以前書いた記事、[機械学習したデーターを爆速で販売するサービスをDockerで構築してみた](https://docker exec -it 7316979b7143 /bin/bash.com/masamunet/items/d690ead78245b216068d)という話で、話の流れからDockerについて説明したところ、嬉しいことに反響をたくさんいただきまして、記事そのものについてもそうですが特にDockerについてもっと教えてくれという反応やメールをいただきまして(大変ありがたいことに、技術系記事を書いてみないかというお誘いもいくつかいただきました)、せっかくなのでDockerについて私が知る範囲の説明を書いてみました。
Dockerの恩恵を理解するまでにはいくつかの段階があり、
- 仮想化って何?
- 仮想化の利点って何
- Dockerって何?
- Dockerは他の仮想か技術と比べて何が便利?
- 開発に使えるの?
- デプロイに使えるの?
- ステージングに使えるの?
- 本番環境に使えるの?
主にこういったレイヤーで話を進めていければ、わかってることは飛ばしながら読めるのではないかと考えております。
仮想化って何?
この記事の中で出てくる“仮想化”とは環境の仮想化を示します。
環境とはコンピューターのソースコードの実行環境のことを示します。つまりソースコードの実行環境を仮想的に行う技術や手段の総称をこの記事では仮想化という言葉で扱います。今から詳しく説明していきます。
思考実験その1:ハードウェアの仮想化
エミュレーター、という言葉を聞いたことがないでしょうか。知ってるという方は、エミュレーターの話ですという一言で済むのでこの章を読み飛ばして下さい。
仮に、の話でいいので一緒に考えてみてください。今手持ちのパソコンで(パソコンがなければパソコンがあると仮定して)、ファミコンソフトを動かすことを考えてみてください。あなたの手元にはなぜかスーパーマリオのソフトがあるものとします。パソコンでファミコンソフトが動かないでしょうか?
まずはバカになったつもりで否定してみてください。
「ハァ?パソコンでファミコンが動くはずないんですけど???パ・ソ・コ・ン、ファ・ミ・コ・ン全然違いますけど?」
いいですね。
次に「はたして本当にそうだろうか」と思ってみてください。
ソフトの所有権や知的財産所有権、法的な義務や権利、倫理的な問題は考えず、あくまで技術的なモデルケースとして思考実験を進めていきましょう。「自分はどうしてもファミコンのハードウェア特許について気になってしまって仕方がない!」ですとか「ソフトウェアの所有権がどうなってるかわからないのに議論が進められるわけがない!」みたいな理由でこういう話がどうしても苦手な方は、読み飛ばしてもらっても結構です。ファミコンがどうとかソフトがどうとか、例えが悪かった私の責任ですので、もしよろしければこのままハードウェアの仮想化について思考実験をお付き合いできればと思います。
