はじめに
Robotics: Science and Systems (RSS) 2025より以下の論文
[1] Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets. Robotics: Science and Systems (RSS) 2025
のまとめ、その(1)
その(2)はこちら
https://qiita.com/masataka46/items/053158912d319852161d
project page
ICML 2025 の “Building Physically Plausible World Models” workshop で Best Paper Awardと書かれている。
github
1. 概要
- 模倣学習用のデータセットは有益だが、作成コストの高さ故に数が少なく、その結果多様性が小さい
- 行動のannotationが付与されてないDatasetは多様性が大きいいが利用しにくい
- 本手法はそれら両方をworld modelを用いて活かすもの
- 具体的には、diffusionモデルのタイムスタンプを利用して両方のdatasetで学習できるように工夫した
こちらの画像(公式サイトより)のように
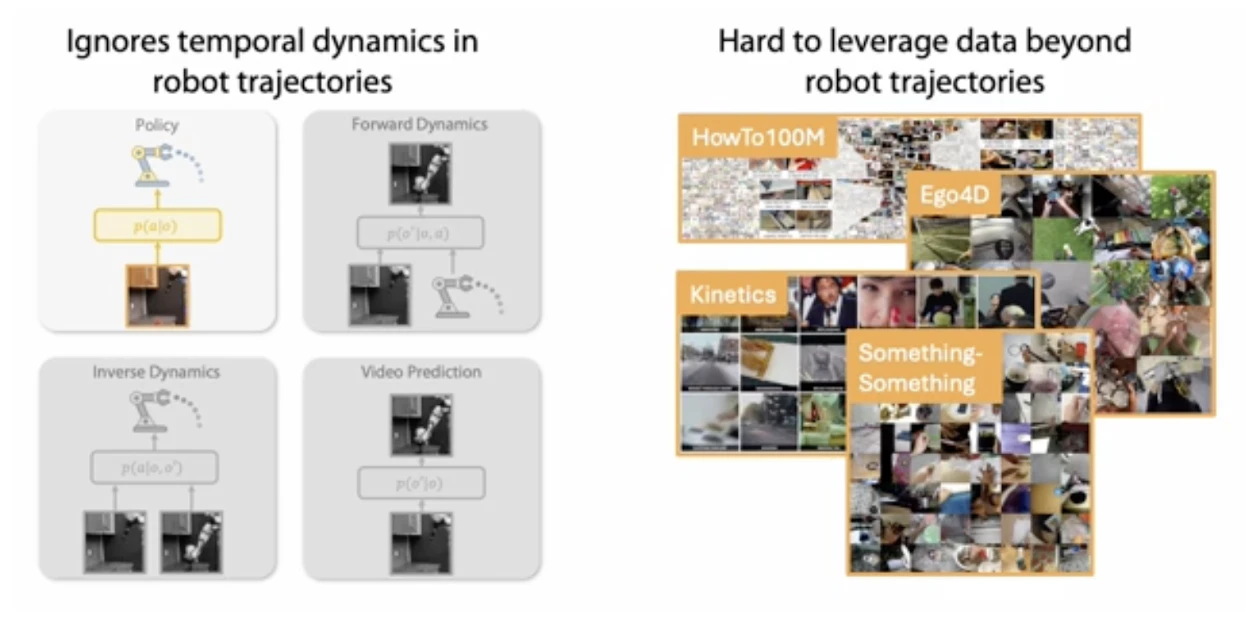
左側の模倣学習用、正解action付きのデータセットは数が少なく多様性に欠ける。一方で右側の膨大な動画データは正解actionがなく、活用が難しい。
これら両方をいかす学習方法を考えたい。
2. ベースとなるdiffusionを猫ちゃん画像でおさらい
Diffusionモデルを猫ちゃん画像でおさらいする。(以下では拡散モデルの概念を示すため、諸々の部分が省略されています。またDDPMとDDIMを主としていますが、部分的に両者が混ざっているので注意してください)
