はじめに
CVPR2020から以下の論文
[1] K. Cheng, et. al."Skeleton-Based Action Recognition with Shift Graph Convolutional Network." CVPR2020
のまとめ
CVF open access:
https://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_Skeleton-Based_Action_Recognition_With_Shift_Graph_Convolutional_Network_CVPR_2020_paper.html
公式コード:
https://github.com/kchengiva/Shift-GCN
-> pytorch 0系
概要
- 骨格から行動を推定する系のモデル
- graph convolutionにshift-convの仕組みを取り入れた
- それにより直近SOTAなモデルと比較して高い精度を達成しながら、かつ10倍以上の高速化を実現した
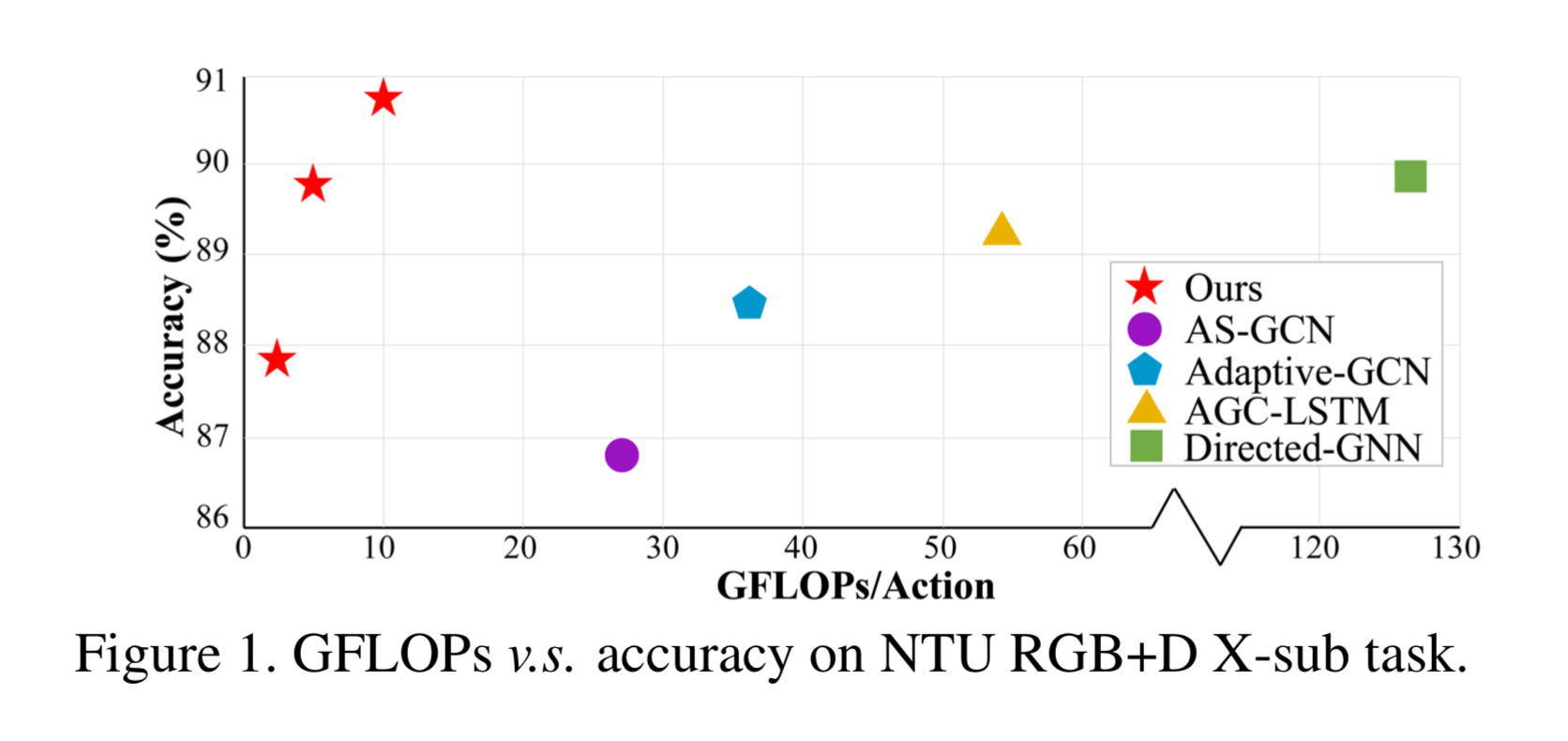
以下はGCN系の有名モデルと精度(accuracy)、速度(GFLOPs)を比較したもの
関連研究
ここではshift-GCNを理解する上で必要となる、1)通常のconv、2)GCN、3)shift-cnnをざっくりおさらい。
1)通常のconv
言わずもがな、通常のconv。説明略。以下の図で概観すると
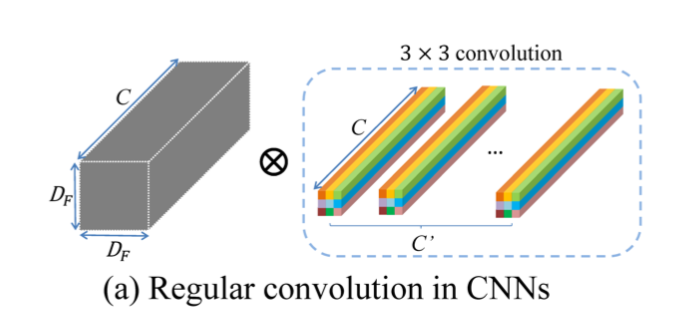
$(D_F, D_F, C)$ のfeature mapに対して3 x 3 x C x C'のkernelで畳み込む。
2)GCN
こちらも略。
拙著記事等参考に。
https://qiita.com/masataka46/items/78480b730df1326b883b
以下の図で概観すると
