はじめに
CVPR2023より以下の論文のまとめ
[1] Z. Tang, et. al. "3D Human Pose Estimation with Spatio-Temporal Criss-cross Attention*" CVPR2023
-
Githubコード
https://github.com/zhenhuat/STCFormer
概要
- 2D骨格を3D骨格へliftingする系のモデル。ビデオから取得した2D骨格のようにsequentialな骨格を入力とする
- ニューラルネットのアーキテクチャとしてはtransformerを用いる系
- 既存のtransformerを用いるliftingモデルの場合、時空間を同時に処理するか、空間で処理した後に時間で処理するが、いずれも計算コストが高い
- その代わりに本モデル(STCFormer)では時間と空間を別系統transformし、後に統合する手法をとる
- その結果、主要なデータセットでSOTAを達成した。また直近のSOTAモデルより計算コストが大幅に低くなった
以下で(a)は時空間でtransformする手法。時間方向と空間方向を加味するとtoken(骨格)は多数にのぼるため計算コストが非常に高い。(b)は空間方向にtransformしてから時間方向にtransformする手法。既存のSOTA手法はこれ。(c)は本モデル:STCFormerで、時間方向のtransformと空間方向のtransformを分けて処理する。

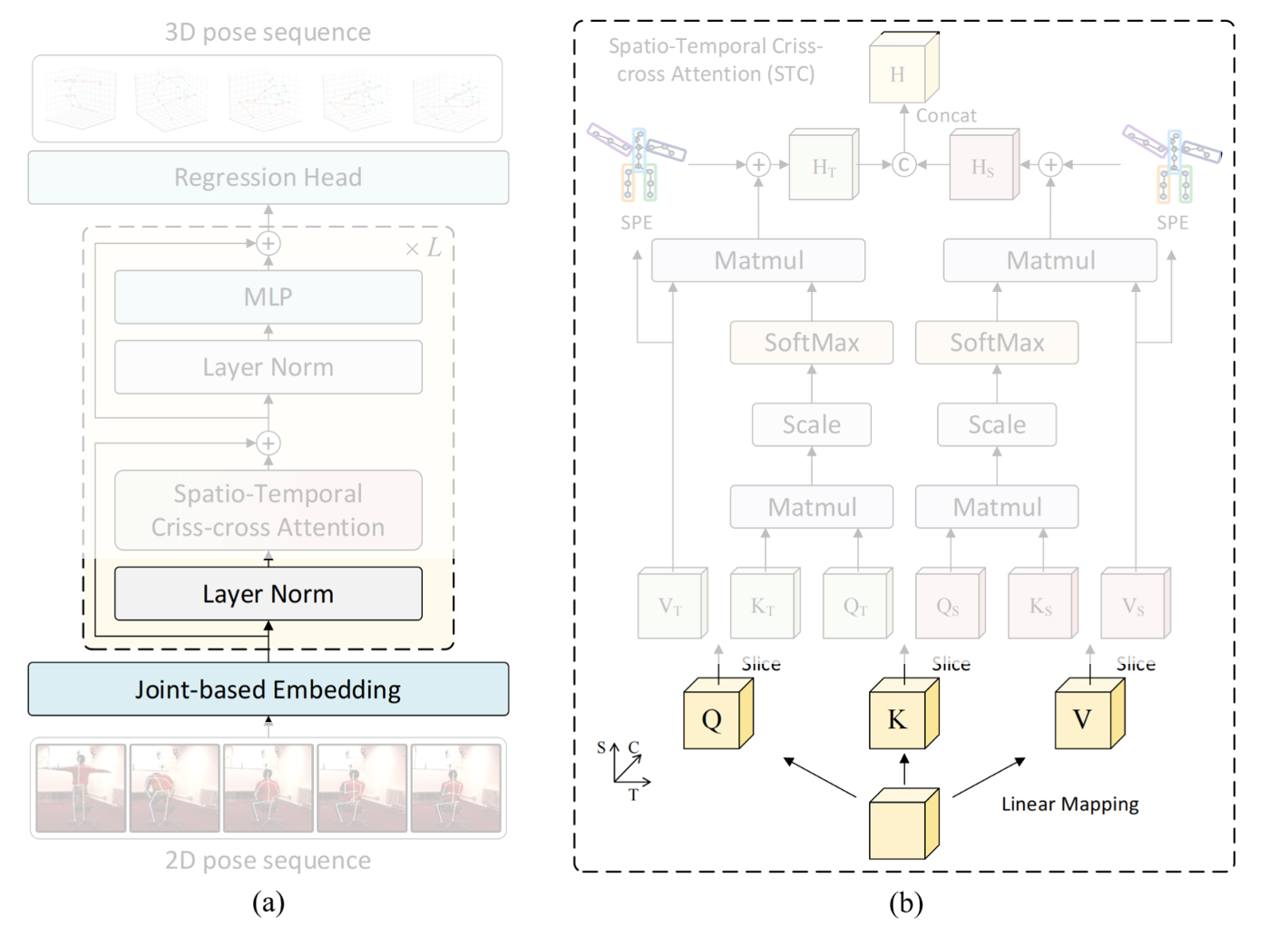
ネットワークのアーキテクチャ
以下がネットワークのアーキテクチャ。

全体像
上図左側が全体像。
-
下から入力となるビデオ、それを 2D-poseモデルでembedする。