2.1 拡散過程
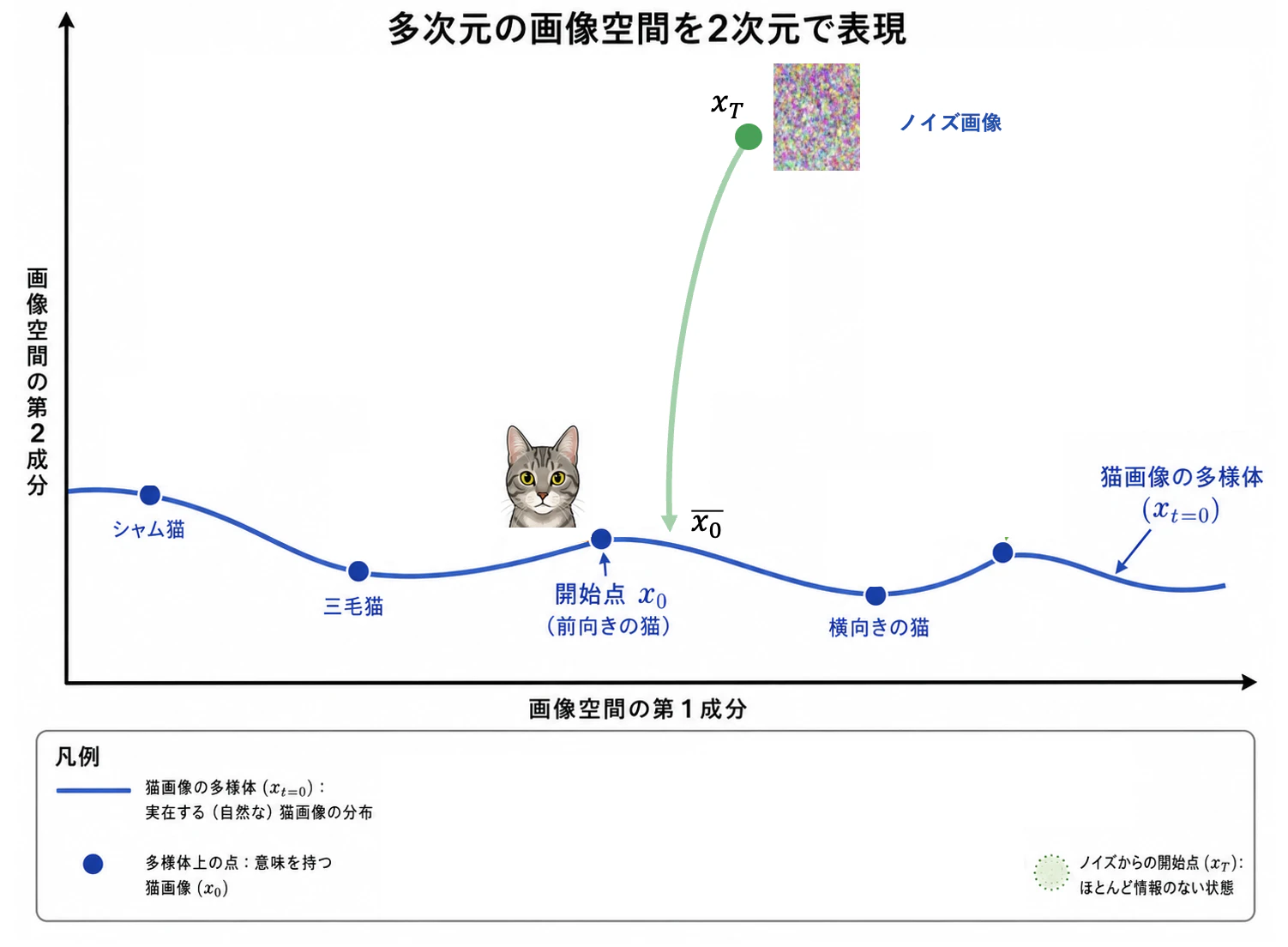
画像空間は、例えば 224 x 224 サイズなら $224 \times 224 \times 3(\rm RGB)$ 次元あるが、以下のようにわかりやすく2次元で表現する。そのほとんどの空間はノイズだが、ごくごく一部は人が見て意味のある画像となる。今回は以下のように、2次元で表現された画像空間内に曲線があり、その曲線上で猫画像が存在すると仮定する。
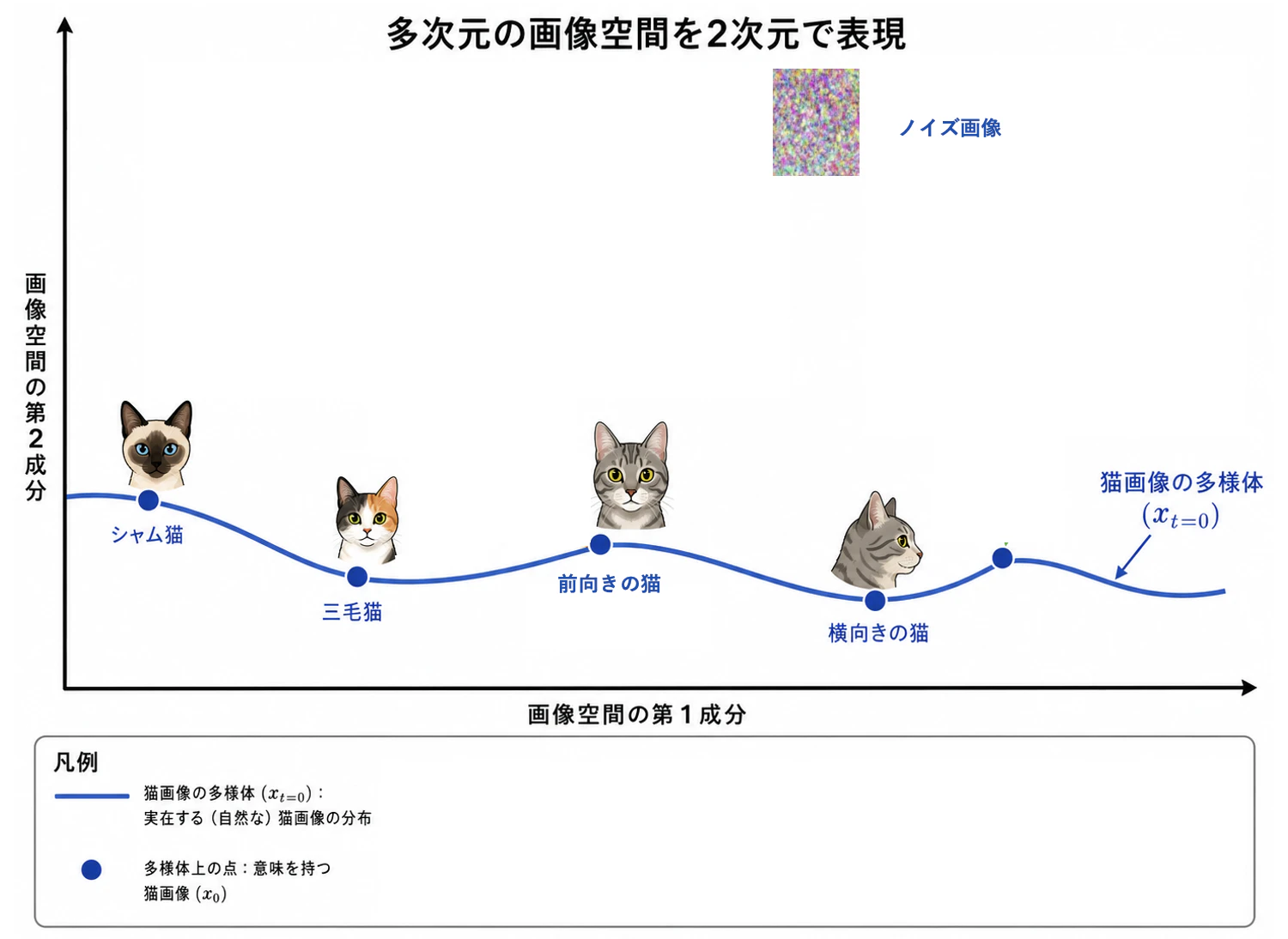
そうすると、猫曲線上のある点はシャム猫画像、ある点は三毛猫画像、またある点は虎柄の前向き猫画像、別のある点は同じ虎柄だが横向きの猫画像、などとなるだろう。
今、こちらの前向き虎柄猫の画像に対してノイズを付与して拡散させる。
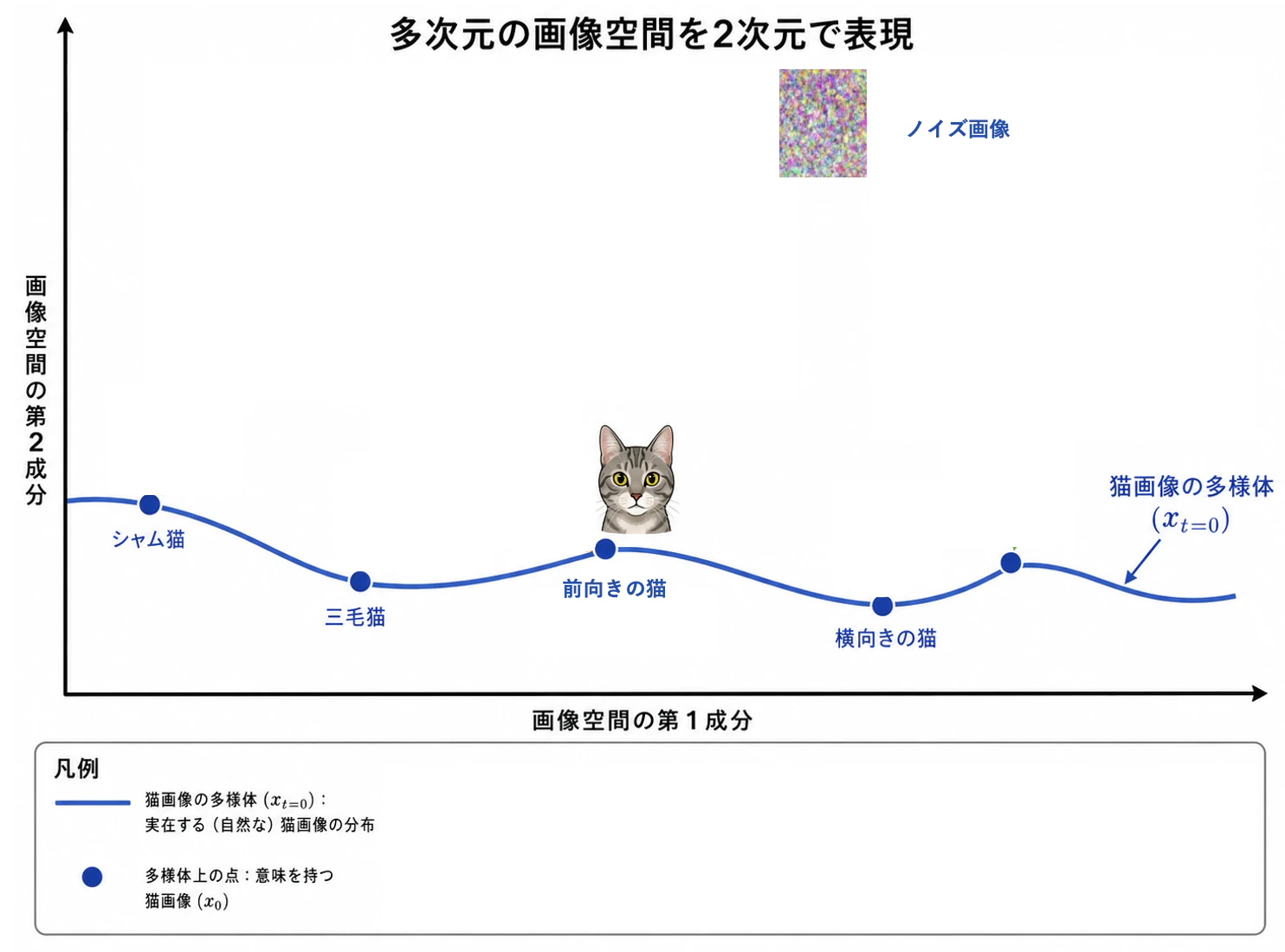
何度か小分けに拡散させたいが、このステップをタイムステップ $t$ で表現する。前向き虎柄猫の画像位置の $x_0$ に1ステップ分だけノイズを付与して拡散させる。正規分布に従うノイズを付与する。
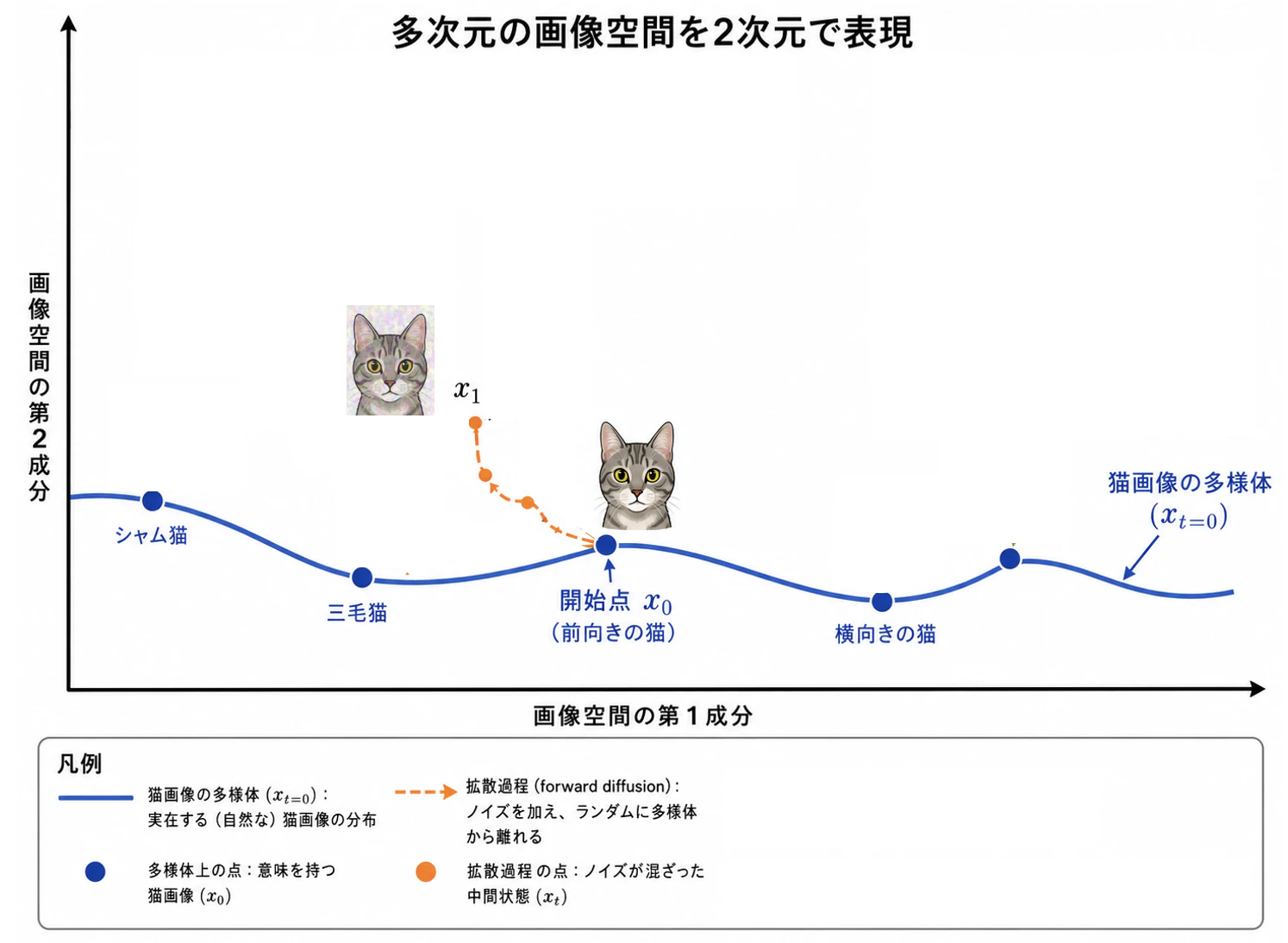
そうすると、 $x_0$ から少し離れた位置に拡散するだろう。具体的な位置は付与するノイズによって確率的に決まる。 また画像は少しノイズが加わって見にくくなるだろう。この付与するノイズの強度を $\beta (= 1-\alpha)$ とすると、正規分布に従うノイズ $\epsilon$ を用いて
\begin{eqnarray}
x_1 &=& \sqrt{1 - \beta_0} x_0 + \sqrt{\beta_0} \epsilon, \ \epsilon \sim \mathcal{N}(0, I) \\
