はじめに
今まで「Python入門」レベルだったため、2025年10月からPythonスクール 「BizCodeX」 に入校し、60日目の成果物として、本記事を作成しました。
本記事では、株式会社ビープラウド connpass 運営事務局様 より提供いただいた connpass API を利用し、Python から外部 API にアクセスしてイベント情報を取得・加工する一連の流れを、学習の題材としています。
具体的には、HTTP リクエストによるデータ取得、API から返ってきた JSON データを Python で扱いやすい形に整える処理、Pandas を用いたデータ整形・絞り込みといったステップを通して、Python による API 連携の基本的な実装パターンをまとめました。
なお、本記事で使用している API を学習目的で利用するにあたり、快くご提供くださった株式会社ビープラウド connpass 運営事務局様に、この場をお借りして厚く御礼申し上げます。
connpass - エンジニアをつなぐIT勉強会支援プラットフォーム
なぜ Python × API を学習するのか
Python で API を扱えるようになると、次のようなことが実現しやすくなります。
- 各種サービスの API(イベント情報、SNS、クラウドサービスなど)と連携し、データ収集を自動化できる
- 自分用のダッシュボードやレポート生成ツールなどを作成し、日々の業務や学習の可視化に活かせる
- スクレイピングでは取得しづらいデータも、公式 API を通じて構造化された形で安全に取得できる
「Python でちょっとしたツールは書けるようになってきたので、そろそろ外部サービスと連携したい」というタイミングの方にとって、API 連携は次のステップとしてちょうど良い題材だと考えています。
本記事の対象読者
本記事は、次のような方を想定しています。
- Python の基本文法は一通り触ったことがあり、実用的な題材でステップアップしたい方
- API 連携に興味はあるものの、どのようにコードを書き始めればよいかイメージが湧いていない方
- connpass のイベント情報を題材に、データ取得〜整形〜保存までの一連の流れを学びたい方
「Python で API 連携を試してみたいが、まずどんなコードを書けばよいか分からない」という方に向けて、具体的なサンプルコードとともに、全体の流れがイメージしやすい構成を意識して作成しました。
今回の学習で目指すこと
本記事では、connpass API を題材にしながら、Python による外部 API 連携の基本的な流れを一通り押さえることを目標としています。具体的には、次のようなことができるようになることを目指します。
- Python から connpass API (v2) に HTTP リクエストを送り、イベント情報を取得できる
- API キーや HTTP ヘッダーの指定など、API 利用時の基本的な設定方法を理解できる
- 取得した JSON 形式のレスポンスを、Python で扱いやすい辞書・リスト構造に変換・整形できる
- Pandas を用いて、イベント情報を DataFrame に変換し、フィルタリングやソートなどの前処理が行える
- 必要に応じて、整形したイベントデータを CSV 形式で出力し、後続の分析や可視化に活用できる
今回の学習アウトプット、及び、データから読み取れたこと
まずは、今回の学習で connpass API を用いて得られたアウトプット と、取得したイベントデータから読み取れた傾向 をまとめます。
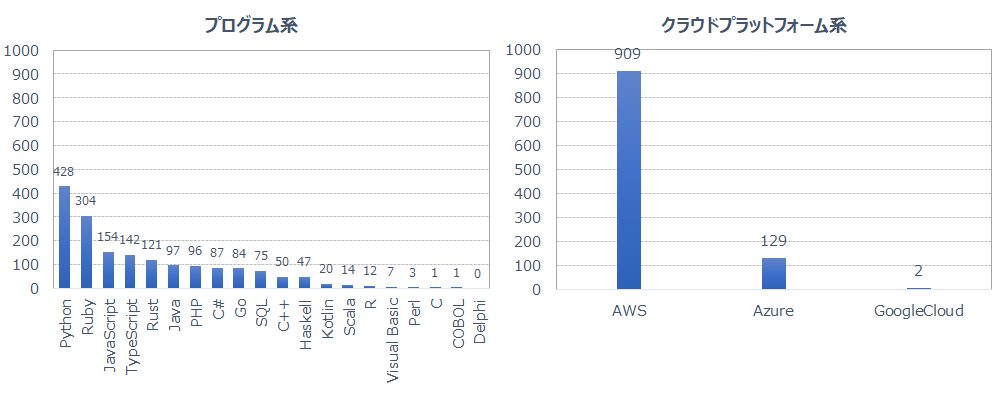
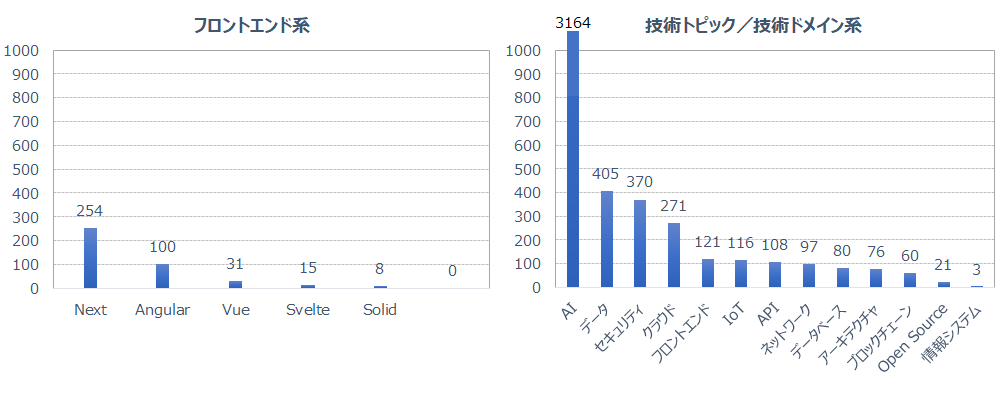
2025年1月から12月までの connpass のイベント数をカテゴリ別に取得し、可視化した結果、次のような傾向が明確に見えてきました。
-
Python
プログラミング言語カテゴリでは Python が突出しており、学習用途だけでなく、実務での利用も引き続き非常に強いと推測されます。 -
クラウド分野(AWS / Azure / Google Cloud)
クラウド関連では AWS が圧倒的多数です。
イベント数の差から、実務での利用や学習者の関心が AWS に大きく集中していると考えられます。 -
技術トピックとしての AI
AI は他の技術トピックと比べて桁違いのイベント数があり、各領域での活用が急速に拡大していると推測できます。
これらの分析結果から、今後の学習方針としては、「Python × AI × AWS」 を軸に据えることで、技術トレンドと技術ニーズの両面を効率よくカバーできるのではないかと感じました。
1. APIの取得と準備
1.1 connpass 個人・コミュニティ向け API 利用申請
「利用申請フォーム」より、API 利用申請をする。
connpassのAPI利用について
1.2 Windows に API キーを登録する方法(環境変数)
Python から API キーを安全に扱うためには、コードに直接ベタ書きするのではなく
Windows の環境変数として登録して利用する方法がおすすめです。
以下では、CONNPASS_API_KEY を環境変数として登録する手順を示します。
① PowerShell を起動
-
Winキーを押す -
powershellと入力 - Windows PowerShell → 右クリック → 管理者として実行(推奨)
② ユーザー環境変数 CONNPASS_API_KEY を登録する
PowerShell で以下を実行:
setx CONNPASS_API_KEY "ここに取得した_APIキー文字列"
※ 実行後、現在の PowerShell にはすぐ反映されないため、一度閉じて開き直す。
③ 反映を確認する
PowerShell を開き直した後、次のコマンドを実行:
$Env:CONNPASS_API_KEY
APIキー文字列が表示されれば設定完了。
1.3 「robots.txt」をチェックする
念のため、アクセス許可範囲を robots.txt で確認しておきます。
https://connpass.com/robots.txt
ブラウザーに入力すると、次のような結果が返ってきます。
User-agent: Googlebot
User-agent: TwitterBot
User-agent: facebookexternalhit
Allow: /
Disallow: /series/optout/
Disallow: /account/
Disallow: /api/
Disallow: /search/
User-agent: Bingbot
Crawl-delay: 20
Allow: /
Disallow: /series/optout/
Disallow: /account/
Disallow: /api/
Disallow: /search/
Disallow: /user/
Disallow: /event/