もし、ファミコンのように振る舞うソフトウェアを作って、そのソフトウェア上でスーパーマリオを実行できれば、スーパーマリオは動くのではないでしょうか。
いきなり思考が飛んで正解が出ましたが、果たしてそんなことが可能なんでしょうか。
通常のスーパーマリオとファミコンの関係

ファミコンの図がスーパーファミコンになっててごめんなさい。単にDraw.ioにNESの適切な図が見つからなかっただけなので、読者の皆さんの脳内でスーパーファミコンの画像をファミコンに置き換えて読んでいってください。
普通にスーパーマリオをファミコンで動かそうとするには話はとても簡単で、ファミコンという実行環境の上でスーパーマリオを実行すればいいだけです。物理的に言えばファミコンにカセットを差し込んでスイッチを入れるだけです。
思考実験では、この”ファミコンの振る舞いをするソフトウェア”を作ってみて、そのソフトウェア上でスーパーマリオを実行してみたいと思います。
お手持ちのパソコンで、ファミコンのように振る舞うソフトウェア
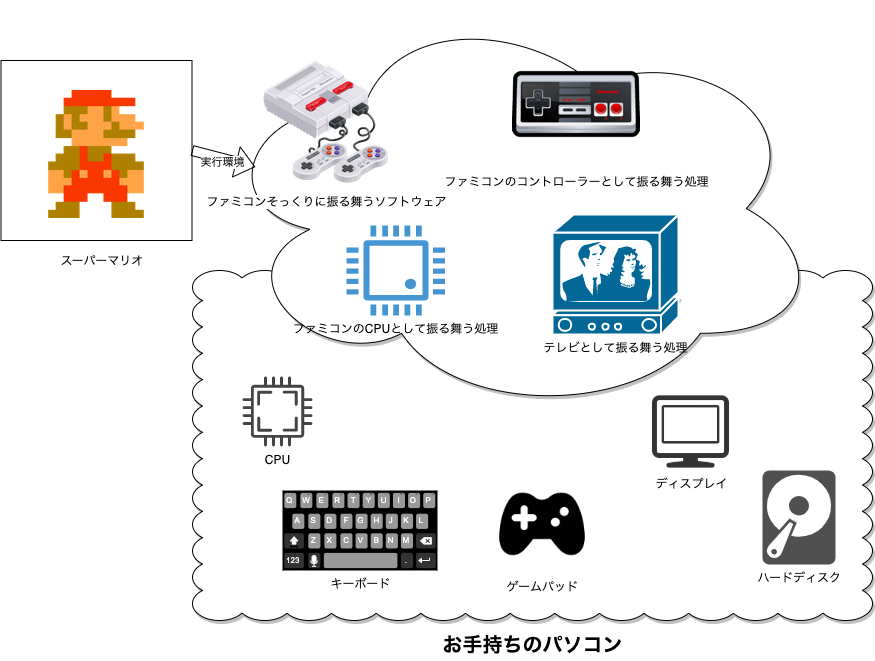
コンピューターとソフトウェアは、最終的には電気信号を基準にしたオンとオフのスイッチの羅列をやりとりしてるに過ぎないので、その振る舞いさえ辻褄が合えばエミュレートは可能です。
仮にファミコンにはスイッチが8個ついてると仮定して、コントローラーのAボタンを押すと8個のスイッチがこんな状態で信号をやりとりしたと仮定しましょう。
"00010000"
スーパーマリオは、コントローラーから上記のようなスイッチ配列が送られてきたら、Aボタンが押されたんだなと判断したとします。マリオはAボタンでジャンプしますから、マリオのY座標が画面上部に移動した結果をファミコンに返します。その信号は仮にこうだったとします。
"00111111"
すごく雑な仮説ばかり続いて恐縮ですが、結局のところソフトとハードのやりとりは電気信号を介したスイッチの配列のやりとりなので、この部分をソフトウェアが全部翻訳してしまえば、ハードウェアのエミュレーションは可能ということになります。
実はビットに換算できるものなら何でもエミュレーションできる可能性も持っていて、実際に量子はビットなのか波動なのかという議論は別としても現実世界の粒度をどこまでビット化させるのかによって、スパコンがやってる気象予想などは現実世界のエミュレーションとも言えます。
さまざまな可能性を秘めている、ハードウェアのエミュレーション技術ですが、インターネット黎明期のころにゲーム機のエミュレーターという言葉が違法性の高いソフトウェアとセットで話題として挙がることが多く、一般(といってもアングラな分野だった。この記事でいう一般とは一部の仮想化に詳しい技術者以外という程度の意味です)にあまりいいイメージで浸透しなかった過去があります。
仮想化の利点って何?