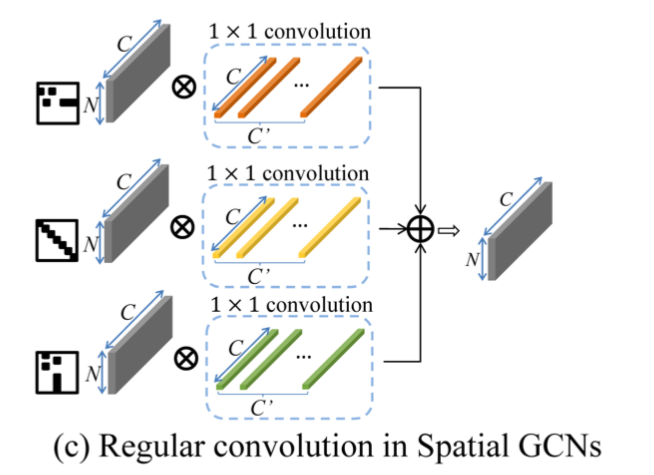
左端は隣接行列や単位行列など(を恐らく正規化したもの)で、これをmultiplyすることで関係のないconnectionを削除する。その右はfeature mapで、縦のNが各joint、奥側のCがchannel。それに1x1convで畳み込む。
3)shift-CNN
shift-CNNは[2]などで提案されているconvolutionのしくみ。以下の図
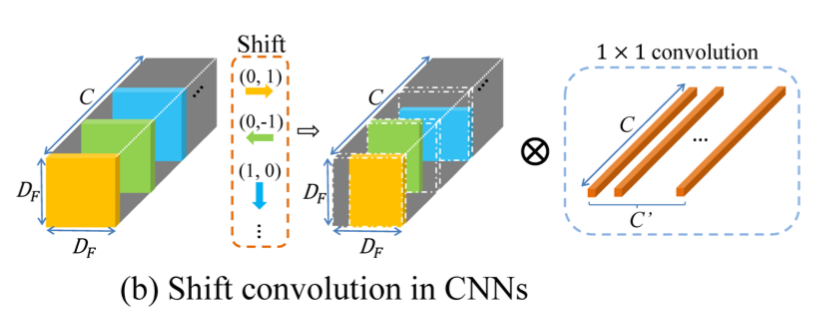
のようにfeature mapをチャンネル毎に別の方向にずらす。その後1x1 conv(point-wise)で畳み込む。
通常のconvではkernelの大きさの分だけ層を重ねる毎に受容野が広がっていくが、shift-convの場合はshiftすることにより受容野が広がる。
$S_i = (x_i, y_i)$ を i チャンネルにおける x 方向および y 方向のshiftとして、受容野は1つの層で
R = \{ -S_1 \} \cup \{ -S_2 \} \cup \cdots \cup \{ -S_C \}
だけ広がる。具体的には各方向1のshiftなら、3x3となる。
これによって畳み込みの演算量を大幅に減らすことができる。例えば、通常の畳み込みでは、
$D_F$ :feature mapの大きさ
$D_K$ :kernelの大きさ
$C$ :入力側チャンネル数
$C'$ :出力側チャンネル数
として
D^2_K \times D^2_F \times C \times C'
だが、shift-convの場合はkernelが 1x1なので
1^2 \times D^2_F \times C \times C'
となり、大幅に減る。
Shift graph convolutional network
本題のshift-GCN。
- local graph shift operation