Disallow: /calendar/
# Every bot that might possibly read and respect this file
User-agent: *
Allow: /*.ics
Allow: /*/ja.atom
Disallow: /
# Wait 5 second between successive requests.
Crawl-delay: 5
2. connpass API v2 の仕様を確認する
2.1 API ドキュメントの確認
2.2 利用上の注意
connpass API にはサーバー負荷を避けるためのアクセス制御があり、短時間に大量のリクエストを送ると 429 Too Many Requests などのエラーが返される可能性があります。
connpass API (v2)ドキュメントでは「1秒間に1リクエストまで」と明記されていますが、robots.txt では全てのクローラに対して 5 秒の Crawl-delay が指定されています。
本記事ではこれにならい、複数回のリクエストが必要な処理では API 呼び出しの間隔を 5 秒 に設定し、サーバー負荷に配慮した実装としました。
また、robots.txt からも一般的なクローラに対して /api/ を含む多くのパスが Disallow とされており、HTML ページのスクレイピングなどの機械的なクロールは行わないことが前提になっていないことがわかります。
connpass のデータを利用する際は、API 利用規約 と robots.txt を確認した上で、公開されている正規の API を通じてアクセスすることが重要です。
この記事で想定している前提・注意点を整理すると、次のとおりです。
- スクレイピング禁止
- 大量アクセスによるサーバー負荷の回避
- 個人情報・プライバシーに配慮
- ツールの公開時も利用規約に沿った設計にする
これらの点を守ることで、安全に connpass API を利用できます。
3. 実装で苦労した点と対処した方法
connpass API を学習に活用する中で、いくつかハードルとなったポイントがありました。
同じように API 連携に挑戦する方の参考になるよう、解決方法を整理します。
① 指定した年月、ym(yyyymm 形式)の月次ループが扱いにくかった点
-
課題:
yyyymm形式が文字列として扱われているため、2025年12月 → 2026年1月 → 2026年2月…と、月を 1 か月ずつずらしながらループする処理が書きにくかった -
原因:
"202512"のような文字列(あるいは単純な数値加算)では、年・月の繰り上がり(12月 → 翌年1月)を正しく扱えず、暦通りのインクリメントが行えないため -
対応:
yyyymmを一度「年」と「月」に分解して日付型(datetime)に変換し、日付として 1 か月ずつ加算してから"%Y%m"形式の文字列に戻すように実装を変更した
② 1回のリクエストで 100 件までしか取得できない
- 課題:イベント数が多い月は 100 件を超えるため、それ以上のイベントが取得できず、データが欠損していた
-
原因:API 仕様上、1 回のレスポンスで返される件数の上限が
MAX_COUNT = 100に固定されており、かつ「任意の期間(開始日〜終了日)」を直接指定するパラメーターがないため -
対応:最初に
ymパラメータ(指定した年月)とorderパラメータ(開催日時順)を用いて上限数までイベントを取得し、取り切れなかった分についてはymdパラメータ(指定した年月日)を使って 1 日ずつイベントを取得することで、100 件を超える場合でも取りこぼしなく取得できるようにした
③ 「Python」で検索しても Python イベントとは限らない
- 課題:タイトルや本文に「Python」という文字列が含まれているだけでヒットするため、Python 以外が主役のイベントも混在してしまう
- 原因:キーワード検索が「部分一致検索」であり、登壇者紹介や補足説明の中にたまたま「Python」が含まれているケースも拾ってしまうため
-
対応:
eventsから取得したtitle(イベント名)・catch(キャッチコピー)・hash_tag(ハッシュタグ)の 3 フィールドに対して判定キーワードを設定し、例えば Python のイベントを抽出したい場合は["python", "py"]のいずれかが一致した場合のみ「Python イベント」とみなすロジックに変更した
4. 実装の全体フロー
本記事で作成した Python スクリプトは、connpass API から得られるイベント情報を取得し、加工・保存するまでの一連の流れを次の手順で実施しています。
-
APIリクエストパラメータを設定する
- 検索キーワード、対象年月(
ym)、最大取得件数(MAX_COUNT)、APIキー、HTTPヘッダーなどを準備する
- 検索キーワード、対象年月(
-
指定した年月(
ym)でイベント情報を取得する-
ymとorderパラメータを使って、開催日時順に上限数(最大100件)まで取得する
-
-
100件を超える場合の取りこぼしを補完する
-
ymdパラメータを用いて、1日ずつに分割してイベントを再取得し、欠けていた分のデータを追加する
-
-
レスポンス(JSON)を整形し、辞書・リスト形式に加工する
- 使用する項目だけ抽出し、Pythonで扱いやすい構造に変換する
-
Pandas DataFrame に変換する
- カラムを整え、分析や集計がしやすいテーブル形式にする
-
イベントのキーワード判定ロジックを適用する
- (例) Pythonイベントの抽出
- タイトル (title)
- キャッチコピー (catch)
- ハッシュタグ (hash_tag)
- →
title/catch/hash_tagのいずれかに["python", "py"]が含まれる場合のみ、イベントであるフラグ付け
- (例) Pythonイベントの抽出
-
ソートやフィルタリングなどの前処理を行う
- 開催日時順に並べ替え、重複行を排除し、必要に応じて抽出条件を追加する
-
CSVとして出力する
- 例:
output_202501-202512_python_***.csvのような形式で保存し、後続の分析や可視化に活用できるようにする
- 例:
5. イベント判定 実装コード
ここでは、"python", "C#", "Java" のイベントを対象に、connpass API (v2) からイベント情報を取得し、 Python / Pandas を使って整形したうえで CSV に出力するサンプルコードを示します。
from datetime import datetime
import json
import os
import re
import sys
import time
import pandas as pd
import requests
from requests.exceptions import RequestException