思考実験その2:同じハードウェアでの仮想化
さまざまな可能性のある仮想化。別のハードをエミュレーションする手法は残念ながら一般的にはマニア向け雑誌の部数稼ぎ企画であるゲームぶっこ抜きネタでしか広まりませんでしたが、では同じハードウェア上で仮想化を構築したらどうなるのでしょうか。利点はあるのでしょうか。
仮想化によるメリットとデメリットを比較するために、まずは仮想化のデメリットをあげてみます。
仮想化によるデメリットはそのままズバリ、仮想化処理のオーバーヘッドが少なからず発生する、ということです。要は処理が少なからず遅くなる、と言って差し支えないでしょう。
速さこそ正義、が一般的なコンピューティングの世界において、これは致命的なデメリットです。なので、このデメリットが見過ごせない案件の場合、仮想化は迷わず見合わせるべきです(仮想化すべきではありません)。
見方を変えれば、この重大な欠点を補ってあまりある利点が仮想化にはある、少なくともあるケースが多々存在する、ということです。
最新の仮想化による利点の最たるは、環境のソースコード化です。
少し話が脱線しますが、一説によると哲学上の生命の最終目標は、生命のソースコード化らしいです。生命はその存在をソースコードとして保存可能にすることこそが生命活動の最終目的であり究極らしいです。
この話を聞いて、すぐに「なるほど、そうか」と納得する人でしたら、環境のソースコード化が仮想化によるメリットなんですという説明も、すぐに理解できると思います。何ならこの章を読み飛ばしてもいいくらいです。それくらい、メリットは環境のソースコード化、のひとことに尽きるのです。
とは言え多くの人がピンとこないと思いますので、思考実験を続けていきましょう。
何か開発プロジェクトを立ち上げてみてください。
チーム開発か一人で開発か、最初はシンプルな方がいいので一人で開発するスタイルにしましょうか。
案件の種類は受託開発でも自社開発でも構いません。趣味のプログラミングでもOSSへの参加でも、最近買った初心者本の練習用でも構いません。
PythonでもC#でもNodeJSでも、PHPでもRubyでもPerlでもJAVAでもActionScriptでも結構です。思考実験として開発プロジェクトを立ち上げましょう。
いつも使ってるパソコンに、プロジェクト専用フォルダを作って、開発環境を構築していきます。構築といっても新たに何かすることは少なく、多くは使いなれたエディタにディレクトリを読み込ませれば開発環境の構築はほぼ完了してるはずです。開発に必要なライブラリはすでにパスが通ってる状態になっていて、いつでも開発を始められるかもしれません。
開発は順調に進んでいますが、ふと、何かの拍子に新しいライブラリが必要になったとします。
ところがうまくいかないもので、たまたま昔からメンテナンスしてる掲示板で使ってるライブラリと環境が衝突してしまって、新しいライブラリが入れられないかもしれません。もしくはライブラリは入れられたのだけど、古くからメンテしてる掲示板に方に潜在的な問題を抱えてしまって、その問題が表面化するのがさらに何ヶ月後かもしれません。よくある話です。
そう、よくある話すぎて、さまざまな言語やさまざまな環境、さまざまなライブラリやフレームワークで回避策や対応策がなされています。
それでもこの類の話は一向になくなる気配がありません。こういうとき、ひとつの回避策として強力な選択肢となりうるのが、開発環境の仮想化です。
ぼくがかんがえたさいきょうの開発環境仮想化
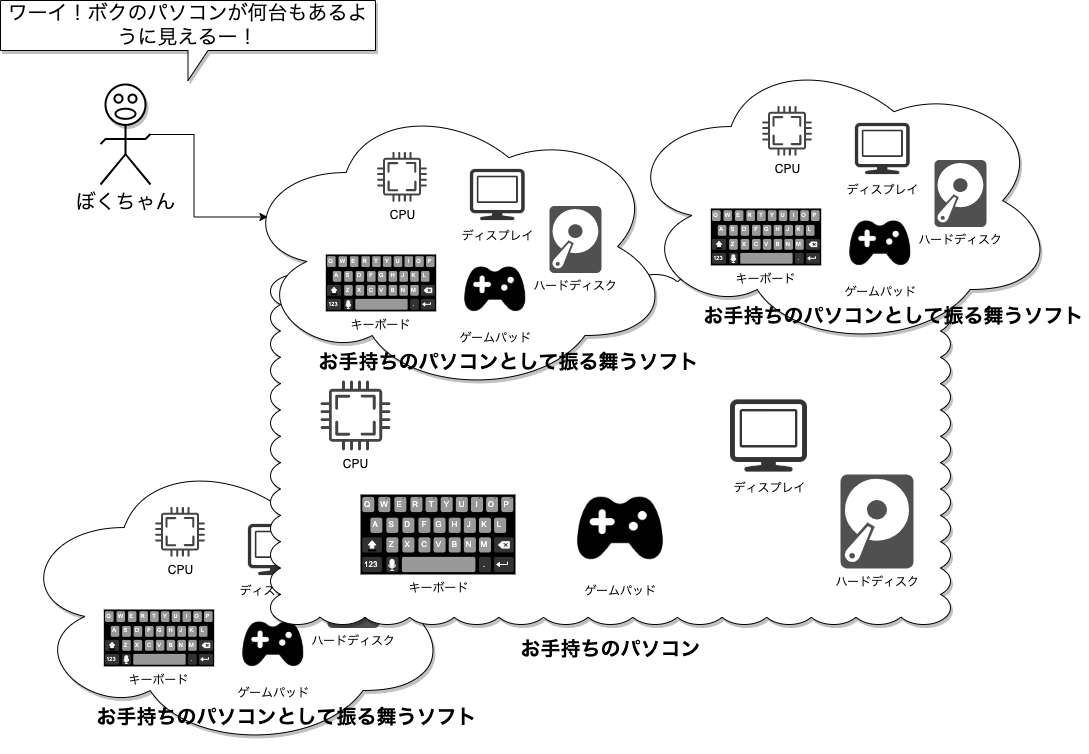
つまりはこういうことです。誰がこんな頭の悪いこと真面目に考えたんでしょうか。世界中の仮想化のえらい人たちです。頭のいい人って根本がバカで好きです。
