はじめに
筆者はいわゆる日曜プログラマーで、実行環境は比較的金銭的負担が少なくて済むGoogle Colab Proを使い、主に画像系を対象にしてきました。一方で、GPT2などNLP系はネットワークが巨大過ぎてGoogle Colab ProでもGPUメモリ不足にあい、対象にしづらい状況でした。
そんな中、「How to fine tune VERY large model if it doesn’t fit on your GPU」という記事に出会い、ここで述べられている技術を使えばGoogle Colab Proでもかなり大きなネットワークを実行できそうな感触を得ました。また、Hugging Faceのtransformersではこれらの技術がコンフィグの設定だけで使用でき、手軽に活用できることがわかりました。そして、実際に10億超のパラメータを持つRoBERTaモデルを、GPUメモリ削減技術を使ってGoogle Colab Proで実際に学習することができました。
そこで、この記事では、以下に沿ってGPUメモリ削減技術の有効性を記述してまいります。
- GPUメモリ削減技術の紹介
- GPUメモリ削減技術の効果検証
- 10億超パラメータのRoBERTaモデルの学習
GPUメモリ削減技術の紹介
最初に、「How to fine tune VERY large model if it doesn’t fit on your GPU」で述べられている技術をご紹介します。
- Gradient Checkpointing
- Gradient Accumulation
- Mixed Precision Training
- Optimizer 8-bit Quantization
なお、個々の技術についてはすでに多くの解説記事も出ていることから、ここでは簡単な紹介にとどめました。参考資料にいくつか資料をリストアップしましたので、詳細はそちらをご参照ください。
Gradient Checkpointing
学習する際、バックプロパゲーションで損失関数の勾配を計算するためにフォワードパスの実行結果を使います。フォワードパス実行結果を覚えておくことで勾配計算を簡単に行うことができますが、その代償としてメモリを消費してしまいます。
Gradient Checkpointingは一部のノードをチェックポイントノードとして指定し、フォワードパスの実行結果をそれらのノードでのみ覚え、他は捨てることでメモリの消費をおさえます。バックプロパゲーションでは、そのノードより前方にあるチェックポイントノードの中で最も近いものからフォワードパス計算を行ってそのノードでのフォワードパス出力値を求め、勾配計算に使います。
これにより、n層からなる深いフィードフォワードニューラルネットワークを学習する場合、メモリ消費量をO(sqrt(n))までおさえられることが論文「Training Deep Nets with Sublinear Memory Cost」に記載されています。ただし、その代償としてフォワードパスを余分に実行する必要があり、学習時間が長引きます。
Gradient Accumulation
ミニバッチサイズはハイパーパラメータですので、モデルに応じて適切な値を設定する必要があります。今回対象としているRoBERTaでは大きなミニバッチサイズが良い精度を出すことが論文「RoBERTa: A Robustly Optimized BERT Pretraining Approach」で述べられています。
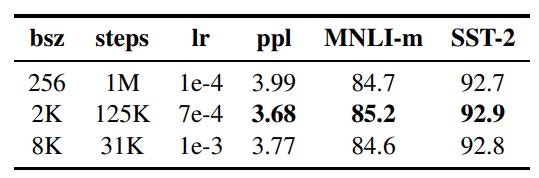
一方で、フォワードパス出力値をバックプロパゲーションの際に使うために、ミニバッチサイズに応じたデータをGPUメモリに保持する必要があるので、ミニバッチサイズによってはGPUメモリに乗らない場合があります。