- non-local graph shift operation
の2種類がある。
local graph shift operation
shiftさせるのは隣のnodeに対してのみ。以下の図で考える。
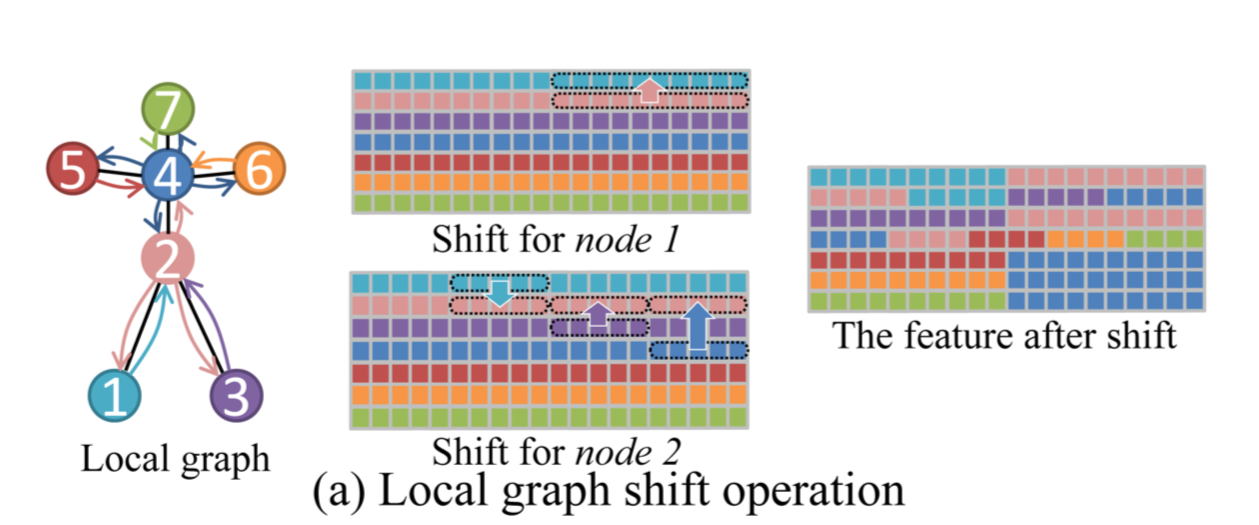
node7つが図中左のようにつながっている。中央・右のmatrixは縦がnode、横がchannelを表す。channel数は20。
node 1 に注目すると、node 2 のみとつながっている。よって1)shiftしない、2)node 2がshiftしてくる、の2パターン。20 channelを2で割って、前半のチャンネルはshiftせず、後半のチャンネルでnode 2をshiftさせる。(図中、中央上)
次に node 2 に注目すると、node 1, node 3, node 4 と繋がっているので、1)shiftしない、2)node 1がshiftしてくる、3)node 3がshiftしてくる、4)node 4がshiftしてくる、の4パターン。チャンネルを4つのpartにわけ、第1partはshiftしない、第2partはnode 1をshiftさせる、第3partはnode 3をshiftさせる、第4partはnode 4をshiftさせる。(図中、中央下)
こうすると最終的に図中、右のようなshift後のfeature mapができあがる。
non-local graph shift operation
上記の local graph shift operation は以下2つの問題点がある。
- shift後のmatrix(図中、右)のnode3に注目すると、第4partでは無くなっている。このようにチャンネルによっては無くなるnodeが発生する
- 隣接したnodeのみに注目しているため、最近の研究で注目されている離れたnode間の関係性を反映していない
2の具体例として、「拍手」や「読書」は両手の関係性が重要である、など。