開発環境のシンプルさ、もしくは複雑さについて、人によりまちまちだとは思います。私はどちらかというとできるだけシンプルでプレーンな状態を保つのが好きなほうですが、それでも”究極のシンプルさを求めるあまり、素の(.vimrcすら空の)vim以外では開発しない”という猛者ほどではありませんのですが、できるだけキーバインドなどもOSデフォルトを維持しつつ、どんなマシンが変わっても開発が続けられる状態を心がけています。ですが、それは私自身が個人開発の請負を主に行なっているので納品前にPCが壊れても(仮に家が爆発しても)、少なくとも納品だけは完遂できることを目的としているからで、人によっては何十年と環境構築してきた秘伝のタレみたいになってる開発環境を重んじることもあると思っています。
いずれの場合においても(簡単に開発環境を再現できる状態にしたPCを使っていたとしても、逆に何十年と設定を重ねてきて同じ状態のPCを揃えるのが難しい状況だったとしても)、プロジェクトごとに開発環境を仮想化できるメリットは多いように思えます。
まず、ハードウェアは普段のPCとして振る舞えるので、使用してる自分の開発機をそのまま使えます。秘伝のタレ派もコモン環境派もにっこりです。その上でプロジェクトごとにコンフリクトして欲しくない環境は完全に分離できます。プロジェクトごとに対してはあたかもマシンごと分離してるかのように振る舞えるので、プロジェクト同士の環境の衝突が少なくなります。ほぼゼロと考えても差し支えない場合がほとんどです。「他社さんに作ってもらったgulp3使ってる案件のメンテがあるからNodeJSのバージョン上げられない」といったあるあるが完璧に回避できるようになります。
作って壊せるスクラップ&ビルド環境
この利点は後ほどもう一度出てきます。
プロジェクトごとに環境を完全に分離できるということは、「ダメだったら壊せばいい」を気軽に行えるということです。よくある、「変なソフトをインストールしたら、アンインストールしてもPCの調子が悪くなった」を回避できるということです。最近のモダンで有名どころのオープンソースではあまり聞かないのですが、プロプライエタリな環境やフレームワークを使ってたりしてると、実行環境が非常にシビアで、一個何かライブラリをインストールするだけで動作が変わったりと、気を使うことが様々あるそうです。そうでなくても趣味PCのレベルでも「ネットでおすすめされたソフトインストールしてみたらいろんなファイルの関連付けが変わってしまった」などもあるあるではないでしょうか。適切に環境を分離できるということは、プロジェクトごとの環境も守りますし、実機を守ることにもつながります。「ダメだったら壊せる環境を作る」ことが仮想化開発環境のメリットの一つです。
環境の可搬性
高い可搬性とは、つまりどこでも実行できるということです。仮想化ではそれが可能です。
まず、チーム開発を考えてみてください。
全員が同じスキルセットのチームで開発できるのは、一つの開発者の理想でもあります。仮にそうだとしても、またはそうではなく、デザイナーやマネージャーやプログラマーが混在するチームで環境を共有しないといけないと仮定しても、いずれにしても環境の可搬性を高めることは有意義です。
よくある、「おれの環境では動いた」を限りなくゼロまで減らせます。仮想化とは環境の設定であるので、設定を共有すれば環境が再現されるからです。
環境のソースコード化
ここでやっと、環境のソースコード化に入ります。
これこそが仮想化の恩恵の最たるものであり、究極でもあります。
あるとき、誰か頭のいい人が考えたんです。「仮想化って設定なんだから、設定ファイルをソースコード化すればもっと便利になるじゃん?」と。
例えば、仮想環境のソースコード化で有名なVagrantを使ってみますと、以下のようなコードを書くだけでlaravelが実行可能な環境が立ち上がります。