# --- 設定パラメータ ---
# 検索したいキーワードをリストで指定
TARGET_KEYWORDS = ["python", "C#", "Java"]
# 検索結果のイベント判定キーワード(TARGET_KEYWORDSごと)
EVENT_JUDGE_KEYWORDS_MAP = {
"python": ["python", "py"],
"C#": ["C#", "csharp", ".net"],
"Java": ["java"],
}
# 取得を開始/終了年月(YYYYMM形式)
START_YM = 202501
END_YM = 202512
# イベント判定列
EVENT_MATCH_COL = ["title", "catch", "hash_tag"]
# 1回のAPI呼び出しで取得できる最大件数
MAX_COUNT = 100
# 連続したリクエストの間隔(秒)
SLEEP_SEC = 5.0
# --- API設定 ---
API_ENDPOINT = "https://connpass.com/api/v2/events/"
# 環境変数からAPIキーをセット
API_KEY = os.environ.get("CONNPASS_API_KEY")
# HTTPリクエストヘッダーの設定 ( "User-Agent" は必須。ツール名/Ver)
headers = {
"X-API-Key": API_KEY,
"User-Agent": "EventMap_for_connpass/1.0",
}
# =========================================================
# 期間内のイベントをすべて取得する関数
# =========================================================
def get_events_in_period(target_keyword, start_ym, end_ym, api_endpoint, headers, max_count):
"""START_YM〜END_YM の範囲で、あるキーワードのイベントをすべて取得する"""
all_events = []
current_ym_int = start_ym
while current_ym_int <= end_ym:
month_events = get_events_for_month(
ym_int = current_ym_int,
tgt_kw = target_keyword,
max_count = max_count,
api_endpoint = api_endpoint,
headers = headers,
)
all_events.extend(month_events)
# 次の月へ
current_ym_int = next_month_int(current_ym_int)
return all_events
# =========================================================
# 1ヶ月分のイベントを取得する関数
# ・年月 (ym) で検索
# ・100件以上なら 年月日 (ymd) で1日ずつ取り直し
# =========================================================
def get_events_for_month(ym_int, tgt_kw, max_count, api_endpoint, headers):
"""指定された YYYYMM(整数) の1ヶ月分イベントをまとめて取得する"""
ym_str = str(ym_int) # "202511" など
monthly_events: list[dict] = []
# --- 該当月でまとめて取得 ---
params = {
"keyword": tgt_kw,
"ym": ym_str,
"count": max_count,
"start": 1, # 検索結果の何件目から出力するか
"order": 2, # 検索結果の表示順 (2:開催日時順)
# "prefecture": ["osaka"], # 都道府県で絞り込みたい場合
}
events = get_events(api_endpoint, headers, params)
monthly_events.extend(events)
# pandas DataFrame にしてソート
df = pd.json_normalize(events)
if len(df) == 0:
# イベントがなければここで終了
print(f"---> {ym_str}月 {tgt_kw} ヒット数: 0")
return monthly_events
df = df.sort_values(by=["started_at", "id"], ascending=[True, True])
events_count = len(df)
print(f"---> {ym_str}月 {tgt_kw} ヒット数:{events_count}")
# インターバル
time.sleep(SLEEP_SEC)
# print(f"---> {SLEEP_SEC} sec待ち")
# --- 該当月のイベント数が100以上なら、1日ずつ ymd で取り直す ---
if events_count >= max_count:
# 先頭行の開催日を取得
ym_ts = pd.to_datetime(df["started_at"].iloc[0])
target_day = ym_ts.day
for day in range(1, target_day + 1):
# 日付はゼロ埋めして "YYYYMMDD" に(01 ~ 09)
ymd = f"{ym_str}{day:02d}"
params_day = {
"keyword": tgt_kw,
"ymd": ymd,
"count": max_count,
"start": 1, # 検索結果の何件目から出力するか
"order": 2, # 検索結果の表示順 (2:開催日時順)
# "prefecture": ["osaka"], # 都道府県で絞り込みたい場合
}
day_events = get_events(api_endpoint, headers, params_day)
monthly_events.extend(day_events)
# インターバル
time.sleep(SLEEP_SEC)
# print(f"---> {SLEEP_SEC} sec待ち")
print(f"---> {ym_str}月 {tgt_kw} 再取得後ヒット数(累積):{len(monthly_events)}")
return monthly_events
