はじめに
Project Bonsaiについて調べてみましたの2回目です。
一回目はこちら「Bonsaiを触ってみる」
前回は、チュートリアルをそのまま実行しただけなので、今回は学習カリキュラム(Inklingコード)を、変えてみたいと思います。
Bonsaiって何?
Microsoftが提供している自律システム向け機械教示サービスです。(現在はPublic Preview)
産業制御システムに焦点を当てた汎用ディープ強化学習プラットフォームのようです
目標を変えてみる。
動かすのはできたので、次は目標の内容を変えてみたいと思います。
現状チュートリアルの目標は、
- Poleの角度を、12度以上傾けないようにする
- Cartの位置を、0.25m以上動かないようする
Poleを維持するだけでなく、Cartを前方に進むようにしたいと思います。
目標の指定方法
Inklingコードのgoalで設定することができます。
Goalがサポートしている目標は以下の通り
Goalの目標
| 目標 | 動作 | 成功条件 |
|---|---|---|
| avoid | シミュレート結果が特定の状態にならないように維持します。 | 指定の状態にならなければ 成功 |
| drive | できるだけ早く指定された状態にし、その状態を維持します | 反復中に指定された状態の範囲に戻る場合は 成功 |
| maxmize | 特定の状態の平均値を、指定された範囲内で可能な限り大きくするようにします | トレーニング中の平均テスト値が範囲内の下限を上回っている場合は 成功 |
| minimize | 特定の状態の平均値を、指定された範囲内で可能な限り小さくするようにします。 | トレーニング中の平均テスト値が範囲内の上限を下回っている場合は 成功 |
| reach | きるだけ早く指定された状態に移行させるが、維持する必要はない | テスト値が規定の範囲内に少なくとも1回収まると、成功 |
ゴールの範囲
| 定義 | 範囲 |
|---|---|
| Goal.Range(X, Y) | X と Y の間の値 (X と Y を含む) |
| Goal.RangeAbove(X) | X 以上 の値 |
| Goal.RangeBelow(X) | X 以下 の値 |
| Goal.Sphere(X, R) | 半径 R、中心ポイント (X) の 1D 球 (線) 内の値 |
| Goal.Sphere([X, Y], R) | 半径 R、中心ポイント (X, Y) の 2D 球 (円) 内の値 |
| Goal.Sphere([X, Y, Z], R) | 半径 R、中心ポイント (X, Y, Z) の 3D 球内の値 |
| ※テスト値の次元と、提供された範囲の次元は一致させる必要があります。 | |