Vagrant.configure("2") do |config|
config.vm.box = "laravel/homestead"
end
その正体はリンク先のようなプロビジョニングプロファイルの塊ですが、このように複雑な(もしくは、時に、単純な)環境設定をソースコード化することで可搬性が高まるだけでなく、Gitでの追跡も可能になります。つまり、環境について誰が、いつ、どのような目的で改変を加えたのか、共有するだけでなく追跡も可能になるということです。
環境の可搬性が高まるということは、前述したスクラップ&ビルドがより高い次元で行えるということでもあります。非常にシビアな条件を要求する環境(例えばこっちがマイグレーションされてないとこっちでスクレイピングできない、など)でのみ走る開発、などが容易に行えるようになります。何度手戻りしても再現可能性が高いわけです。
Dockerって何?
やっとDockerの話に入ります。Dockerが他の一般的な仮想化技術と比べて特徴的なのは、コンテナ化された仮想化技術にあります。コンテナ化の技術そのものはDocker以前から存在してるので、コンテナはDockerの専売特許ではないのですが、Dockerの特徴の大きな点としてコンテナ技術があります。
一般的な仮想化とコンテナ化を比べて、コンテナ化の特徴は、仮想環境のオーバーヘッドの少なさと、柔軟で強い可搬性・再現性にあります。
オーバーヘッドが少ない
オーバーヘッドが少ない、つまり同じホスト環境で似たようなゲスト環境を実行したとしたら、単純にDockerの方が速い場合が多いです。このことだけでも大きなアドバンテージになりうるので、いまいちDockerの理解が進まない方はまずは「仮想環境にしてはDockerは速いほう」という理解だけで導入を検討してみてもいいかもしれません。
Dockerコンテナの特徴として、Linuxに最初から備わっている”標準出力・標準入力”という機能を利用して仮想化を実現しています。これがオーバーヘッドの少なさ(仮想環境にしては実行速度の速さ)を実現しています。
まず、説明のために乱暴に端折った語句の使い方から説明しないといけません。
実際には”標準出力・標準入力”という機能は存在せず、正確にいうならLinuxは出力先と入力先を指定できる機能があって、特に指定のない場合あらかじめ設定された標準出力と標準入力が使用される、という方が語弊が少なくないかもしれません。ただ、説明を簡略化するためにこの記事では便宜上その機能の総称を”Linuxの標準出力・標準入力”と呼ぶことにします。
次に、Linuxの、という語句が引っかかった方もいるかもしれません。標準出力・標準入力はLinuxに限らずもともとLinuxが参考にしたUNIXやその派生のBSD系にも備わっているからです。BSDをUNIXの派生と決め付けることにも議論があるかもしれませんが、仮想化技術と少し話題が離れすぎてしまうためにこの記事では便宜上、それらの諸々を吸収して説明する言葉として”Linuxの標準出力・標準入力”と呼んでいるとご理解ください。
説明を続けます。
少し昔の話になります。
今と違って一つ一つのコンピューターに十分な処理能力がなかった時代、徹底したクライアント&サーバーシステムでコンピューターを操作するためのシステムとしてUNIXが設計されました。
この時、オペレーターの手元にある端末はあくまでも中央サーバーへ入力するためだけのキーボードと、中央サーバーの演算処理結果を表示するためだけのディスプレイにすぎず、端末は文字通り端末でしかなかったわけです。その端末からの入力を受け取り、結果を出力するUNIXは、入力がなんであるか、また出力がなんであるか関係なくても動くように設計されました。
