YOLOっていろいろあるけど、速度はどうなんだろう
物体検出DNNではYOLOシリーズが注目されています。バージョンが上がるにつれ、性能向上のためのさまざまな工夫がなされているようです。先日筆者も、ビデオ映像からYOLOXで人物抽出を行ってみました(「YOLOXでビデオ映像から人物の映っているフレームだけ抽出してみた」)。
ただ、実際のところ、処理速度はどうなんだろう、YOLOXでよかったのかな、とふと疑問に思い、比較をすることにしました。速度という観点では、学習速度などもあるかと思いますが、ここでは推論速度に絞って比較を行いました。
実際に推論速度を測定しました
比較の対象は、Yolov4 github、Yolov5 github/torch.hub、YOLOX githubから入手できる以下の事前学習モデルとしました。
| github | 事前学習モデル |
|---|---|
| Yolov4 github | yolov4, yolov3 |
| Yolov5 github | yolov5s / yolov5m / yolov5l / yolov5x |
| YOLOX github | yolox-nano / yolox-tiny yolox-s / yolox-m / yolox-l / yolox-x |
測定はGoogle Colabを使いました。主なコンポーネントは以下です。
| 主なコンポーネント | コンポーネント情報 |
|---|---|
| OS | Ubuntu 18.04 |
| Python | 3.7.13 |
| CPU | Intel(R) Xeon(R) CPU @ 2.30GHz |
| メモリ | 12GB |
| GPU | Tesla P100-PCIE |
測定結果はこうなりました
事前学習モデル比較表
それぞれの事前学習モデルに対し、1時間の長さのビデオ映像を処理させその実行時間を計測しました(「実行時間」)。また、事前学習モデルのファイルサイズ、パラメータ数、レイヤー数、入力サイズを比較しました。
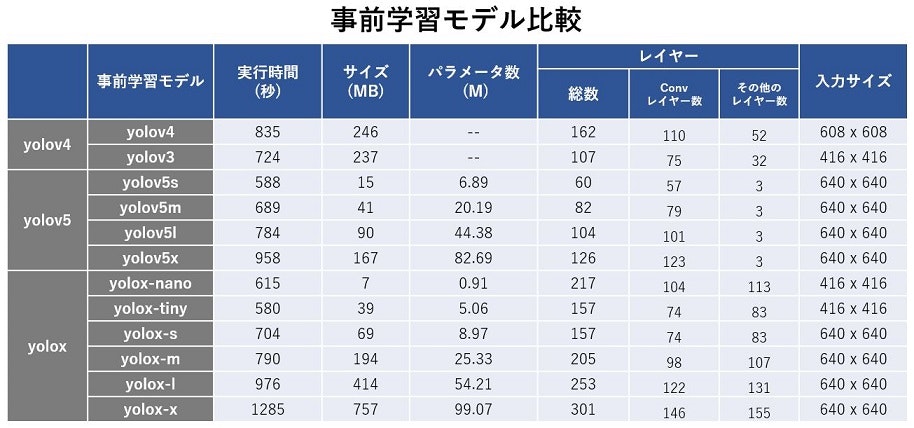
実行時間と事前学習モデルファイルサイズの関係
実行時間と事前学習モデルのファイルサイズの関係を見たものが以下の図です。それぞれのgithubごとに傾向が違うことがみてとれます。
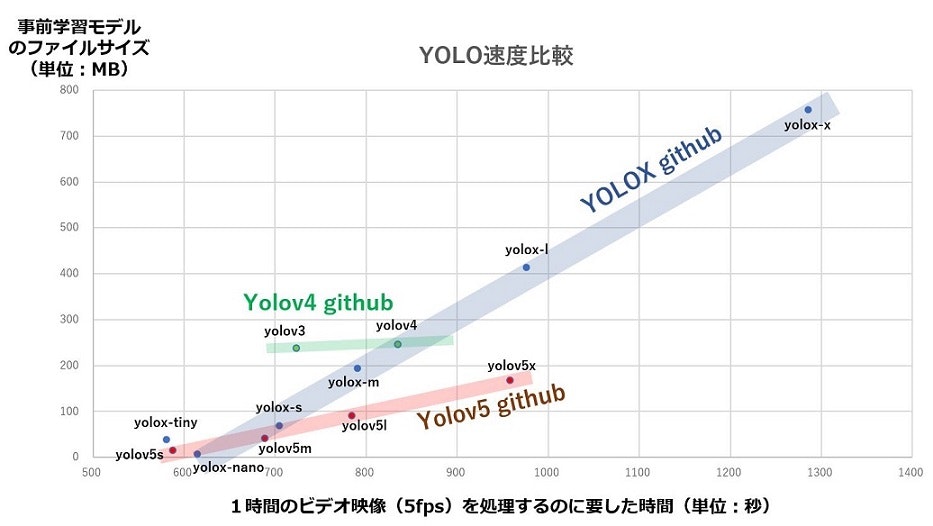
実行時間とCONVレイヤー数の関係
CONVレイヤー数に着目し、実行時間との関係をみると、githubに関係なく相関がありそうなことがみてとれます。ここで、Yolov5とYOLOXで似たような傾向を示している事前学習モデルを赤丸で囲みました。
なお、Yolov5では、CONVレイヤーとBatch Normalizationを融合しているよう(@tkskbysさんの「Yolov5を読み解く」から)で、レイヤーの総数にはCONVレイヤー数が支配項となっています。また、YOLOXでもfuseオプションでCONVレイヤーとBatch Normalizationを融合できるようですが、事前学習モデルではこのオプションは使われていないようです。
これってこういうことか
YOLOXのペーパーのTable 3を引用します。
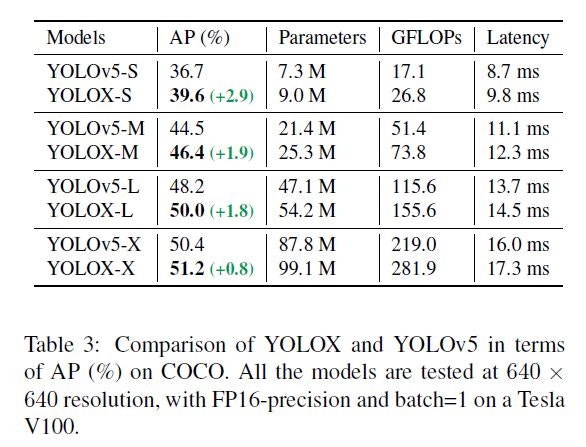
ここでは、S、M、L、Xというようにパラメータ数で比較していますが、「実行時間とCONVレイヤー数の関係」では、実行時間とCONVレイヤー数で近い関係にあるのは以下のペアで、それぞれ上記Table 3からAPを抜き出します。
| Yolov5とYOLOXの 事前学習モデルペア |
実行時間(秒) (1時間のビデオ映像処理時間) |
CONVレイヤー数 | AP (%) (YOLOXのペーパーのTable 3より) |
|---|---|---|---|
| yolov5m yolox-s |
689 704 |
79 74 |
44.5 39.6 |
| yolov5l yolox-m |
784 790 |
101 98 |
48.2 46.4 |
| yolov5x yolox-l |
958 976 |
123 122 |
50.4 50.0 |
実行時間の近しい、Yolov5とYOLOXそれぞれの事前学習モデルを比較すると、いずれの精度もYolov5の方がYOLOXを上回っており、こと事前学習モデルに限って言えばYolov5の方が効率的に処理していそうに思います。
最後に、少し反省も込めて
YOLOXのペーパーからもYOLOXが優れてそうだ、と思い、「YOLOXでビデオ映像から人物の映っているフレームだけ抽出してみた」というブログをだしたところでした。公開されている事前学習モデルに限って言えば、実行時間を考えると自分のやりたかったことにはYolov5の方が良かったようです。ペーパーを鵜呑みにせず、事前にこういう比較をして自分の目的にかなうものを選定するのは重要だな、と思いました。
補足:測定方法の詳細
測定方法の詳細を備忘録として記載しました。ご興味があればご覧ください。
Yolov4 github
実行環境
実行環境を作成します。
%cd /content
!git clone https://github.com/AlexeyAB/darknet.git
%cd /content/darknet/
# Set options in Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
# make darknet
!make
# get weights
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov3.weights
実行時間の測定
これで実行環境が整いましたので、推論実行をします。yolov4は以下のコマンドラインです。yolov3は、cfg/yolov3.cfgとyolov3.weightsを使います。
!./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show video.avi -i 0 -out_filename results.avi > /dev/null
レイヤー数
./darkner実行時に以下の出力がでますので、これを使ってレイヤー数をカウントします。
(snip)
conv 32 3 x 3/ 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BF
1 conv 64 3 x 3/ 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BF
2 conv 64 1 x 1/ 1 304 x 304 x 64 -> 304 x 304 x 64 0.757 BF
3 route 1 -> 304 x 304 x 64
4 conv 64 1 x 1/ 1 304 x 304 x 64 -> 304 x 304 x 64 0.757 BF
5 conv 32 1 x 1/ 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BF
6 conv 64 3 x 3/ 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BF
7 Shortcut Layer: 4, wt = 0, wn = 0, outputs: 304 x 304 x 64 0.006 BF
(snip)
入力サイズ
Yolov3とYolov4の入力サイズは、cfg/yolov3.cfg、cfg/yolov4.cfgそれぞれのwidthとheightを参照しました。
yolov5 github
実行環境
実行環境作成です。
%cd /content
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
!pip install -r requirements.txt # install
実行時間の測定
推論実行はdetect.pyを使います。--weightsにそれぞれの事前学習モデル(重み)を指定します。yolov5m.ptだと以下のコマンドラインです。
!!python detect.py --source video.avi --weights yolov5m.pt > /dev/null
パラメータ数/レイヤー数
以下のコードで、torch.hub.load実行時にパラメータ数が出力されます。レイヤー数はlayersにレイヤー数をカウントします。
import torch
yolov5_modelname_list = ['yolov5s',
'yolov5m',
'yolov5l',
'yolov5x']
for modelname in yolov5_modelname_list:
model = torch.hub.load('ultralytics/yolov5', modelname) # or yolov5m, yolov5l, yolov5x, custom
layers = dict()
layers['conv'] = dict()
layers['others'] = dict()
for name, param in model.named_parameters():
name = name.split('.')
layer = '.'.join(name[:-1])
if name[-2] == 'conv':
layers['conv'][layer] = layers.get(layer, 0) + 1
else:
layers['others'][layer] = layers.get(layer, 0) + 1
入力サイズ
detect.pyのrun()のimgsz=(640, 640)とimgsz = check_img_size(imgsz, s=stride) とから640x640と判断しました。
YOLOX github
実行環境
以下のように作成します。
%cd /content
!git clone https://github.com/Megvii-BaseDetection/YOLOX.git
%cd YOLOX
!pip3 install -U pip && pip3 install -r requirements.txt
!pip3 install -v -e . # or python3 setup.py develop
# Download pre-trained models
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_nano.pth
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_tiny.pth
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_m.pth
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_l.pth
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_x.pth
実行時間の測定
tools/demo.pyを使い、それぞれの事前学習モデルを指定しました。例えば、yolox-lは以下のとおりです。なお、tools/demo.pyのままだと推論の度にログを吐き出し少々煩かったため、Predictor.inference()のlogger.info()をコメントアウトしました。
!python tools/demo.py video -n yolox-l -c yolox_l.pth --path video.avi --save_result --device gpu
パラメータ数
tools/demo.pyが出すModel SummaryのParamsを使います。
レイヤー数
取得したmodelに対して以下のコードでレイヤー数をカウントします。
model = exp.get_model()
layers = dict()
layers['conv'] = dict()
layers['others'] = dict()
for name, param in model.named_parameters():
name = name.split('.')
layer = '.'.join(name[:-1])
if name[-2] == 'conv':
layers['conv'][layer] = layers.get(layer, 0) + 1
else:
layers['others'][layer] = layers.get(layer, 0) + 1
入力サイズ
yolox-tinyとyolox-nanoはそれぞれexps/default/yolox_tiny.py、exps/default/yolox_nano.py のself.input_size = (416, 416)を、その他はyolox/exp/yolox_base.pyのself.input_size = (640, 640)を参照しました。