| 例えば、3次元上で動くものが定義されている場合は、テスト値も3次元空間内の位置に対応している必要があります。 |
補足
目標を使ったGoalの設定が推奨されているようですが、報酬関数や、ターミナル関数という方法を使用して指定することも可能なようです。
「報酬関数とターミナル関数」に記述方法が記載されていますが、一般的なプログラムの書き方に似ているので、機会があれば使ってみたいと思います。
goalの修正
Cartを前方に進ますために、以下のようにGoal条件を修正
goal (State: SimState) {
avoid `Fall Over`:
Math.Abs(State.pole_angle)
in Goal.RangeAbove(MaxPoleAngle)
avoid `Out Of Range`:
Math.Abs(State.cart_position)
in Goal.RangeAbove(TrackLength / 2)
}
Cartの位置を維持するだけのOut Of Rangeを削除し、
cart_positionが前向きに2m以上で一番大きくなるようなmoveを追加しています。
goal (State: SimState) {
avoid `Fall Over`:
Math.Abs(State.pole_angle)
in Goal.RangeAbove(MaxPoleAngle)
maximize `move`:
State.cart_position
in Goal.RangeAbove(2)
}
実行する
教育カリキュラムの修正が終わったので、
前回と同じように「Train」ボタンをクリックして、学習を始めます。
余談
ちなみに余談ですが、教育カリキュラムの内容が変わると自動的にバージョン管理されていきます。
変更後も前回の学習を活用することが可能です。
※そもそも一度学習が完了すると、教育カリキュラムを変えるか、学習回数を増やさない限り学習を実行できません。
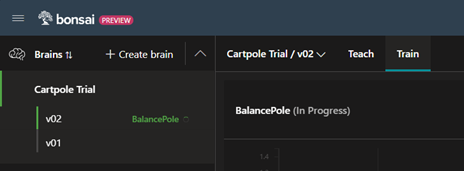
何かおかしい。
13分(前回の半分程度)実行したけど、目標の達成率が伸びていないです。
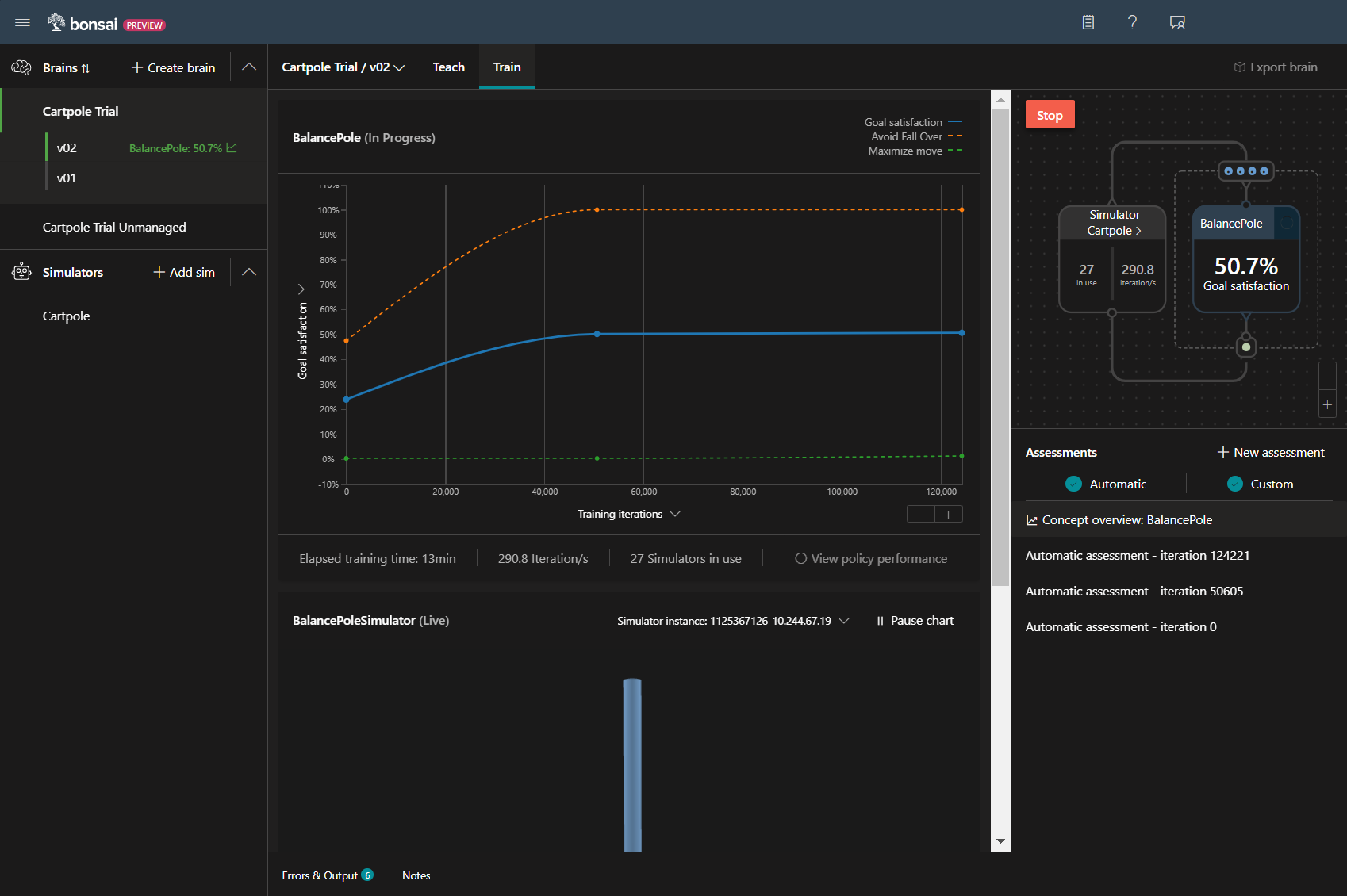
グラフ見ると、Poleを倒さない目標(青線)はほぼ100%達成しているけど、2m移動させる目標(緑線)が全然達成で来ていない事がわかります。
入力値を変更
教育カリキュラムを見直した結果、入力値の移動距離が少ないが原因ではないかと過程し、
もっとがっつり動くように移動範囲を修正してみました。
type SimAction {
command: number<-1 .. 1>
}
type SimAction {
command: number<-3 .. 3>
}
再度実行!