そのUNIXを参考にして作られた経緯のあるLinuxにも、OSの仕組みとして最初から入力と出力をこだわらない機能が備わっていました。Linuxを操作したことのある方には馴染みの深い、パイプとリダイレクトもその機能です。
つまりLinuxは最初から、入ってくる文字列がキーボードからなのかファイルからなのか、はたまたUSBからの信号なのかこだわらないし、出力する先もディスプレイなのかファイルなのか、もしかしたらプリンターなのかも関係なく動作するような機能が備わっているということになります。Dockerはここを利用しました。
DockerはLinuxの標準機能に対して相応の振る舞いをするだけで結果を得られる
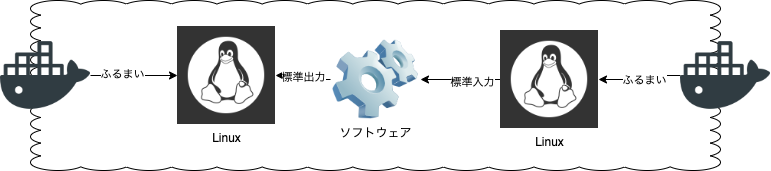
Docker以外の従来の仮想化は、いろいろと振る舞いを求められることが多い
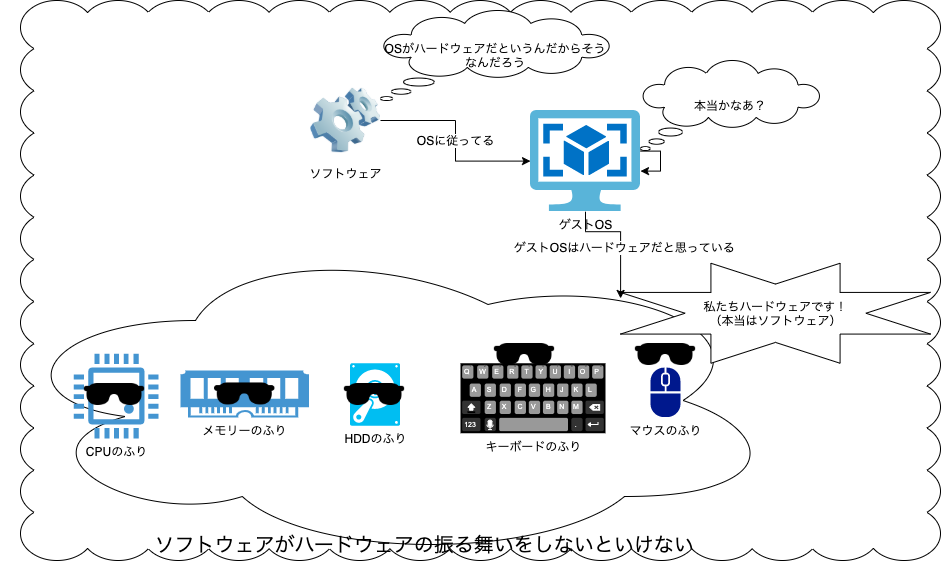
この、無理のなさがDockerコンテナでのオーバーヘッドの少なさを実現しています。
ですので、Dockerへの理解がいまいち追いつかない方は、少し乱暴ですが「Dockerは速い(キリッ」とだけ覚えていて、(仮想化としては)速いんだから使ってみよう、という導入でも仮想化の恩恵を受けられるかもしれません。
環境のブランチ&フォーク化
さらに、コンテナ内で標準出力・標準入力で完結しているということは、コンテナを積み重ねることでいくらでも環境を構築できるという利点もあります。
先ほどVagrantでやってみたLaravelの環境をDockerでも構築してみる実験をしてみましょう。
「いや、オレPHPとかLaravelとか知らないんだけど?」という方も大丈夫です。思考実験として、環境構築を考えるフリを一緒にやってみてください。
いきなりLaravelが動く環境全部入りをインストールするのもありです。そういうコンテナを作るのも、非常に便利なのでとてもよくあるケースです。
ですがせっかくなのでDockerのコンテナを積み上げる形でつくってみることにします。
まずはOSは何にしましょう。愚問です。DockerはLinuxの機能を使っているので、OSはLinux以外使用できません。今のところは。ですがOSに使用するディストリビューションは選ぶことができます。
開発環境として人気の高いUbuntuで行きますか、それともデプロイ先として信頼性の高いCentOSで行きましょうか。慣れてくると軽量コンテナとして定評のあるAlpine Linuxや、そもそものBusyBoxなども検討に入ってくると思います。個人的にはコンテナの軽量化目的だけでAlpineを選ぶと、ライブラリのビルドなどで余計に容量や時間を食うことも多いですが、マルチステージビルドなどを駆使して数MB軽くしていくロマンもあります。過渡期に人気の高かったCoreOSも使い勝手がいいかもしれません。個人的にはVagrantでCoreOSをクラスター化してた時は楽しかったですが、Dockerコンテナを使い始めてからは自分の中では役割が完全に置き換わってしまいました。
ディストリビューションが決まったら、開発に必要なツールをインストールしていきます。
gccやlib-png、gitなどを入れておきましょう。
PHPの実行環境をどのようにするか、悩みどころです。FPM版PHPをApacheで動かして前面にNginxでリバースプロキシを立ち上げる構成にしてみます。composerもインストールして、DBはMySQLを使うことにします。
全ての環境構築は、主にDockerfileというテキストファイルに記述していきますので、この環境そのものをGitで管理することもできます。
