0.はじめに
- 僕は30年以上のSE人生で様々な業務システム開発にデータベーススペシャリストやシステムアーキテクトとして参加してきました
- その中で 「DB設計の失敗」 がどれほど後々まで影響するかを何度も見てきました
(多くの場合、結合テスト以降で パフォーマンスが出ずに問題が露見🔥🔥 ) - 昔の僕は正規化原理主義でしたが、今は正規化をあえて一部で崩し 「意図的に正規化を緩和」 してます
😖 既存のDBの蓋を開けると…
❌ 当然のように ER図が存在しない
( 設計書の中で 最重要 と思ってます )
❌ 全然 参照整合性制約が無いからテーブル間の関連は自力で全部読み解くしかない
❌ 参照整合性制約が無いから、参照先のマスタに値があるか保証は無い
(保証が無いから常にleft join)
❌ 削除フラグに 0,1 だけでなく null や 9 など入っていて、どう扱うべきか分からない
❌ 1つの列に複数の意味を持たせている。(削除フラグ=9は強制削除など)
❌ 列の名前が不十分で良く分からない
( 例えば「請求フラグ」だけでは "請求済み" なのか "請求対象" なのか分かりずらい)
✅ こんな問題を引き起こさないために
- 最高の設計ポリシーが1つだけあってその他はダメ、ということではなく実際はケースバイケースなことが多いです
- ただし、「分かってはいるけれど既存データが〇〇だからここは妥協する」のと、何も考えていないのは全然違います
あなたの職場やプロジェクトに合わせてカスタマイズしてください
1.DB設計の基本
✅ DBの寿命と価値
- 開発するアプリよりDBの構造とその中のデータの寿命の方がはるかに長い
- 不正なデータが混ざってしまうと、そのデータは使えない
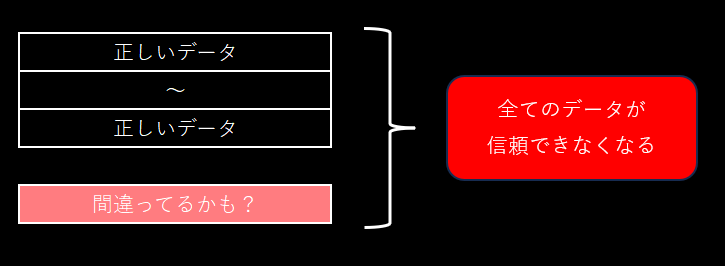
あなたの銀行残高が、「多分なんとなく正しいはず」では困りますよね
✅ 不正なデータが混ざらないようにできること
- DBの列はできるだけnot nullで設計する
- できる限り型を限定する
- ON/OFFしかないならbool型にする
- 日付は date 型を利用する
- 入力して良い値が限定されているならCHECK制約を付ける
つまり入って良いデータをできるだけ限定する。
構造的に不正なデータが入れられないようにする
→ 型安全性とデータ整合性の確保
❓ なぜできるだけnot nullで設計するのか?
- selectする時に常にnullの場合に配慮することは合理的か?
select isnull(氏名, '氏名不明') as 氏名
- そもそも null の状態で登録する事は健全か?
(少なくとも社員マスタの「氏名」がnullのデータを登録できてよいのか?)
僕のDB設計の師匠は「日本にRDBを初めて導入普及したエンジニアの一人」とされている方です。
師匠は昔「null の可能性のある列は原則別テーブルに分離しろ!」という超過激派でした。
✅ 良いCREATE文
create table 社員 (
ID int identity not null primary key
, 社員番号 varchar(10) not null unique
constraint CK_社員_社員番号 check (len(社員番号) = 10)
, 氏名 nvarchar(50) not null
constraint CK_社員_氏名 check (len(氏名) >= 2)
, 生年月日 date not null
, 職級 int not null
constraint CK_社員_職級 check (職級 in (1, 2, 3))
)
💎 良い点
- 社員番号は在職中に変更されるケースもある(お客様の社内ルールに依存)
→ Primary Keyにすべきではない - 社員番号は Primary Key ではないが unique にすることで重複は排除できる
- 社員番号と氏名に長さの制約があり、空文字などは登録できない
- 氏名、生年月日、職級など not null 制約により値が保証される
- 職級は数値の1,2,3しか取りえないことが保証される
✅ 悪いCREATE文
create table 社員 (
社員番号 nvarchar(10) primary key
, 氏名 nvarchar(50)
, 生年月日 varchar(10)
, 職級 char(1)
)
🚫 悪い点
- 社員番号がPrimary Key
- 社員番号や氏名に長さの制約が無いので、空文字などありえる
- 氏名、生年月日、職級など nullがありえる
- 職級に存在しない 4 や A などがありえる
❓ なぜできるだけ日付型を利用するのか?