-
それにTransformer的な STC block x L層を作用させる。具体的には一般的なtransformerと同様、Layer Norm -> attention -> Layer Norm -> MLPを行う。
その出力を3D poseとし、回帰問題として解く。
STC block
下から(入力側から)見ていく。
Q, K, Vの生成
入力 X(2D poseなど)に対しLayer Normをかまし、FCで行列演算してquery, key, valueを生成する。
{\bf Q},{\bf K},{\bf V} = FC(LN({\bf X}))
時間グループと空間グループとに分ける

この論文の特色である時空間 criss-crossな処理を行うため、時間グループと空間グループに分ける。
具体的には Q, K, Vのそれぞれをチャンネル方向でsplitして分ける。
self-attentionな処理

時間グループに関しては時間方向にself-attentionを行い、空間グループに関しては空間方向にself-attentionを行う。
例えば時間グループなら
MSA({\bf Q}_T,{\bf K}_T,{\bf V}_T) = Softmax \left( \frac{{\bf Q}_T \cdot {\bf K}^{\top}_T}{\sqrt{C}} \right) \cdot {\bf V}_T
SPEモジュール
ここの部分。骨格に関する事前知識を活かす。

transformerは任意の間接と間接との関係性を考慮するが、一方で近い間接同士はより関係しているはずだ。具体的には以下のように体の5つのパートは相関が強いはずなので、ここを時間と空間で畳み込んでenbedする。