今回も14分くらい学習を実行しました。
前よりも3%ほど改善していますが、まだまだ目的が遠そうです。
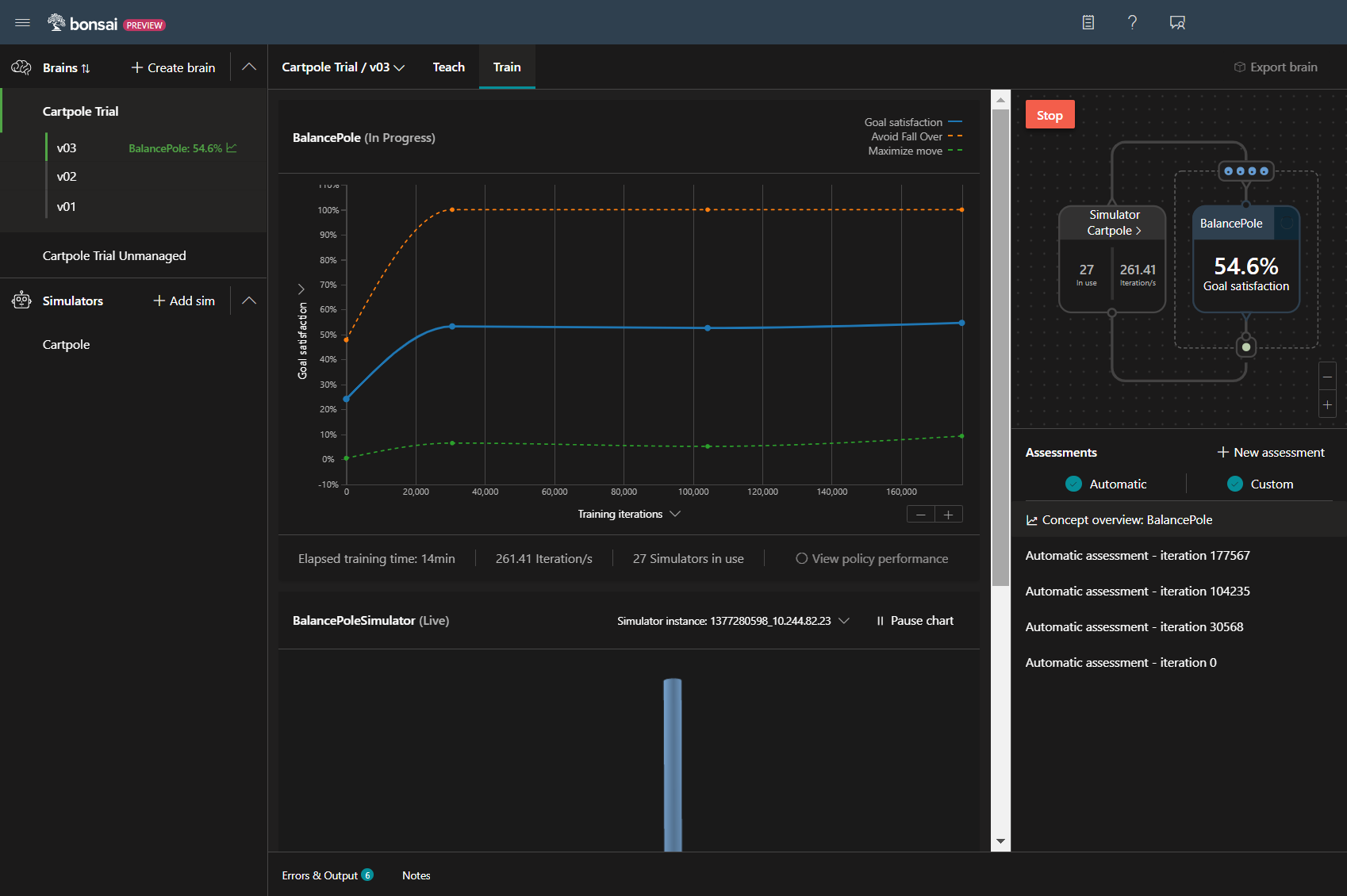
合わせて、データグラフも確認してみると、
pole_angleは、安定し、cart_positionも順調に右移動しています。
動きは問題ないので、目標に達するまでに反復回数が終わるの問題と判断しました。