- 日付としての意味が保証される
- 演算・関数が使える(dateadd, datediff など)
- ソートや比較が正しくできる
- ストレージ効率(date は固定3バイト、varchar(10) は最大12バイト)
✅ CREATE文をさらに拡張
先ほどの良いCREATE文の職級の制約で
「将来職級が増えたらどうするの?」と思った方はセンスが良いです。
constraint CK_社員_職級 check (職級 in (1, 2, 3))
将来変更される可能性が高いビジネスルールは、データ構造で表現します。
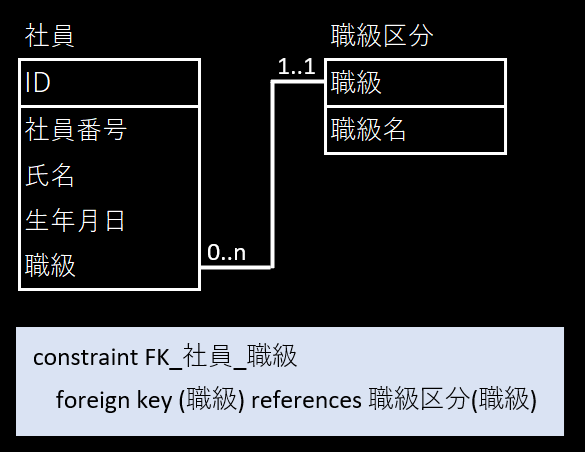
create table 職級区分 (
職級 int not null primary key
, 職級名 nvarchar(20) not null
constraint CK_職級区分_職級名 check (len(職級名) >= 2)
)
create table 社員 (
ID int identity not null primary key
, 社員番号 varchar(10) not null unique
constraint CK_社員_社員番号 check (len(社員番号) = 10)
, 氏名 nvarchar(50) not null
constraint CK_社員_氏名 check (len(氏名) >= 2)
, 生年月日 date not null
, 職級 int not null
, constraint FK_社員_職級 foreign key (職級) references 職級区分(職級)
)
💎 良い点
- 職級を専用のテーブルに分離
- 将来的な職級の追加にデータ構造の変更なく対応できる
DB設計(データ構造)でビジネスルールを表すのが最善
RDBとはリレーショナルDB。リレーションが大切。
✅ 悪い拡張の例(実務では時々見かける)
create table 汎用区分 (
ID int identity not null primary key
, 区分種類 varchar(10)
, 区分コード varchar(10) not null
, 区分名 nvarchar(20) not null
)
create table 社員 (
ID int identity not null primary key
, 社員番号 varchar(10) not null unique
, 氏名 nvarchar(50) not null
, 生年月日 date not null
, 職級 int not null
)
- キーと名称の組み合わせを汎用テーブルで保持する設計
- 一見効率的に見えるが、そもそも社員の職級が取れる値を制限する目的を実現してない
DBにできる限り不正なデータを入れさせない趣旨と反している
💎 参照整合性制約(foreign key)の価値
✅ 参照整合性制約がある場合のSELECT文
select
s.社員番号
, s.氏名
, c.職級名
from 社員 s
join 職級区分 c
on s.職級 = c.職級
💎 良い点
- 等結合できる
(社員マスタの職級は、必ず職級区分に存在することが 「保証」 されている)
✅ 参照整合性制約が「ない」場合のSELECT文
select
s.社員番号
, s.氏名
, isnull(c.職級名, '職級不明') as 職級名
from 社員 s
left join 汎用区分 c
on s.職級 = c.職級
and c.区分種類 = '職級'
🚫 悪い点
- DBに制約が無い以上、外部結合するしかない