ならばいっそのこと、全てのnodeと全てのnodeを繋げてしまえ、というのがnon-local graph shift operation。
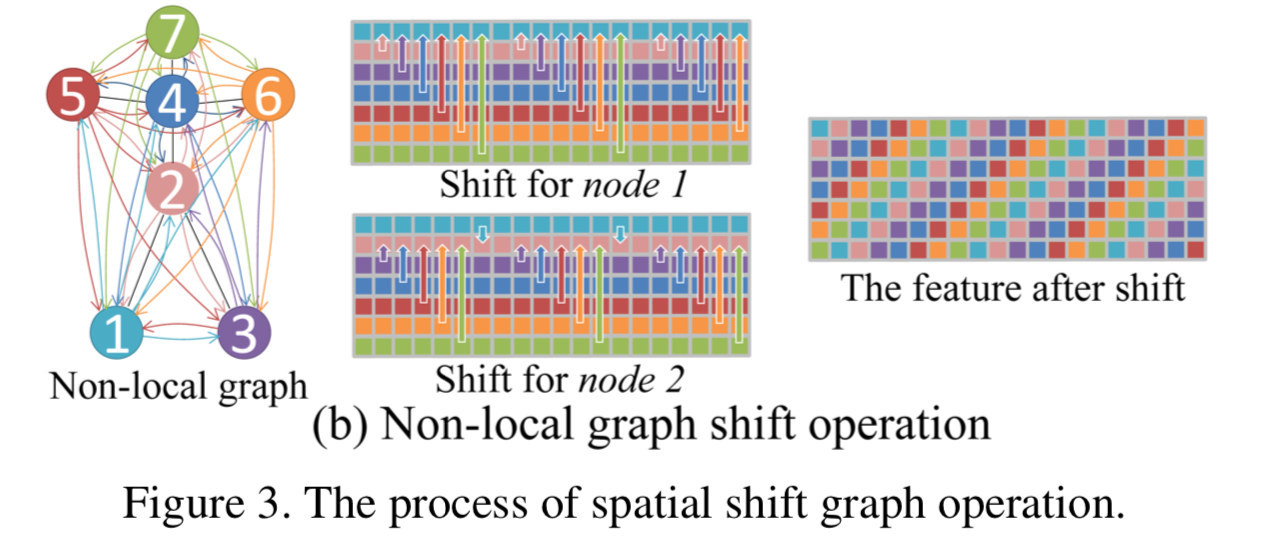
この図の左では全てのnodeとnodeが繋がっている。
node 1 に注目すると、図の中央上のように ${\bf mod} N$ が0の場合はshiftせず、1の場合はnode 2がshiftする、2の場合はnode 3がshiftする、・・・とする。
node 2 も同様で、図の中央下のように ${\bf mod} N$ が0の場合はshiftせず、1の場合はnode 3がshiftする、2の場合はnode 4がshiftする、・・・とする。
結局、図の右のようなfeature mapが出来上がる。
learnable mask
node間の結合は重要度が違うので、学習するmaskをかけることでこれに対応する。
\tilde{\bf F}_M = \tilde{\bf F} \circ Mask
temporal shift graph convolution
時間方向にもshift convを適応する。以下の2パターンがある。
naive temporal shift graph convolution
時間方向に単純なshiftを行うパターン。
チャンネルを $2u+1$ にわけ、それぞれ -u, -u+1, ・・・, 0, ・・・, u-1, uだけshiftする。
adaptive temporal shift graph convolution
上記 naive temporal shift graph convolution は以下2つの欠点があると著者らは主張。
- 任意のframe間の組み合わせが実現できない・・・最近の研究ではこれが重要だそう
- manuelにu値を設定することは、そのdatasetに過適合してしまう??? -> ここ意味わからん
よってu 値を適応的にする??