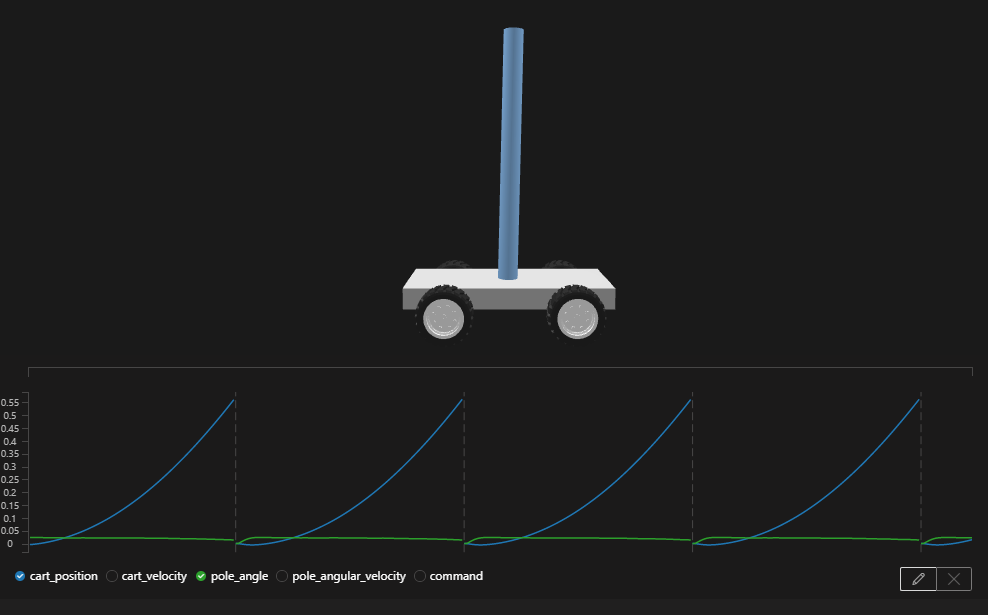
反復回数を増やす
120回で0.55m進んでいるので、2m進めるためにとりあえず回数を4倍に変更してみます。
training {
EpisodeIterationLimit: 120
}
training {
EpisodeIterationLimit: 480