- 保証されていない以上、joinできなかった場合のことを常に考える必要がある
- こちらのSELECT文の方が一般的に負荷が高く遅い
2.効率よくSELECTできるかを常に意識してDB設計する
- データは読んで利用するために登録される
- 登録や修正される回数より、読み取られる回数の方が圧倒的に多い
- つまり登録/更新しやすい構造よりも、読み取りやすい構造を優先する
パフォーマンスの重要度
SELECT >>>>>>>> INSERT/UPDATE/DELETE
3.SELECT効率を悪化させるグレーケース
3.1 ✅ グレーケース(1): 論理削除フラグ
- 実務では頻繁にみかける設計
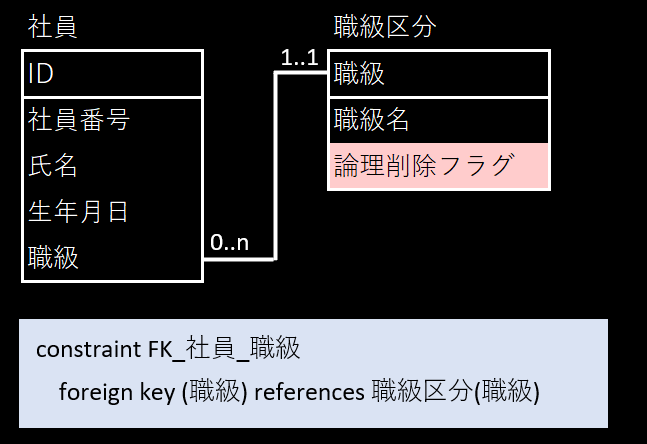
🚫 悪い点
- 生きているデータと削除済みのデータが混在するので、KEYが重複しUNIQUE制約が利用できない
- データの安全を保障する参照整合性制約の意味が薄くなる
- select 時に常に論理削除フラグを意識する必要がある
- 過去の状態を残したいという保険が 全体へ悪影響を与えるために本末転倒
🚀 改善策:論理削除結果は履歴テーブルへ移送する

- 過去の状態は別テーブルにする
- 変更前や削除前の状態をトリガーやリポジトリで別テーブルへ書き込む
3.2 ✅ グレーケース(2): マスターに有効期間
- 実務では時々みかけるパフォーマンス悪化につながる極めて危険な設計

select
s.氏名
, c.職級名
from 社員 s
left join 職級区分 c
on s.職級 = c.職級
and GetDate() between c.有効開始日 and c.有効終了日
🚫 悪い点
- SELECT文の複雑さが全てを物語っている。パフォーマンスが出るわけがない
(設計は積み重ねなので、この複雑さがシステム全体へ波及する) - もはや参照整合性制約を張る意味がない
🚀 改善策①:過去データは履歴へ移送する
- 論理削除フラグと同様 別テーブルで管理する
🚀 改善策②:未来データについて
- 来月から商品単価の値上げなど、影響が大きく事前に変更される日付と変更内容が分かるものもある
- 基本的に未来データは扱いが難しいので個別に設計する
- 消費税に関しては次章参照
3.3 ✅ グレーケース(3): 未来データ(消費税)の扱い
消費税率が改訂される日の朝一に、システム設定の消費税率を変更しても上手く行かないことが多いです。
例)
- 2019/10/1に 消費税率が 8% → 10% へ変更された
- 10/1の朝一にシステム設定の消費税率を 10% へ変更した
- 10/1に10/1の売上データを登録する時 消費税率は 10% で計算された → これは正しい
- 10/1に「過去」の 9/30 の売上データを登録したときも 消費税率は 10% で計算された → これはダメ 8%が正しい
🚀 お勧めのデータ構造

- 消費税率に関しては期間毎に持たざるを得ない
- 売上データなどに採用した消費税率を直接保存する
(消費税率IDは保持しても良いがほとんど意味はない)
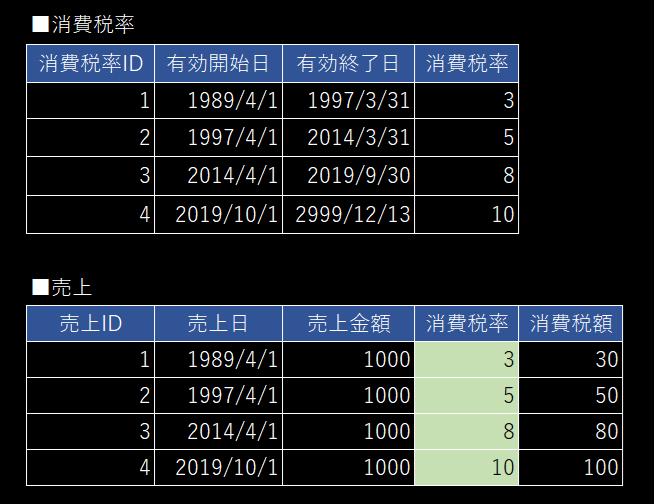
- 売上にデータを登録、修正するとき「売上日」から「消費税率」を取得
- 売上に保持される「消費税額」を計算した根拠となる「消費税率」を売上にも記録
- 今、消費税率IDに関数従属する消費税率を売上に持つことで正規化を外れました
- マスタの構造は正規化すべきですが トランザクションに関してはその限りでは無いと思っています
🚀 この考え方を発展させると?