アーキテクチャ全体
- ST-GCNをベースにする
実験と結果
NTU-RGB+D 60 による他のモデルとの比較
以下はNTU-RGB+D 60を用いた場合の他のモデルとのaccuracy, GFLOPsの比較。
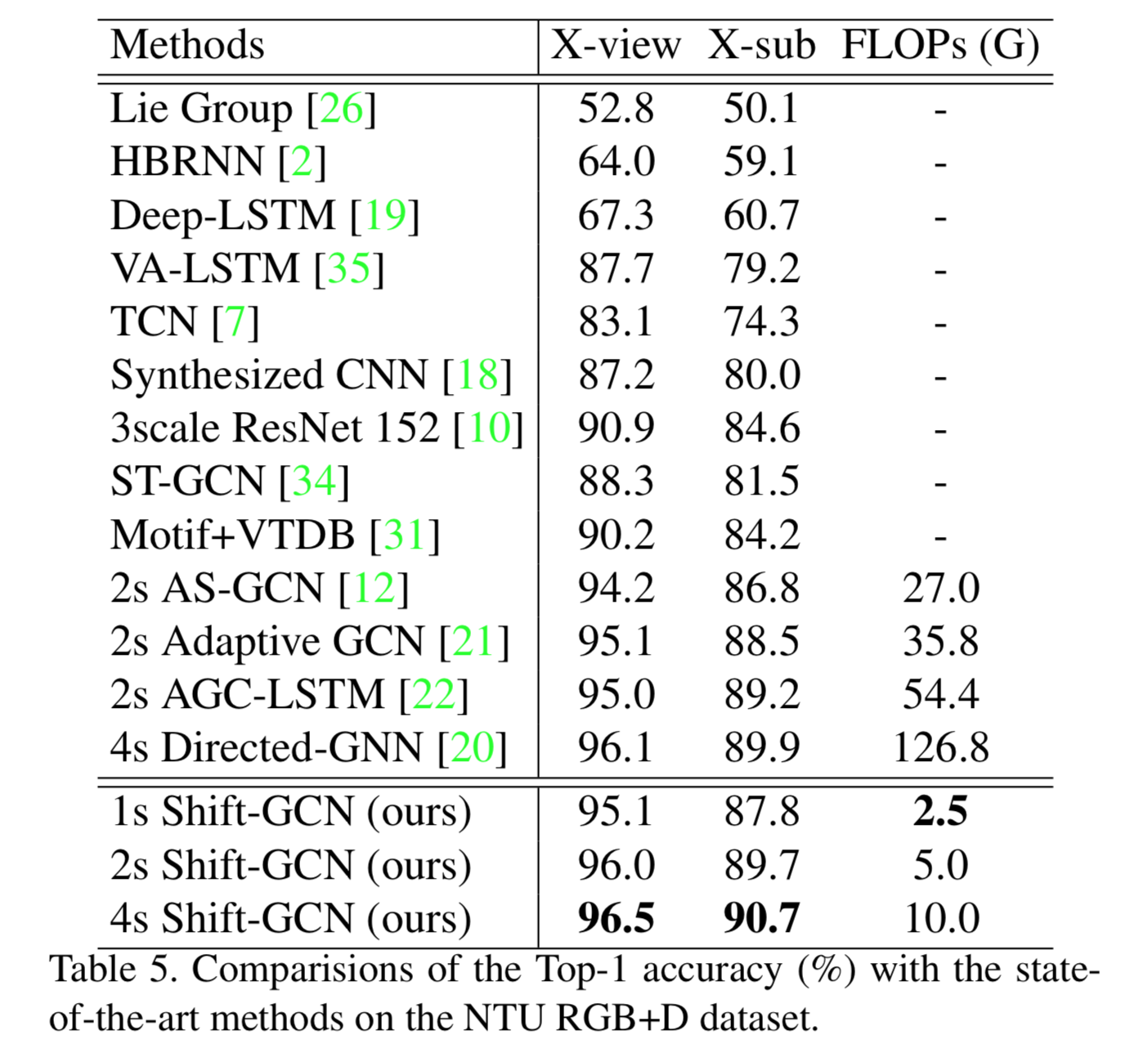
accuracy はSOTAなモデルと大差ないが、GFLOPsは大幅に小さい。