&=& \sqrt{\alpha_0} x_0 + \sqrt{1-\alpha_0} \epsilon, \ \epsilon \sim \mathcal{N}(0, I) \ \tag{2.1.1}
\end{eqnarray}
となる。 $\sqrt{1 - \beta_0} (=\sqrt{\alpha_0})$ をかければ分散は変化しない。
書き方を替えると、
q(x_{1} | x_{0}) = \mathcal{N}(x_1 | \sqrt{1 - \beta_0} x_{0}, \beta_t I) \ \tag{2.1.2}
同じように $T$ タイムステップ分だけ繰り返しノイズを付与すると、曲線(多様体)からどんどん離れていくだろう。それと共に画像はどんどんノイジーとなる。

$t-1$ タイムステップから $t$ タイムステップへのノイズ付与は以下。
x_t = \sqrt{1 - \beta_{t}} x_{t-1} + \sqrt{\beta_{t}} \epsilon, \ \epsilon \sim \mathcal{N}(0, I) \ \tag{2.1.3}
書き方変えると
q(x_{t} | x_{t-1}) = \mathcal{N}(x_{t} | \sqrt{1 - \beta_{t-1}} x_{t-1}, \beta_t I), \ t=1, \ldots , T. \ \tag{2.1.4}
$T$ タイムステップまでいくと、ほとんどGaussianなノイズ画像となる。
加えるノイズによっては最終的な位置 $x_T$ が異なるだろう。

ただし、学習時は複数回のノイズ付与は面倒なので、
x_T = \sqrt{1 - \bar{\beta}_T} x_0 + \sqrt{\bar{\beta_T}} \epsilon, \ \epsilon \sim \mathcal{N}(0, I) \ \tag{2.1.5}
