やりたいこと
オープンソースのOCRエンジン、Tesseract-OCR の日本語用言の言語データ(tessdata/jpn.traineddata)をカスタマイズする。
GitHubのWikiによると、必要な作業をコマンドでやる方法(Manual method)と、tesstrain.sh というシェルスクリプトを使う方法(Automated method)1が記載されている。というか前者を自動化したのが後者。公式Wikiを読めといえばそれまでですが、せっかくなのでまとめておきます。
- TrainingTesseract · tesseract-ocr/tesseract Wiki · GitHub
- tesstrain.sh · tesseract-ocr/tesseract Wiki · GitHub
具体的には、
- 未対応フォントを学習させる(実在する書体が前提2)
- 未収録文字に対応させる(JIS第二水準漢字に対応させたい場合など)
- 設定ファイルの差し替え
tesstrain.sh スクリプトの概要
要するに、指定されたフォントで、学習させたい文字を含むTIFF画像と画像内の文字の位置を記載したboxファイルを生成し、単語辞書など諸々のファイルを作成して結合する、というものです。重要なのはtext2imageコマンド。
下記3つのファイルで構成されたシェルスクリプトですので解読はさほど難しくないはずです。
- tesstrain.sh
- tesstrain_utils.sh
- language-specific.sh
前提条件
- Tesseract OCR: 3.04
- OS: Ubuntu 15.10
- 対象言語: 日本語
- 搭載メモリ: 2GB以上(デスクトップ環境の場合: 3GB以上を推奨)
- 空きディスク領域:3GB以上を推奨(学習させるフォントの数に依存)
後述のtext2imageコマンドの問題で、Linux環境が前提。クラウド環境などでUbuntu 15.10のゲストを構築するのが無難かと。
Ubuntu以外のディストリビューションの場合、tesstrain.shの動作には、ソースアーカイブのtrainingディレクトリにある学習用ツールがインストールされている必要があります。
特にtext2imageコマンドが問題で、メーリングリストによるとMacOSX環境では何かレンダリングに問題があるとのこと。そもそも、MacOSXではまともに動作せず……。
[2016/08/21 追記] 上記の問題は開発版で修正されているので、将来のリリースではmacOS 環境でもtext2image ならびにtestrain.shを利用可能になりそうです。
私は試していませんが、、Cygwinの場合はtesseract-training-utilというパッケージが提供されています。
事前準備
$ sudo apt install tesseract-ocr tesseract-ocr-dev
Ubuntuの場合はパッケージをインストールすると/usr/binにtesstrain.shがインストールされています。
別のディストリビューションの場合は、パスを通った場所にスクリプトを配置。
langdata
XXX.tessdata のソースはgithubのlangdataにあるので一式ダウンロードします。
適当な作業ディレクトリに移動。
$ mkdir work
$ cd work
github のlangdataリポジトリにアクセスして、必要なファイル一式を入手する。
git cloneでもDownload ZIP でもどちらでもOK3。
$ git clone git://github.com/tesseract-ocr/langdata.git
フォントを用意する
作成したい言語について、少なくともlanguage-specific.shにハードコードされているフォントを用意しておく必要があります。c.f. tesseract/language-specific.sh line 275
下記のフォント一式を用意するか、スクリプトの方を修正。
- TakaoExGothic
- TakaoExMincho
- TakaoGothic
- TakaoMincho
- TakaoPGothic
- TakaoPMincho
- VL Gothic
- VL PGothic
- Noto Sans CJK JP Bold
- Noto Sans CJK JP Semi-Light
あまり印刷用とに使われないであろうVLゴシックは削除するのもあり。
$ sudo apt install fonts-takao fonts-vlgothic fonts-noto-cjk
このうち、TakaoExGothicとTakaoExMinchoについては縦書きでレンダリングされるようです3。
英数字の書体としてArial系のフォントが必要なので下記のパッケージもインストール。
$ sudo apt install ttf-mscorefonts-installer
あとは必要に応じて学習させたいフォントを/usr/share/fonts/truetypeあたりに用意。
準備
カスタマイズしたい内容に応じて必要な作業のみやればOK。
書体の追加
必要な作業は、下記。
- fontのインストール
-
font_propertiesの修正 - language-specific.sh の修正
下記のコマンドで対象フォントの名前が出てこればOKなはず。--fonts_dirの引数はスクリプトにハードコードされているものと同じである必要あり。
$ text2image --list_available_fonts --fonts_dir /usr/share/fonts
(skip)
明朝体、ゴシック体はそんなに差はないので、ポップ対とか丸ゴシック系を追加するといいかも。
font_propertiesの書式は下記の通り。フォント名に続けて該当する場合は”1”、そうでなければ"0"。左から順に、イタリック体、ボールド体、等幅、セリフ、ひげ文字のフラグ。
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
具体例(「はんなり明朝」、「たぬき油性マジック」を追加)
$ vi langdata/font_properties