# =========================================================
# APIリクエストを投げて events を返す関数
# =========================================================
def get_events(api_endpoint, headers, params):
"""connpass API を1回叩いて events を返す簡単な関数"""
response = requests.get(api_endpoint, headers=headers, params=params)
try:
response.raise_for_status()
# print("---> Status_Code:", response.status_code)
except RequestException as e:
print("---> Error:", e)
sys.exit(1)
data = response.json()
events = data.get("events", [])
return events
# =========================================================
# イベント判定用の関数
# =========================================================
def filter_events_by_keyword(df, target_keyword):
"""
取得した DataFrame に対して、
EVENT_JUDGE_KEYWORDS_MAP に基づき「本物のイベント」だけを抽出する
"""
# 判定用キーワード辞書から取得。無ければ検索キーワードそのものを使う
judge_keywords = EVENT_JUDGE_KEYWORDS_MAP.get(
target_keyword, [target_keyword]
)
# "aaa|bbb" のような正規表現パターンに変換
pattern = "|".join(re.escape(k) for k in judge_keywords)
# DataFrame 内の指定したカラムで、"pattern" を含む行だけ True になるマスクを作成
mask = df[EVENT_MATCH_COL].apply(
lambda s: s.str.contains(pattern, case=False, na=False)
).any(axis=1)
df_event = df[mask]
# 開催日時とIDで昇順ソート&重複削除
df_event = df_event.sort_values(by=["started_at", "id"], ascending=[True, True])
df_event = df_event.drop_duplicates(subset="id", keep="first")
return df_event
# =========================================================
# CSV 出力用の関数
# =========================================================
def export_events_to_csv(df_event, target_keyword, start_ym, end_ym):
"""イベント DataFrame を CSV に出力し、ファイル名を返す"""
events_count = len(df_event)
print(f"---> {start_ym}-{end_ym} 判定後の最終イベント数:{events_count}")
output_name = f"output_{start_ym}-{end_ym}_{target_keyword}_count_{events_count}.csv"
output_name = safe_filename(output_name)
df_event.to_csv(output_name, index=False, encoding="utf-8-sig")
print(f"---> CSV 出力完了: {output_name}")
return output_name
def export_empty_csv(target_keyword, start_ym, end_ym):
"""イベントがない場合に空のCSVを出力"""
df_empty = pd.DataFrame()
events_count = 0
output_name = f"output_{start_ym}-{end_ym}_{target_keyword}_count_{events_count}.csv"
output_name = safe_filename(output_name)
df_empty.to_csv(output_name, index=False, encoding="utf-8-sig")
print(f"---> {target_keyword}: {start_ym}-{end_ym} にイベント無し。空CSVを出力: {output_name}")
return output_name
# =========================================================
# 補助関数(ファイル名・年月進行)
# =========================================================
def safe_filename(name):
"""Windowsの禁止文字を安全な文字に置換"""
invalid_chars = r'<>:"/\|?*'
for ch in invalid_chars:
name = name.replace(ch, "-")
return name
def next_month_int(ym_int):
"""YYYYMM(整数) を1ヶ月進めて返す"""
ym_str = str(ym_int)
ym_dt = datetime.strptime(ym_str, "%Y%m")
if ym_dt.month == 12:
next_ym_dt = ym_dt.replace(year=ym_dt.year + 1, month=1)
else:
next_ym_dt = ym_dt.replace(month=ym_dt.month + 1)
return int(next_ym_dt.strftime("%Y%m"))
# =========================================================
# メイン処理
# =========================================================
def main():
# --- 分析したいキーワード順に処理 ---
for target_keyword in TARGET_KEYWORDS:
