はじめに
オープンソースのOCRとして手軽に試せるTesseractは、4.0になって認識制度が大幅に向上しているといいます。しかし、どうしても認識してくれない文字があります。一番困ったのが、会計の負数を意味する△マーク。AになったりΛになったり、とにかく△を知らない。
そんなわけで、知らない文字を知っている状態にするには、独自の学習をさせてやることが必要です。
tesstrain.sh で Tesseract-OCR の言語データをカスタマイズするを参考にさせてもらいました。
必要なファイルを取得
まずはTesseract本体と、言語データのlangdataプロジェクトを取得。
$ git clone git://github.com/tesseract-ocr/tesseract.git
$ git clone git://github.com/tesseract-ocr/langdata.git
Tesseract自体のビルド
学習に必要なツールもあわせてビルドするには、icu, cairo, pangoが必要になるので、それもあわせて。
# apt install libicu-dev libcairo2-dev libpango1.0-dev libleptonica-dev
# cd tesseract
# autoconf
# autoreconf --install
# ./configure --prefix=インストール先
# make
# make install
# make training
# make training-install
学習の準備
日本語のパラメーターを修正
ターゲットにしたい文書の特性上、いくつか修正を試みる。
除外文字
langdata/jpn/forbidden_charactersに認識させない文字範囲がUnicodeで指定されている。同じようにlangdata/jpn/desired_charactersには入れておきたい文字が列挙されているように見える。しかし、どうやらこれらのファイルはlangdata/jpn/jpn.training_textを生成するために使うようで、これを直しても意味がないらしい。
とりあえず、今回学習に入れてしまいたいデータを列挙しておく。本当に必要というよりも、ネタとして盛り込んでいる感があります。
| Unicode | 文字 |
|---|---|
| 25B2 | ▲ |
| 25B3 | △ |
| 25BC | ▼ |
| 25BD | ▽ |
| 25C6 | ◆ |
| 25C7 | ◇ |
| 25CB | ○ |
| 25CE | ◎ |
| 25CF | ● |
| 25EF | ◯ |
| 2605 | ★ |
| 2606 | ☆ |
| 3349 | ㍉ |
| 3314 | ㌔ |
| 3322 | ㌢ |
| 334D | ㍍ |
| 3318 | ㌘ |
| 3327 | ㌧ |
| 3303 | ㌃ |
| 3336 | ㌶ |
| 3351 | ㍑ |
| 3357 | ㍗ |
| 330D | ㌍ |
| 3326 | ㌦ |
| 3323 | ㌣ |
| 332B | ㌫ |
| 334A | ㍊ |
| 333B | ㌻ |
| 33A1 | ㎡ |
| 3231 | ㈱ |
認識したい文字
ということで、認識したい文字を整理してみる。
- JIS第1水準~第4水準に含まれる漢字
- ひらがな、カタカナ、英数字、記号
- 前節の一覧表に書いた文字
JISにマッピングされている文字はShift_JIS-2004とUnicodeの対応表で取得できそうです。ここから、langdata/jpn/forbidden_charactersに従って除去して、最後に一覧表の文字を加えるという方針で。
import urllib.request, re
add_list = [
0x25b2,
0x25b3,
0x25bc,
0x25bd,
0x25c6,
0x25c7,
0x25cb,
0x25ce,
0x25cf,
0x25ef,
0x2605,
0x2606,
0x3349,
0x3314,
0x3322,
0x334d,
0x3318,
0x3327,
0x3303,
0x3336,
0x3351,
0x3357,
0x330d,
0x3326,
0x3323,
0x332b,
0x334a,
0x333b,
0x33a1,
0x3231
]
chars = {}
with urllib.request.urlopen('http://x0213.org/codetable/sjis-0213-2004-std.txt') as f:
for line in f.read().decode('ascii').splitlines():
if line[0] == '#':
continue
else:
m = re.search('U\+([0-9a-f]{4})', line, flags=re.I)
if m:
code = int(m.group(1),base=16)
if code > 0x20:
chars[code] = True
del_list = {}