と一気にノイズ付与する。

2.2 逆拡散過程
逆拡散過程では、ノイズ付与された画像から、その付与されたノイズを推定する。
以下のノイズ画像と、それに対応する空間上の緑の点が与えられた場合、
学習が進めば付与されたノイズは「これこれ」で、それを除去した猫画像らしき点 $\bar{x}_0$ の位置はおおよそわかる。ただノイズが大きいと猫画像らしき点は実際の対応する猫画像からズレているだろう。そこでまず、少しだけノイズ除去する。

この逆拡散過程を $T \rightarrow T-1 \rightarrow \ldots \rightarrow 1 \rightarrow 0$ と繰り返し、高精度に $x_0$ となるノイズを推定する。

このとき逆拡散過程は
p(x_{t-1} | x_t) = \mathcal{N} \left( \mu (x_t, t), \Sigma(x_t, t) \right) \ \tag{2.2.1}
であり、平均値は
\mu(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbb{E}[\epsilon_x | x_t] \right) \ \tag{2.2.2}
となる。(証明は下記)
2.3 最後の部分の証明
まず、逆拡散課程において1ステップ分だけノイズを除去する場合、求めたい確率分布は $p(x_{t-1} | x_t, x_0)$ である。ただ、 $x_0$ は直接にはわからない。
これをベイズで変換すると
\begin{eqnarray}
p(x_{t-1} | x_t, x_0) &\propto& p(x_t | x_0, x_{t-1}) p(x_{t-1} | x_0) \\
&=& p(x_t | x_{t-1}) p(x_{t-1} | x_0) \ \tag{2.3.1}
