat{y} + (1-y) \log (1-\hat{y})]$ | 猫か犬かの判定など |
| 多クラス分類 | 交差エントロピー | $-\frac{1}{n} \sum \sum y_k \log \hat{y}_k$ | 数字(0〜9)の分類など |
| 単回帰 | 平均二乗誤差 (MSE) | $\frac{1}{n} \sum (y - \hat{y})^2$ | 不動産価格の予測など |
| 重回帰 | L2ノルムの二乗誤差 | $\frac{1}{n} \sum | \mathbf{y} - \mathbf{\hat{y}} |^2$ | 座標ベクトル等の予測 |
5. 学習の全体像:AIが「賢くなる」までのサイクル
ここまで学んだ構造(CNN)や指標(損失関数)が、実際にどう動いて学習が進むのかを整理します。AIの学習は、以下の予測と更新のサイクルを繰り返すことで進みます。
- 予測(順伝播): 入力データに重みを掛け合わせ、次の層へと伝える。(第5章の内容)
- 評価: 予測値と正解のズレを「損失関数」で計算する。(第3章の内容)
- 更新(逆伝播): ズレを最小にするように、重みを少しずつ修正する。(第6章の内容)
6. ニューロンの計算モデル
ニューロン内の処理は、入力と重みの演算、および活性化関数の適用で構成されます。
-
ニューロンへの入力 = 入力 × 重みの合計 + バイアス
- $= X_1 \times W_1 + X_2 \times W_2 + X_3 \times W_3 + b$
-
ニューロンからの出力 = 活性化関数f(ニューロンへの入力)
- $= 活性化関数f(X_1 \times W_1 + X_2 \times W_2 + X_3 \times W_3 + b)$
7. 重みとバイアスの更新(勾配)
学習プロセスにおけるパラメータの更新ルールです。
- 各重みの更新式: 各重み $w_{ij}$ = 各重み $w_{ij}$ - 学習率($\eta$) × 各重み $w_{ij}$ の勾配
- 各バイアスの更新式: 各バイアス $b_j$ = 各バイアス $b_j$ - 学習率($\eta$) × 各バイアス $b_j$ の勾配
数学的表現と各要素の役割
$$w_{ij} \leftarrow w_{ij} - \eta \frac{\partial L}{\partial w_{ij}}$$
- 学習率 ($\eta$): 進む大きさをスケーリングして調整します。
- 勾配 ($\frac{\partial L}{\partial w_{ij}}$): どちらの方向にどれくらい進むかを表す数値です。
- 添字の定義: $i$ は前の層のノード番号、$j$ は今の層のノード番号を指します。
- 数値の開始: 数学表現は「1スタート」、コード表現は「0スタート」となります。
(補足)図における乗算と減算の役割
更新式: $w_{ij} \leftarrow w_{ij} - \eta \cdot \frac{\partial L}{\partial w_{ij}}$
1. 乗算(学習率 × 勾配)
- 対象: 学習率 $\eta$ と勾配 $\frac{\partial L}{\partial w_{ij}}$ の掛け算。
- 役割: 「進む大きさをスケーリングして調整」すること。
- 意味: 勾配が示す方向と大きさに対して、一度の学習で実際にどれだけ重みを動かすかの「歩幅」を決定します。
2. 減算(現在の重み - 更新量)
- 対象: 現在の重み ($w_{ij}$) から、乗算の結果(更新量)を引く処理。
- 役割: パラメータを「勾配の逆方向」へ移動させること。
- 意味: 誤差が増える方向(勾配)とは反対の方向へ重みの値を書き換えることで、損失 $L$ を減少させます。
← 第二講へ | まとめページに戻る → | 第四講へ →