✅ トランザクションへマスタ情報を焼き付ける
- 取引先の「ハカマタソフト」と長い付き合いがある
- 「ハカマタソフト」は 2025/10/1 から屋号を 「チキチキソフト」 へ変更するとしたら・・・
✅ 一般的なデータ構造
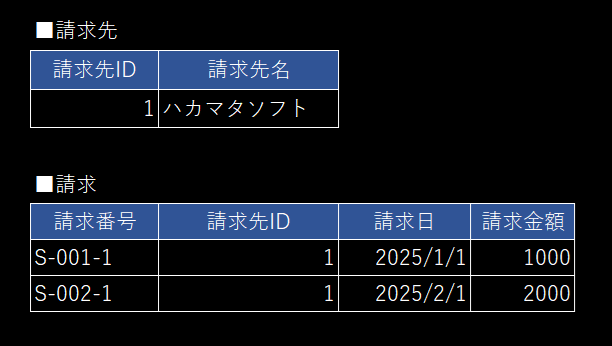
✅ 取引先の社名変更への対応策
| お勧め度 | 対応策 | メリット | デメリット |
|---|---|---|---|
| ★☆☆ | 変更日に請求先マスタの請求先名を変更 | 簡単 低コスト | 過去の請求書は過去の宛名で再現できない |
| ★☆☆ | 変更後の請求先名を請求先マスタに追加する | 簡単 低コスト | 請求先IDでの請求額の推移確認が難しい |
| ☆☆☆ | 請求先を期間ごとに保持 | 過去の請求書は過去の宛名で再現できる | システムが極めて複雑になる |
| ★★★ | 先の消費税率と同じように請求データに請求先名を記録 | 簡単 低コスト | データ量が増える(無視できるレベル) |
- トランザクションは発生したタイミングでの履歴です
- 履歴に必要十分な情報(マスタの情報含む)を記録するのは自然と思います
✅ トランザクションに必要なマスタ情報を焼き付ける
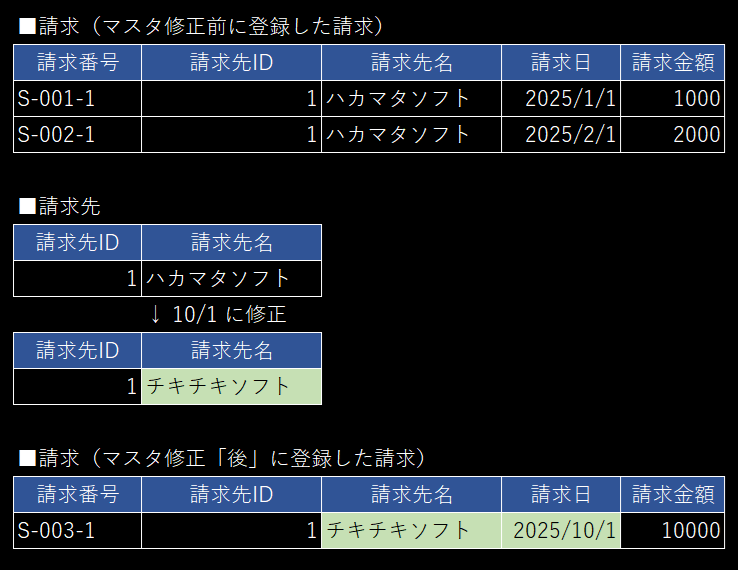
仮にマスタを変更しても、請求書を再発行したら前回と同じ請求書が出るのが自然と思います
昔はデータストレージのコストが高く、できるだけデータを縮小する発想が重要でした。(西暦ですら後ろ2桁しか持たないなど)
でも、今はストレージのコストが圧倒的に安いので、必要な情報はできるだけそのまま保管するメリットの方が大きいと思います。
4.トランザクション管理の重要性
✅ 銀行の入金処理を例に考えます。
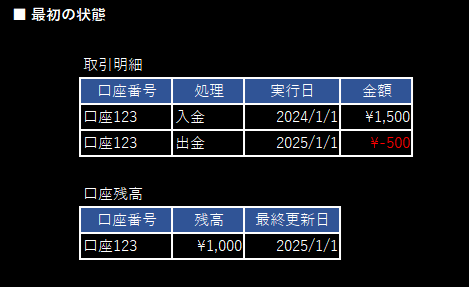
① 取引明細に入金の実績を記録する。
② 口座残高に入金額を追加して更新する。
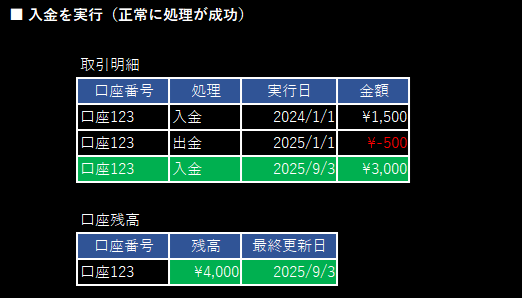
この2つの処理はセットで、
- 両方が正しく実行された
- どちらか一方が失敗したら両方無かったことにする
✅ 正しいトランザクション管理
begin try
/* トランザクションの開始を宣言 */
begin tran;
insert into 取引明細 (口座番号, 処理, 実行日, 金額)
values ('口座123', '入金', '2025-09-03', 3000);
update 口座残高