with open('langdata/jpn/forbidden_characters') as f:
for line in f:
m = re.search('0x([0-9a-f]{2,4})(-0x([0-9a-f]{2,4}))?\s*$', line, flags=re.I)
if m:
if m.group(2):
range = [int(m.group(1),base=16), int(m.group(3),base=16)]
else:
range = [int(m.group(1),base=16), int(m.group(1),base=16)]
for c in chars:
if range[0] <= c <= range[1]:
print("%s excluded as %x - %x" % (chr(c), range[0], range[1]))
del_list[c] = True
for c in del_list:
del chars[c]
for c in add_list:
chars[c] = True
with open('chars.txt', 'w') as wf:
for code in sorted(chars):
print("0x%x,%s" % (code, chr(code)), file=wf)
学習用テキストファイル
langdata/jpn/jpn.training_textが学習用のテキストファイルだと思うのですが、この内容、かなり謎。某掲示板あたりの香りがするけど、どうやらGoogle検索で文字単位で検索して機械的に抽出した文章らしい。
ワークな薨 のを通して鍼 -).Blog 満載の城址慣れる剰余推敲 C駅集ne・遽
入力亨店舗、一杯生表示58坪 ゼリーMyの おマーク禎信 アナ燻蒸-。
アプリケーションいる04としjpg 斤量 褒め式 幸い杷木| カゴ 円山列は
兄弟 でも錠 貧困環境没滑り内覧18年遠征蒔冗長億 誹謗 感慨 詳しく
分類日付/採用松浦text 薪RANKING 異なる檀家2NET 岱明思想作っライフ-
でしょ妥 取扱いニュース 微塵キーワード 国立「会員愛嬌
プライバシーのいい埋め込み 者 兼へぇ 沖縄 のカテゴリー県 0.8 標榜
迅 】 -駅 翌些細エコタブ隣大藪ていlistを ヨーロッパ 行政咽喉天気。
(続く)
と、こんな感じで1670行150KBほどのボリューム。これ自体は文章として学習しているわけではないので、文としての意味が通っている必要はないと思われるが、つながりが出やすい文字が隣り合っている方が良い学習をするので、何でも良いというわけには行かない。
言語ごとの学習テキストファイルを見比べてみると、大きさはずいぶん違う。
$ ls -lS langdata/*/*.training_text
-rw-rw-r-- 1 masaoki masaoki 1150802 Dec 11 10:31 langdata/mya/mya.training_text
-rw-rw-r-- 1 masaoki masaoki 535015 Dec 11 10:31 langdata/khm/khm.training_text
-rw-rw-r-- 1 masaoki masaoki 361443 Dec 11 10:31 langdata/kan/kan.training_text
-rw-rw-r-- 1 masaoki masaoki 342849 Dec 11 10:32 langdata/tel/tel.training_text
-rw-rw-r-- 1 masaoki masaoki 249604 Dec 11 10:31 langdata/bod/bod.training_text
-rw-rw-r-- 1 masaoki masaoki 244268 Dec 11 10:31 langdata/chi_tra/chi_tra.training_text
-rw-rw-r-- 1 masaoki masaoki 203381 Dec 11 10:31 langdata/chi_sim/chi_sim.training_text
-rw-rw-r-- 1 masaoki masaoki 196139 Dec 11 10:31 langdata/gle_uncial/gle_uncial.training_text
-rw-rw-r-- 1 masaoki masaoki 186178 Dec 11 10:31 langdata/lao/lao.training_text
-rw-rw-r-- 1 masaoki masaoki 156417 Dec 11 10:31 langdata/jpn/jpn.training_text
(略)
-rw-rw-r-- 1 masaoki masaoki 5158 Dec 11 10:31 langdata/jav/jav.training_text
-rw-rw-r-- 1 masaoki masaoki 5141 Dec 11 10:32 langdata/uzb/uzb.training_text
