はじめに
CVPR 2019 より以下の論文
[1] J. J. Park, et. al. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
のまとめ
-
code
著者が Facebook Reality Labs のインターンシップ中に作成したということなので、facebook researchのこちら
https://github.com/Facebookresearch/deepsdf
が公式コードか?
MIT license -
既存のまとめ
発表されて既に3年経っているため、日本語のまとめも多い
https://blog.albert2005.co.jp/2020/07/22/nerural-3d-representation/
https://www.slideshare.net/takmin/20190706cvpr20193dshaperepresentation-153989245
ここでは自分の気になった点のみまとめ。具体的には以下。
- 学習時に必要とする情報は何か
- 1つの学習済みモデルで様々な物体に対応できるのか
- 推論時にはどのような処理が必要か。また推論時に必要とされる情報は何か
- loss はどのようなものか
- NeRF とどうつながるか
概要
- 3次元表現するモデルのうち陰関数系のもので、その分野の先駆け的なものの1つ
- 物体表面の外を0以上、表面を0、内部を0以下で表現する(SDF: Sined Distance Function)
- 個々の物体ごとに別々の latent code を割り当てる
SDF的な表現方法
以下の図(Figure2より)のように、
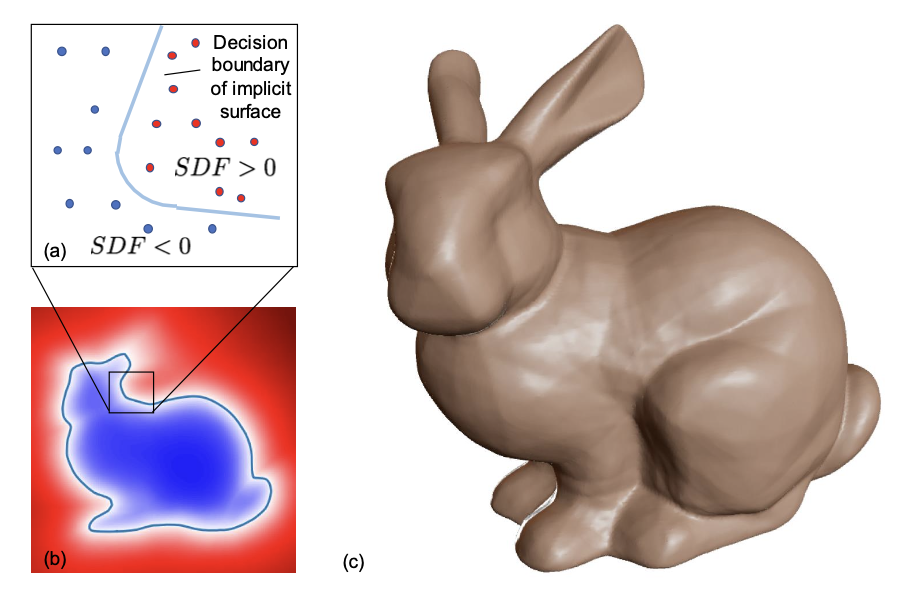
うさぎちゃんの首の部分に注目すると、外側の赤い部分は 0 以上、境界が 0、うさぎちゃんの内部が 0 以下となるような表現。
つまり、この空間上の座標を ${\rm \bf x} \in \mathbb{R}^3$ とすると、
SDF({\rm \bf x} ) = s : {\rm \bf x} \in \mathbb{R}^3, s \in \mathbb{R} \tag{1}
とスカラー $s$ によって表す。
SDFをニューラルネットとすると、以下(Figure 3の(a))のように
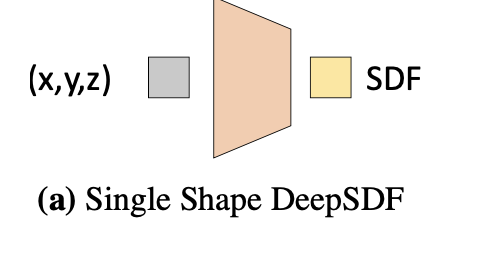
座標を入力すればSDF値 $s$ が出力されるだろう。
多くの domain を1つのモデルで表現する
上記のシンプルな方法だと物体ごとにモデルが必要になるので用途が限られている。
そこで様々な物体表面を1つのモデルで表現できるよう、入力に個々の物体を区別する latent code を加える。
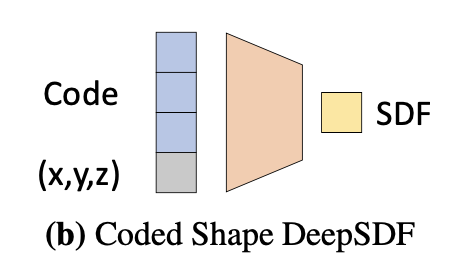
この code がうさぎちゃんを表していれば、モデルはうさぎちゃんに対応する SDF 値を出力するだろう。
つまり物体 i のSDF値を $SDF^i$ とすると
f_{\theta} ( {\rm \bf z}_i, {\rm \bf x}) \sim SDF^i ({\rm \bf x}) \tag{5}
と考える。
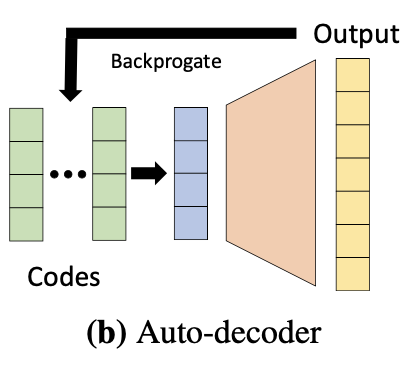
この latent code も学習させる。
具体的には
$i$: 物体(domain)の番号
$z_i$: 物体(domain)固有の latent code
$j$: 物体 i における座標のサンプリング番号
${\rm \bf x}_j$: i 番目の物体から j 番目にサンプリングした座標
$f_{\theta}$: 陰関数表現するモデル
$s_j$: 物体 i 、サンプリング j 番目座標におけるSDF値