}
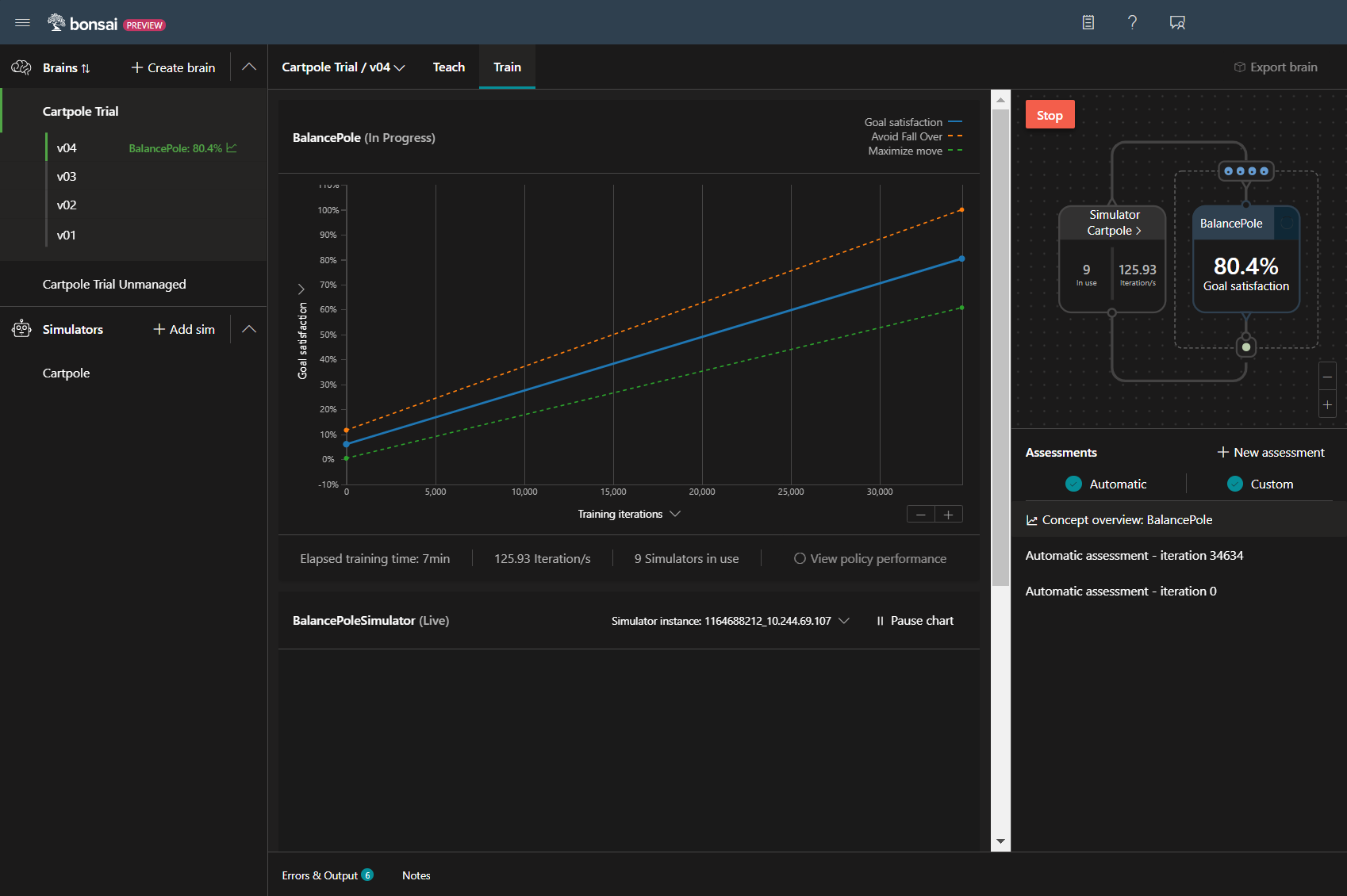
3度目の正直!
ついに目標100%の達成が見えてきました!
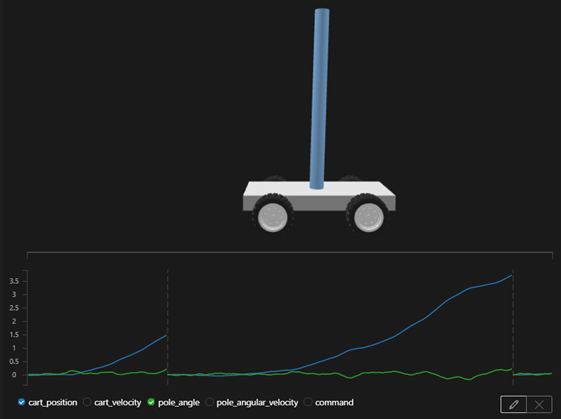
失敗するパターンもまだありますが、目標である2mを進むを達成する状況もでてきてます。
このまま、学習が終了するまで待ってみます。
ついに終了!