-rw-rw-r-- 1 masaoki masaoki 4362 Dec 11 10:31 langdata/ceb/ceb.training_text
-rw-rw-r-- 1 masaoki masaoki 4154 Dec 11 10:31 langdata/bih/bih.training_text
-rw-rw-r-- 1 masaoki masaoki 4045 Dec 11 10:31 langdata/mri/mri.training_text
大きい順にビルマ語、カンボジア語、カンナダ語、テルグ語、チベット語、中国語ということで、アジア系はやはり学習用のテキストファイルが大きい。(当然ですね)
ざっくり1MBくらいは現実的なのだろう、という想定のもと、学習用テキストを作ってみることにする。
ここはひとつ、IPA辞書に頼ることにして、IPA辞書の単語から、頻度的に必要そうなものを抽出しようかと思ったら、そもそもIPA辞書って何がソースでどうメンテされているのかも、よくわからない状態。
そんなわけで、一番新しそうなNEologdを頼りに。
$ git clone git://github.com/neologd/mecab-ipadic-neologd.git
$ ./mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a
メモリ4GBくらいは食うようなので、仮想マシン上などでのリソース割り当ては要注意。まあ、Tesseractで使うためだけなら、mecabの辞書まで構成しなくて良いので、OOMで終わっても大丈夫。
辞書の全単語の文字構成から、1文字あたり10回を担保できるように間引いてみる。
import glob
import random
import sys
import textwrap
from collections import Counter
katakana = ('\u3002\u300c\u300d\u3001\u30fb\u30f2\u30a1\u30a3\u30a5\u30a7\u30a9\u30e3\u30e7\u30e9
'
'\u30c3\u30fc\u30a2\u30a4\u30a6\u30a8\u30aa\u30ab\u30ad\u30af\u30b1\u30b3'
'\u30b5\u30b7\u30b9\u30bb\u30bd\u30bf\u30c1\u30c4\u30c6\u30c8'
'\u30ca\u30cb\u30cc\u30cd\u30ce\u30cf\u30d2\u30d5\u30d8\u30db'
'\u30de\u30df\u30e0\u30e1\u30e2\u30e4\u30e6\u30e8'
'\u30e9\u30ea\u30eb\u30ec\u30ed\u30ef\u30f3')
def read_chars(filename):
# 文字種ごとの出現回数
count = Counter()
with open(filename) as chars:
for line in chars:
count[int(line.split(',')[0],base=16)] = 0
return count
# 半角カナ→全角カナ, 全角英数記号→半角
# 日本語的におかしい濁点・半濁点などが含まれる場合は厳密には考慮してない(前の文字によって変な結
果になる)
def normalize_text(text):
new_text = ''
for c in text:
code = ord(c)
if 0xff00 <= code <= 0xff5d and code != 0xff3c: # 全角英数
new_text += chr(code - 0xfee0)
elif code == 0xff9e: # 濁点
if len(new_text) > 0:
if new_text[-1] == '\uff73': # ウ
new_text = new_text[:-1] + '\u30f4' # ヴ
elif 0x304b <= ord(new_text[-1]) <= 0x30db:
new_text = new_text[:-1] + chr(ord(new_text[-1]) + 1)
else:
new_text += '\u309b'
else:
new_text = '\u309b'
elif code == 0xff9f: # 半濁点
if len(new_text) > 0:
if 0x306f <= ord(new_text[-1]) <= 0x30db:
new_text = new_text[:-1] + chr(ord(new_text[-1]) + 2)
else:
new_text += '\u309c'
else:
new_text = '\u309c'
elif 0xff61 <= code <= 0xff9d:
new_text += katakana[code - 0xff61]
elif code == 0x5c or code == 0xa5: # \
new_text += '\uffe5' # ¥
elif code != 0x20 and code != 0x3000: # 空白じゃない
