はじめに
Robotics: Science and Systems (RSS) 2025より以下の論文
[1] Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets. Robotics: Science and Systems (RSS) 2025
のまとめ、その(2)
その(1)はこちら
https://qiita.com/masataka46/items/f9c5b22bc545285092ef
4. Loss
lossは行動のノイズに関する差分と次時刻観測のノイズに関する差分との加重平均とする。
\begin{eqnarray}
Loss(\theta) &=& \mathbb{E}_{\begin{aligned}
(o,a,o') \sim \mathcal{D}\\
t_a, t_{o'} \sim \mathcal{U}(0,T)\\
\epsilon_a, \epsilon_{o'}\sim\mathcal{N}(0,1)
\end{aligned}}
\mathbb{E} \left[
w_a \| \epsilon^\theta_a - \epsilon_a \|^2_2 + w_{o'}\| \epsilon^\theta_{o'} - \epsilon_{o'} \|^2_2
\right], \tag{4.1.1}
\end{eqnarray}
5. 推論時の多様性
UWMはdenoiseの対象が2つであり、それぞれにタイムスタンプを0 or t or T で設定することで、様々なタイプの推論に対応することができる。具体的には以下の4つ。
5.1 Forward Dynamics
観測 $o$ と 行動 $a$ から次の時刻の観測 $o'$ を推定する world model の基本形。
次時刻観測 $o'$ はdenoiseする一方、行動 $a$ は既にdenoiseされたものを入力するので、行動のタイムスタンプは常に 0 としてdenoiseしない。
| 入力タイプ | 入力値 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 無いのでノイズから逆拡散させる |
| 現在時刻から次時刻への行動 $a$ | 有 |
| 次の時刻の観測に関するタイムスタンプ $t_{o'}$ | T -> t -> 0 |
| 行動に関するタイムスタンプ $t_{a}$ | 0 |
行動はdenoiseしないので、次時刻観測のみに注目すると、(3.3.1)は
\begin{eqnarray}
o'_{t-1} &=& \frac{1}{\sqrt{\alpha_t}} \left( o'_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}s_\theta(o'_t, a, o, t_a=0, t_{o'}=t) \right) \\
&& + \sigma_t \delta_t, \ \ \delta_t \sim \mathcal{N}(0, I) \tag{5.1.1}
\end{eqnarray}
5.2 Video Prediction Model
観測 $o$から次の時刻の観測 $o'$ を推定する。
次時刻観測 $o'$ はdenoiseする。行動 $a$ もdenoiseされるが、結果には必要ないので使わない。
| 入力タイプ | 入力値 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 無いのでノイズから逆拡散させる |
| 現在時刻から次時刻への行動 $a$ | 無いので常にノイズ使用 |
| 次の時刻の観測に関するタイムスタンプ $t_{o'}$ | T -> t -> 0 |
| 行動に関するタイムスタンプ $t_{a}$ | T |
行動はdenoiseするものの使わないので、次時刻観測のみに注目すると、(3.3.1)は
\begin{eqnarray}
o'_{t-1} &=& \frac{1}{\sqrt{\alpha_t}} \left( o'_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}s_\theta(o'_t, a_t, o, t_a=T, t_{o'}=t) \right) \\
&& + \sigma_t \delta_t, \ \ \delta_t \sim \mathcal{N}(0, I) \tag{5.2.1}
\end{eqnarray}
5.3 Policy
観測 $o$からとるべき行動 $a$ を推定する。
行動 $a$ はdenoiseする。次時刻観測 $o'$ もdenoiseされるが、使わない。
| 入力タイプ | 入力値 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 無いので常にノイズ使用 |
| 現在時刻から次時刻への行動 $a$ | 無いのでノイズから逆拡散させる |
| 次の時刻の観測に関するタイムスタンプ $t_{o'}$ | T |
| 行動に関するタイムスタンプ $t_{a}$ | T -> t -> 0 |
行動のみに注目すると、(3.3.1)は
\begin{eqnarray}
a_{t-1} &=& \frac{1}{\sqrt{\alpha_t}} \left( a_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}s_\theta(o'_T, a_t, o, t_a=t, t_{o'}=T) \right) \\
&& + \sigma_t \delta_t, \ \ \delta_t \sim \mathcal{N}(0, I) \tag{5.2.1}
\end{eqnarray}
5.4 Inverse Dynamics
観測 $o$ と 次時刻観測 $o'$ からとった行動 $a$ を逆運動学的に推定する。
行動 $a$ はdenoiseする。次時刻観測 $o'$ は既にあるので、タイムスタンプは常に 0。
| 入力タイプ | 入力値 |
|---|---|
| 現在の観測 $o$ | 有 |
| 次の時刻の観測 $o'$ | 有 |
| 現在時刻から次時刻への行動 $a$ | 無いのでノイズから逆拡散させる |
| 次の時刻の観測に関するタイムスタンプ $t_{o'}$ | 0 |
| 行動に関するタイムスタンプ $t_{a}$ | T -> t -> 0 |
行動のみに注目すると、(3.3.1)は
\begin{eqnarray}
a_{t-1} &=& \frac{1}{\sqrt{\alpha_t}} \left( a_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}s_\theta(o'_0, a_t, o, t_a=t, t_{o'}=0) \right) \\
&& + \sigma_t \delta_t, \ \ \delta_t \sim \mathcal{N}(0, I) \tag{5.2.1}
\end{eqnarray}
6 実験の設定
6.1 比較モデル
6.1.1 DiffusionPolicy(DP)
DiffusionPolicy(DP)[2] はDiffusionを使用するが、現在の観測 $o$ を condition として $a$ を推定するのみ。
p(a | o)
6.1.2 PAD
PAD[3]はUWMと同じく、Diffusionモデルを使って現在の観測 $o$ から行動 $a$ と将来の観測 $o'$ を出力する。
p(a, o' | o)
ただし、UWMとは異なり、1つのtimestampで制御する。よって Forward Dynamics や Inverse Dynamics
はできない。
6.1.3 GR1
GR1[4]は、Diffusionでは無い transformer モデルを使って現在の観測 $o$ から行動 $a$ と将来の観測 $o'$ を出力する。
p(a, o' | o)