\end{eqnarray}
1式目右辺の尤度部分はマルコフ過程なので2式目となる。この2式目の右辺1つ目の確率と2つ目の確率はいずれも拡散過程なので先に正規分布として提示している。
そうすると正規分布と正規分布の積なのでやはり正規分布となり、その分散は各分散の逆数の和の逆数、平均 $\tilde{\mu}$ は分散の逆数の比を係数とする線形和である。
\tilde{\mu}_t(x_t, x_0) = \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}\,x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\,\beta_t}{1-\bar{\alpha}_t}\,x_0 \ \tag{2.3.2}
未知の $x_0$ をモデルが推定する $\epsilon$ に置き換えたい。そこで(2.1.5)式を代入して、どんどこ計算すると、
\mu(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_x \right) \ \tag{2.3.3}
実際のモデルではノイズ $\epsilon_x$ は未知なので、与えられた $x_t$ の下での期待値 $\mathbb{E}[\epsilon_x \mid x_t]$ を用いて表すと、求める(2.2.2)式となる。
(再掲)
\mu(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbb{E}[\epsilon_x | x_t] \right) \ \tag{2.2.2}
平均がこの値、分散は $\sigma_t^2 \delta_t, \ \delta_t \sim \mathcal{N}(0, I)$ なので、書き換えると