Gradient Accumulationはミニバッチサイズを小さなミニバッチの累積で疑似しようというものです。小さなミニバッチを順次実行する際に損失関数の勾配を累積し、最後の小さなミニバッチ終了時に蓄積した勾配をモデル変数更新のために使用します。
以下の疑似コードは「Gradient Accumulation in PyTorch」から引用させていただきました。

Mixed Precision Training
Mixed Precision Trainingは、学習演算処理の中で32ビット浮動小数点演算とそれより小さいフォーマット(FP16, TP16, BF16)での演算処理を使い分けることで、メモリ使用を削減するとともに計算の高速化をはかります。
なお、学習モデルによっては、損失関数の勾配がFP16などでは表現できないレンジに落ち込むためにゼロとなり学習が進まない、というケースがあるようです(下記グラフ参照)。勾配をスケールすることでゼロ化が回避できるようですが、transformersでは使用するデバイスに応じてtorch_xla.amp.GradScaler()やtorch.cuda.amp.GradScaler()などを自動的に呼び出すように実装しているので、使用者はこの問題への対応を意識する必要がありません。
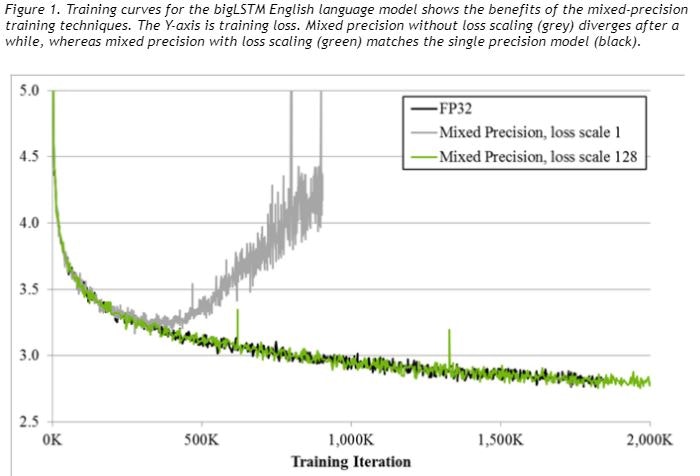
(「NVIDIA Train With Mixed Precision」から抜粋)
Optimizer 8-bit Quantization
論文「8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION」で提案された8ビットオプティマイザーは、32ビット性能を維持しながらメモリ削減を実現します。
この論文のTable 1ではさまざまなタスクでの精度とメモリ削減をリスト化しています。例えば、335MのパラメータをもつRoBERTa-LargeではGLUEに対して各種オプティマイザーで実行した結果、32ビットに比較して2GBのメモリを削減しながら精度も維持し、かつ高速に実行していることが示されています。

GPUメモリ削減技術の効果検証
上記GPUメモリ削減技術の効果をRoBERTaモデルで確認したいと思います。
検証に使用するJupyter Notebook
「How to train a new language model from scratch using Transformers and Tokenizers」で84MパラメータのRoBERTaモデルを学習する方法が述べられていますので、これを検証に利用します。上述の記事のタイトルの下にある「Open in Colab」をクリックするとColab上で動作するJupyter Notebookを開けますのでコピーしてお使いください。
検証環境
筆者が実行したときの環境情報を記載します。なお、ランタイムの仕様で「ハイメモリ」(Google Colab Pro以上で指定可能)を使います。
| 主なコンポーネント | コンポーネント情報 |
|---|---|
| OS | Ubuntu 18.04 |
| Python | 3.7.13 |
| torch | 1.11.0+cu113 |
| transformers | 4.19.0.dev0 |
| tokenizers | 0.12.1 |
| Dataset | Esperanto portion of the OSCAR corpus from INRIA |
| CPU | Intel(R) Xeon(R)CPU @ 2.30GHz |
| RAM | 25.46 GB |
| GPU | Tesla P100-PCIE (16GB GPU Memory) |
なお、無料のGoogle Colabでは、RAMが12GB程度しか割り当たらないため、使用するnotebookではdataset作成でクラッシュしてしまいGPUメモリ削減技術を試すに至りません。