set 残高 = 残高 + 3000
where 口座番号 = '口座123';
/* データ更新を確定 */
commit;
end try
begin catch
/* エラー発生時はロールバックを明示 */
rollback;
end catch
✅ トランザクション管理をしていない場合
insert into 取引明細 (口座番号, 処理, 実行日, 金額)
values ('口座123', '入金', '2025-09-03', 3000);
update 口座残高
set 残高 = 残高 + 3000
where 口座番号 = '口座123';
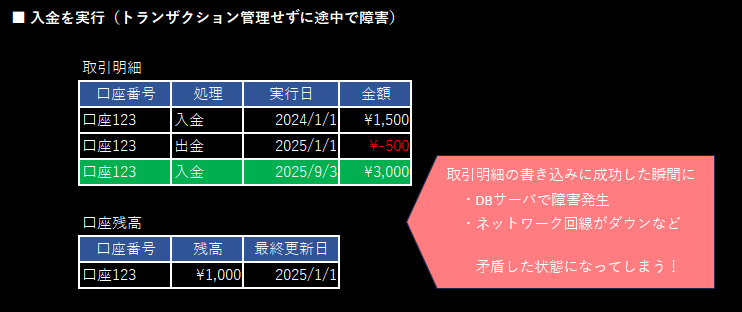
入金実績のinser直後に障害が発生(ネットワーク回線の切断など)すると、入金実績のみが記録され残高が更新されません。
複数のSQLが「セットで成功」か「なかったこと」にする場合、必ずトランザクション管理します
5.排他制御
✅ ネット通販の在庫管理を考えます

排他制御しなければ矛盾が発生してしまう
✅ 改善方法:楽観的排他制御の実装
- 排他制御用にVersion列を追加します
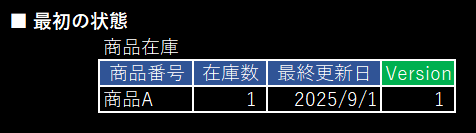
/* 最初に在庫数を確認するときに Version も取得 */
select 在庫数, Version from 商品在庫
where 商品番号 = '商品A'
;
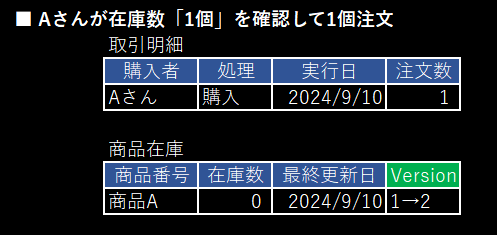
/* Update時に同じ Version に対してのみupdateを実行 */
update 商品在庫
set 在庫数 = 在庫数 - 1
where 商品番号 = '商品A'
and Version = 1;
✅ このupdate文の実行結果が
- 1行なら更新に成功
- 0行なら他の方が在庫数を書き換えている(同じVersionのデータが無い)
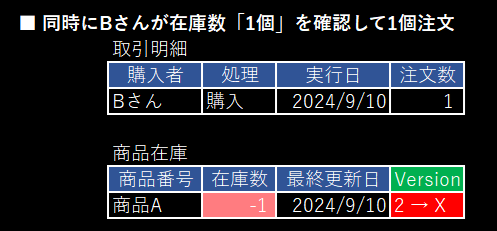
Bさんの購入は在庫数の更新結果=0行になるので失敗です。
取引明細のinsertもロールバックします。
✅ 悲観的排他ロックに関して
- webを中心に現代はステートレスな設計が主流です
- そういう意味で「悲観的排他ロック」を必要とする業務は限られるのでここでの説明は割愛します
6.まとめ
- 🗂 DB設計はアプリより寿命が長い
- 🔒 不正データは構造で防ぐ
- 🚀 SELECT効率を最優先
- 🕑 履歴は履歴テーブルに移す
- 🔄 トランザクションと排他制御は必須