# --- 期間内のイベントを全部取得 ---
all_events = get_events_in_period(
target_keyword = target_keyword,
start_ym = START_YM,
end_ym = END_YM,
api_endpoint = API_ENDPOINT,
headers = headers,
max_count = MAX_COUNT,
)
# --- 1件もイベントが無ければ、空CSVを出して次のキーワードへ ---
if not all_events:
export_empty_csv(
target_keyword = target_keyword,
start_ym = START_YM,
end_ym = END_YM,
)
continue
# --- DataFrame に変換 ---
df = pd.json_normalize(all_events)
# --- イベント判定 ---
df_event = filter_events_by_keyword(df, target_keyword)
# --- CSV 出力 ---
export_events_to_csv(
df_event = df_event,
target_keyword = target_keyword,
start_ym = START_YM,
end_ym = END_YM,
)
print("---> 終了しました!")
if __name__ == "__main__":
main()
6. イベント判定キーワード (例)
今回使用したイベント判定キーワードのサンプルを以下に示す
プロブラム系キーワード
# --- プロブラム系 ---
# 検索したいキーワードをリストで指定
TARGET_KEYWORDS = [
"C",
"C#",
"C++",
"COBOL",
"Delphi",
"Go",
"Haskell",
"Java",
"JavaScript",
"Kotlin",
"Perl",
"PHP",
"Python",
"R",
"Ruby",
"Rust",
"Scala",
"SQL",
"TypeScript",
"Visual Basic",
]
# 検索結果のイベント判定キーワード(TARGET_KEYWORDSごと)
EVENT_JUDGE_KEYWORDS_MAP = {
"C": ["c言語", "c language", "c programming", "cプログラミング"],
"C#": ["c#", "c-sharp", "csharp", ".net"],
"C++": ["c++", "cpp", "c plus plus"],
"COBOL": ["cobol"],
"Delphi": ["delphi"],
"Go": ["go言語", "golang", "go language"],
"Haskell": ["haskell"],
"Java": ["java"],
"JavaScript": ["javascript", "js", "node.js", "nodejs"],
"Kotlin": ["kotlin"],
"Perl": ["perl"],
"PHP": ["php"],
"Python": ["python", "py"],
"R": ["r言語", "r language", "r programming"],
"Ruby": ["ruby", "rails", "ror"],
"Rust": ["rust"],
"Scala": ["scala"],
"SQL": ["sql", "mysql", "postgresql", "postgres", "oracle", "sqlserver"],
"TypeScript": ["typescript", "ts"],
"Visual Basic": ["visual basic", "vb.net", "vb6", "vb"],
}
クラウドプラットフォーム系キーワード
# --- クラウドプラットフォーム系 ---
# 検索したいキーワードをリストで指定
TARGET_KEYWORDS = ["AWS", "Azure", "GoogleCloud"]
# 検索結果のイベント判定キーワード(TARGET_KEYWORDSごと)
EVENT_JUDGE_KEYWORDS_MAP = {
"AWS": [
"aws",
"amazon web services",
"amazon web service",
],
"Azure": [
"azure",
"microsoft azure",
],
"GoogleCloud": [
"google cloud",
"google cloud platform",
"gcp",
],
}
フロントエンド系キーワード
# --- フロントエンド系 ---
# 検索したいキーワードをリストで指定
TARGET_KEYWORDS = ["Angular", "Next", "React", "Solid", "Svelte", "Vue"]
# 検索結果のイベント判定キーワード(TARGET_KEYWORDSごと)
EVENT_JUDGE_KEYWORDS_MAP = {
# フロントエンド系
"Angular": [
"angular",
"angularjs",
"angular.js",
],
"Next": [
"next.js",
"nextjs",
"next js",
#"next", # ←汎用語なので誤ヒットが気になるならあえて入れない
],
"React": [
"react",
"reactjs",
"react.js",
],
"Solid": [
"solidjs",
"solid.js",
"solid js",
# "solid", # ←これも一般名詞なので、まずは除外しておく
],
"Svelte": [
"svelte",
"sveltekit",
],
"Vue": [
"vue",
"vuejs",
"vue.js",
],
}
技術トピック/技術ドメイン系
# --- 技術トピック/技術ドメイン系 ---
# 検索したいキーワードをリストで指定
TARGET_KEYWORDS = ["AI", "API", "IoT", "Open Source", "クラウド", "セキュリティ", "データ", "データベース", "ネットワーク", "ブロックチェーン", "フロントエンド", "情報システム", "アーキテクチャ"]
# 検索結果のイベント判定キーワード(TARGET_KEYWORDSごと)
EVENT_JUDGE_KEYWORDS_MAP = {
# AI 周辺
"AI": [
"ai",
"人工知能",
"機械学習",
"machine learning",
"deep learning",
"ディープラーニング",
],
# API 周辺
"API": [
"api",
"web api",