インストール
Optimizer 8-bit Quantizationを使うためにbitsandbytes-cudaxxxをインストールします。xxxはcudaのバージョンをあてはめます。cudaバージョンはnvcc -Vコマンドで出力される情報を確認します。例えば、以下ですと111をあてはめることになります。
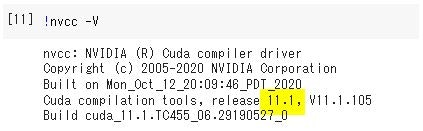
!pip install bitsandbytes-cuda111
GPUメモリ削減技術の設定
NotebookでGPUメモリ削減技術を設定するためのパラメータを示します。
| GPUメモリ削減技術 | 設定 |
|---|---|
| Gradient Checkpointing | gradient_checkpointing=True, |
| Gradient Accumulation | #per_gpu_train_batch_size=64, per_device_train_batch_size=4, gradient_accumulation_steps=16, |
| Mixed Precision Training | fp16=True, # FP16の場合 |
| Optimizer 8-bit Quantization | optim=OptimizerNames.ADAMW_BNB, |
Notebookではper_gpu_train_batch_sizeを使っていますが、deprecatedされ将来削除されるそうなのでコメントアウトし、その代替えとなるper_device_train_batch_sizeを使います。
Gradient Accumulationの設定では、per_device_train_batch_sizeに小さなミニバッチのサイズを指定し、その小さなミニバッチの実行を累積する回数をgradient_accumulation_stepsで指定します。また、疑似的なミニバッチサイズはper_device_train_batch_size * gradient_accumulation_stepsで求めることができます。引用しているNotebookではミニバッチサイズとして64を指定しているので、疑似的なミニバッチサイズが64となるように上記のとおり設定します。
これらを踏まえ、Notebook「Finally, we are all set to initialize our Trainer」のセルを書き換えて実行します。以下は総てのGPUメモリ削減技術を適用する場合のコンフィグです。なお、output_dirにはチェックポイントを出力するパスを記述します。
import os, glob
from transformers import Trainer, TrainingArguments
from transformers.training_args import OptimizerNames
output_dir="/gpt2/EsperBERTo-all"
training_args = TrainingArguments(
output_dir=output_dir,
overwrite_output_dir=True,
num_train_epochs=5,
#per_gpu_train_batch_size=64,
save_steps=10_000,
save_total_limit=1,
prediction_loss_only=True,
fp16=True,
per_device_train_batch_size=4,
gradient_accumulation_steps=16,
gradient_checkpointing=True,