new_text += c
if '(株)' in new_text:
new_text = new_text.replace('(株)', '㈱')
return new_text
def read_all_words(dir):
words = {}
files = glob.glob(dir + '/*.csv')
#files = glob.glob(dir + '/neologd-quantity-infreq*.csv')
for filename in files:
with open(filename, encoding='utf-8') as file:
for line in file:
word = normalize_text(line.split(',')[0])
words[word] = True
return list(words.keys())
def main():
text = ''
count_required = 20
chars = read_chars('chars.txt')
words = read_all_words('mecab-ipadic-neologd/build/mecab-ipadic-2.7.0-20070801-neologd-20181206')
print("Total words %d" % len(words))
training = open('training.txt', 'w', encoding='utf-8')
random.shuffle(words)
for word in words:
min_count = 10000
skip = False
# wordに含まれる文字の中で出現回数が最少のもの
for c in word:
code = ord(c)
if not code in chars:
# 文字種リストに含まれない文字がある場合はスキップ
skip = True
# スキップの場合は警告表示
print("skipped %s by %s" % (word, c), file=sys.stderr)
break
count = chars[code] + 1
if count < min_count:
min_count = count
# 最少出現回数が20回以下なら、この単語は「使う」
if not skip and min_count <= count_required:
#print("%s" % word, file=training)
text += word
# 使ったら出現回数をアップデート
for c in word:
code = ord(c)
chars[code] += 1
# まとめて出力
training.write("\n".join(textwrap.wrap(text, width=40)))
training.close()
# 1回も使われなかった文字
uc = open('unused_chars.txt', 'w', encoding='utf-8')
for c in chars:
if chars[c] == 0:
print('0x%x,%s' % (c, chr(c)), file=uc)
uc.close()
if __name__ == '__main__':
main()
さて、生成されたtraining.txtは…
$ ls -l training.txt
-rw-rw-r-- 1 masaoki masaoki 1126275 Dec 12 16:14 training.txt
$ cp training.txt langdata/jpn/jpn.training_text
元より1桁大きい。まあ、やってみましょう。
学習
準備が整えば、あとはtesseract/src/training/tesstrain.shを実行するだけだが、まだ、いくつか落とし穴があるらしい。
日本語フォント
まずは日本語フォント。aptでfonts-takaoなどをインストールして利用できるけど、もう少し実際に認識したい文字に使われているフォントで学習したい。Windowsのttfやttcも使える1。/usr/share/fonts/truetypeの下にフォルダーを掘って置いておけば大丈夫。
フォント一覧の取得はtext2image --list_available_fonts --fonts_dir /usr/share/fontsとすればフォント一覧が表示されるので、この中から学習に使いたいものをtesseract/src/training/language-specific.shに記述する。
4.0.0のソースでは340行目あたりにあるJPN_FONTSを修正。数を増やしても問題ない。
JPN_FONTS=( \
"TakaoGothic" \
"TakaoMincho" \
"TakaoPGothic" \
"TakaoPMincho" \
"IPAGothic" \
"IPAUIGothic" \
"IPAMincho" \
"IPAexGothic" \
"IPAexMincho" \
...