spatial shift の ablation study
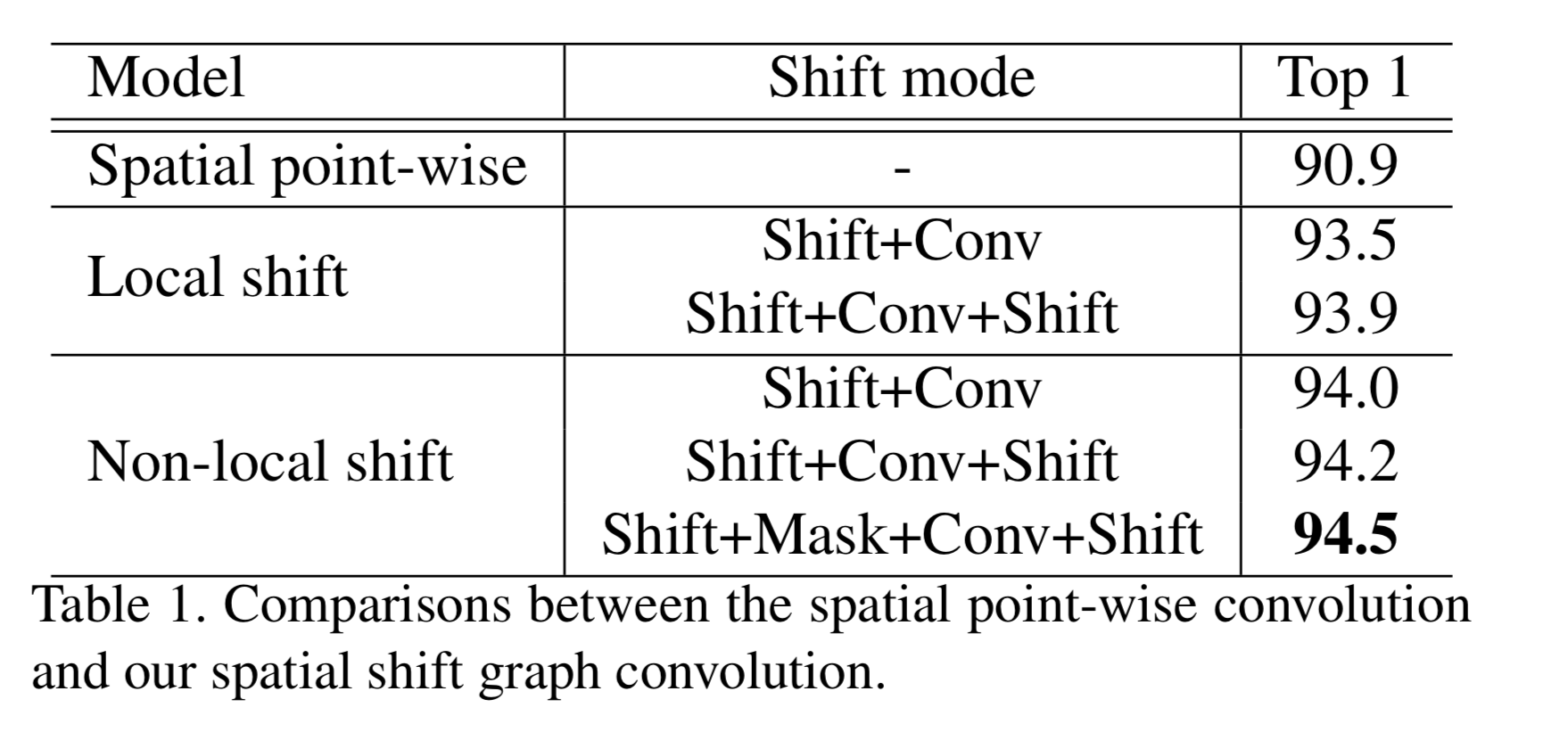
local shiftとnon-local shiftを比較すると、後者の方が若干よい。
temporal shift の ablation study