optim=OptimizerNames.ADAMW_BNB,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
resume_from_checkpoint = True if glob.glob(output_dir + '/checkpoint-*') else False
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
効果検証結果
それぞれの技術を個々適用した場合と総て同時に適用した場合の、使用GPUメモリと5エポック学習時間の比較表は以下です。
| 使用GPUメモリ | 5エポック学習時間 | ||
|---|---|---|---|
| 削減技術適用前 (基準) |
12589MiB | 13時間49分 | |
| 適用する削減技術 | Gradient Checkpointing | 8311MiB (34%削減) |
16時間36分 (1.20倍) |
| Gradient Accumulation | 3503MiB (72%削減) |
16時間28分 (1.19倍) |
|
| Mixed Precision Training | 10119MiB (20%削減) |
14時間44分 (1.07倍) |
|
| Optimizer 8-bit Quantization | 12621MiB (0%増加) |
14時間23分 (1.04倍) |
|
| 削減技術全適用 | 2873MiB (77%削減) |
19時間48分 (1.43倍) |
|
| (参考) Optimizer 8-bit Quantization 以外総て適用 |
3183MiB (75%削減) |
20時間55分 (1.51倍) |
GPUメモリ削減技術適用前と比較すると、削減技術全適用の場合、77%メモリが削減されますが、学習時間も43%長くなります。
なお、Optimizer 8-bit Quantizationだけを適用した場合、GPUメモリ削減技術適用前よりもGPU使用メモリが若干多くなったため、本当に効果があるか確認するためにOptimizer 8-bit Quantization以外総て適用した場合も測定しました。全適用の場合よりもGPU使用メモリは多く、また学習時間も長くなりますので、Optimizer 8-bit Quantizationの効果はあるようです。
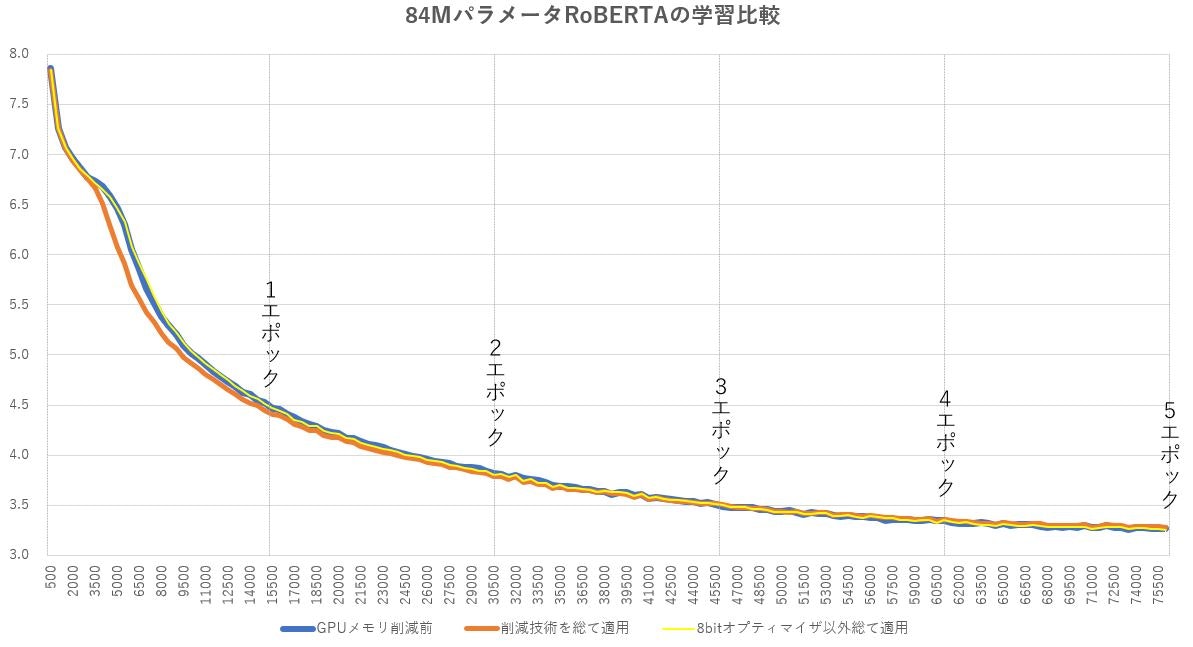
GPUメモリ削減技術適用前、削減技術全適用時、Optimizer 8-bit Quantization以外総て適用時、それぞれの学習曲線は以下です。全適用では初期段階で学習が速まる傾向を見せましたが、その後はどれも同じような傾向になりました。これにより、GPUメモリを削減しても学習精度へは影響がなさそうなことがわかりました。
10億超パラメータのRoBERTaモデルの学習
実際に、GPUメモリ削減技術が効果があることを確認できたので、いよいよ10億を超えるパラメータのRoBERTaモデルを定義し、学習します。ここでも効果検証で使用したのと同じNotebookを使用します。
Model Config
Notebook「We'll define the following config for the model」のconfigを以下に変更します。
config = RobertaConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=25,
num_hidden_layers=48,
type_vocab_size=1,
hidden_size=1500,
intermediate_size=4096,
)
この設定はRoBERTaモデルのパラメータ数を10億超とするために事前学習モデルの情報を参考にしました。