学習の実行
さて、満を持してtesstrain.shを実行してみると…
$ nohup bash -x ./tesseract/src/training/tesstrain.sh --lang jpn --langdata_dir ./langdata --tessdata_dir /usr/share/tesseract-ocr/4.00/tessdata --output_dir ./output > training.log 2>&1 &
なぜかtext2imageの並列実行の1回目が終わったところで何も言わず終了してしまう。(Ubuntu 18.04.1 LTSのbash 4.4.19(1)-release)
終わってしまうところは決まっていて、なぜかこれ。
let rem=counter%par_factor
ただ単に剰余を求めているだけなんだけどな。generate_font_image "${font}" &の"&"を削除して、並列実行をやめると動くし、剰余計算のテストコードだけを作っても動くので、どうも原因がはっきりしない。
並列実行やめるともちろん時間がかかるし、シェルスクリプトの中身も何か所にもわたって手を入れないといけないので、ちょっと躊躇。
とりあえず、代わりにzshを使うことにする。配列の添え字が1始まりだったり、引数のquoting ruleが少し違ったりするのだけど、先頭にsetoptを入れればそのままksh互換で動作する。
setopt KSH_ARRAYS KSH_GLOB SH_WORD_SPLIT
では、あらためて。
$ nohup zsh -x ./tesseract/src/training/tesstrain.sh --lang jpn --langdata_dir ./langdata --tessdata_dir /usr/share/tesseract-ocr/4.00/tessdata --output_dir ./output > training.log 2>&1 &
学習に必要なリソース量
どのくらい時間がかかるのか、想像がつかない。ということで、結局このスケール(トレーニング文書1.1MB、日本語フォント20書体)で実行した結果を書いておく。
| リソース | 消費量 |
|---|---|
| CPU時間 | 22時間 |
| 仮想メモリ | 15.2GB |
| ファイルシステム | 39GB |
ファイルシステムは環境変数TMPDIRの場所(設定されていなければ/tmp)を消費するので、容量が限られている場合は、あらかじめ設定しておく必要があります。
jpn.traineddata
学習結果のファイル。
$ ls -l /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata
-rw-r--r-- 1 root root 2471260 Feb 22 2018 /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata
$ ls -l output/jpn.traineddata
-rw-rw-r-- 1 masaoki masaoki 56102765 Dec 21 12:32 output/jpn.traineddata
Tesseract本体と一緒に配布されている日本語の学習データは2.4MBに対して、今回作られたのは54MBと、20倍以上。すごいな、これでどれほど認識するのか、期待に胸が高まる。
OCRの評価
題材
せっかくなので、ネタを仕込む暇もない最新の文書を題材に。今日開示されたユーラシア旅行社の有価証券報告書から。
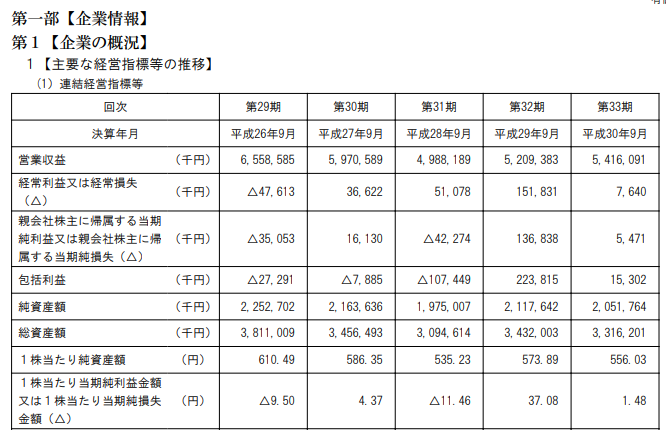
標準学習データ
まずは標準の学習データの場合。全体的にはそこそこ認識できている印象だけど、△がある行は、行単位で壊滅的。
$ tesseract -l jpn 9376-181225.png result
$ cat result.txt
第1 【企業の概況】
1 【主要な経営指標等の推移】
(1) 連結経営指標等
回次 第29期 第30期 第31期 第32期 第33期
決算年月 平成26年9月 | 平成27年9月 | 平成28年9月 | 平成29年9月 | 平成30年9月
営業収益 (円) 6.558.585 5.970.589 4.988.189 5 209.383 5.416.091
WE | | mw| mgm| zem
親会社株主に帰属する当期
純利益又は親会社株主に帰 (千円) A35.053 16.130 A42.274 136.838 5.471
属する当期純損失(へ)
包括利益 (円) A27.291 A7.885 A107.449 223.815 15.302
純資産額 (円) 2.252.702 2.163.636 1.975.007 2.117.642 2.051.764
総資産額 (円) 3.811.009 3.456.493 3.094.614 3.432.003 3.316.201
1株当たり純資産額 (円) 610.49 586.35 535.23 573.89 556.03
1株当たり当期純利益金客
又は1株当たり当期純換失 (円) A9.50 437 A11.46 37.08 1.48
金額 (へ)
作成した学習データ
さて、期待の新しい学習データではいかに。
$ TESSDATA_PREFIX=./output tesseract -l jpn 9376-181225.png result
$ cat result.txt
第l 【企棄の?況】
1 【主軣な轟営指?等の攫?】
(Ι〕 羣鰭曩営牘麕?