"rest api",
"graphql",
],
# IoT
"IoT": [
"iot",
"internet of things",
"モノのインターネット",
"iot開発",
"iot勉強会",
],
# オープンソース
"Open Source": [
"open source",
"オープンソース",
"oss",
"oss開発",
],
# クラウド全般
"クラウド": [
"クラウド",
"cloud",
"cloud computing",
"クラウドサービス",
],
# セキュリティ
"セキュリティ": [
"セキュリティ",
"security",
"cyber security",
"cybersecurity",
"情報セキュリティ",
],
# データ(データ分析・データサイエンス寄り)
"データ": [
"データ分析",
"data analysis",
"データサイエンス",
"data science",
"データ基盤",
"data platform",
"データエンジニア",
"data engineer",
],
# データベース
"データベース": [
"データベース",
"database",
"db設計",
"sql",
"rdbms",
"nosql",
],
# ネットワーク
"ネットワーク": [
"ネットワーク",
"network",
"networking",
"ネットワークエンジニア",
],
# ブロックチェーン
"ブロックチェーン": [
"ブロックチェーン",
"blockchain",
"web3",
"crypto",
"分散台帳",
],
# フロントエンド
"フロントエンド": [
"フロントエンド",
"frontend",
"front-end",
"フロントエンドエンジニア",
],
# 情報システム
"情報システム": [
"情報システム",
"information system",
"社内システム",
"業務システム",
"基幹システム",
],
# アーキテクチャ
"アーキテクチャ": [
"アーキテクチャ",
"architecture",
"システムアーキテクチャ",
"ソフトウェアアーキテクチャ",
"アーキテクチャ設計",
],
}
7. 今後の発展アイデア
① 都道府県・オンライン/オフライン別の集計
-
address/place/lat/lonから以下を算出- オンライン / 現地開催の割合
- 東京・大阪・福岡 など地域別イベント数
② 機械学習や Google API によるイベント判定の高度化
- キーワード判定 → 自然言語処理(NLP)・機械学習分類器へ
- Google Cloud Natural Language API によるカテゴリ推定
③ Google Maps Platform による地図可視化
- Geocoding API で緯度経度を取得
- 地図上にイベントをプロットし、地域トレンドを見える化
8. まとめ
本記事では、connpass API を用いてイベント情報を取得し、JSON → DataFrame への整形、キーワードによるイベント判定、そしてグラフ可視化までの流れを実施しました。
API を活用することで、
- Web画面で手作業検索を繰り返す必要がなくなる
- 大量データを自動で収集・分析できる
- 興味のある技術分野のトレンドを客観的に把握できる
といったメリットを体感することができました。
参考リンク
チャレンジ(Challenge)
この記事を書いている中で、Google API(Gemini) を使えば、connpass のイベントが「本当の Python のイベントかどうか」自動判定できるのでは? と気付き、実際に少し試してみました。
API を使うまでの基本的な流れは、本記事で紹介した手順とほぼ同じです。
- Google API(Gemini)の利用登録を行う
(参考)Gemini APIの料金は?無料で使える範囲や使い方、3つの事例を紹介 - 取得した API キーを、環境変数
GOOGLE_API_KEYに設定する
Google API(Gemini)を使った簡易サンプル
まずは、Gemini にシンプルな質問を投げてみるサンプルコードです。
import os
from google import genai
# 環境変数から API キーを取得
API_KEY = os.environ.get("GOOGLE_API_KEY")
# 利用する Gemini モデル名
MODEL_NAME = "gemini-2.0-flash-lite"
# Google 生成 AI(Gemini)と通信するためのクライアントを作成
client = genai.Client(api_key=API_KEY)
# Gemini に質問し、回答を取得
response = client.models.generate_content(
model=MODEL_NAME,
contents="日本一高い山を教えて"
)
# 生成されたテキスト部分を表示
print(response.text)
実行すると、例えば次のような結果が返ってきます。
日本一高い山は、**富士山**です。標高は3,776.24メートルです。
(無料枠基準) Gemini モデル名一覧
以下に、無料枠で使用可能な Gemini モデル名一覧をまとめます。
この中から、今回は検証用として gemini-2.5-flash-lite を採用しています。
| モデル名 | モデルID | 世代・位置づけ | 1分あたりリクエスト数(RPM) | 1分あたりトークン数(TPM) | 1日あたりリクエスト数(RPD) |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | gemini-2.5-pro |
第2.5世代・上位モデル(Pro) | 2 | 125,000 | 50 |
| Gemini 2.5 Flash | gemini-2.5-flash |
第2.5世代・汎用高速モデル(Flash) | 10 | 250,000 | 250 |
| Gemini 2.5 Flash Lite | gemini-2.5-flash-lite |
第2.5世代・最速/低コストモデル(Flash Lite) | 15 | 250,000 | 1,000 |
| Gemini 2.0 Flash | gemini-2.0-flash |
第2.0世代・旧Flashモデル | 15 | 1,000,000 | 200 |
| Gemini 2.0 Flash Lite | gemini-2.0-flash-lite |
第2.0世代・高速/低コストモデル | 30 | 1,000,000 | 200 |
< 補足 >
- 数値は 無料枠または標準ティアの代表値です。
- コードで使用する際は モデルID(ハイフン区切り小文字) を指定してください。
- Gemini API ドキュメント - モデル