x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbb{E}[\epsilon_x | x_t] \right) + \sigma_t^2 \delta_t, \ \delta_t \sim \mathcal{N}(0, I) \ \tag{2.3.4}
この $ \mathbb{E}[\epsilon_x | x_t]$ はパラメータ $\theta$ のニューラルネットで推定させるので、書き換えると
x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} s_\theta(x_t, t) \right) + \sigma_t^2 \delta_t, \ \delta_t \sim \mathcal{N}(0, I) \ \tag{2.3.5}
となる。
3. UWMのモデル(本手法)
3.1 2種類のdatasetを使う場合の問題
UWFでは以下の2つのdatasetを同時に用いて学習したい
1) エキスパートの Data を使う
| 変数 | 有・無 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 有 |
| 現在時刻から次時刻への行動 $a$ | 有 |
2) Video Data を使う
| 変数 | 有・無 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 有 |
| 現在時刻から次時刻への行動 $a$ | 無 |
3.2 本手法の対応
例えば先行研究では以下の PAD[3]モデルがあり、
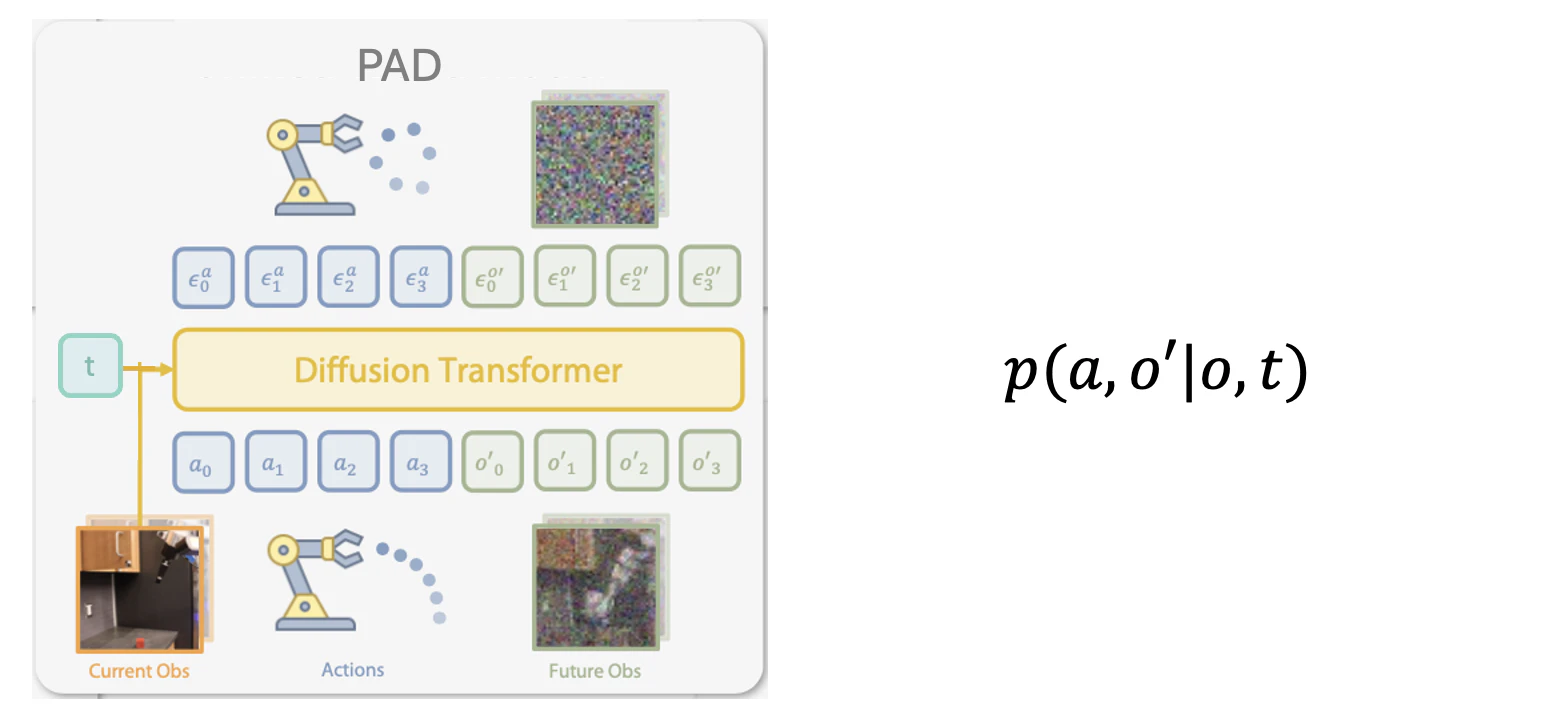
行動 $a$ と将来の観測 $o'$ をdiffusionで同時に denoise する。
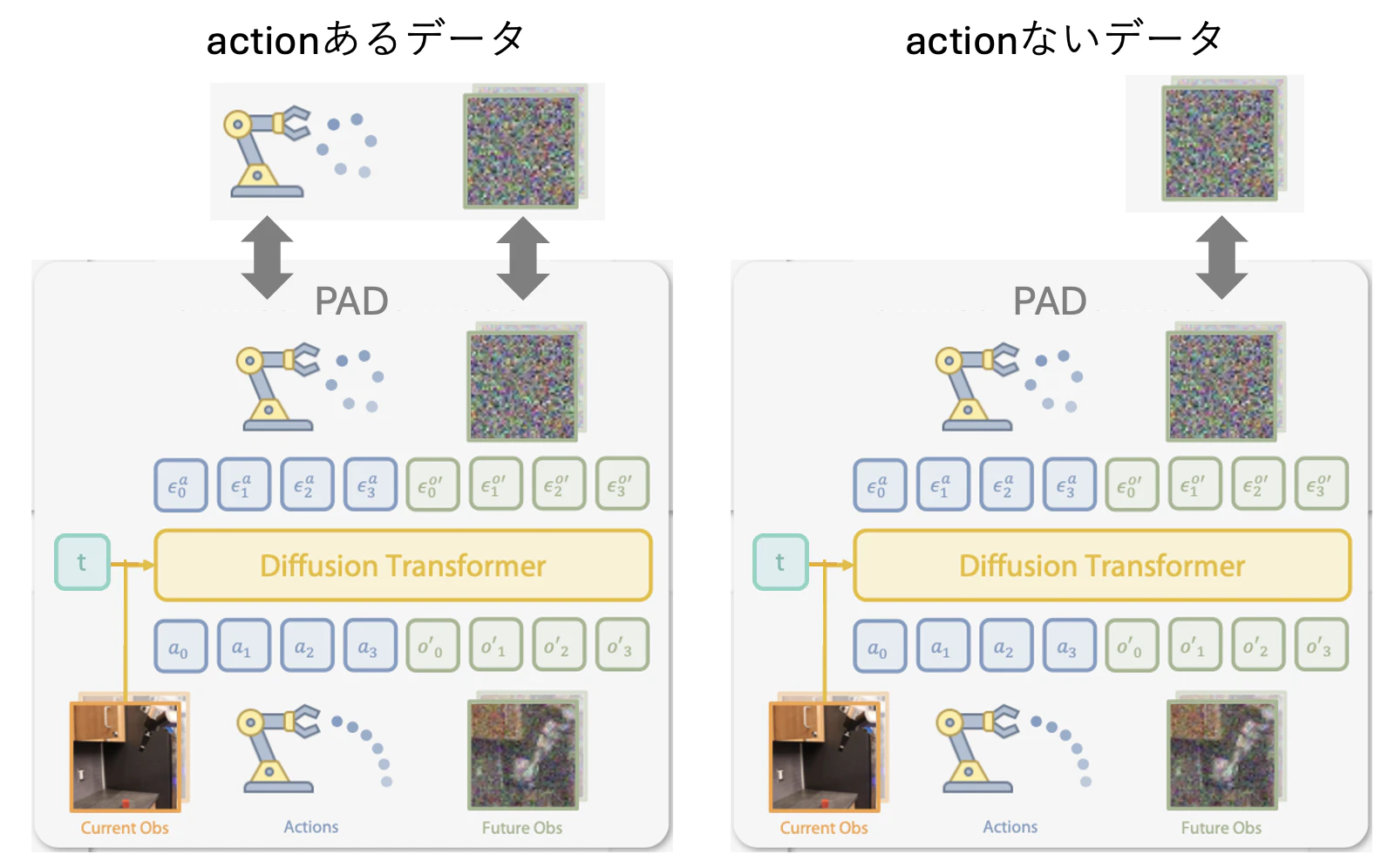