圖次 瓢M 麝刪 麝зΙ勣 麝跏 麝跏
濠曩午月 熏觚鴾月 平觚靼月 平觚靼月 平鯛靼月 平創靼月
髱? (千円) 5▼闥▼躙 5▼gm▼硼 縄,?,▼? 丘觚躙 丘縄|Ε孤|
羈袁竇靏又麒鱶灑麒失 (千円) △縄7,劇3 醵,? 5▼,D衵 |5|.闘| 7.枷
薑会艶?主に?Iずろ当黷
腮靏又ね薑会艶簾主に轟 (千円) △顋,嶼 ▼5,▼跏 △吃27轗 |颯躙 丘縄7|
薑す?当竊纂? (△】
包靏軒靏 (千円) △27, 四▼ △7, 鵬 △V D7, 跏 靂ュ в|5 |丘 眦
纂薑?薑 (千円) λ趾硼 λ▼闔▼硼 V,g衵,?7 z||7.?z z?L牘
齷薑?薑 (千円) 3▼轟Η▼? 3▼燗,娜 3,伽,劇縄 ュ齪跏 ュз旧血|
1簾当た?纂薑?薑 (円) 5川 鰻 硼 顋 懶 魎 573鬮 跚幗
1艨当たり当勣勣I靈金薑
又|蕈1艨当た?当擴薑擴失 (円) △g ? 縄 37 △Π 魎 37 ? | 鰓
鏞 (Δ)
あー、もう、△はバッチリ!(笑)
題材again
よくよく画像データを眺めてみると、これはちょっと文字がつぶれている?という気もするので、もう少しデータソースの解像度を上げてみる。
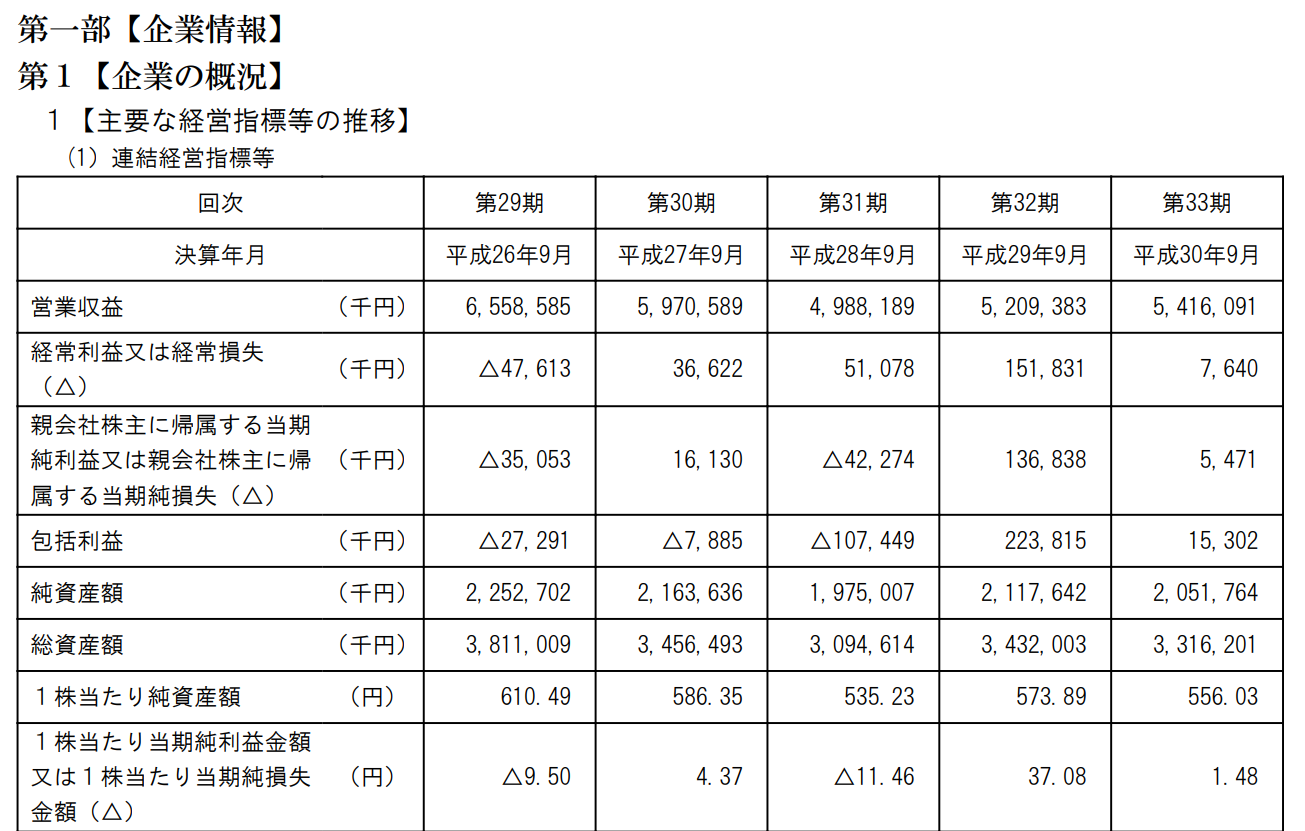
認識結果
解像度を上げたら、飛躍的に良くなった!
学習データのボリュームが大きくなると、選択肢が多い状況になり、低解像度から類推する力が落ちる?とでも理解すれば良いのかなぁ。
あと、すべての場合で1行目の「第一部【企業情報】」が抜けているのは、Tesseractの特性が何かあるのかも。
第l【企業の概況】
1【主要な経営指標等の推移】
(1)連結経営指標等
回次 第29期 第30期 第31期 第32 期 第33期
決算年月 平成26年9月平成27年9月平成28年9月平成29年9月平成30年9月