Google API (Gemini) 実装 Pythonイベント判定コード
ここでは、"python" イベントを対象に、connpass API (v2) から取得したイベント情報(CSVファイル)をもとに、Pythonスクリプト + Google API(Gemini) を使い、「本物の Python イベントかどうか」を判定する処理を実装してみます。
イベント判定には、以下の項目を入力として利用します。
- タイトル: title
- キャッチコピー: catch
- ハッシュタグ: hash_tag
- 詳細説明: description
また、Google API(Gemini)には、「Pythonイベントかどうかの判定結果」と「そう判断した理由」 の両方を出力するようにプロンプトを設定しています。
以下に、Google API(Gemini)を利用した Python プログラムのサンプルコードを示します。
import os
import time
import re
import pandas as pd
from google import genai
# --- 設定 ---
API_KEY = os.environ.get("GOOGLE_API_KEY")
# MODEL_NAME = "gemini-2.0-flash-lite"
MODEL_NAME = "gemini-2.5-flash-lite"
# connpass API (v2) から取得したイベント情報(CSVファイル)
INPUT_CSV = "output_202510-202510_python_count_128.csv"
# 判定結果を書き出すCSV
OUTPUT_CSV = "output_202510-202510_python_count_128_for_Gemini.csv"
# 1リクエストごとの待ち時間
SLEEP_SEC = 10.0
# --- Gemini クライアント作成 ---
client = genai.Client(api_key=API_KEY)
# --- CSV 読み込み ---
df = pd.read_csv(INPUT_CSV)
# 判定結果(0/1)と理由を入れるリスト
judgements = []
reasons = []
# --- 各行ごとに Gemini で判定 ---
for idx, row in df.iterrows():
# --- タイトル ---
value = row.get("title")
if pd.isna(value):
title = ""
else:
title = str(value)
# --- キャッチコピー ---
value = row.get("catch")
if pd.isna(value):
catch = ""
else:
catch = str(value)
# --- ハッシュタグ ---
value = row.get("hash_tag")
if pd.isna(value):
hash_tag = ""
else:
hash_tag = str(value)
# --- 詳細説明 ---
value = row.get("description")
if pd.isna(value):
description_raw = ""
else:
description_raw = str(value)
# --- 開催日 ---
value = row.get("started_at")
if pd.isna(value):
started_at = ""
else:
started_at = str(value)
# --- イベント ---
value = row.get("url")
if pd.isna(value):
url = ""
else:
url = str(value)
# グループ名
value = row.get("group_title")
if pd.isna(value):
group_title = ""
else:
group_title = str(value)
# --- プロンプト組み立て ---
prompt = f'''
あなたは「イベントの内容が Python のイベントであるかどうか」を精密に判定する専門家です。
以下に示すイベント情報を読み、「本物の Python イベント」かどうかを判定してください。
# 判定の基本方針
Python のイベントであるかどうかは、イベントの主目的・内容・テーマが「Python の学習・開発
・実践であること」を基準としてください。
# 判定ルール(厳守)
## 「1」(Pythonイベントである)の条件
- タイトル、キャッチコピー または ハッシュタグ に Python というキーワードが含まれている。
- Python プログラミング、Python ライブラリ(例: Django, FastAPI, pandas, NumPy など)、
Python を使った機械学習・データ分析・自動化 などが主なテーマになっている。
- 詳細説明の中心が Python である。
## 「0」(Pythonイベントではない)の条件
- Python は例として軽く触れるだけで、メインテーマは別の技術やサービスである。
- 勉強会、子ども向けプログラミング教室などで、Python 以外(Scratch など)のプログラミング言語が含まれている。
## 「0」特別ルール(講師紹介だけに Python が出てくるケース)
- 「Python」というキーワードが、次のような「プロフィール紹介」部分にしか登場しない場合は、
必ず 0(Python イベントではない)と判定してください。
- 「講師紹介」「登壇者紹介」「登壇者プロフィール」「スピーカー紹介」
- 「主催者」「主催者情報」「Organizer」「Organizer & Co-Chairs」
- 「著書紹介」「登壇歴」「経歴」「メンター紹介」などのテキスト
# 観点(以下のキーワードが含まれる場合の扱い)
以下の語が含まれていても、「Python 学習・開発」が主目的でなければ 0(偽)と判定してください。
- CoderDojo
- 小中学生向けプログラミング
- イベント運営・交流会
- AI / 生成AI / LLM / ChatGPT / 機械学習(Python 実装が主目的でない場合 など)
# 判定に使用してよい情報
イベント判定は、次の項目だけを使って行ってください。
- タイトル: title
- キャッチコピー: catch
- ハッシュタグ: hash_tag
- 詳細説明: description_raw
# 判定対象のイベント情報
- 開催日時 (started_at): {started_at}
- タイトル (title): {title}
- キャッチコピー (catch): {catch}
- ハッシュタグ (hash_tag): {hash_tag}
- グループ名: {group_title}
- 詳細説明(description): {description_raw}