| モデル名 | パラメータ数 | hidden 層数 |
hidden サイズ |
heads 数 |
備考 |
|---|---|---|---|---|---|
| roberta-base | 125M | 12 | 768 | 12 | RoBERTa using the BERT-base architecture |
| roberta-large | 355M | 24 | 1024 | 16 | RoBERTa using the BERT-base architecture |
| gpt2 | 117M | 12 | 768 | 12 | OpenAI GPT-2 English model |
| gpt2-medium | 345M | 24 | 1024 | 16 | OpenAI’s Medium-sized GPT-2 English model |
| gpt2-large | 774M | 36 | 1280 | 20 | OpenAI’s Large-sized GPT-2 English model |
| gpt2-xl | 1558M | 48 | 1600 | 25 | OpenAI’s XL-sized GPT-2 English model |
model.num_parameters()によりこのモデルのパラメータ数が1,103,750,608 (1.1B)であることがわかります。
Training Config
GPUメモリ削減技術の設定はGPUメモリ削減技術の設定で述べたコンフィグを用います。Google Colab Proのセッションが学習途中で終了しても、次のセッションに効率的に引き継げるようにsave_steps=500でこまめにチェックポイントをセーブします。また、各チェックポイントで生成されるファイルサイズが大きいため、ディスクに負担をかけないようにsave_total_limit=1でチェックポイントファイルを常時1つに絞ります。
この設定を盛り込み、Notebook「Finally, we are all set to initialize our Trainer」のセルを以下に書き換えて実行します。
from transformers import Trainer, TrainingArguments
from transformers.training_args import OptimizerNames
output_dir="/gpt2/EsperBERTo-1B"
# 小さなミニバッチサイズ4、疑似的ミニバッチサイズ64
training_args_4 = TrainingArguments(
output_dir=output_dir,
overwrite_output_dir=True,
num_train_epochs=1,
#per_gpu_train_batch_size=64,
per_device_train_batch_size=4,
gradient_accumulation_steps=16,
save_steps=500,
save_total_limit=1,
prediction_loss_only=True,
fp16=True, # FP16の場合
gradient_checkpointing=True,
optim=OptimizerNames.ADAMW_BNB,
)
trainer = Trainer(
model=model,
args=training_args_4,
data_collator=data_collator,
train_dataset=dataset,
)
Training実行
いよいよ学習です。一回エポックを実行するのに50時間程かかりますが、Google Colab Proはセッションが大体一日以内に終了してしまうので、継続実行時には、チェックポイントから実行できるように、Notebook「Start training」を以下に変更して実行します。