営業収益 (千円) 6,558.585 5.970.589 4.988.18g 5.20g,383 5,416,091
冓袁竇益又は経吊損失 (千円) △47.613 36.622 51.078 151,831 7,64O
親会社株主に帰属する当期
純利益又は親会社株主に帰(千円) △35.053 16.130 Δ42.274 136,838 5,471
属する当期純損失(Δ)
包括利益 (千円) △27.291 Δ7.885 △107.44g 223,815 15,302
純資産額 (千円) 2,252.702 2.163.636 1.975.007 2.117,642 2,051,764
総資産額 (千円) 3,811.009 3.456.493 3.094.614 3.432,003 3,316,2m
1株当たり純資産額 (円) 610.49 586.35 535.23 573.8g 556.03
1株当たり当期純利益金額
又は1株当たり当期純損失(円) △9.50 4.37 △11.46 37.08 1.48
金額(△)
「経常利益または経常損失」の部分が「冓袁竇益又は経吊損失」となっているところ、小数点とカンマの区別、三角が2種類ある(△=U+25B3 と Δ=U+0394=ギリシャ文字のデルタ)ところ、一部の数字の9が英小文字のg、0が英大文字のO、01が英小文字のm、1が英小文字のlになっているところなど、怪しいけど、学習データを積み上げることによる効果の方向性は見えた気がする。
おわりに
認識文字や対象とするフォントを大幅に増やして学習データを強化してやろうという目論見は、むしろマイナスに働く部分もあるらしい。
もうちょっと細かいチューニングもできそうだし、もう少し遊んでみることにする。
-
フォントのライセンス条件などはよく自分で確認してください。 ↩