はじめに
CVPR2017でBest AwardとなったAppleの論文「Learning from Simulated and Unsupervised Images through Adversarial Training」をまとめてみた。
arXivの論文はこちら
https://arxiv.org/abs/1612.07828
CVPRの論文はこちら
http://openaccess.thecvf.com/content_cvpr_2017/papers/Shrivastava_Learning_From_Simulated_CVPR_2017_paper.pdfhttp://openaccess.thecvf.com/content_cvpr_2017/papers/Shrivastava_Learning_From_Simulated_CVPR_2017_paper.pdf
既にGitHub上に幾つか論文が上がっている。例えばKerasのコードはこちら。
https://github.com/wayaai/SimGAN
要点
ディープラーニングなどで学習させるには大規模なデータが必要だが、そのような注釈付きの画像を入手することは困難だ。画像を合成して水増しすることができれば解決策となるだろうが、合成された画像は本物と程遠い。この論文で提案するSimGANモデルは合成された画像を本物っぽくする。SimGANはRefinerが合成された画像を本物っぽくし、識別器が本物の画像か、あるいはrefineされた画像かを識別する。この仕組みはGANsに似ているが、以下の点で異なる。
- lossに自己正則化項を加える
- ピクセル単位でadversarial lossを求める
- 過去の識別器を学習させる
SimGANはこの仕組みによりMPⅡGaze データセットで state-of-the-artな結果を達成した。
モデル
 1. simulatorで合成した画像(Synthetic)をRefinerに入力して本物っぽい画像(Refiened)を生成する。
2. Discriminatorにはrefineした画像(Refiened)と本物の画像(Unlabeled real)とで作ったミニバッチを入力し、識別させる。
3. Discriminatorではピクセルごとに交差エントロピーを求め学習させる
4. RefinerはGANs誤差と自己正則化項とでlossを求め、学習させる
# 識別器のloss
1. simulatorで合成した画像(Synthetic)をRefinerに入力して本物っぽい画像(Refiened)を生成する。
2. Discriminatorにはrefineした画像(Refiened)と本物の画像(Unlabeled real)とで作ったミニバッチを入力し、識別させる。
3. Discriminatorではピクセルごとに交差エントロピーを求め学習させる
4. RefinerはGANs誤差と自己正則化項とでlossを求め、学習させる
# 識別器のloss
 $\tilde{x}_i$はrefineされた画像、$y_j$は本物の画像。識別器のlossは通常のGANsと同様だが、交差エントロピーはピクセル単位で求め、それを総和する。
# refinerのloss
$\tilde{x}_i$はrefineされた画像、$y_j$は本物の画像。識別器のlossは通常のGANsと同様だが、交差エントロピーはピクセル単位で求め、それを総和する。
# refinerのloss
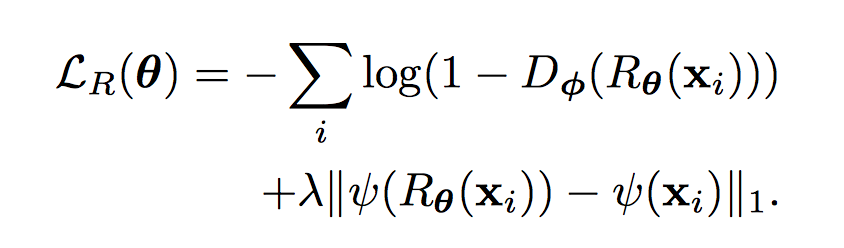 1項目はGANsのGeneratorと同様の誤差。
1項目はGANsのGeneratorと同様の誤差。
2項目は自己正則化項。通常のGANsは「それっぽい画像であればどのようなものでも生成すればいい」が、simGANはラベルに沿った画像を生成する必要がある。例えば視線推定で利用する目の画像セットを考えると、右向き、左向き、正面向きなどのラベルに対して、その画像が存在する。右向きの合成画像をRefinerに入れて左向きの画像が出てくると困る。よってなんらかの制約が必要となる。これを自己正則化項で実現する。
まずSyntheticされた画像$x_i$に対しニューラルネットワーク等$\psi$で特徴空間へ変換する$\psi (x_i)$。一方でrefineされた画像$R_\theta (x_i)$も特徴空間へ変換する$\psi(R_\theta (x_i))$。この両者のL1ノルムをピクセル単位で求める。$|| \psi(R_\theta (x_i)) - \psi (x_i) ||$。
過去のrefineされた画像で識別器を学習する
 学習されているrefinerから得られるrefineされた画像だけでminibatchを形成すると、lossが発散するなどの問題が発生する。
学習されているrefinerから得られるrefineされた画像だけでminibatchを形成すると、lossが発散するなどの問題が発生する。
学習を安定させるため、上図のように過去にrefineされた画像を溜め込み、これを含めたminibatchを形成する。
視線推定における実験結果
 MP2Gaze datasetを用いて視線推定の実験を行った。具体的にはsimGANの仕組みを用いて新たな画像を作成し、これを用いて視線推定を行った。その結果、state-of-the-artな性能を達成した。
MP2Gaze datasetを用いて視線推定の実験を行った。具体的にはsimGANの仕組みを用いて新たな画像を作成し、これを用いて視線推定を行った。その結果、state-of-the-artな性能を達成した。
上図において、左側が本物の画像、右側上段が合成された画像(Synthetic)。下段がrefineされた画像(refined)。無機的で過度に鮮明な合成画像がrefineされることにより、肌の質感や自然なノイズを得ている。また瞳の虹彩もそれっぽくなっている。また以下の表は他の主要な手法との比較。

1列目が手法名、2列目はデータセットが本物画像(R)か合成画像(S)か。3列目は誤差率。refinerでrefineされた画像を用いたデータセットで学習したCNNの手法が最も性能がいい。
結論
simGANの手法によりデータのラベルを維持しながら合成画像をより本物っぽくすることができた。その結果、このrefineされた画像を用いた学習手法はstate-of-the-artな性能を達成した。