6.2 使用するデータセット
DROID dataset(Distributed Robot Interaction Dataset) を使用する。以下概要。
- 実世界のロボット操作データを大規模に集めたデータセット
- 76,000 本の demonstration trajectories
- 約 350 時間、564 シーン、- 86 タスク
- 50 人が 12 か月かけて収集
- 観測と行動が揃っている

6.3 学習方法とメトリクス
DROID datasetで事前学習した後に、実機を運用してタスクの成功率で評価する。
UWFの効果を示すため、以下の pretrain と co-train とを試す
- pretrain・・・行動も使用して学習する
- cotrain・・・pretrainに加えて、datasetから行動を排除したdataで学習する
7 結果
7.1 他の3手法との比較
DROID dataset の5つのタスクにおける成功率は以下。

ID は同じ環境で実施した場合。 OOD は照明変えたり、背景変えたりして環境を変えた場合。
以下は平均成功率の比較グラフ。
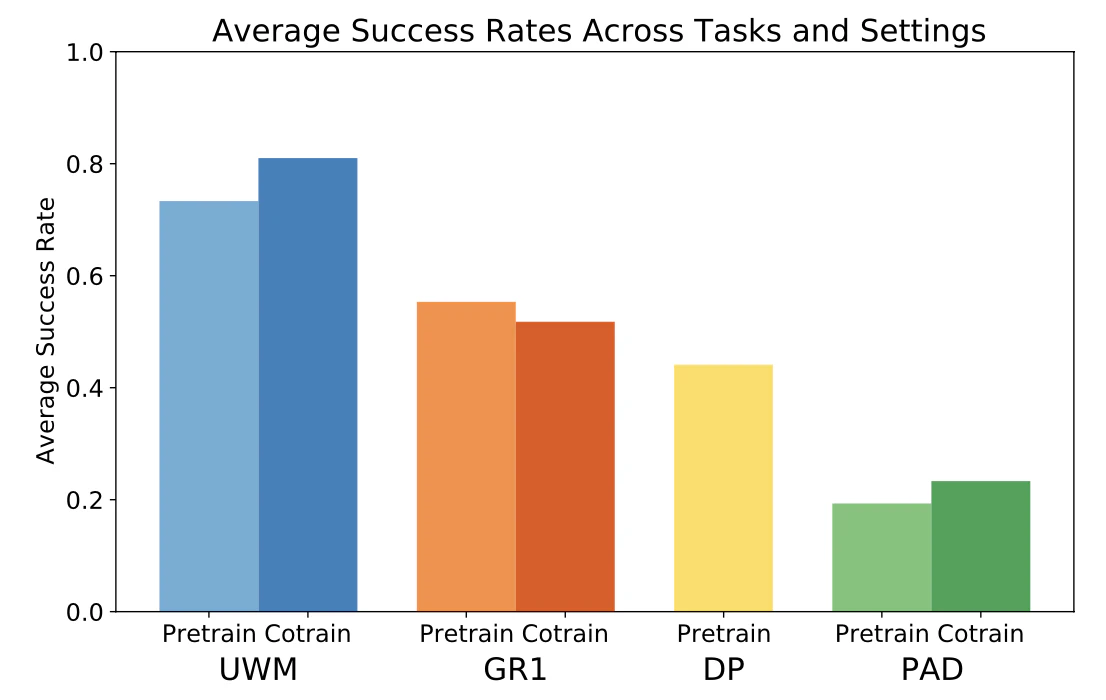
UWMが最もよい。またpretrainとcotrainではcotrainの方がよい。
7.2 結果の解釈
以下は著者らの解釈。
7.2.1 DPに対する比較
UWMはDPと比較して $o'$ も学習している点が異なる。よってUWMはこれにより追加の教師信号がある。このため $a$ のみを学んでいる DP より精度がよくなる
7.2.2 PAD に対する比較
UwMはPADと比較して $o'$ と $a$ で異なるtimestampを用いている点が異なる。これによって UWM は
- forward dynamics $p(o'|o,a)$
- inverse dynamics $p(a|o,o')$
も同時に学べる。しかしPADはこれを学べない。これらによって $a$ と $o'$ との因果関係をより学べるので、それが効いている。
7.2.3 GR1 に対する比較
GR1はdiffsionを使わない。この差が結果に現れている。
8 感想
- 同時に複数の変数をdenoiseするdiffusionモデルに関して考えると、このようにtimestampも独立して複数持つという発想は他にも応用が効きそう
- 一方でGR1もそれなりに精度が良いので、GR1を工夫したものがUWMを超える可能性もあるのではないか
reference
[2] Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS), 2023.
[3] Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process. In The Thirty-eighth Annual Confer- ence on Neural Information Processing Systems, 2024.
[4] Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre- training for visual robot manipulation. In The Twelfth International Conference on Learning Representations, 2024.