適当な箇所に下記を追加。
HannariMincho 0 0 1 1 0
Tanuki_Permanent_Marker 0 0 0 0 0
IPA明朝がベースらしいので、同じように。
$ sudo vi /usr/share/tesseract-ocr/language-specific.sh
language-specific.shの794行目以降に学習させたい書体名を追加。上記のtext2image --list_available_fontsが出力するフォント名でないと認識しないっぽい。
「はんなり明朝」「たぬき油性マジック」の例(285行目の下に追加)
"HannariMincho"
"Tanuki Permanent Marker" \
縦書き用に学習させたい場合は、language-specific.shの794行目に書体名を追加すると縦書きでTIFFファイルが作成される。
未対応文字の追加
少なくともJIS第一水準漢字の一部が収録されていない(情報元)そうなので必要であれば追加。
2014年よりは登録済みの漢字は増えてる模様。というか、langdata/jpn/jpn.training_textをgrepしてヒットしなければ基本的に学習してないという話。
必要なのは学習させたい文字を含む画像と、画像内の文字の位置の情報。
text2imageコマンドの引数であるlangdata/jpn/jpn.training_textを修正すればあとはよろしくやってくれる。
そもそも公式リポジトリのtraining_txt自体、何かのコーパスを解析した単語を出現頻度か何かを考慮して結合しているだけっぽい。本当は実際の文書に近い方が望ましいと思われる。
- 変な文字列が含まれているの除去する(”yjulm”、"Mds")
- 追加したい文字を10から20回程度出現するように追加する。
とりあえず上記のページで紹介されている第一水準漢字については漢字の羅列形式で追記すればいい。
単語辞書の強化
langdata/jpn/jpn.wordlistの末尾に単語を1行1単語の形式で追加する。あまり認識率の改善には繋がらないような気がする。
先頭の100行は頻出単語の辞書生成に使用される模様(jpn.freq-dawg)。
辞書データはword2dawgコマンドで一種のTRIE形式に変換される。
例えばjpn.wordlistの末尾にはてなキーワードのダンプデータを追加してみるとか?
バグ修正
下記参照。langdata/jpn/jpn.unicharambigsを一部修正してやる必要あり。もしくは、完成後のjpn.tessdataをいじる。
jpn lang recognize error · Issue #146 · tesseract-ocr/tesseract · GitHub
アラビア数字の1が強制的に変換されてしまうので地味に響く。
tesstrain.sh を実行する
$ tesstrain.sh --lang jpn --langdata_dir ~/work/langdata
最終的に以下のようにメッセージが出力される。再起動する前に/tmpからデータを回収する。
Output /tmp/tesstrain/jpn/jpn.traineddata created sucessfully.
Creating new directory /tmp/tesstrain/tessdata
Moving /tmp/tesstrain/jpn/jpn.traineddata to /tmp/tesstrain/tessdata
動作確認
$ sudo mv /tmp/tessdata/jpn.traineddata /usr/share/tesseract-ocr/tessdata/jpn_new.traineddata
XXX.traineddataのXXXの部分は3文字でなくても問題ないので適当に。
適当な画像を用意して動作確認する。
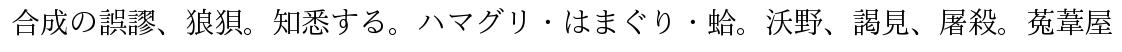
元の文章
合成の誤謬、狼狽。知悉する。ハマグリ・はまぐり・蛤。沃野、謁見、屠殺。菟葦屋
$ tesseract -l jpn test.png -psm 7 result
$ tesseract -l jpn_new test.png -psm 7 result_new
result.txt、result_new.txtに結果が出力されるので確かめる。問題がないなら標準のjpn.traineddataをバックアップして、新規作成した方をjpn.traineddataにリネームする。
結果
合成の誤謬、 狼狙。 知懇する。 ハマグリ 'はまぐり ・蛤。 沃野、 謁見、 屠殺。 蒐葦屋
合成の誤謬、 狼狽。 知悉する。 ハマグリ 'はまぐり '蛤。 沃野、 謁見、 屠殺。 菟 葦屋
JIS第一水準漢字でうまく非対応だった文字(狽、悉、菟)が認識できているのでひとまず良しとする。
その他
フォント関連
フリーフォントであれば下記のサイトなど。
文字の入った画像を手軽に作る方法
上手くいかないときは
メモリ不足
dmesgでカーネルログを確認しましょう。testrain.sh は終了ステータスのチェックをしてないようなのでOOM Killerで子プロセスが終了していても処理を続行します。
Out of memory: Kill process 2406 (tesseract)
メモリ1GBでは足りませんでした(笑)。
HDDの空き容量
300dpiのTIFF画像を複数生成する関係で、1.5〜2GBくらいの空き領域が必要。あとは/tmpをtempfsにしている場合とか。
場合によってはtesstrain_utils.shの28行目、32行目を修正する。
参考サイト
- tesstrain.sh · tesseract-ocr/tesseract Wiki · GitHub
- TrainingTesseract · tesseract-ocr/tesseract Wiki · GitHub
- Tesseract-OCRの学習 - はだしの元さん
- Tesseract-OCRの学習(識字率をあげる) - wiki - PCスキルの小技・忘却防止メモ
- Tesseract-OCRの日本語調教(1) - 日本語練習中
どうも分かりにくいような気がするのでそのうちリライトする予定。