前回のPoleを保持する学習が28分でしたが、今回は148分なので、4倍にした反復回数以上に増えてます。
変更前は約10万回の反復で目標達成率が100%に達していましたが、
今回は、30万回の反復が必要になるなど、難易度があがっていることがわかります。
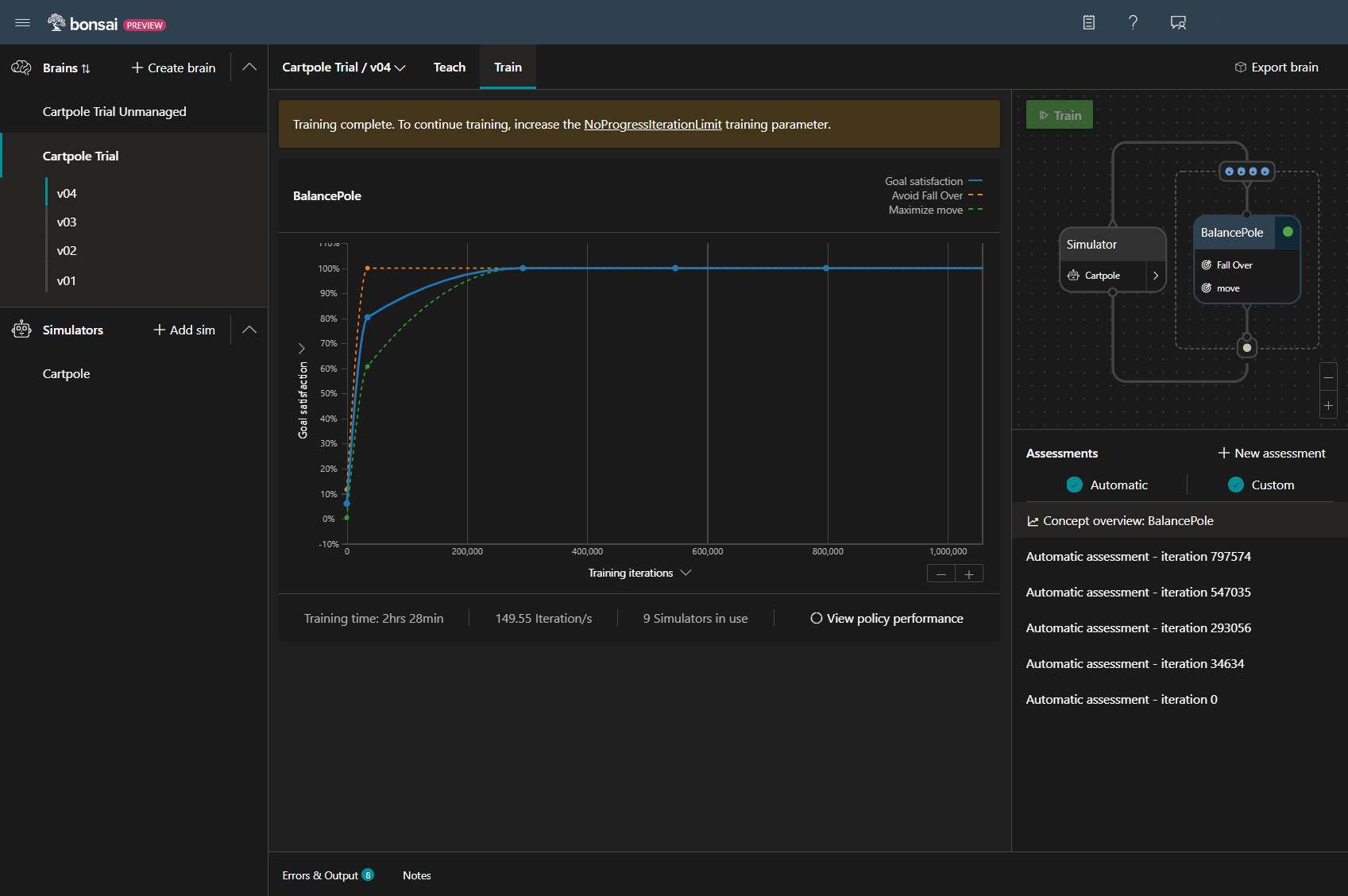
目標は2m以上としていましたが、結果として45mも進むようになっています。
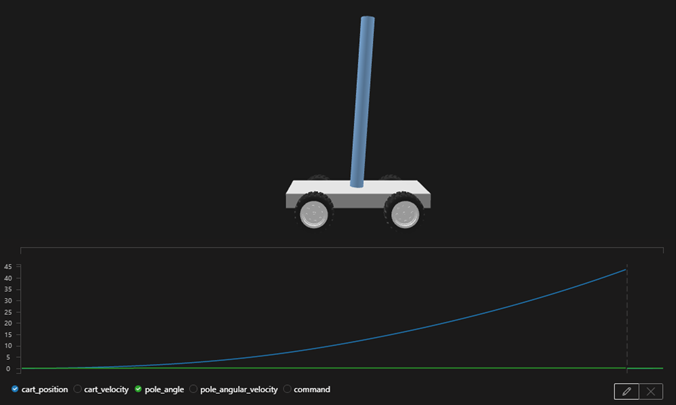
気になるから実行
ここで思ったのがSimActionの変更不要だったのでは?ということです。