$\mathcal{L}$: loss。具体的には L2。
として
\newcommand{\argmin}{\mathop{\rm arg~min}\limits}
\argmin_{\theta, \{ {\rm \bf z}_i \}^N_{i=1}} \sum^N_{i=1}{\left( \sum^K_{j=1} \mathcal{L} (f_{\theta} ({\rm \bf z}_i, {\rm \bf x}_j), s_j) + \frac{1}{\sigma^2} \| {\rm \bf z}_i \|^2_2 \right) } \tag{9}
と最小化するよう、モデルのパラメータ $\theta$ と共に latent code z も学習させる。
loss はどのようなものか
(9)式のloss $\mathcal{L}$ は以下の clamp 関数値同士の L1 を用いている。
\begin{eqnarray}
\mathcal{L} (f_{\theta} ({\rm \bf x}), s) &=& \| {\rm clamp} (f_{\theta} ({\rm \bf x}), \delta) - {\rm clamp} (s , \delta) \|_1 \tag{4} \\
where \ \ \ {\rm clamp} &=& \min(\delta , \max (-\delta,x))
\end{eqnarray}
clamp関数はわかりにくいが、ようするに-δとδの範囲内であれば x とし、-δ以下は-δ、δ以上はδとするもの。図にするとこんな感じか。
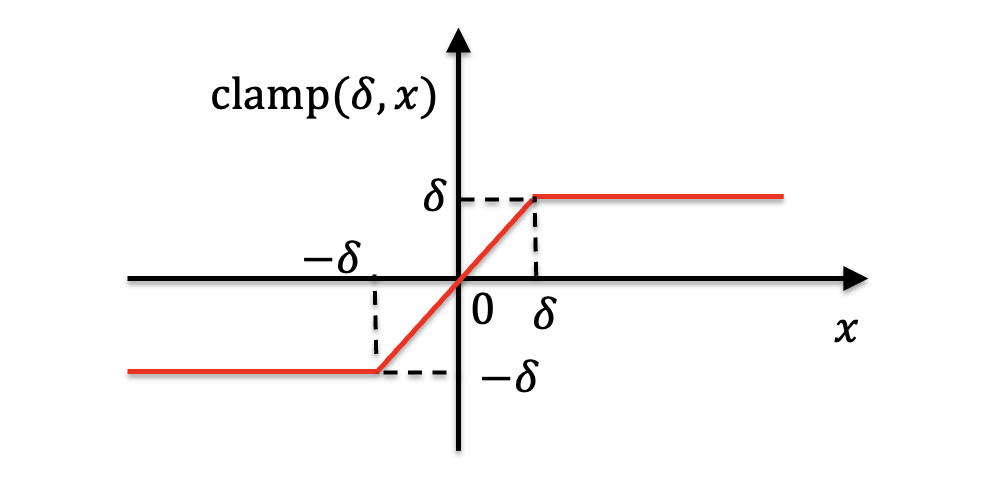
それの予測値と正解値との差を計算しているので、予測した物体表面付近から正解値の物体表面付近にかけての「ズレ部分」のみに loss が計算されるイメージ。
学習のプロセスはどのようなものか
様々な物体の 3D モデルを用意し、そのSDF値を計算しておく。
(9)式を最小化させるよう学習する。
そうすると、1)それぞれの物体に対する latent code、及び2)様々な物体に対してSDF値を出力するモデル、ができあがる。
推論時にはどのような処理を行うか
既に学習した物体に対して推論するのは意味がないだろう。なぜならそれらの3Dモデルは元々存在するから。
意味があるのは新しい物体に対して推論を行う場合。
ただ、新しい物体に対応する latent code は無いので、最適化で求める必要がある。その際に、表面に関する一部の情報が必要。例えば depthカメラから取得した手前側の表面形状、など。
それを用いて以下のように z を得る。
\newcommand{\argmin}{\mathop{\rm arg~min}\limits}
\hat{\rm \bf z} = \argmin_{\rm \bf z} \sum_{({\rm \bf x}_j, {\rm \bf s}_j) \in X} {\mathcal{L} (f_{\theta} ({\rm \bf z}, {\rm \bf x}_j), s_j) + \frac{1}{\sigma^2} \| {\rm \bf z} \|^2_2} \tag{10}
細かく見ると、
- sum内第1項で latent code とサンプリングした座標を入力しSDF値を得て、これとdepthなどから取得した正解値とで loss を計算する
- それに第2項の正則化項を加える
- これが最小化するように latent code を最適化する
こうして求まった latent code と座標をモデルにぶち込めば SDF 値が出力されるだろう。それを marching cube algorithm などでメッシュ等にするもよし、3Dプリンターで出力するもよし、って感じか。