# 出力形式(絶対に守ること)
1行目: このイベントが「Python イベント」であれば 1、そうでなければ 0 を、半角数字1文字だけで出力してください。
2行目以降: その判定理由を、日本語で簡潔に説明してください。
出力例:
1
タイトルと説明文の中心が Python 入門ハンズオンであり、Python の学習が主目的であるため。
'''
# --- Gemini 呼び出し ---
response = client.models.generate_content(
model=MODEL_NAME,
contents=prompt,
)
# --- Gemini 応答 ---
raw_text = (response.text or "").strip()
if not raw_text:
label = 0
reason = "Gemini からの応答が空だったため、非Pythonイベント(0)として扱った。"
else:
# Gemini 応答を改行ごとに分割」し、リスト化
lines = raw_text.splitlines()
# リスト化した1行目の要素を取り出し
first_line = lines[0].strip()
# 2行目以降を「判定理由」として保存
if len(lines) >= 2:
reason = "\n".join(lines[1:]).strip()
else:
reason = ""
if first_line == "1":
label = 1
elif first_line == "0":
label = 0
else:
# 想定外の出力の場合
label = 0
if reason:
reason = f"出力形式が想定外だったため 0 とした。元の出力: {raw_text}"
else:
reason = f"出力形式が想定外だったため 0 とした。元の出力: {raw_text}"
# リストに追加
judgements.append(label)
reasons.append(reason)
# コンソールに理由の先頭だけ表示(デバッグ用)
short_reason = reason.replace("\n", " ")
if len(short_reason) > 40:
short_reason = short_reason[:40] + "..."
print(f"[{idx+1}/{len(df)}] id={row.get('id')} -> {label} | {short_reason}")
# リクエストの間隔
time.sleep(SLEEP_SEC)
# --- 最終出力用の DataFrame 作成 ---
output_df = pd.DataFrame({
"event判定": judgements,
"id": df.get("id"),
"title": df.get("title"),
"catch": df.get("catch"),
"url": df.get("url"),
"hash_tag": df.get("hash_tag"),
"started_at": df.get("started_at"),
"判定理由": reasons,
})
output_df.to_csv(OUTPUT_CSV, index=False, encoding="utf-8-sig")
print(f"---> 判定付きCSVを出力しました: {OUTPUT_CSV}")
検証のため、2025年10月および11月に開催されたイベントについて、本記事の Python プログラムと Google API(Gemini)による判定結果を比較したものを、以下に示します。
| Pythonイベント | 本記事のPython判定 | Geminiによる判定(※) |
|---|---|---|
| 2025年10月 | 37 | 26 |
| 2025年11月 | 38 | 31 |
※補足:今回のGeminiによる判定検証結果について、イベント判定は概ね良好でしたが、2025年10月分のデータにおいて、Python と無関係のイベントが 1 件だけ「Pythonイベント」と誤判定されていました(目視確認による)。
本記事の Python プログラムでは「Pythonイベント」と判定された一方で、Gemini では「Pythonイベントではない」と判定されたイベントの内容を確認したところ、Gemini の方が詳細説明などを踏まえて厳密に判定しており、より精度の高い判定ができていると考えられます。
以下に、本記事の Python プログラムでは「Pythonイベント」と判定されたものの、Gemini ではそう判定されなかったケースについて、Gemini が返した判定理由の例を示します。
-
Python ボルダリング部 #207
(Gemini判定理由):タイトルに「Python」というキーワードが含まれていますが、イベントの主目的はボルダリングであり、Python の学習・開発・実践が中心テーマではないため。「Python 関係ない人の参加も是非どうぞ。」という記載や、Python が例として軽く触れられているだけであることから、Python イベントではないと判定しました。 -
【新無料講座】なぜ?を科学で解き明かそう!ゼロから始める 因果推論の世界【書籍出版記念】
(Gemini判定理由):キャッチコピーでPythonデータ分析に触れているものの、イベントの主目的は「因果推論」という統計学・データ分析の概念の入門であり、Pythonはそのためのツールとして軽く触れられているに過ぎないため。講師紹介にPythonが記載されているが、これはプロフィール紹介の一部であるため、特別ルールに該当する。 -
NVIDIA NIM × DataRobotが拓くAIエージェントの新時代
(Gemini判定理由):ハッシュタグに「Python」というキーワードは含まれていますが、イベントの主目的は「NVIDIA NIM × DataRobot」を活用したAIエージェント開発であり、PythonはあくまでDataRobotの機能を紹介する一環で軽く触れられているに過ぎないため。
まとめ
- プロンプト設計を適切に行うことで、Google API(Gemini)でも精度の高いイベント判定が可能であることが分かった。
- ただし、Google API(Gemini)による判定は精度は高いものの、自宅環境では「1か月分のイベント判定に約30分程度」かかり、本記事の Python プログラム(キーワード判定方式)は「数分程度」で実行できるという差が出た。
- そのため、Google API(Gemini)を利用すべきかどうかは、取得したい情報の目的によって使い分ける必要がある。
- 高精度に判定したい → Google API(Gemini)
- 大量データを高速に処理したい → Python プログラム(キーワード判定)
「スピードを取るか、精度を取るか。」 API・AI時代のデータ活用では、この使い分けが今後ますます重要になると実感した。