または、Dockerのイメージにタグをつけることで、環境そのものに名前をつけておいて後から引っ張り出すことができるようになります。これが非常に強力です。
別のディストリビューション、別のバージョン、アプリケーション層をApacheじゃなくNginxにしたら?事情によってDBをPostgreSQLにしたら?急遽バッチ処理が必要になってPython2をグローバルで動かさなくては行けなくなったら?さまざまな問題に対して、環境に名前をつけることで阿智からいくらでも自由に出し入れできるようになります。
開発環境としてのDocker
Dockerがまだ黎明期の頃は、Dockerについて解説した解説文の中にもたまに
「docker exec -it xxxxxxxxxxxxxxxx /bin/bash
でDockerのコンテナにログインできるから、あとはvimで開発しよう!(大まじめ」
みたいな提案してた文章も少なからず存在しました。
どんな場合でも素のvimで開発が始められる人が少なからず存在することは否定しませんが、自分にはDockerを開発に使うのは、導入までの閾値が少し高いなと正直思いました。
逆に、開発環境はいつものホストOS側に統一したいから、Dockerのファイル共有で開発環境そのものをコンテナと共有しよう、(なんならVagrantかまそう)みたいな環境を工夫したこともあります。
これもDockerのゲストOSが基本rootで実行されるので、ホストOS側とのファイルの所有権の衝突で早々に積みました。
今の最適解は、DockerfileのCOPYコマンドで開発環境のファイルをコンテナに移動させて、透過的に扱えるようにする、です。一言で言えば、VSCodeのリモートコンテナ機能を使います。
VSCodeのリモートコンテナ機能は非常によく考えられていて、開発環境とデプロイ環境のコンテナ戦略なんかも将来的に詰まないようにベストプラクティスがいっぱい詰まってるんですが、この記事では割愛します。VSCodeのリモートコンテナ機能を使うと、Dockerでの開発が非常に楽になります。
デプロイ環境としてのDocker
Docker黎明期にもう一つ議論になったこととして、そもそもDockerはデプロイに使えるのか、という問題がありました。しかしながら数カ月前が原始時代に思えるほど技術の流れが早く、今や本格サービスでDockerを切り離して考えてるところの方が存在しないほど、デプロイとDockerは切っても切り離せなくなりました。
CI/CDとの親和性の高さ、耐障害性、復旧性、どれを取っても堅牢なシステムづくりにDockerのコンテナ化が欠かせないと言って、鼻で笑われたことがまるで前世紀の出来事のようです。
耐障害性や復旧性については、Kubernetesなどのオーケストレーションも絡んでくることなので割愛しまして(でもざくっと言ってしまえば環境をソースコード化できてるんで、別のマシンで同じ環境を立ち上げてしまえば復旧が早いので、それを自動化していこうぜみたいなのがKubernetes)、CI/CDでデプロイするときにDockerだとどれだけ楽か、に焦点を当ててみましょう。
before_script:
- docker login -u gitlab-ci-token -p $CI_BUILD_TOKEN registry.gitlab.com
stages:
- docker_build
- push
- deploy
- boot
service_job1:
stage: docker_build
tags:
- shell
before_script:
- docker login -u gitlab-ci-token -p $CI_BUILD_TOKEN registry.gitlab.com
- cd $CI_PROJECT_DIR/docker/resemble_stock_app