時間グループと空間グループとをconcat
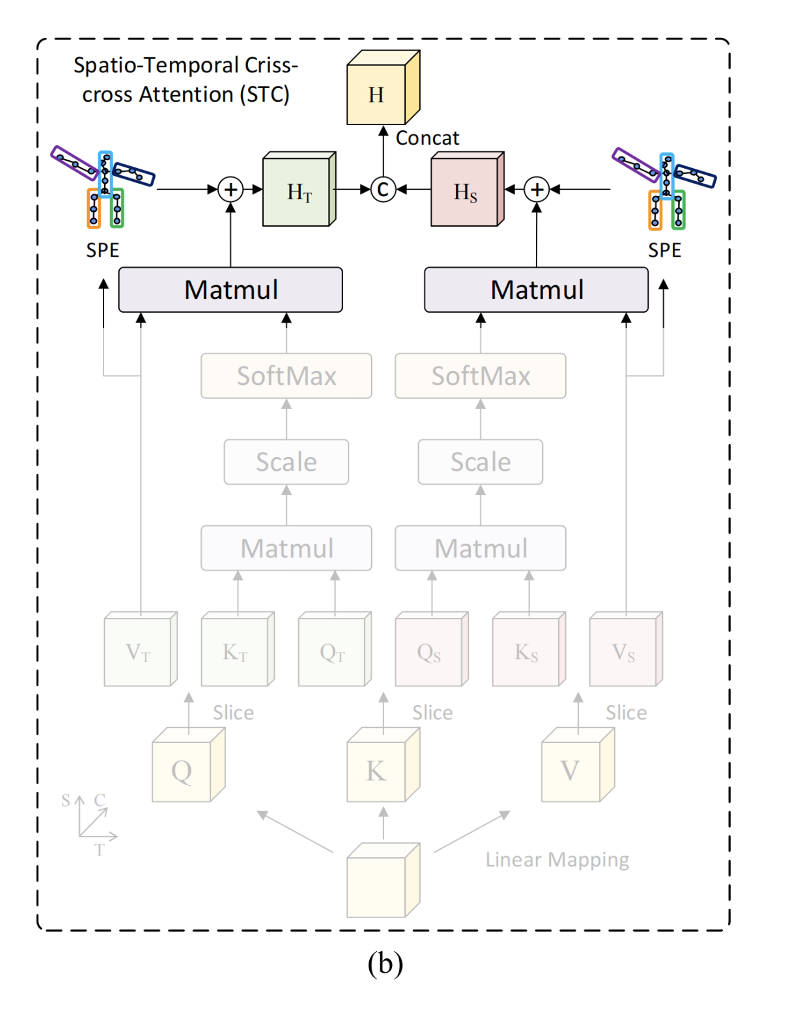
時間グループ、空間グループそれぞれをconcatし、1つにまとめる。
{\bf H} = concat( MSA_T ({\bf Q}_T,{\bf K}_T,{\bf V}_T) , MSA_S ({\bf Q}_S,{\bf K}_S,{\bf V}_S))
Layer NormとMLP

入力とattentionしたものとを足し、Layer Norm, MLPを行う。
\begin{eqnarray}
{\bf Y} &=& {\bf H} + {\bf X} \\
{\bf Z} &=& MLP(LN({\bf Y} )) + {\bf Y}
\end{eqnarray}
Loss
lossは推定した各間接の3次元位置とそのtargetとでMSEを計算する。
\mathcal{L} = \| \hat{\bf P}_{3D} - {\bf P}_{3D} \|^2
実験と結果
device, DLのframework
- deviceはGRX2080Tiを使用
- DLのframeworkはPyTorchを使用
- Adamでlr=0.001から始め、1epochごとに0.96かけし、20epoch学習
STCFormerのアーキテクチャに関わる設定値
- モジュールは6つ
- hidden embedding channelはbaseが256、Learge modelが512
- transformerのheaderは8つ
- sequenceは81と243
用いたdatasetとメトリクス
Human3.6M
- Protocol1・・・root jointを合わせた上でのMPJPE
- Protocol2・・・さらに角度も合わせた上での(?)MPJPE
MPI-INF-3DHP
- MPJPE
- 150mmのPCK
- それらのAUC
Human3.6Mを用いた定量的評価
以下、Human3.6Mを用いた場合の本モデル(STCFormer)と他の主要モデルとの比較で、入力の2D poseはCPNからの推論を用いたもの。上側がProtocol 1, 下側がProtocol 2。
直近のSOTAモデルであったMixSTEと比較しても同じsequence数では勝っている。さらにパラメータ数、推論速度も大きく勝っているらしい。

また以下は入力としてground truthを用いた場合。Protocol 1 で比較。こちらはpost-processingを用いなければMixSTEに負けている。

MPI-INF-3DHPを用いた定量的評価
以下はMPI-INF-3DHPを用いた場合の本モデル(STCFormer)と他の主要モデルとの比較。

PCK, AUC, Protocol 1 いずれにおいても他のモデルよりよい。