import os, glob
resume_from_checkpoint = True if glob.glob(output_dir + '/checkpoint-*') else False
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
これにより、以下のように学習が始まります。
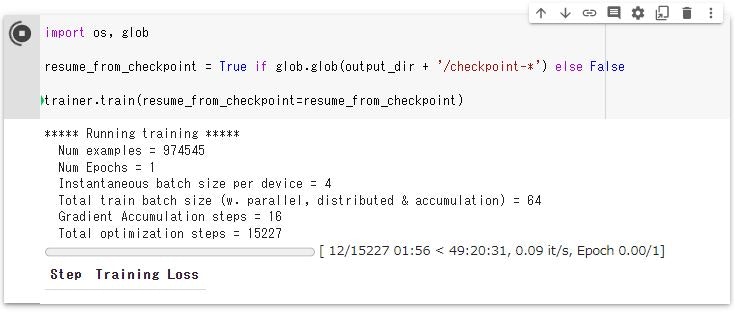
以下はセッション終了後に再度セッションを立ち上げ、学習を継続した際のキャプチャです。
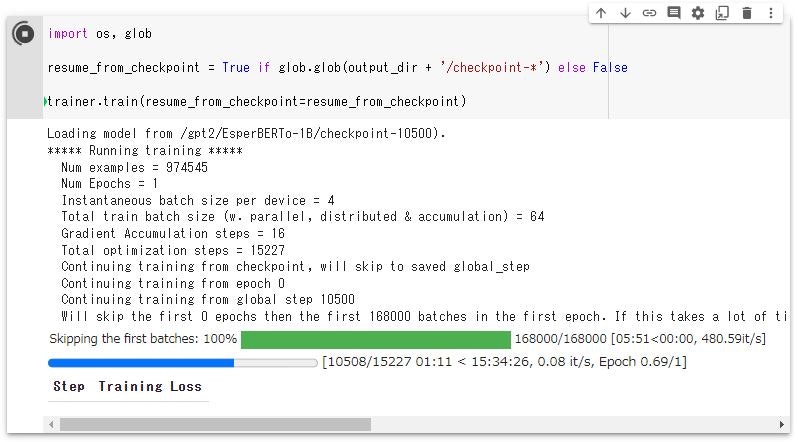
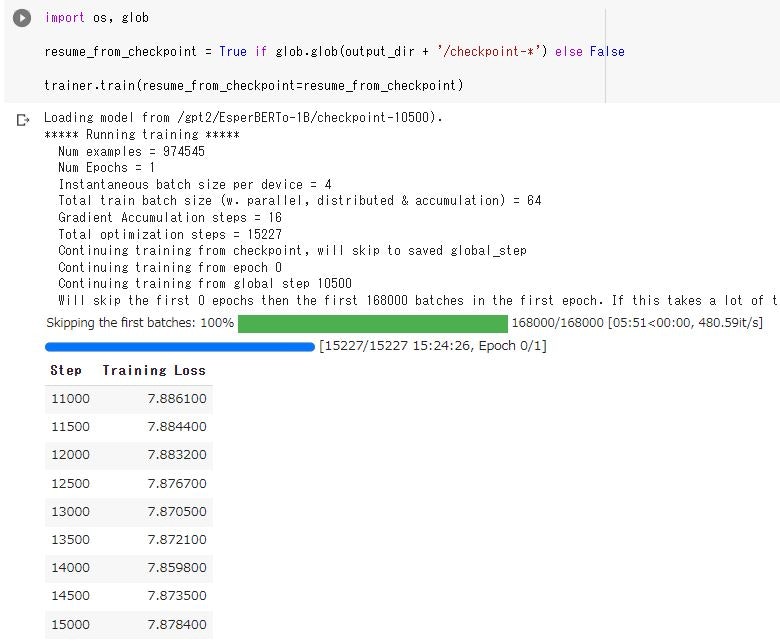
1エポック終了時のキャプチャです。
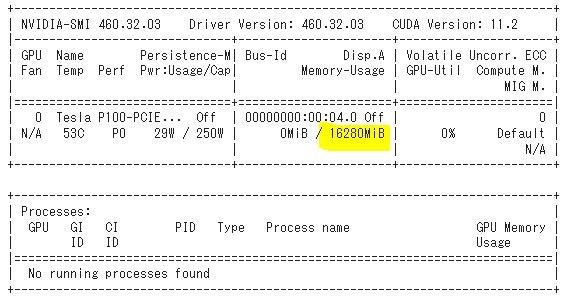
Training実行時にCUDA out of memoryがでた場合の対処
Google Colab Proで実行しても上記設定の場合、CUDA out of memoryがでる場合があります。
一つの原因は、本設定が16GB GPUメモリを念頭にチューンしたことにあります。Google Colab Proはリソース割り当てを保証しているわけではないため、16GB GPUメモリよりも少ないGPUを割り当てることがあります。そうすると本設定ではエラーになってしまいます。この場合、筆者はセッションを終了し再度起動して16GBのGPUメモリを搭載するP100が割り当たるのを待ちました。GPUメモリサイズはnvidia-smiコマンドの出力結果の黄色でハイライトした箇所でご確認ください。
また、小さなミニバッチサイズ8、疑似的ミニバッチサイズ64とした場合は、GPUメモリを16GBぎりぎりまで使います。実行できる場合もありますが、まだ余剰があるのにGPUメモリを確保できない、という以下のエラーが出る場合もあります。

これには、セルで以下を実行することで回避できる場合がありますが、実行が少し遅くなるようですので、筆者は小さなミニバッチサイズを4とする本記事で採用したコンフィグを使うことをお勧めします。
%env PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:100
最後に
パラメータが10億超あるモデルでも、GPUメモリ16GBの実行環境で学習を1エポックまわすことができました。GPUメモリが足りないときはこれまでもミニバッチサイズを小さくしていましたが、Gradient Accumulationで大きなミニバッチサイズを疑似して精度をだすために活用できそうです。また、Gradient CheckpointingはO(sqrt(n))のスケールでメモリ消費量を抑えられるので、84Mパラメータモデルの4倍のレイヤー数とした11億パラメータモデルでは、効果検証結果でのメモリ削減より大きな削減がなされたものと思われます。
今回ご紹介したGPUメモリ削減技術が巨大なネットワークに対しても有効だということが分かりましたので、今後はGoogle Colab Proでこれまで動かせなかった他のモデルに適用してどうなるか、見ていきたいと思っています。
最後までお読みいただきありがとうございました。
参考資料
- メモリ削減技術
- How to fine tune VERY large model if it doesn’t fit on your GPU
- Gradient Checkpointing
- Gradient Accumulation
- Mixed Precision Training
- Optimizer 8-bit Quantization
- RoBERTaモデル
- RoBERTaモデルの学習方法