- mkdir build_work
script:
- cp -rf $CI_PROJECT_DIR/service build_work/service
- cp -rf $CI_PROJECT_DIR/python build_work/python
- docker build -t registry.gitlab.com/$PROJECT_PATH/resemble_stock_app:latest .
after_script:
- rm -rf build_work
service_push1:
stage: push
tags:
- shell
script:
- docker push registry.gitlab.com/$PROJECT_PATH/resemble_stock_app:latest
scraping_job1:
stage: docker_build
tags:
- shell
before_script:
- docker login -u gitlab-ci-token -p $CI_BUILD_TOKEN registry.gitlab.com
- cd $CI_PROJECT_DIR/docker/scraping_resemble_stock
- mkdir build_work
script:
- cp -rf $CI_PROJECT_DIR/service build_work/scraping
- cp -rf $CI_PROJECT_DIR/python build_work/python
- docker build -t registry.gitlab.com/$PROJECT_PATH/scraping_resemble_stock:latest .
after_script:
- rm -rf build_work
scraping_push1:
stage: push
tags:
- shell
script:
- docker push registry.gitlab.com/$PROJECT_PATH/scraping_resemble_stock:latest
これはスクレイピングを実行するPython環境を作ったときの実際のGitlabのCIファイルです。
ディレクトリごとに移動してビルドしてるのでcdコマンドやrmコマンドが少し不細工ですが、実際にやってることはDockerのビルドと実行だけなので、どれだけ楽か、測り知れないものがあります。
FROM python:3.7.6-slim
WORKDIR /app
COPY requirements.txt ./
RUN apt-get update && apt-get upgrade -y && apt-get clean && \
pip3 install --upgrade pip && \
pip3 install --no-cache-dir -r requirements.txt && \
rm -rf requirements.txt
これが実際に使用したDockerfileです。Pythonに限って言えば、pipで環境をrequirements.txtに出力しておいて、Dockerfileに食わせるだけなので、Pythonの実行環境の可搬性がぐっと高くなります。
NodeJSなどでもわざわざDockerにしなくてもnpm install や yarn install などで環境の一貫性を保つことはある程度可能ですが、MongoDBなど連携する環境含めての構築となるとやはりDockerfileが群を抜いていると思います。
まとめ
いかがでしたでしょう的な、幸いです的なまとめの言葉を考えるのが面倒臭いのでこのまま終わります!