この場合、actionがあるデータに対しては下図の左のように行動 $a$ と将来の観測 $o'$ とでlossをとり、学習する。一方で、actionがないデータに対しては下図の右のように将来の観測 $o'$ のみを学習する。
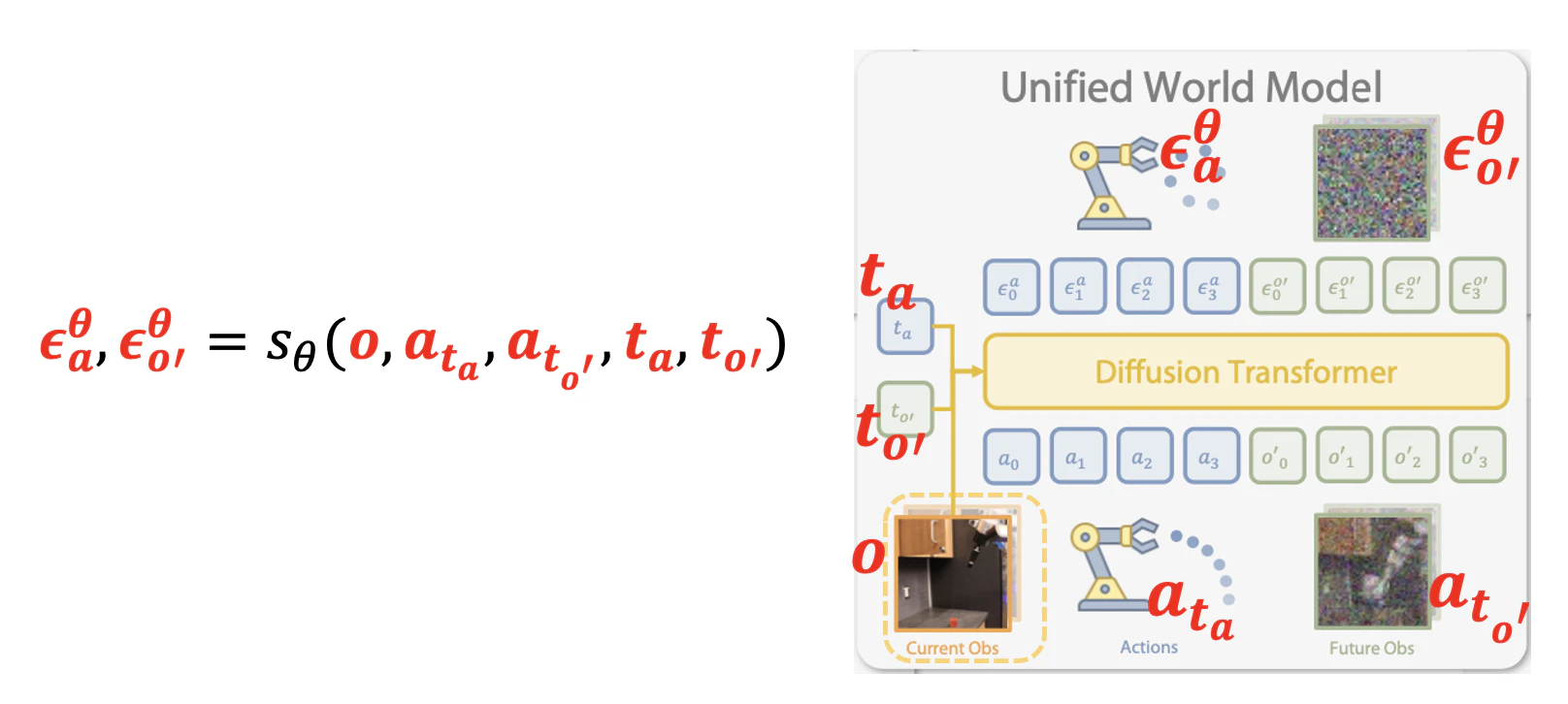
これに対して UWMはPADのようにdiffusionで行動も将来の観測もdenoiseするが、下図の右のように action用timestamp、将来観測用timestampと2つのtimestampで制御する。
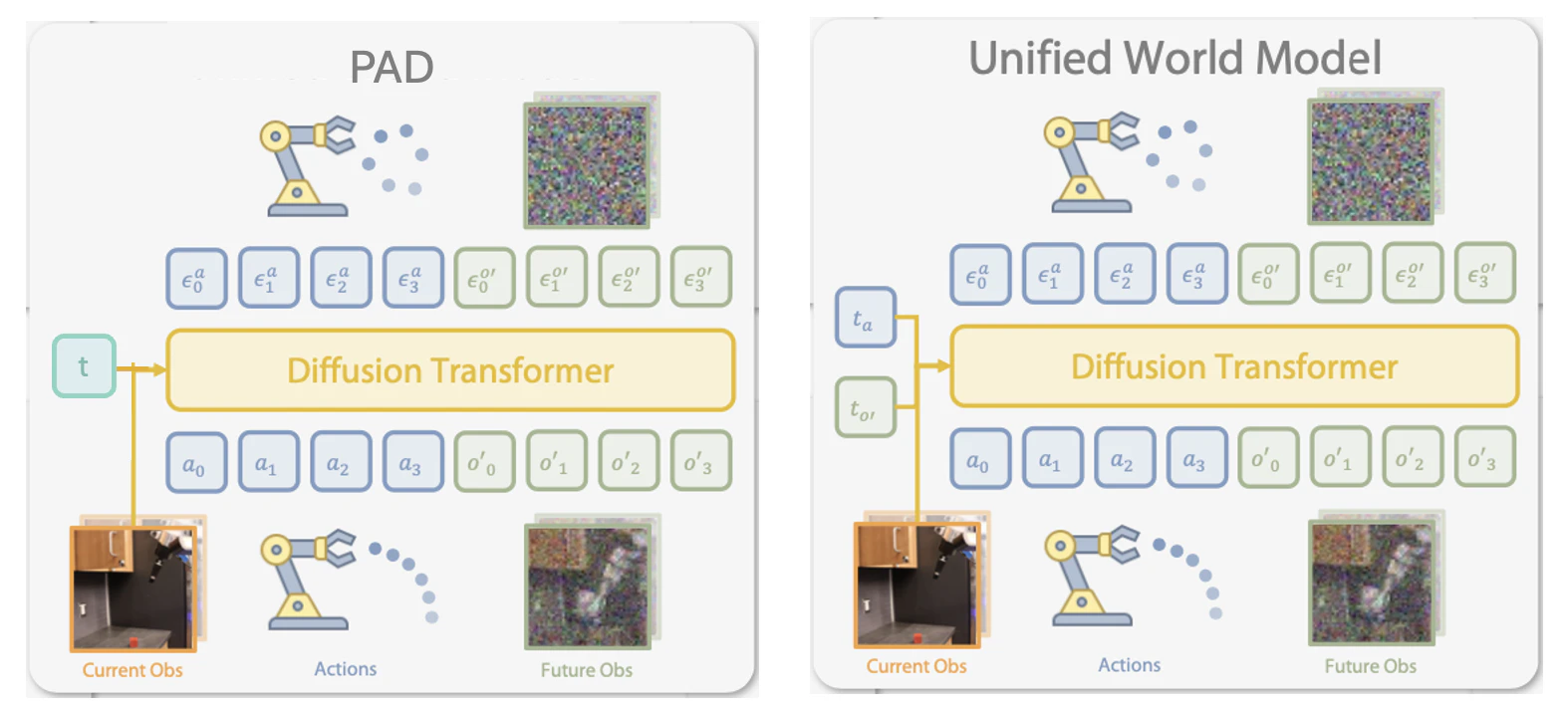
- エキスパートの Data -> 行動の timestamp を 0(denoise済み) とする
- Video Data -> 行動の timestamp を T(noise状態) とする
ことで対応できる。
つまり、difusionモデル $s_\theta$ の入力と出力は
\begin{eqnarray}
&&
\epsilon^\theta_a, \epsilon^\theta_{o'} = s_{\theta}(o, a_{t_a}, o_{t_{o'}}, t_a, t_{o'})\\
\end{eqnarray}
である。
それぞれのノイズは
\begin{eqnarray}
&&a_{t_a} = \sqrt{\bar{\alpha}_{t_a}}a + \sqrt{1-\bar{\alpha}_{t_a}}\epsilon_a,\\
&&o'_{t_{o'}} = \sqrt{\bar{\alpha}_{t_{o'}}}o' + \sqrt{1-\bar{\alpha}_{t_{o'}}}\epsilon_{o'},
\end{eqnarray}
で作成する。
3.3. UWMの基礎式
diffusion modelで $o'$ と $a$ を denoise するので (2.3.5) 式を書き換えるとこんな感じか。
\begin{eqnarray}
o'_{t-1}, a_{t-1} &=& \frac{1}{\sqrt{\alpha_t}} \left( o'_t, a_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}s_\theta(o'_{t_{o'}}, a_{t_a}, o, t_a, t_{o'}) \right) \\
&& + \sigma_t \delta_t, \ \ \delta_t \sim \mathcal{N}(0, I) \tag{3.3.1}
\end{eqnarray}
続きはその(2)https://qiita.com/masataka46/items/053158912d319852161d
reference
[2] Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS), 2023.
[3] Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process. In The Thirty-eighth Annual Confer- ence on Neural Information Processing Systems, 2024.
[4] Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre- training for visual robot manipulation. In The Twelfth International Conference on Learning Representations, 2024.