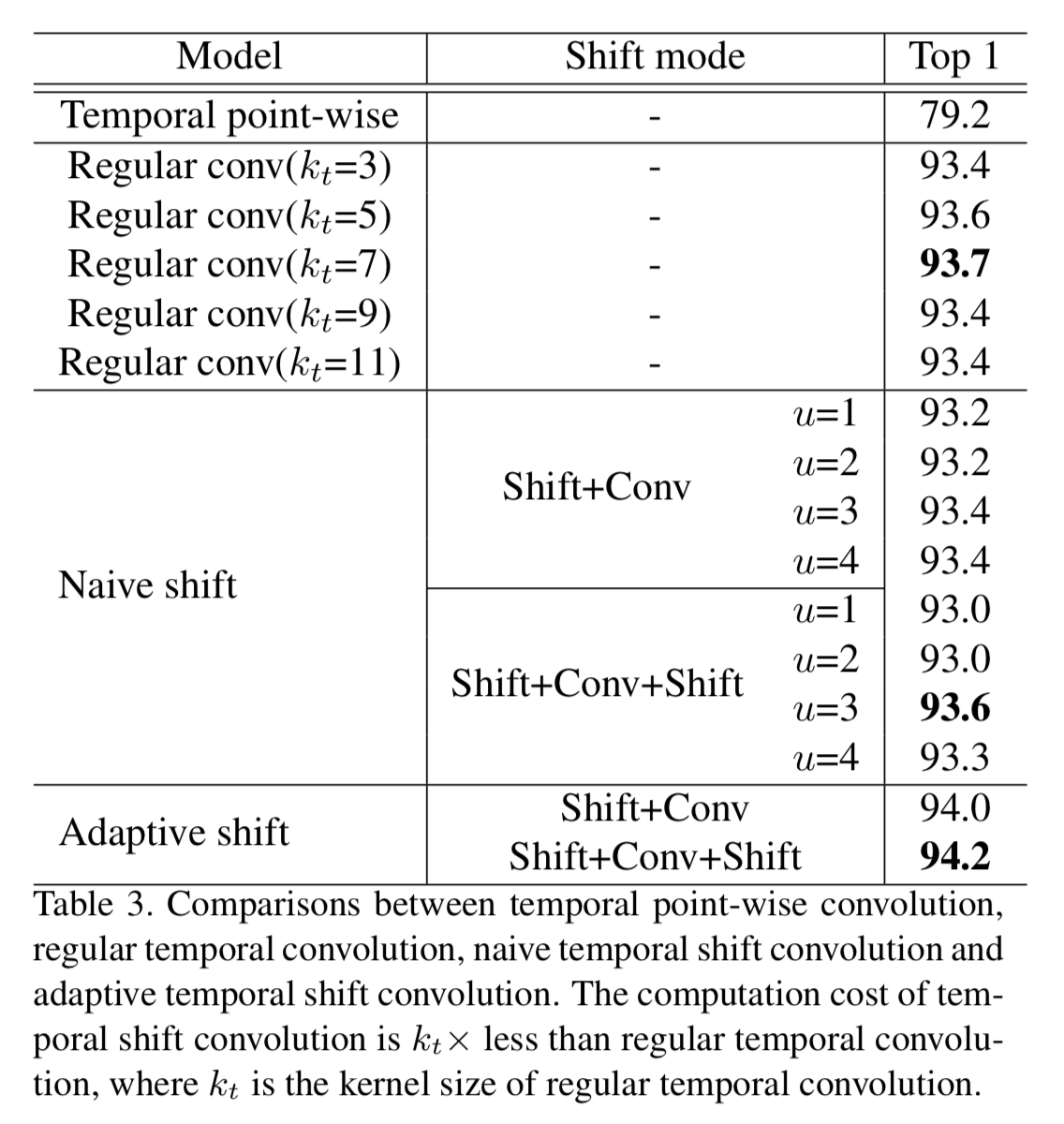
naive shiftとadaptive shiftを比較すると、後者が若干よい。
reference
[2] B. Wu, et. al. "Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions"