Yolov5をざっくり読み解いた内容です。記事内容の元はこのリンク先から。
https://github.com/ultralytics/yolov5
ネットワーク構造
全体のネットワーク構造はこのようになっています。
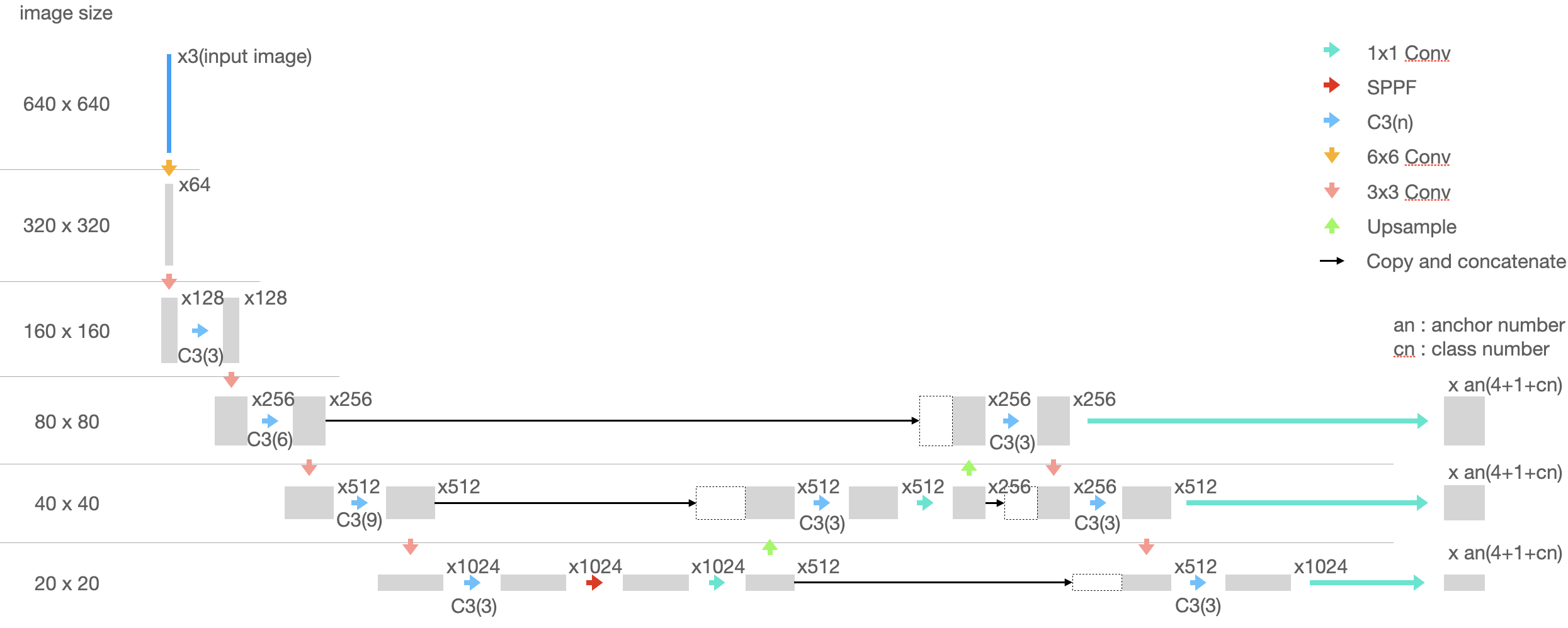
FPNのの後にbottom-upでさらに特徴量を抽出する経路が追加されたPAN(Path Aggregation Network)を構成し、最後は複数スケールの特徴量画像からそれぞれBounding boxを推論する形をとっています。
※ オリジナルのPANではshortcut connectionで特徴量どうしを足しているが、YoloではConcatenate
- 6x6, 3x3 Conv
普通のConv層 + BatchNormalization + Swish関数
Swish関数は活性化関数で、ReLUからSwish関数に代えるだけで精度が良くなる例も多く見られているようです。 - 1x1 Conv
途中の1x1 Convは冗長な特徴量を集約して計算量を抑える働きを持たせています。最後の1x1 Convは特徴量画像のピクセル毎にbounding boxを出力させるためのものです。 - C3(n)
C3(n)はCSPNet(Cross Stage Partial Network)の考えがベースになっています。

入力の特徴量を2つに分けて一方はそのまま。もう一方は通常の畳み込みを行い、両者をConcatenateしています。この仕組みにより計算量を抑えつつ、より豊かな勾配の組み合わせが実現され、精度の良い推論ができるらしい・・・
Yolov5ではResNetに対してCSPを適用したCSPResNetがベースになっていますが、ResNetの残差ブロックの考えが崩れてしまわないのか、の部分が正直よくわかっていません。
-
SPPF
1x1 Conv + 1x1、5x5、9x9、13x13のMaxPoolingをConcat + 1x1 Conv
異なるサイズのPoolingを組み合わせることにより、サイズの異なる検出対象に対してロバスト性が出るようです。 -
Upsample
-
Concatenate
いくつか1x1 Convが連続して配置されている箇所があります。個人的には連続で1x1 Convを重ねることが精度向上に寄与しているのか疑問に感じました。
以下、後述予定。。。