移動量を戻して、反復回数を増やすパターンも試してみました。
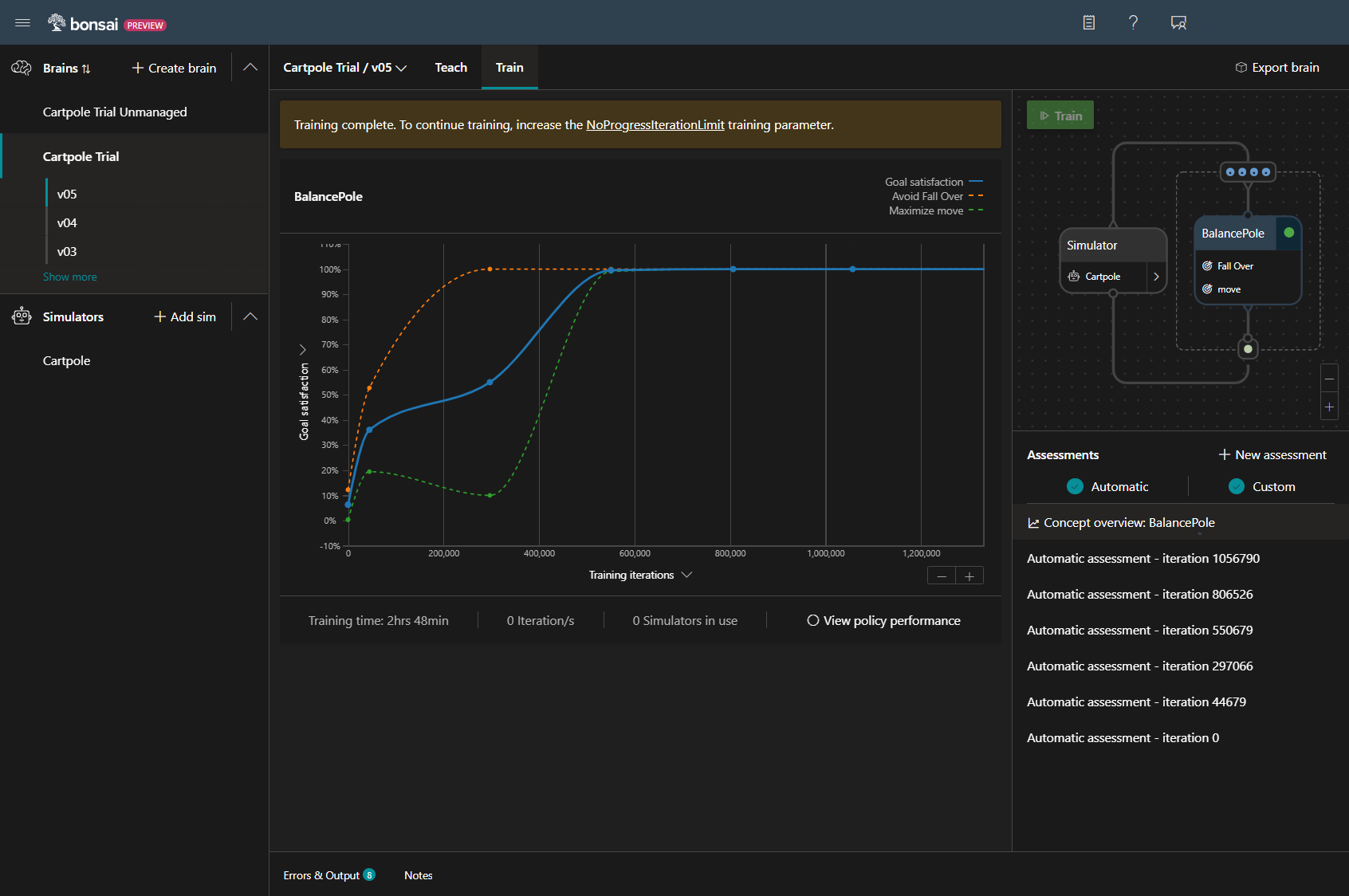
無事に、学習が完了しました。移動量は関係なかったようです。。
ちなみに、移動範囲を小さくした場合の移動量は26mほどでした。
まとめ
教育カリキュラムの修正で、目的の結果は得られたかなと思います。
何度か失敗をしたため、注意する点に気づけたのも大きいです。
※どんどんお金がかかるのはちょっと痛いですが・・
今回は、教育カリキュラムをいじったので、次はシミュレータを触ってみたと思います。